 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss and Reward Weighing for increased learning in Distributed Reinforcement Learning
Apr 25, 2023



This paper introduces two learning schemes for distributed agents in Reinforcement Learning (RL) environments, namely Reward-Weighted (R-Weighted) and Loss-Weighted (L-Weighted) gradient merger. The R/L weighted methods replace standard practices for training multiple agents, such as summing or averaging the gradients. The core of our methods is to scale the gradient of each actor based on how high the reward (for R-Weighted) or the loss (for L-Weighted) is compared to the other actors. During training, each agent operates in differently initialized versions of the same environment, which gives different gradients from different actors. In essence, the R-Weights and L-Weights of each agent inform the other agents of its potential, which again reports which environment should be prioritized for learning. This approach of distributed learning is possible because environments that yield higher rewards, or low losses, have more critical information than environments that yield lower rewards or higher losses. We empirically demonstrate that the R-Weighted methods work superior to the state-of-the-art in multiple RL environments.
Contrastive Transformer: Contrastive Learning Scheme with Transformer innate Patches
Mar 26, 2023This paper presents Contrastive Transformer, a contrastive learning scheme using the Transformer innate patches. Contrastive Transformer enables existing contrastive learning techniques, often used for image classification, to benefit dense downstream prediction tasks such as semantic segmentation. The scheme performs supervised patch-level contrastive learning, selecting the patches based on the ground truth mask, subsequently used for hard-negative and hard-positive sampling. The scheme applies to all vision-transformer architectures, is easy to implement, and introduces minimal additional memory footprint. Additionally, the scheme removes the need for huge batch sizes, as each patch is treated as an image. We apply and test Contrastive Transformer for the case of aerial image segmentation, known for low-resolution data, large class imbalance, and similar semantic classes. We perform extensive experiments to show the efficacy of the Contrastive Transformer scheme on the ISPRS Potsdam aerial image segmentation dataset. Additionally, we show the generalizability of our scheme by applying it to multiple inherently different Transformer architectures. Ultimately, the results show a consistent increase in mean IoU across all classes.
Unsupervised Representation Learning in Partially Observable Atari Games
Mar 13, 2023State representation learning aims to capture latent factors of an environment. Contrastive methods have performed better than generative models in previous state representation learning research. Although some researchers realize the connections between masked image modeling and contrastive representation learning, the effort is focused on using masks as an augmentation technique to represent the latent generative factors better. Partially observable environments in reinforcement learning have not yet been carefully studied using unsupervised state representation learning methods. In this article, we create an unsupervised state representation learning scheme for partially observable states. We conducted our experiment on a previous Atari 2600 framework designed to evaluate representation learning models. A contrastive method called Spatiotemporal DeepInfomax (ST-DIM) has shown state-of-the-art performance on this benchmark but remains inferior to its supervised counterpart. Our approach improves ST-DIM when the environment is not fully observable and achieves higher F1 scores and accuracy scores than the supervised learning counterpart. The mean accuracy score averaged over categories of our approach is ~66%, compared to ~38% of supervised learning. The mean F1 score is ~64% to ~33%.
A contrastive learning approach for individual re-identification in a wild fish population
Jan 02, 2023



In both terrestrial and marine ecology, physical tagging is a frequently used method to study population dynamics and behavior. However, such tagging techniques are increasingly being replaced by individual re-identification using image analysis. This paper introduces a contrastive learning-based model for identifying individuals. The model uses the first parts of the Inception v3 network, supported by a projection head, and we use contrastive learning to find similar or dissimilar image pairs from a collection of uniform photographs. We apply this technique for corkwing wrasse, Symphodus melops, an ecologically and commercially important fish species. Photos are taken during repeated catches of the same individuals from a wild population, where the intervals between individual sightings might range from a few days to several years. Our model achieves a one-shot accuracy of 0.35, a 5-shot accuracy of 0.56, and a 100-shot accuracy of 0.88, on our dataset.
