 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuktabh Mayank Srivastava
Benchmark for Generic Product Detection: A strong baseline for Dense Object Detection
Dec 19, 2019
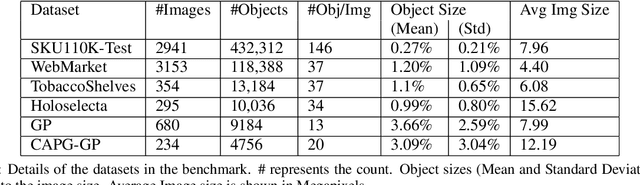

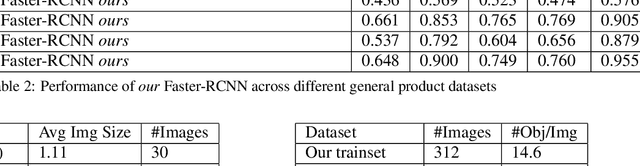

Object detection in densely packed scenes is a new area where standard object detectors fail to train well (Goldman et al., 2019). We show that the performance of the standard object detectors on densely packed scenes is superior when it is trained on normal scenes rather than dense scenes. We train a standard object detector on a small, normally packed dataset with data augmentation techniques. This achieves significantly better results than state-of-the-art methods that are trained on densely packed scenes. We obtain 68.5% mAP on SKU110K dataset (Goldman et al., 2019), 19.3% higher and 1.4x better than the previous state-of-the-art. We also create a varied benchmark for generic SKU product detection by providing full annotations for multiple public datasets. It can be accessed at this [URL](https://github.com/ParallelDots/generic-sku-detection-benchmark). We hope that this benchmark helps in building robust detectors that perform reliably across different settings.
Prototypical Metric Transfer Learning for Continuous Speech Keyword Spotting With Limited Training Data
Jan 12, 2019
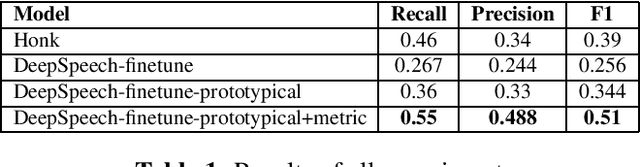
Continuous Speech Keyword Spotting (CSKS) is the problem of spotting keywords in recorded conversations, when a small number of instances of keywords are available in training data. Unlike the more common Keyword Spotting, where an algorithm needs to detect lone keywords or short phrases like "Alexa", "Cortana", "Hi Alexa!", "Whatsup Octavia?" etc. in speech, CSKS needs to filter out embedded words from a continuous flow of speech, ie. spot "Anna" and "github" in "I know a developer named Anna who can look into this github issue." Apart from the issue of limited training data availability, CSKS is an extremely imbalanced classification problem. We address the limitations of simple keyword spotting baselines for both aforementioned challenges by using a novel combination of loss functions (Prototypical networks' loss and metric loss) and transfer learning. Our method improves F1 score by over 10%.
