 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNa Li
Gaussian Max-Value Entropy Search for Multi-Agent Bayesian Optimization
Mar 10, 2023



We study the multi-agent Bayesian optimization (BO) problem, where multiple agents maximize a black-box function via iterative queries. We focus on Entropy Search (ES), a sample-efficient BO algorithm that selects queries to maximize the mutual information about the maximum of the black-box function. One of the main challenges of ES is that calculating the mutual information requires computationally-costly approximation techniques. For multi-agent BO problems, the computational cost of ES is exponential in the number of agents. To address this challenge, we propose the Gaussian Max-value Entropy Search, a multi-agent BO algorithm with favorable sample and computational efficiency. The key to our idea is to use a normal distribution to approximate the function maximum and calculate its mutual information accordingly. The resulting approximation allows queries to be cast as the solution of a closed-form optimization problem which, in turn, can be solved via a modified gradient ascent algorithm and scaled to a large number of agents. We demonstrate the effectiveness of Gaussian max-value Entropy Search through numerical experiments on standard test functions and real-robot experiments on the source-seeking problem. Results show that the proposed algorithm outperforms the multi-agent BO baselines in the numerical experiments and can stably seek the source with a limited number of noisy observations on real robots.
Latent Variable Representation for Reinforcement Learning
Dec 17, 2022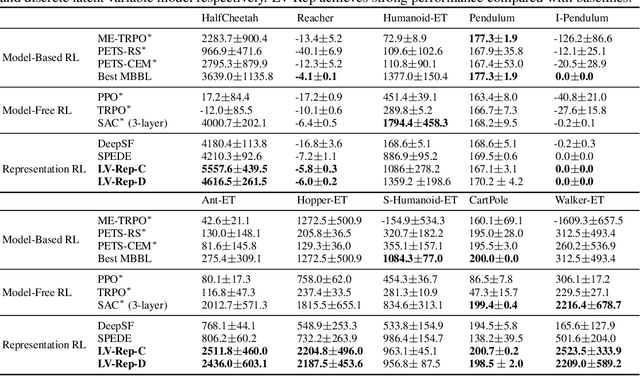

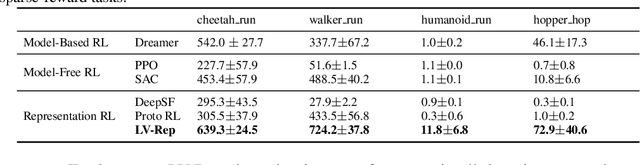
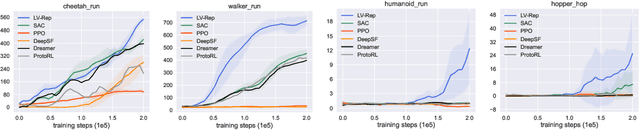
Deep latent variable models have achieved significant empirical successes in model-based reinforcement learning (RL) due to their expressiveness in modeling complex transition dynamics. On the other hand, it remains unclear theoretically and empirically how latent variable models may facilitate learning, planning, and exploration to improve the sample efficiency of RL. In this paper, we provide a representation view of the latent variable models for state-action value functions, which allows both tractable variational learning algorithm and effective implementation of the optimism/pessimism principle in the face of uncertainty for exploration. In particular, we propose a computationally efficient planning algorithm with UCB exploration by incorporating kernel embeddings of latent variable models. Theoretically, we establish the sample complexity of the proposed approach in the online and offline settings. Empirically, we demonstrate superior performance over current state-of-the-art algorithms across various benchmarks.