A Comparison Between Tsetlin Machines and Deep Neural Networks in the Context of Recommendation Systems
Dec 20, 2022Recommendation Systems (RSs) are ubiquitous in modern society and are one of the largest points of interaction between humans and AI. Modern RSs are often implemented using deep learning models, which are infamously difficult to interpret. This problem is particularly exasperated in the context of recommendation scenarios, as it erodes the user's trust in the RS. In contrast, the newly introduced Tsetlin Machines (TM) possess some valuable properties due to their inherent interpretability. TMs are still fairly young as a technology. As no RS has been developed for TMs before, it has become necessary to perform some preliminary research regarding the practicality of such a system. In this paper, we develop the first RS based on TMs to evaluate its practicality in this application domain. This paper compares the viability of TMs with other machine learning models prevalent in the field of RS. We train and investigate the performance of the TM compared with a vanilla feed-forward deep learning model. These comparisons are based on model performance, interpretability/explainability, and scalability. Further, we provide some benchmark performance comparisons to similar machine learning solutions relevant to RSs.
CaiRL: A High-Performance Reinforcement Learning Environment Toolkit
Oct 03, 2022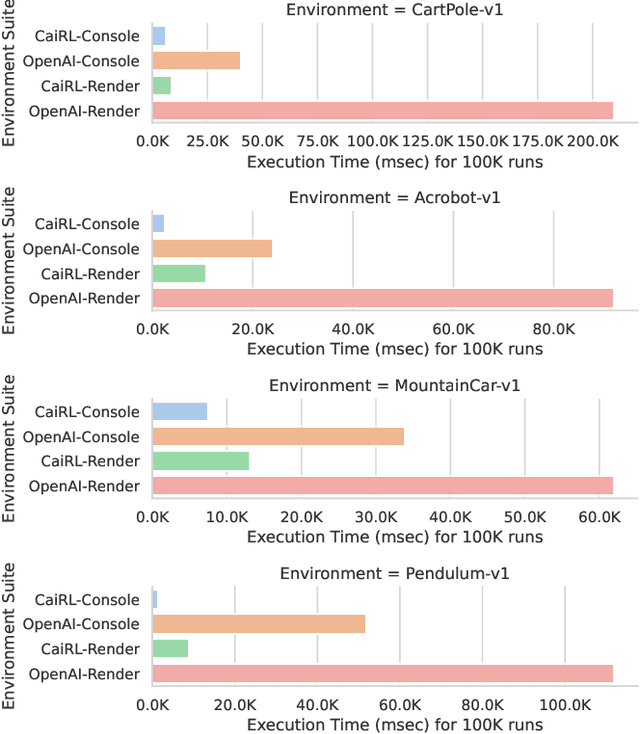
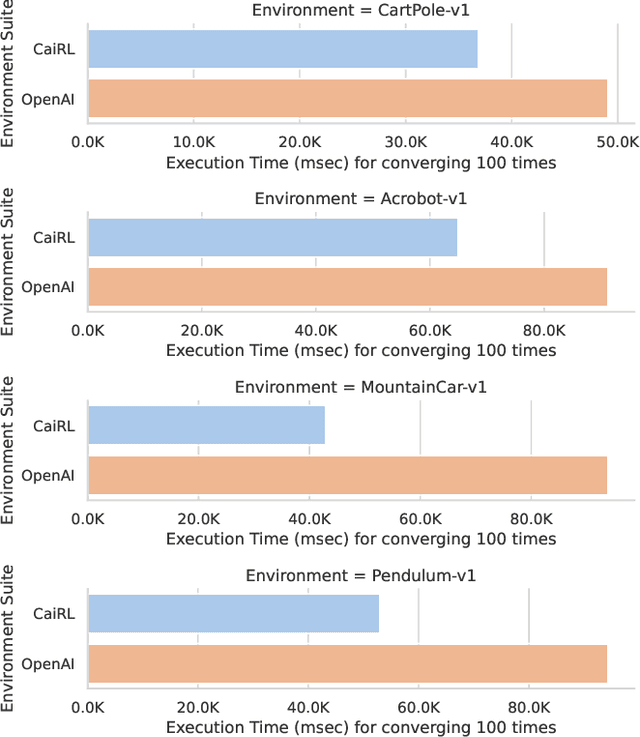
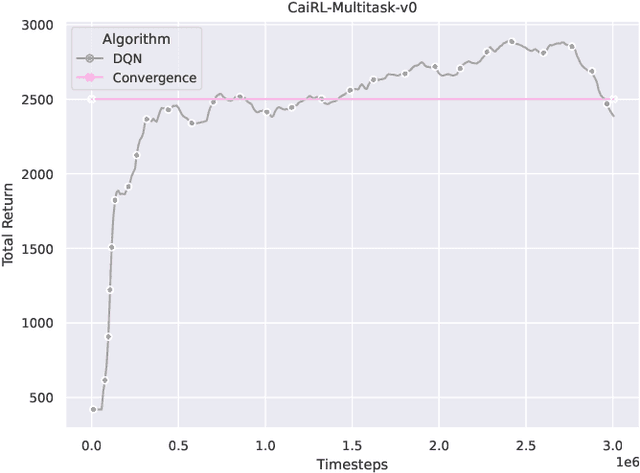
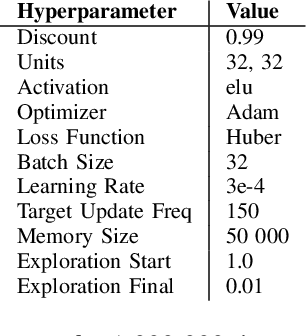
This paper addresses the dire need for a platform that efficiently provides a framework for running reinforcement learning (RL) experiments. We propose the CaiRL Environment Toolkit as an efficient, compatible, and more sustainable alternative for training learning agents and propose methods to develop more efficient environment simulations. There is an increasing focus on developing sustainable artificial intelligence. However, little effort has been made to improve the efficiency of running environment simulations. The most popular development toolkit for reinforcement learning, OpenAI Gym, is built using Python, a powerful but slow programming language. We propose a toolkit written in C++ with the same flexibility level but works orders of magnitude faster to make up for Python's inefficiency. This would drastically cut climate emissions. CaiRL also presents the first reinforcement learning toolkit with a built-in JVM and Flash support for running legacy flash games for reinforcement learning research. We demonstrate the effectiveness of CaiRL in the classic control benchmark, comparing the execution speed to OpenAI Gym. Furthermore, we illustrate that CaiRL can act as a drop-in replacement for OpenAI Gym to leverage significantly faster training speeds because of the reduced environment computation time.
* Published in 2022 IEEE Conference on Games (CoG)
CostNet: An End-to-End Framework for Goal-Directed Reinforcement Learning