Multidomain Document Layout Understanding using Few Shot Object Detection
Aug 22, 2018
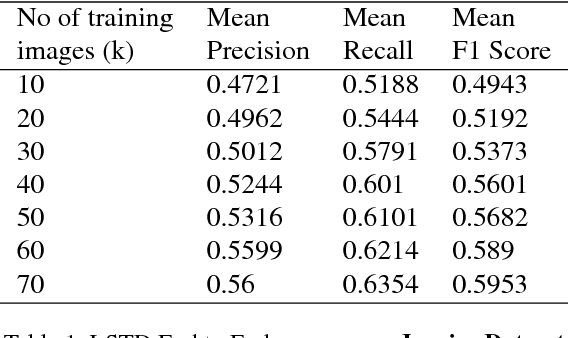
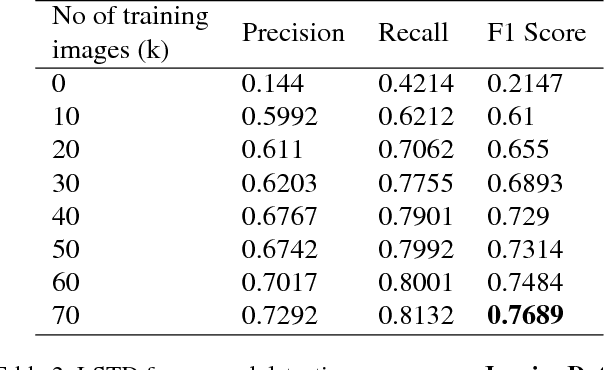
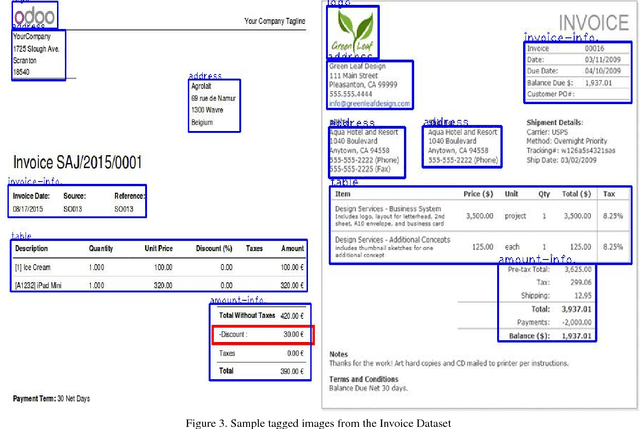
We try to address the problem of document layout understanding using a simple algorithm which generalizes across multiple domains while training on just few examples per domain. We approach this problem via supervised object detection method and propose a methodology to overcome the requirement of large datasets. We use the concept of transfer learning by pre-training our object detector on a simple artificial (source) dataset and fine-tuning it on a tiny domain specific (target) dataset. We show that this methodology works for multiple domains with training samples as less as 10 documents. We demonstrate the effect of each component of the methodology in the end result and show the superiority of this methodology over simple object detectors.
Example Mining for Incremental Learning in Medical Imaging
Jul 24, 2018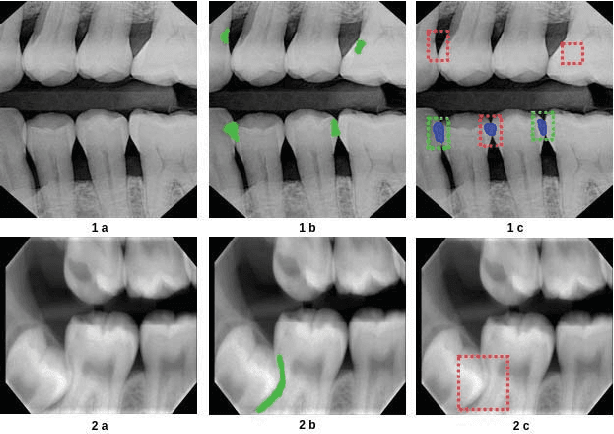
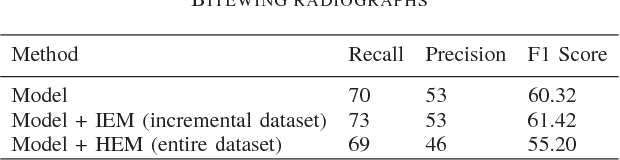

Incremental Learning is well known machine learning approach wherein the weights of the learned model are dynamically and gradually updated to generalize on new unseen data without forgetting the existing knowledge. Incremental learning proves to be time as well as resource-efficient solution for deployment of deep learning algorithms in real world as the model can automatically and dynamically adapt to new data as and when annotated data becomes available. The development and deployment of Computer Aided Diagnosis (CAD) tools in medical domain is another scenario, where incremental learning becomes very crucial as collection and annotation of a comprehensive dataset spanning over multiple pathologies and imaging machines might take years. However, not much has so far been explored in this direction. In the current work, we propose a robust and efficient method for incremental learning in medical imaging domain. Our approach makes use of Hard Example Mining technique (which is commonly used as a solution to heavy class imbalance) to automatically select a subset of dataset to fine-tune the existing network weights such that it adapts to new data while retaining existing knowledge. We develop our approach for incremental learning of our already under test model for detecting dental caries. Further, we apply our approach to one publicly available dataset and demonstrate that our approach reaches the accuracy of training on entire dataset at once, while availing the benefits of incremental learning scenario.