Learning to Optimize with Stochastic Dominance Constraints
Nov 21, 2022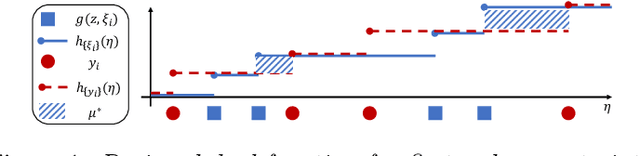

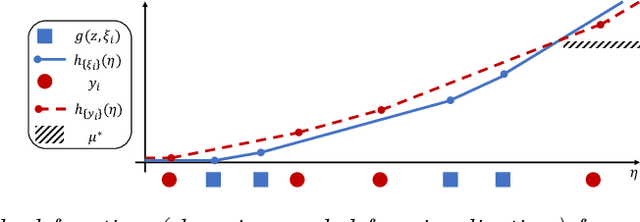

In real-world decision-making, uncertainty is important yet difficult to handle. Stochastic dominance provides a theoretically sound approach for comparing uncertain quantities, but optimization with stochastic dominance constraints is often computationally expensive, which limits practical applicability. In this paper, we develop a simple yet efficient approach for the problem, the Light Stochastic Dominance Solver (light-SD), that leverages useful properties of the Lagrangian. We recast the inner optimization in the Lagrangian as a learning problem for surrogate approximation, which bypasses apparent intractability and leads to tractable updates or even closed-form solutions for gradient calculations. We prove convergence of the algorithm and test it empirically. The proposed light-SD demonstrates superior performance on several representative problems ranging from finance to supply chain management.
Semantic Video Moments Retrieval at Scale: A New Task and a Baseline
Oct 15, 2022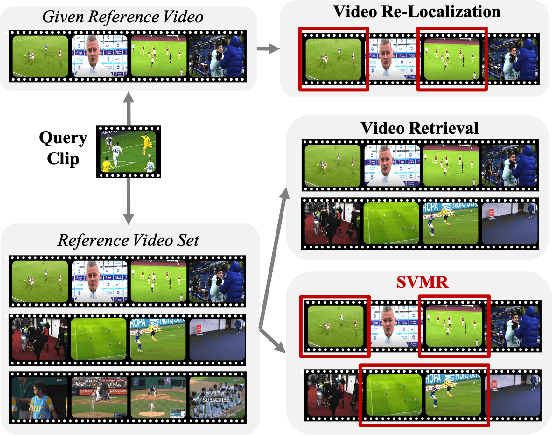


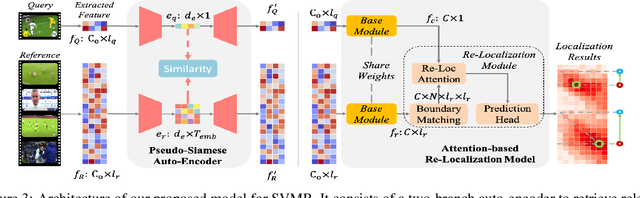
Motivated by the increasing need of saving search effort by obtaining relevant video clips instead of whole videos, we propose a new task, named Semantic Video Moments Retrieval at scale (SVMR), which aims at finding relevant videos coupled with re-localizing the video clips in them. Instead of a simple combination of video retrieval and video re-localization, our task is more challenging because of several essential aspects. In the 1st stage, our SVMR should take into account the fact that: 1) a positive candidate long video can contain plenty of irrelevant clips which are also semantically meaningful. 2) a long video can be positive to two totally different query clips if it contains clips relevant to two queries. The 2nd re-localization stage also exhibits different assumptions from existing video re-localization tasks, which hold an assumption that the reference video must contain semantically similar segments corresponding to the query clip. Instead, in our scenario, the retrieved long video can be a false positive one due to the inaccuracy of the first stage. To address these challenges, we propose our two-stage baseline solution of candidate videos retrieval followed by a novel attention-based query-reference semantically alignment framework to re-localize target clips from candidate videos. Furthermore, we build two more appropriate benchmark datasets from the off-the-shelf ActivityNet-1.3 and HACS for a thorough evaluation of SVMR models. Extensive experiments are carried out to show that our solution outperforms several reference solutions.
