 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoders and Decoders for Quantum Expander Codes Using Machine Learning
Sep 06, 2019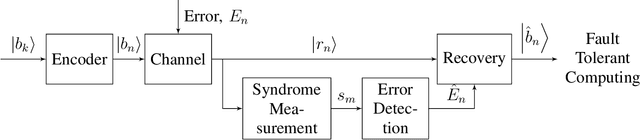
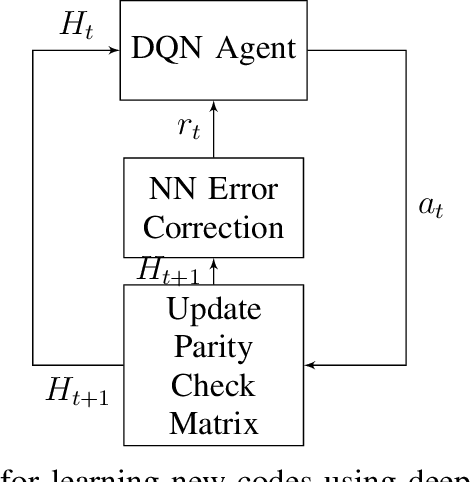
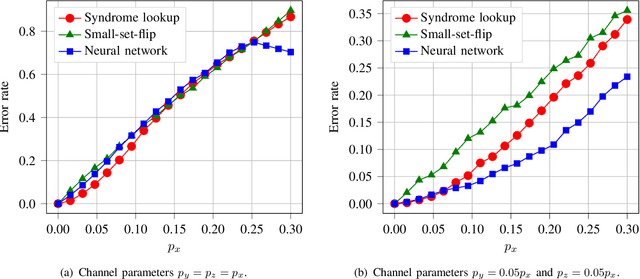
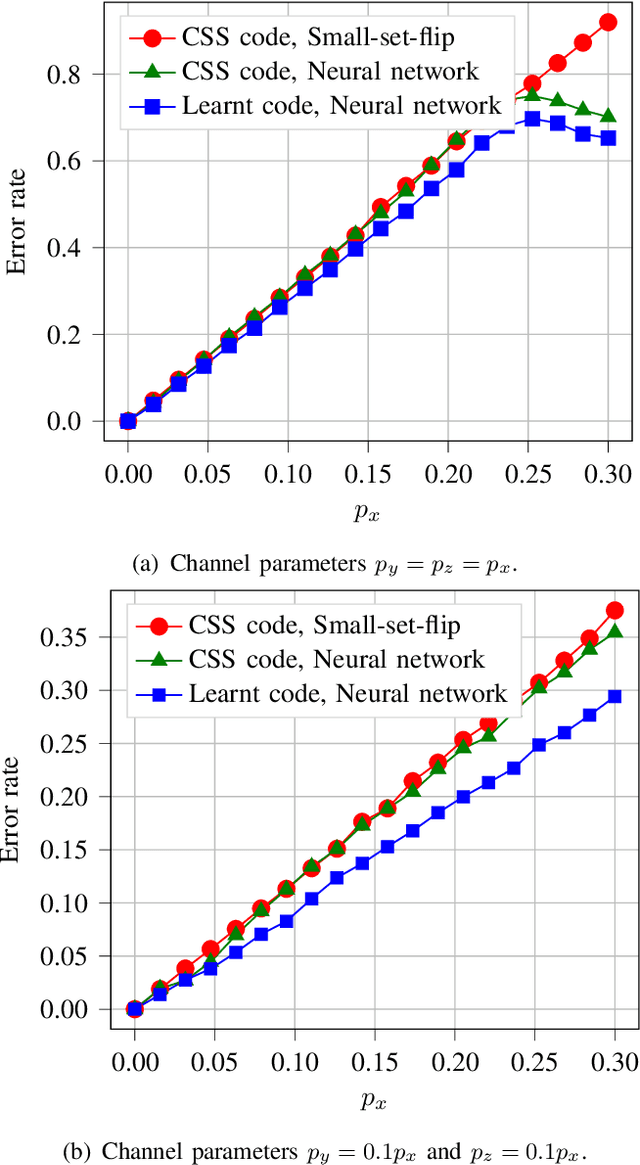
Quantum key distribution (QKD) allows two distant parties to share encryption keys with security based on laws of quantum mechanics. In order to share the keys, the quantum bits have to be transmitted from the sender to the receiver over a noisy quantum channel. In order to transmit this information, efficient encoders and decoders need to be designed. However, large-scale design of quantum encoders and decoders have to depend on the channel characteristics and require look-up tables which require memory that is exponential in the number of qubits. In order to alleviate that, this paper aims to design the quantum encoders and decoders for expander codes by adapting techniques from machine learning including reinforcement learning and neural networks to the quantum domain. The proposed quantum decoder trains a neural network which is trained using the maximum aposteriori error for the syndromes, eliminating the use of large lookup tables. The quantum encoder uses deep Q-learning based techniques to optimize the generator matrices in the quantum Calderbank-Shor-Steane (CSS) codes. The evaluation results demonstrate improved performance of the proposed quantum encoder and decoder designs as compared to the quantum expander codes.