Oct 03, 2022Reinforcement Learning (RL) is a general framework concerned with an agent that seeks to maximize rewards in an environment. The learning typically happens through trial and error using explorative methods, such as epsilon-greedy. There are two approaches, model-based and model-free reinforcement learning, that show concrete results in several disciplines. Model-based RL learns a model of the environment for learning the policy while model-free approaches are fully explorative and exploitative without considering the underlying environment dynamics. Model-free RL works conceptually well in simulated environments, and empirical evidence suggests that trial and error lead to a near-optimal behavior with enough training. On the other hand, model-based RL aims to be sample efficient, and studies show that it requires far less training in the real environment for learning a good policy. A significant challenge with RL is that it relies on a well-defined reward function to work well for complex environments and such a reward function is challenging to define. Goal-Directed RL is an alternative method that learns an intrinsic reward function with emphasis on a few explored trajectories that reveals the path to the goal state. This paper introduces a novel reinforcement learning algorithm for predicting the distance between two states in a Markov Decision Process. The learned distance function works as an intrinsic reward that fuels the agent's learning. Using the distance-metric as a reward, we show that the algorithm performs comparably to model-free RL while having significantly better sample-efficiently in several test environments.
* 14 pages, 5 figures, In Proceedings of the International Conference on Innovative Techniques and Applications of Artificial Intelligence, SGAI2020
Interpretable Option Discovery using Deep Q-Learning and Variational Autoencoders
Oct 03, 2022Deep Reinforcement Learning (RL) is unquestionably a robust framework to train autonomous agents in a wide variety of disciplines. However, traditional deep and shallow model-free RL algorithms suffer from low sample efficiency and inadequate generalization for sparse state spaces. The options framework with temporal abstractions is perhaps the most promising method to solve these problems, but it still has noticeable shortcomings. It only guarantees local convergence, and it is challenging to automate initiation and termination conditions, which in practice are commonly hand-crafted. Our proposal, the Deep Variational Q-Network (DVQN), combines deep generative- and reinforcement learning. The algorithm finds good policies from a Gaussian distributed latent-space, which is especially useful for defining options. The DVQN algorithm uses MSE with KL-divergence as regularization, combined with traditional Q-Learning updates. The algorithm learns a latent-space that represents good policies with state clusters for options. We show that the DVQN algorithm is a promising approach for identifying initiation and termination conditions for option-based reinforcement learning. Experiments show that the DVQN algorithm, with automatic initiation and termination, has comparable performance to Rainbow and can maintain stability when trained for extended periods after convergence.