Binarizer at SemEval-2018 Task 3: Parsing dependency and deep learning for irony detection
May 03, 2018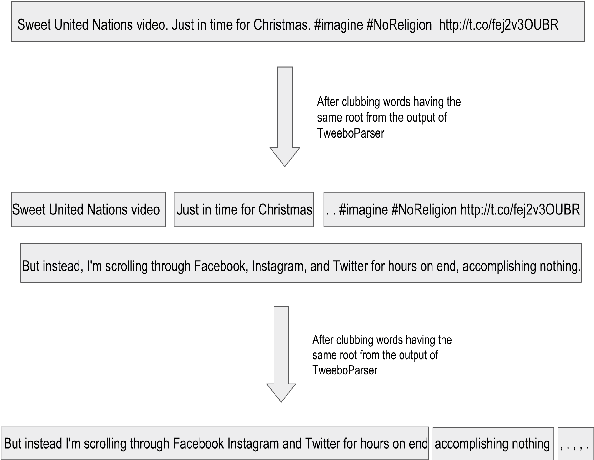
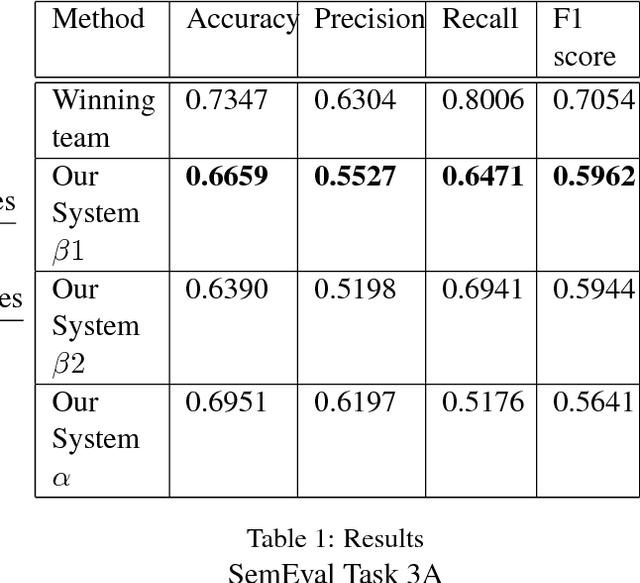

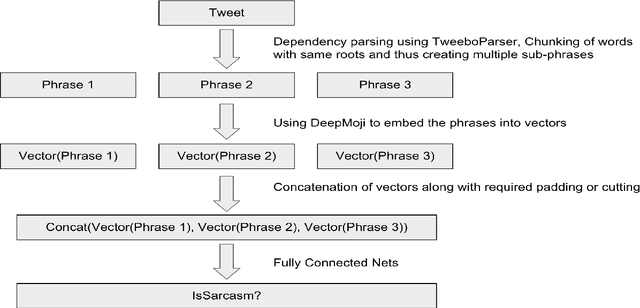
In this paper, we describe the system submitted for the SemEval 2018 Task 3 (Irony detection in English tweets) Subtask A by the team Binarizer. Irony detection is a key task for many natural language processing works. Our method treats ironical tweets to consist of smaller parts containing different emotions. We break down tweets into separate phrases using a dependency parser. We then embed those phrases using an LSTM-based neural network model which is pre-trained to predict emoticons for tweets. Finally, we train a fully-connected network to achieve classification.
