 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosted Cascaded Convnets for Multilabel Classification of Thoracic Diseases in Chest Radiographs
Nov 23, 2017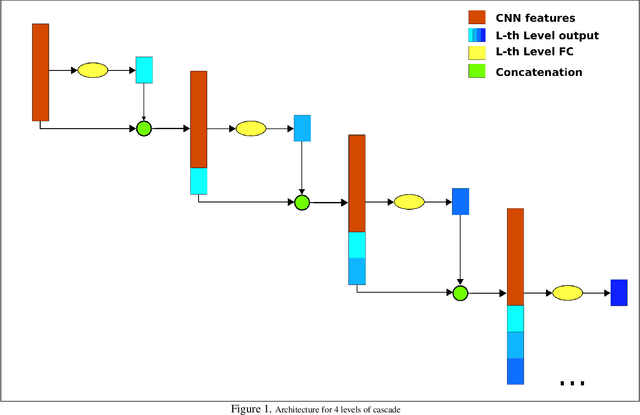
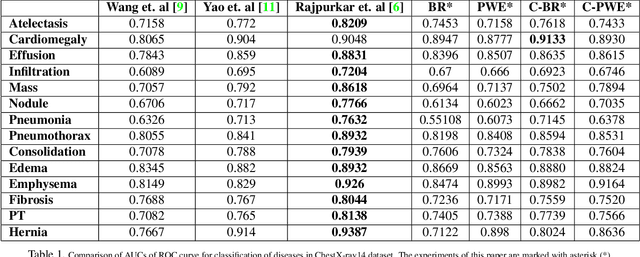
Chest X-ray is one of the most accessible medical imaging technique for diagnosis of multiple diseases. With the availability of ChestX-ray14, which is a massive dataset of chest X-ray images and provides annotations for 14 thoracic diseases; it is possible to train Deep Convolutional Neural Networks (DCNN) to build Computer Aided Diagnosis (CAD) systems. In this work, we experiment a set of deep learning models and present a cascaded deep neural network that can diagnose all 14 pathologies better than the baseline and is competitive with other published methods. Our work provides the quantitative results to answer following research questions for the dataset: 1) What loss functions to use for training DCNN from scratch on ChestX-ray14 dataset that demonstrates high class imbalance and label co occurrence? 2) How to use cascading to model label dependency and to improve accuracy of the deep learning model?
Detection of Tooth caries in Bitewing Radiographs using Deep Learning
Nov 23, 2017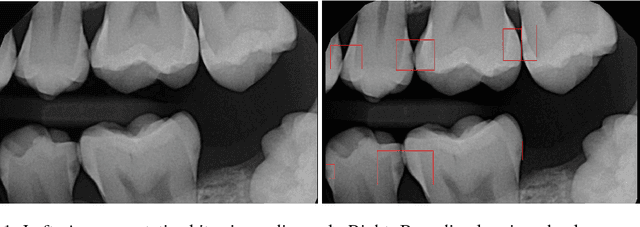
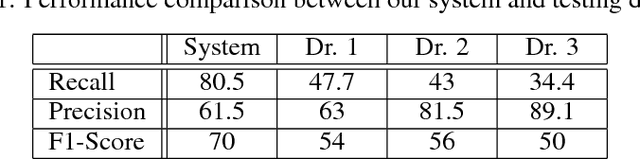
We develop a Computer Aided Diagnosis (CAD) system, which enhances the performance of dentists in detecting wide range of dental caries. The CAD System achieves this by acting as a second opinion for the dentists with way higher sensitivity on the task of detecting cavities than the dentists themselves. We develop annotated dataset of more than 3000 bitewing radiographs and utilize it for developing a system for automated diagnosis of dental caries. Our system consists of a deep fully convolutional neural network (FCNN) consisting 100+ layers, which is trained to mark caries on bitewing radiographs. We have compared the performance of our proposed system with three certified dentists for marking dental caries. We exceed the average performance of the dentists in both recall (sensitivity) and F1-Score (agreement with truth) by a very large margin. Working example of our system is shown in Figure 1.
