 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Flexible Mixed Integer Programming framework for Nurse Scheduling
Oct 12, 2012In this paper, a nurse-scheduling model is developed using mixed integer programming model. It is deployed to a general care ward to replace and automate the current manual approach for scheduling. The developed model differs from other similar studies in that it optimizes both hospitals requirement as well as nurse preferences by allowing flexibility in the transfer of nurses from different duties. The model also incorporated additional policies which are part of the hospitals requirement but not part of the legislations. Hospitals key primary mission is to ensure continuous ward care service with appropriate number of nursing staffs and the right mix of nursing skills. The planning and scheduling is done to avoid additional non essential cost for hospital. Nurses preferences are taken into considerations such as the number of night shift and consecutive rest days. We will also reformulate problems from another paper which considers the penalty objective using the model but without the flexible components. The models are built using AIMMS which solves the problem in very short amount of time.
Intelligent Search Heuristics for Cost Based Scheduling
Oct 04, 2012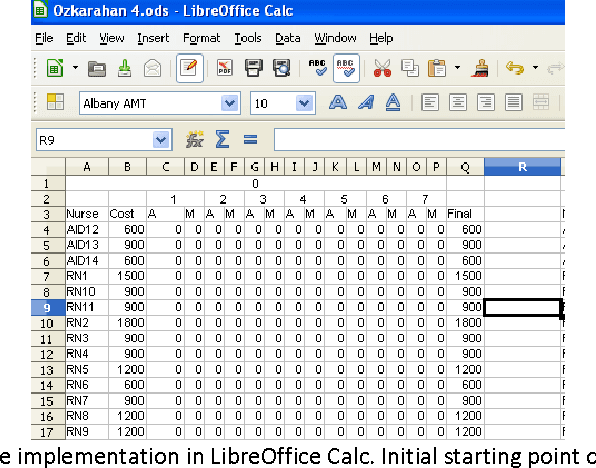
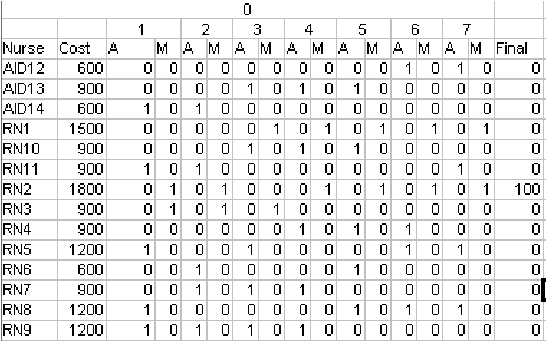
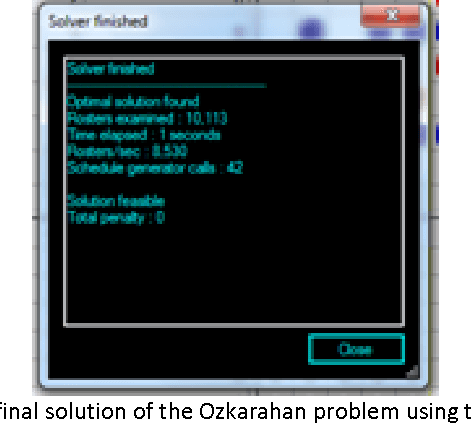
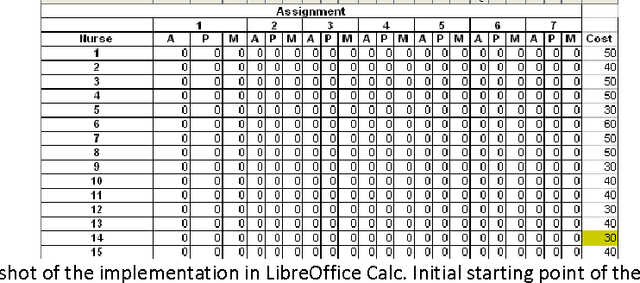
Nurse scheduling is a difficult optimization problem with multiple constraints. There is extensive research in the literature solving the problem using meta-heuristics approaches. In this paper, we will investigate an intelligent search heuristics that handles cost based scheduling problem. The heuristics demonstrated superior performances compared to the original algorithms used to solve the problems described in Li et. Al. (2003) and Ozkarahan (1989) in terms of time needed to establish a feasible solution. Both problems can be formulated as a cost problem. The search heuristic consists of several phrases of search and input based on the cost of each assignment and how the assignment will interact with the cost of the resources.