* 12 pages, 5 figures, Proceedings of the 3rd International Conference on Intelligent Technologies and Applications
Deep Reinforcement Learning with Swin Transformer
Jun 30, 2022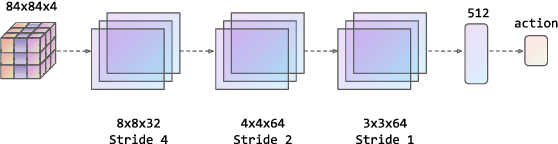
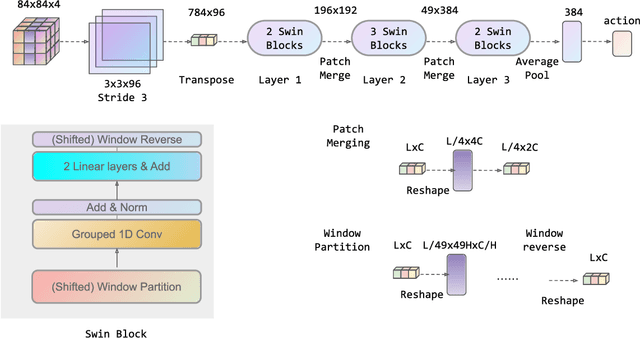
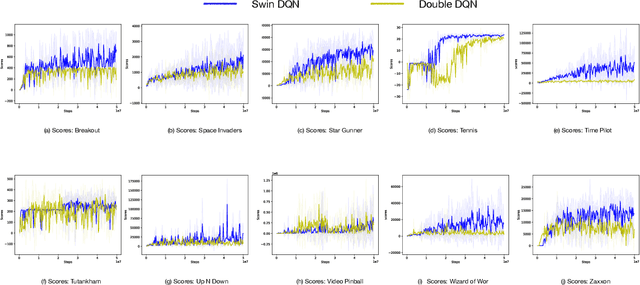
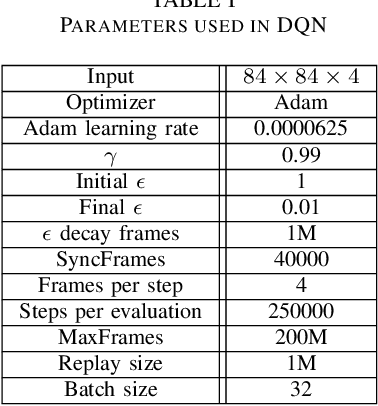
Transformers are neural network models that utilize multiple layers of self-attention heads. Attention is implemented in transformers as the contextual embeddings of the 'key' and 'query'. Transformers allow the re-combination of attention information from different layers and the processing of all inputs at once, which are more convenient than recurrent neural networks when dealt with a large number of data. Transformers have exhibited great performances on natural language processing tasks in recent years. Meanwhile, there have been tremendous efforts to adapt transformers into other fields of machine learning, such as Swin Transformer and Decision Transformer. Swin Transformer is a promising neural network architecture that splits image pixels into small patches and applies local self-attention operations inside the (shifted) windows of fixed sizes. Decision Transformer has successfully applied transformers to off-line reinforcement learning and showed that random-walk samples from Atari games are sufficient to let an agent learn optimized behaviors. However, it is considerably more challenging to combine online reinforcement learning with transformers. In this article, we further explore the possibility of not modifying the reinforcement learning policy, but only replacing the convolutional neural network architecture with the self-attention architecture from Swin Transformer. Namely, we target at changing how an agent views the world, but not how an agent plans about the world. We conduct our experiment on 49 games in Arcade Learning Environment. The results show that using Swin Transformer in reinforcement learning achieves significantly higher evaluation scores across the majority of games in Arcade Learning Environment. Thus, we conclude that online reinforcement learning can benefit from exploiting self-attentions with spatial token embeddings.