The DKU-Tencent System for the VoxCeleb Speaker Recognition Challenge 2022
Oct 11, 2022
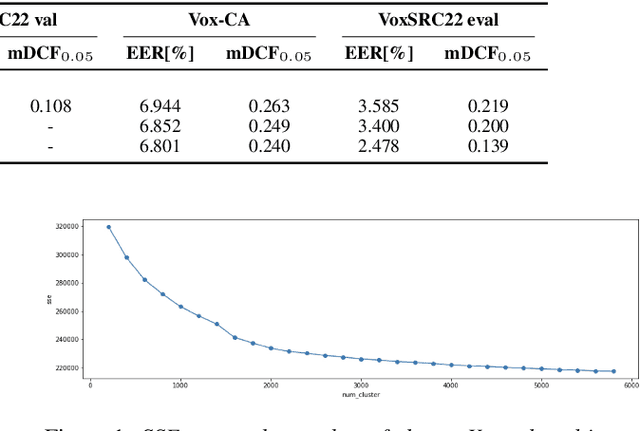
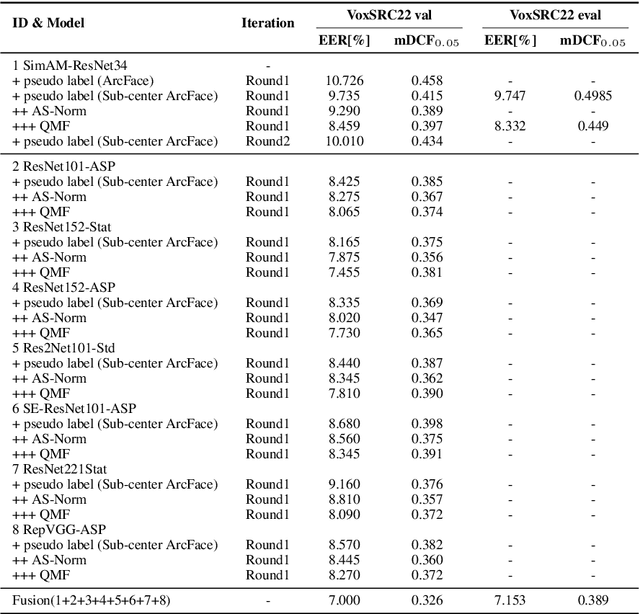
This paper is the system description of the DKU-Tencent System for the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC22). In this challenge, we focus on track1 and track3. For track1, multiple backbone networks are adopted to extract frame-level features. Since track1 focus on the cross-age scenarios, we adopt the cross-age trials and perform QMF to calibrate score. The magnitude-based quality measures achieve a large improvement. For track3, the semi-supervised domain adaptation task, the pseudo label method is adopted to make domain adaptation. Considering the noise labels in clustering, the ArcFace is replaced by Sub-center ArcFace. The final submission achieves 0.107 mDCF in task1 and 7.135% EER in task3.
Towards a Theoretical Foundation of Policy Optimization for Learning Control Policies
Oct 10, 2022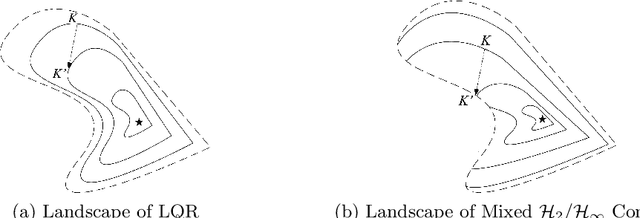
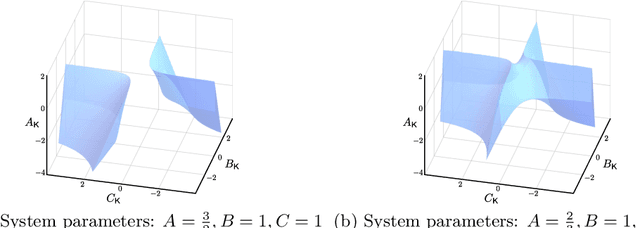
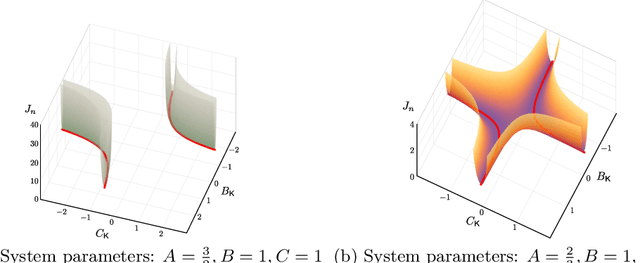
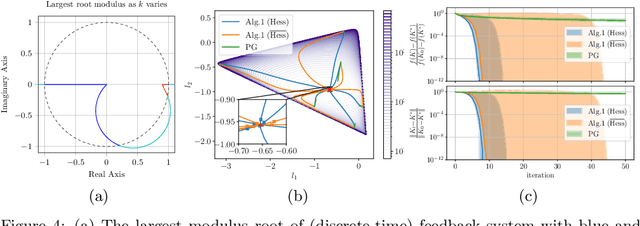
Gradient-based methods have been widely used for system design and optimization in diverse application domains. Recently, there has been a renewed interest in studying theoretical properties of these methods in the context of control and reinforcement learning. This article surveys some of the recent developments on policy optimization, a gradient-based iterative approach for feedback control synthesis, popularized by successes of reinforcement learning. We take an interdisciplinary perspective in our exposition that connects control theory, reinforcement learning, and large-scale optimization. We review a number of recently-developed theoretical results on the optimization landscape, global convergence, and