A Reinforcement Learning Based Approach for Joint Multi-Agent Decision Making
Sep 06, 2019
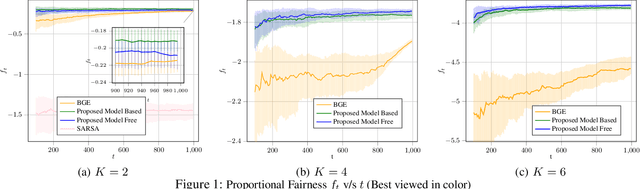
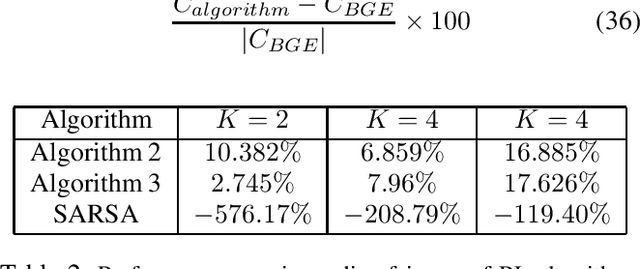
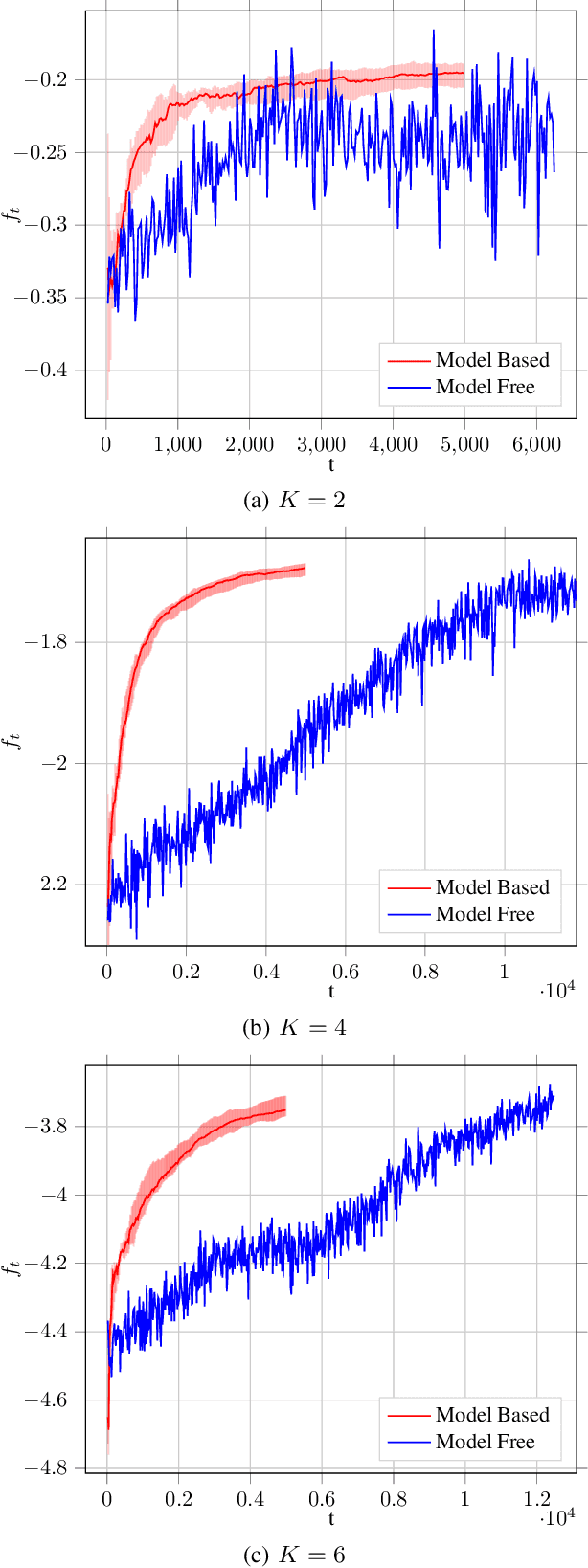
Reinforcement Learning (RL) is being increasingly applied to optimize complex functions that may have a stochastic component. RL is extended to multi-agent systems to find policies to optimize systems that require agents to coordinate or to compete under the umbrella of Multi-Agent RL (MARL). A crucial factor in the success of RL is that the optimization problem is represented as the expected sum of rewards, which allows the use of backward induction for the solution. However, many real-world problems require a joint objective that is non-linear and dynamic programming cannot be applied directly. For example, in a resource allocation problem, one of the objective is to maximize long-term fairness among the users. This paper addresses and formalizes the problem of joint objective optimization, where not only the sum of rewards of each agent but a function of the sum of rewards of each agent needs to be optimized. The proposed algorithms at the centralized controller aims to learn the policy to dictate the actions for each agent such that the joint objective function based on average per step rewards of each agent is maximized. We propose both model-based and model-free algorithms, where the model-based algorithm is shown to achieve $\Tilde{O}(\sqrt{\frac{K}{T}})$ regret bound for $K$ agents over a time-horizon $T$, and the model-free algorithm can be implemented using deep neural networks. Further, using fairness in cellular base-station scheduling as an example, the proposed algorithms are shown to significantly outperform the state-of-the-art approaches.