Content Based Document Recommender using Deep Learning
Oct 23, 2017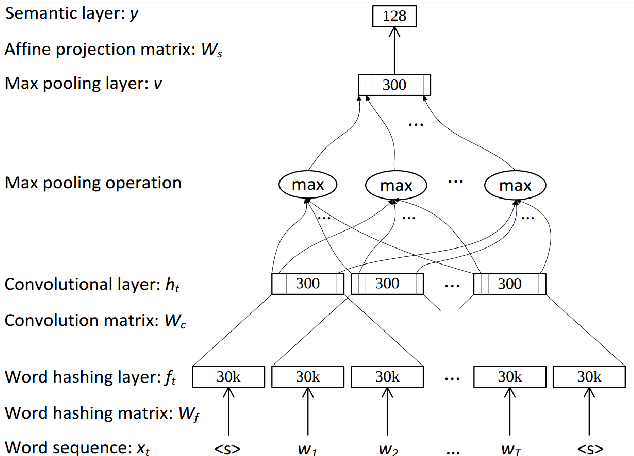
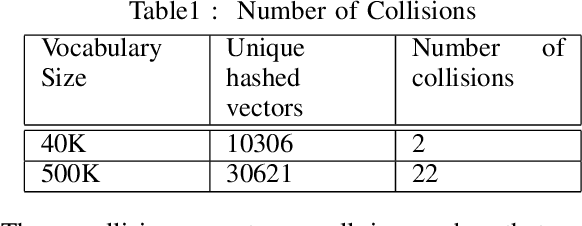
With the recent advancements in information technology there has been a huge surge in amount of data available. But information retrieval technology has not been able to keep up with this pace of information generation resulting in over spending of time for retrieving relevant information. Even though systems exist for assisting users to search a database along with filtering and recommending relevant information, but recommendation system which uses content of documents for recommendation still have a long way to mature. Here we present a Deep Learning based supervised approach to recommend similar documents based on the similarity of content. We combine the C-DSSM model with Word2Vec distributed representations of words to create a novel model to classify a document pair as relevant/irrelavant by assigning a score to it. Using our model retrieval of documents can be done in O(1) time and the memory complexity is O(n), where n is number of documents.
Testing the limits of unsupervised learning for semantic similarity
Oct 23, 2017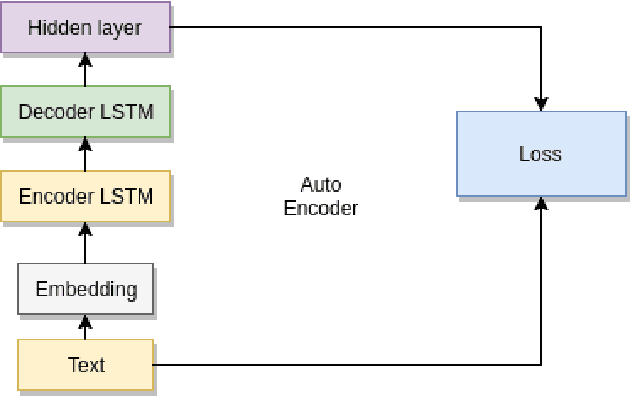
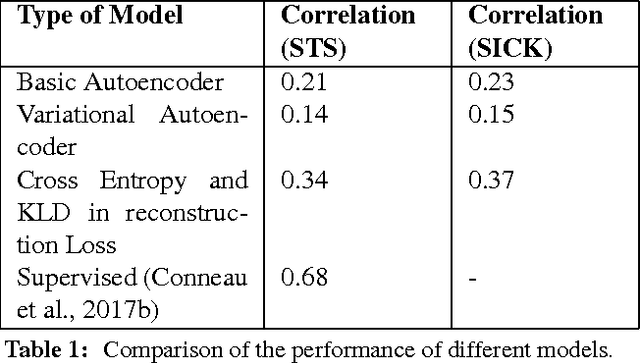
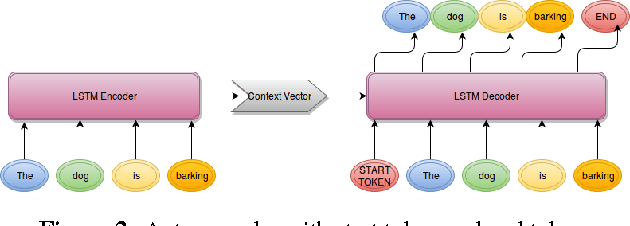
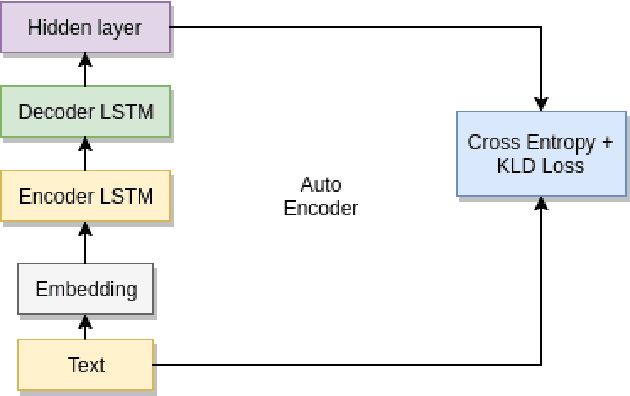
Semantic Similarity between two sentences can be defined as a way to determine how related or unrelated two sentences are. The task of Semantic Similarity in terms of distributed representations can be thought to be generating sentence embeddings (dense vectors) which take both context and meaning of sentence in account. Such embeddings can be produced by multiple methods, in this paper we try to evaluate LSTM auto encoders for generating these embeddings. Unsupervised algorithms (auto encoders to be specific) just try to recreate their inputs, but they can be forced to learn order (and some inherent meaning to some extent) by creating proper bottlenecks. We try to evaluate how properly can algorithms trained just on plain English Sentences learn to figure out Semantic Similarity, without giving them any sense of what meaning of a sentence is.