sample complexity of gradient-based methods for various continuous control problems such as the linear quadratic regulator (LQR), $\mathcal{H}_\infty$ control, risk-sensitive control, linear quadratic Gaussian (LQG) control, and output feedback synthesis. In conjunction with these optimization results, we also discuss how direct policy optimization handles stability and robustness concerns in learning-based control, two main desiderata in control engineering. We conclude the survey by pointing out several challenges and opportunities at the intersection of learning and control.
Distributed Information-based Source Seeking
Sep 20, 2022

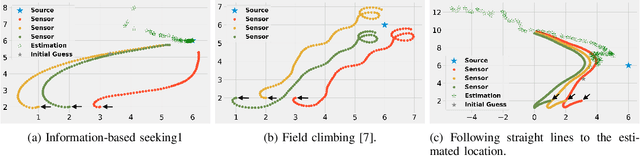
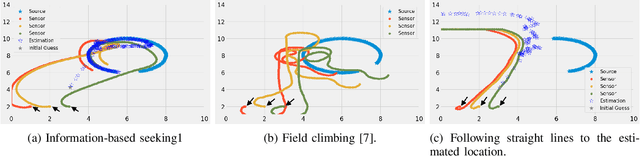
In this paper, we design an information-based multi-robot source seeking algorithm where a group of mobile sensors localizes and moves close to a single source using only local range-based measurements. In the algorithm, the mobile sensors perform source identification/localization to estimate the source location; meanwhile, they move to new locations to maximize the Fisher information about the source contained in the sensor measurements. In doing so, they improve the source location estimate and move closer to the source. Our algorithm is superior in convergence speed compared with traditional field climbing algorithms, is flexible in the measurement model and the choice of information metric, and is robust to measurement model errors. Moreover, we provide a fully distributed version of our algorithm, where each sensor decides its own actions and only shares information with its neighbors through a sparse communication network. We perform intensive simulation experiments to test our algorithms on large-scale systems and physical experiments on small ground vehicles with light sensors, demonstrating success in seeking a light source.