Regret Bounds for Stochastic Combinatorial Multi-Armed Bandits with Linear Space Complexity
Nov 29, 2018
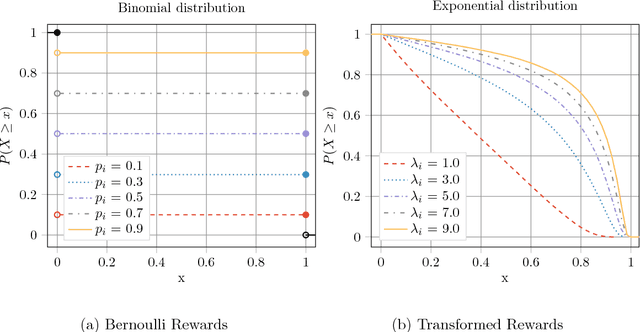
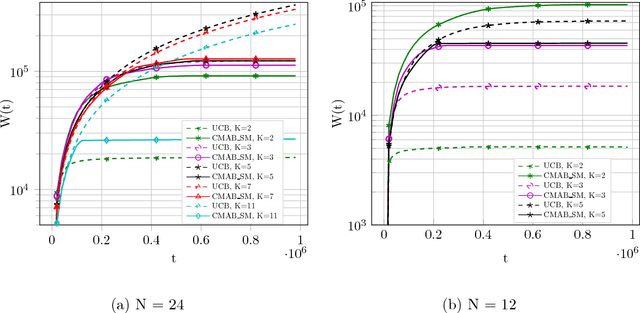
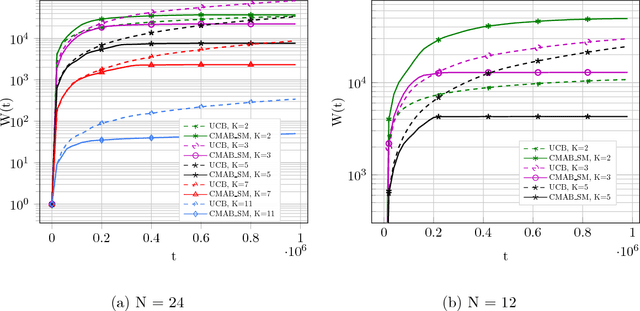
Many real-world problems face the dilemma of choosing best $K$ out of $N$ options at a given time instant. This setup can be modelled as combinatorial bandit which chooses $K$ out of $N$ arms at each time, with an aim to achieve an efficient tradeoff between exploration and exploitation. This is the first work for combinatorial bandit where the reward received can be a non-linear function of the chosen $K$ arms. The direct use of multi-armed bandit requires choosing among $N$-choose-$K$ options making the state space large. In this paper, we present a novel algorithm which is computationally efficient and the storage is linear in $N$. The proposed algorithm is a divide-and-conquer based strategy, that we call CMAB-SM. Further, the proposed algorithm achieves a regret bound of $\tilde O(K^\frac{1}{2}N^\frac{1}{3}T^\frac{2}{3})$ for a time horizon $T$, which is sub-linear in all parameters $T$, $N$, and $K$. The evaluation results on different reward functions and arm distribution functions show significantly improved performance as compared to standard multi-armed bandit approach with $\binom{N}{K}$ choices.