Weakly Supervised Object Localization on grocery shelves using simple FCN and Synthetic Dataset
Mar 19, 2018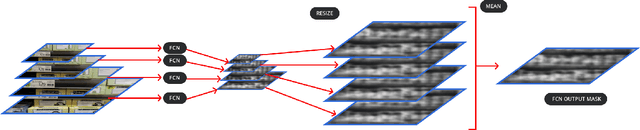



We propose a weakly supervised method using two algorithms to predict object bounding boxes given only an image classification dataset. First algorithm is a simple Fully Convolutional Network (FCN) trained to classify object instances. We use the property of FCN to return a mask for images larger than training images to get a primary output segmentation mask during test time by passing an image pyramid to it. We enhance the FCN output mask into final output bounding boxes by a Convolutional Encoder-Decoder (ConvAE) viz. the second algorithm. ConvAE is trained to localize objects on an artificially generated dataset of output segmentation masks. We demonstrate the effectiveness of this method in localizing objects in grocery shelves where annotating data for object detection is hard due to variety of objects. This method can be extended to any problem domain where collecting images of objects is easy and annotating their coordinates is hard.
Visual aesthetic analysis using deep neural network: model and techniques to increase accuracy without transfer learning
Jan 31, 2018
We train a deep Convolutional Neural Network (CNN) from scratch for visual aesthetic analysis in images and discuss techniques we adopt to improve the accuracy. We avoid the prevalent best transfer learning approaches of using pretrained weights to perform the task and train a model from scratch to get accuracy of 78.7% on AVA2 Dataset close to the best models available (85.6%). We further show that accuracy increases to 81.48% on increasing the training set by incremental 10 percentile of entire AVA dataset showing our algorithm gets better with more data.
Anatomical labeling of brain CT scan anomalies using multi-context nearest neighbor relation networks
Jan 22, 2018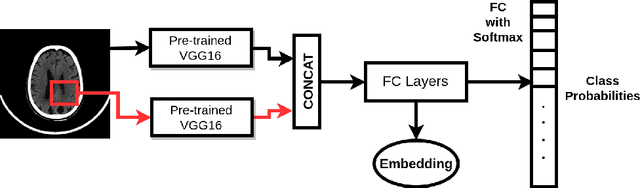
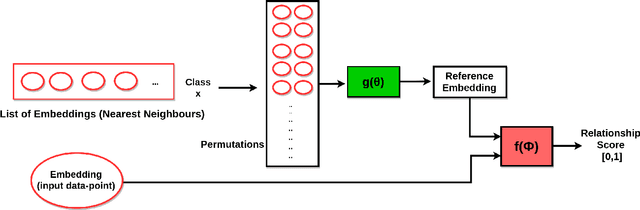
This work is an endeavor to develop a deep learning methodology for automated anatomical labeling of a given region of interest (ROI) in brain computed tomography (CT) scans. We combine both local and global context to obtain a representation of the ROI. We then use Relation Networks (RNs) to predict the corresponding anatomy of the ROI based on its relationship score for each class. Further, we propose a novel strategy employing nearest neighbors approach for training RNs. We train RNs to learn the relationship of the target ROI with the joint representation of its nearest neighbors in each class instead of all data-points in each class. The proposed strategy leads to better training of RNs along with increased performance as compared to training baseline RN network.