Multi-armed Bandit Learning on a Graph
Sep 20, 2022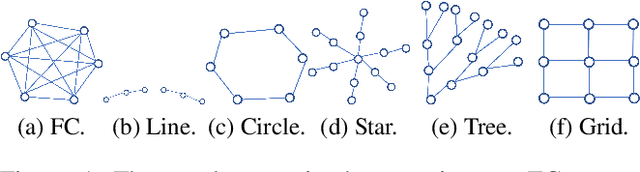
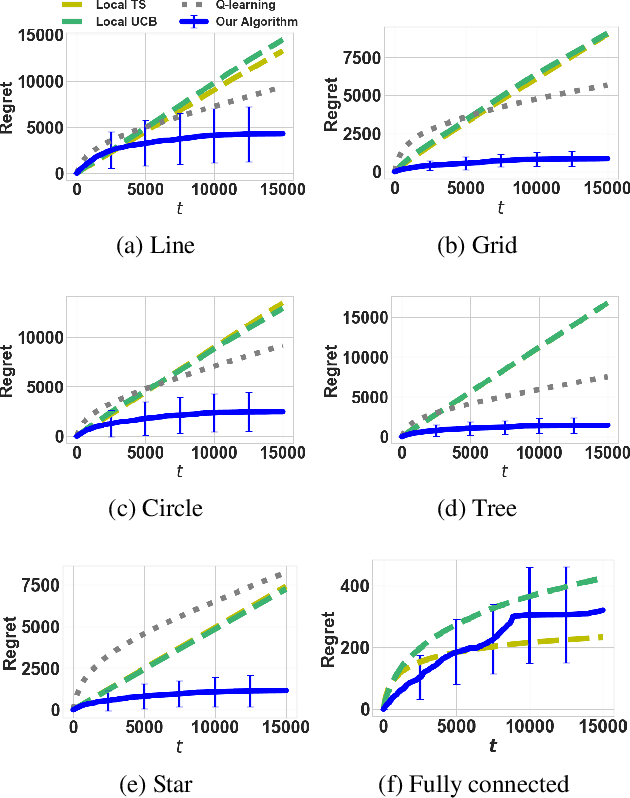
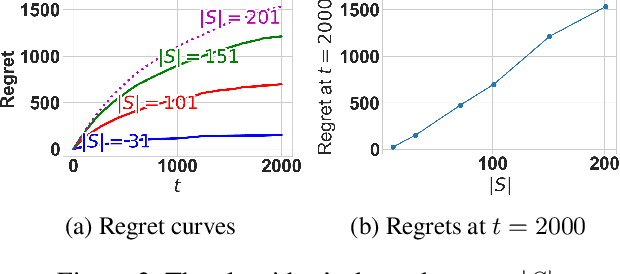
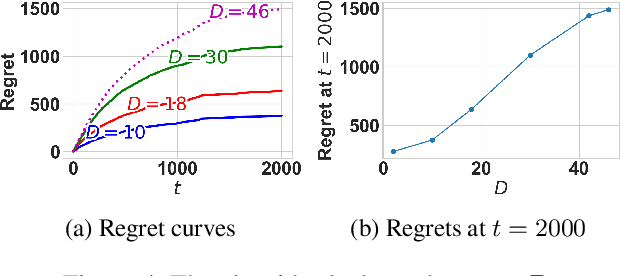
The multi-armed bandit(MAB) problem is a simple yet powerful framework that has been extensively studied in the context of decision-making under uncertainty. In many real-world applications, such as robotic applications, selecting an arm corresponds to a physical action that constrains the choices of the next available arms (actions). Motivated by this, we study an extension of MAB called the graph bandit, where an agent travels over a graph trying to maximize the reward collected from different nodes. The graph defines the freedom of the agent in selecting the next available nodes at each step. We assume the graph structure is fully available, but the reward distributions are unknown. Built upon an offline graph-based planning algorithm and the principle of optimism, we design an online learning algorithm that balances long-term exploration-exploitation using the principle of optimism. We show that our proposed algorithm achieves $O(|S|\sqrt{T}\log(T)+D|S|\log T)$ learning regret, where $|S|$ is the number of nodes and $D$ is the diameter of the graph, which is superior compared to the best-known reinforcement learning algorithms under similar settings. Numerical experiments confirm that our algorithm outperforms several benchmarks. Finally, we present a synthetic robotic application modeled by the graph bandit framework, where a robot moves on a network of rural/suburban locations to provide high-speed internet access using our proposed algorithm.