Effective Listings of Function Stop words for Twitter
May 29, 2012Many words in documents recur very frequently but are essentially meaningless as they are used to join words together in a sentence. It is commonly understood that stop words do not contribute to the context or content of textual documents. Due to their high frequency of occurrence, their presence in text mining presents an obstacle to the understanding of the content in the documents. To eliminate the bias effects, most text mining software or approaches make use of stop words list to identify and remove those words. However, the development of such top words list is difficult and inconsistent between textual sources. This problem is further aggravated by sources such as Twitter which are highly repetitive or similar in nature. In this paper, we will be examining the original work using term frequency, inverse document frequency and term adjacency for developing a stop words list for the Twitter data source. We propose a new technique using combinatorial values as an alternative measure to effectively list out stop words.
A sentiment analysis of Singapore Presidential Election 2011 using Twitter data with census correction
Aug 29, 2011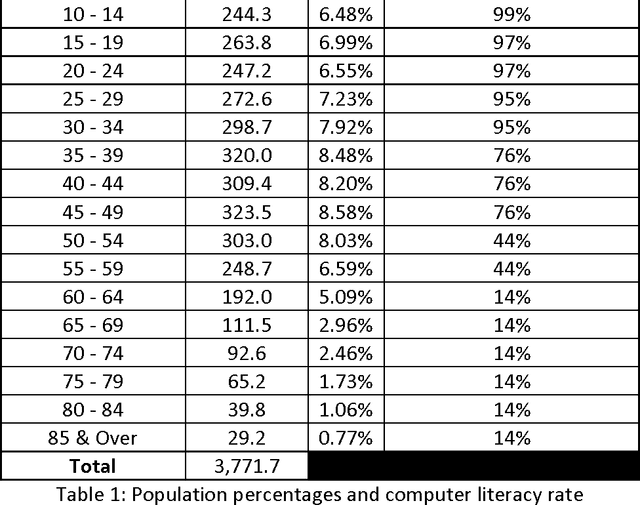
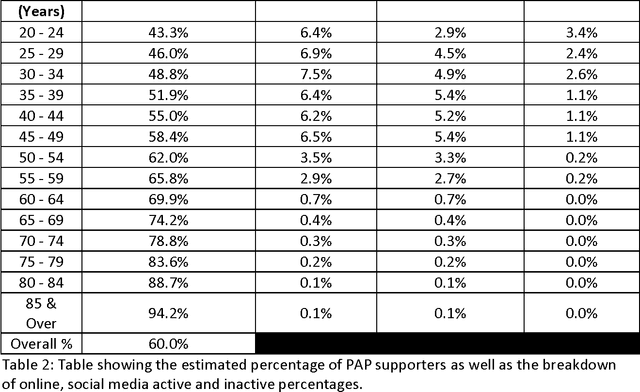
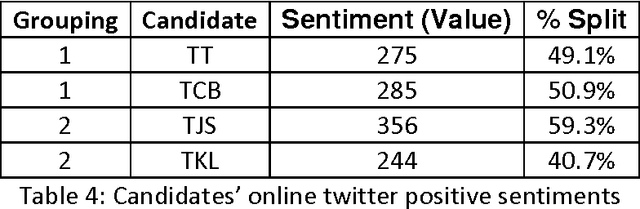
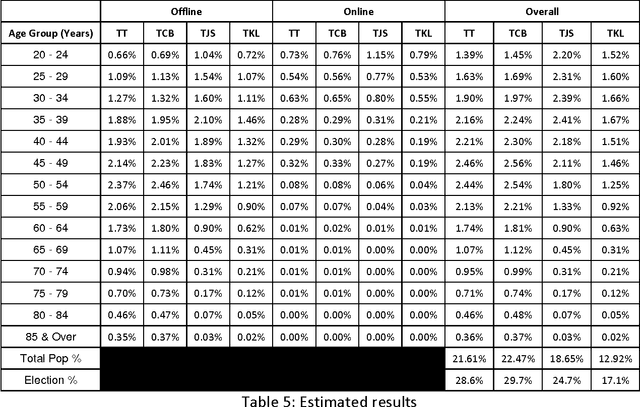
Sentiment analysis is a new area in text analytics where it focuses on the analysis and understanding of the emotions from the text patterns. This new form of analysis has been widely adopted in customer relation management especially in the context of complaint management. With increasing level of interest in this technology, more and more companies are adopting it and using it to champion their marketing efforts. However, sentiment analysis using twitter has remained extremely difficult to manage due to the sampling bias. In this paper, we will discuss about the application of using reweighting techniques in conjunction with online sentiment divisions to predict the vote percentage that individual candidate will receive. There will be in depth discussion about the various aspects using sentiment analysis to predict outcomes as well as the potential pitfalls in the estimation due to the anonymous nature of the internet.