Towards Automated Tuberculosis detection using Deep Learning
Jan 22, 2018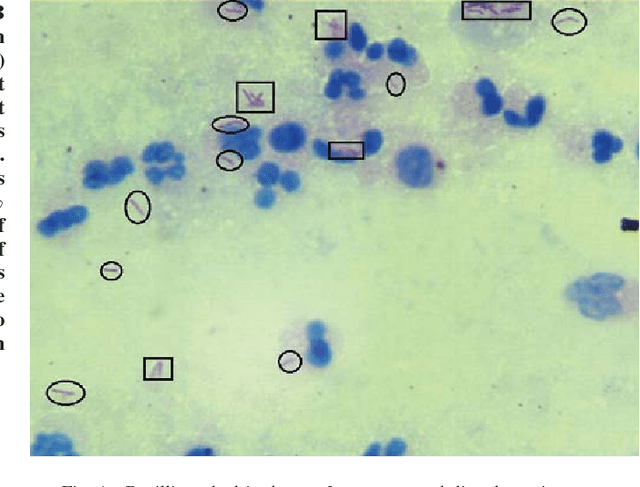
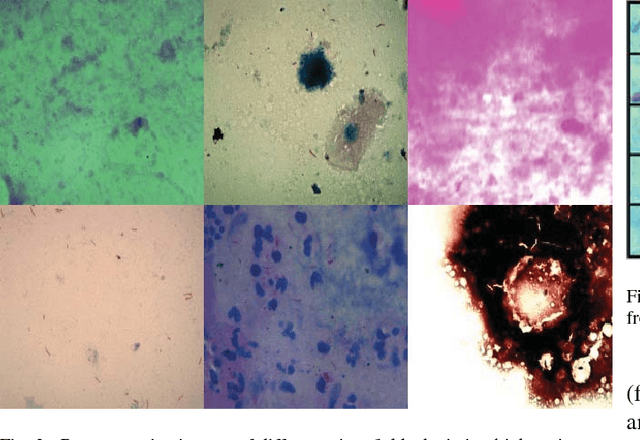
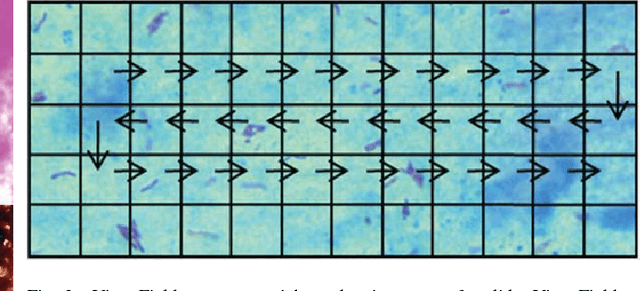
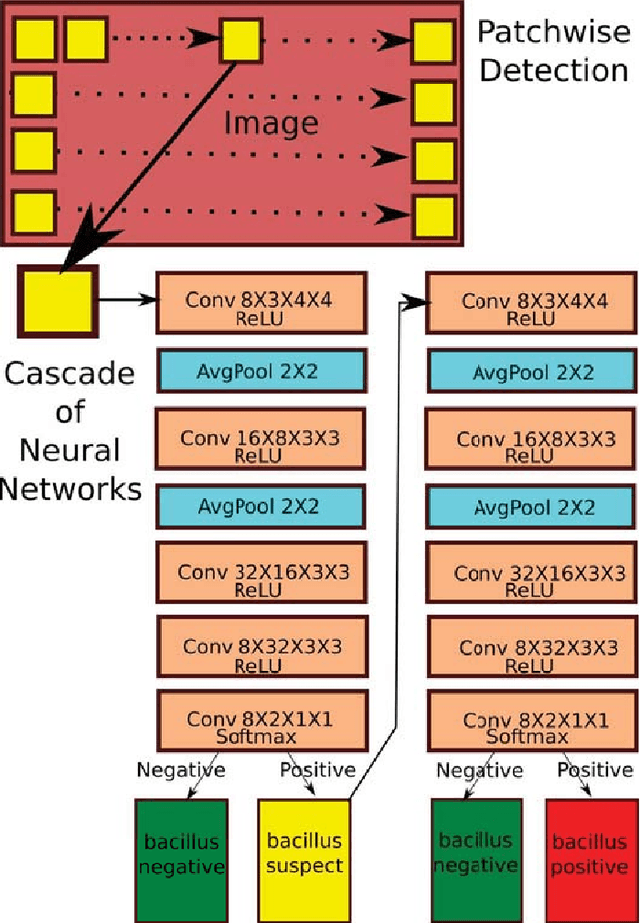
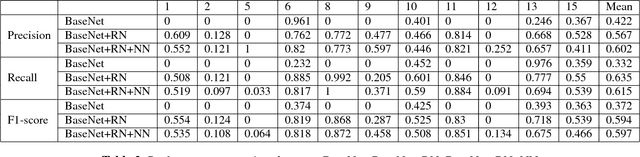
Tuberculosis(TB) in India is the world's largest TB epidemic. TB leads to 480,000 deaths every year. Between the years 2006 and 2014, Indian economy lost US$340 Billion due to TB. This combined with the emergence of drug resistant bacteria in India makes the problem worse. The government of India has hence come up with a new strategy which requires a high-sensitivity microscopy based TB diagnosis mechanism. We propose a new Deep Neural Network based drug sensitive TB detection methodology with recall and precision of 83.78% and 67.55% respectively for bacillus detection. This method takes a microscopy image with proper zoom level as input and returns location of suspected TB germs as output. The high accuracy of our method gives it the potential to evolve into a high sensitivity system to diagnose TB when trained at scale.
RADNET: Radiologist Level Accuracy using Deep Learning for HEMORRHAGE detection in CT Scans
Jan 03, 2018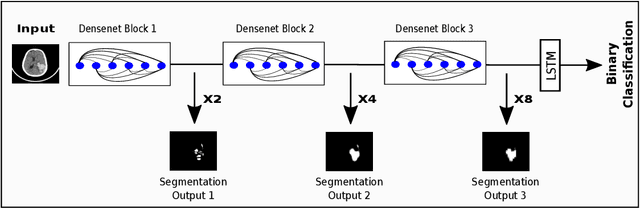