FedDAR: Federated Domain-Aware Representation Learning
Sep 08, 2022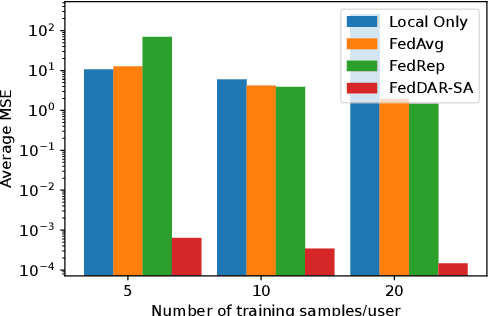

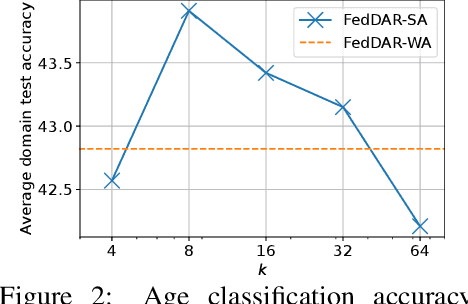
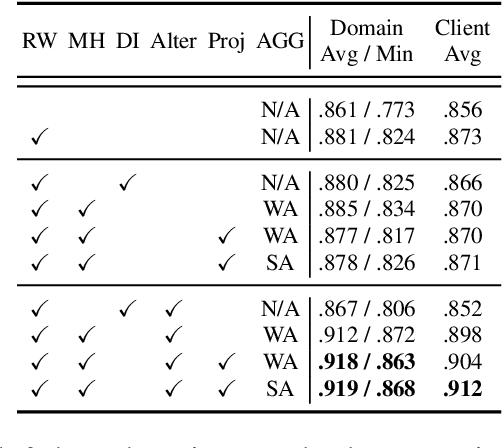
Cross-silo Federated learning (FL) has become a promising tool in machine learning applications for healthcare. It allows hospitals/institutions to train models with sufficient data while the data is kept private. To make sure the FL model is robust when facing heterogeneous data among FL clients, most efforts focus on personalizing models for clients. However, the latent relationships between clients' data are ignored. In this work, we focus on a special non-iid FL problem, called Domain-mixed FL, where each client's data distribution is assumed to be a mixture of several predefined domains. Recognizing the diversity of domains and the similarity within domains, we propose a novel method, FedDAR, which learns a domain shared representation and domain-wise personalized prediction heads in a decoupled manner. For simplified linear regression settings, we have theoretically proved that FedDAR enjoys a linear convergence rate. For general settings, we have performed intensive empirical studies on both synthetic and real-world medical datasets which demonstrate its superiority over prior FL methods.
Dialogue Policies for Confusion Mitigation in Situated HRI
Aug 19, 2022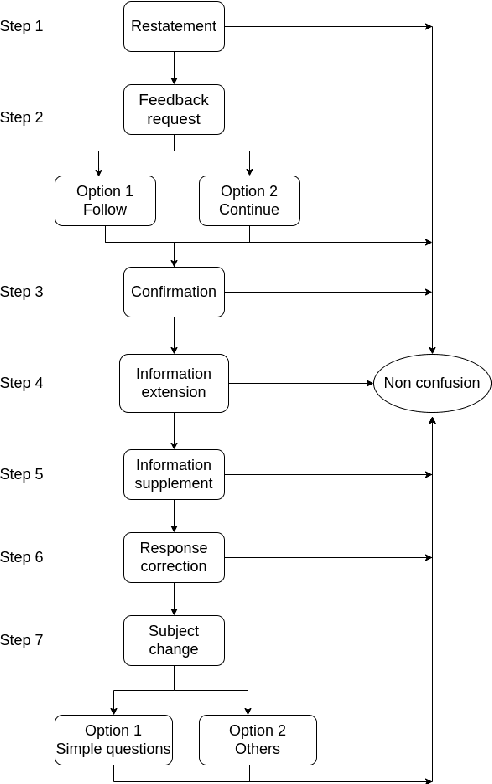
Confusion is a mental state triggered by cognitive disequilibrium that can occur in many types of task-oriented interaction, including Human-Robot Interaction (HRI). People may become confused while interacting with robots due to communicative or even task-centred challenges. To build a smooth and engaging HRI, it is insufficient for an agent to simply detect confusion; instead, the system should aim to mitigate the situation. In light of this, in this paper, we present our approach to a linguistic design of dialogue policies to build a dialogue framework to alleviate interlocutor confusion. We also outline our sketch and discuss challenges with respect to its operationalisation.