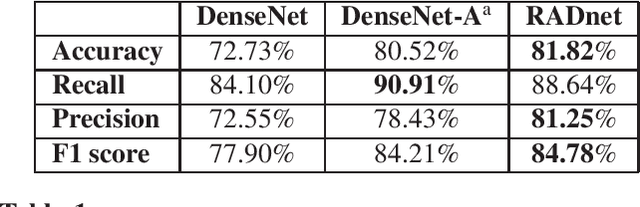
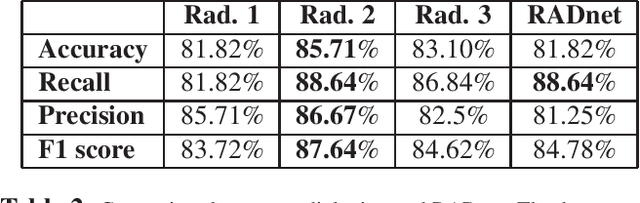
We describe a deep learning approach for automated brain hemorrhage detection from computed tomography (CT) scans. Our model emulates the procedure followed by radiologists to analyse a 3D CT scan in real-world. Similar to radiologists, the model sifts through 2D cross-sectional slices while paying close attention to potential hemorrhagic regions. Further, the model utilizes 3D context from neighboring slices to improve predictions at each slice and subsequently, aggregates the slice-level predictions to provide diagnosis at CT level. We refer to our proposed approach as Recurrent Attention DenseNet (RADnet) as it employs original DenseNet architecture along with adding the components of attention for slice level predictions and recurrent neural network layer for incorporating 3D context. The real-world performance of RADnet has been benchmarked against independent analysis performed by three senior radiologists for 77 brain CTs. RADnet demonstrates 81.82% hemorrhage prediction accuracy at CT level that is comparable to radiologists. Further, RADnet achieves higher recall than two of the three radiologists, which is remarkable.