Socially Fair Mitigation of Misinformation on Social Networks via Constraint Stochastic Optimization
Mar 23, 2022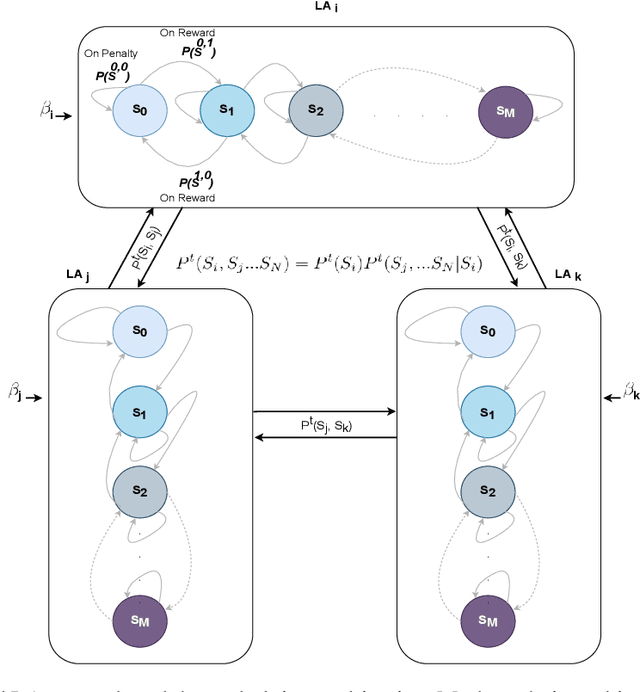
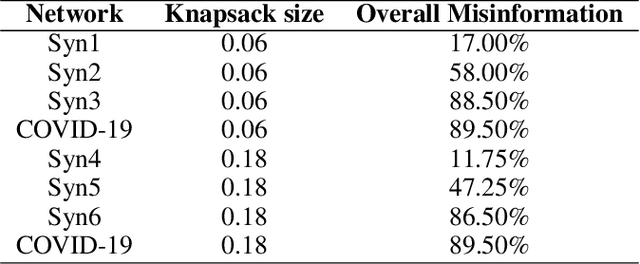
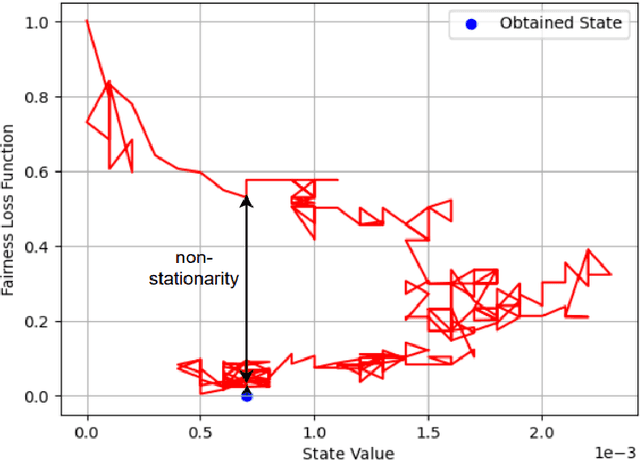
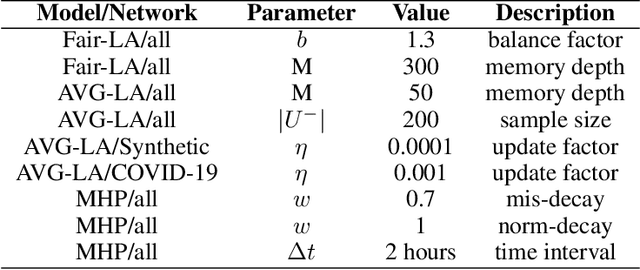
Recent social networks' misinformation mitigation approaches tend to investigate how to reduce misinformation by considering a whole-network statistical scale. However, unbalanced misinformation exposures among individuals urge to study fair allocation of mitigation resources. Moreover, the network has random dynamics which change over time. Therefore, we introduce a stochastic and non-stationary knapsack problem, and we apply its resolution to mitigate misinformation in social network campaigns. We further propose a generic misinformation mitigation algorithm that is robust to different social networks' misinformation statistics, allowing a promising impact in real-world scenarios. A novel loss function ensures fair mitigation among users. We achieve fairness by intelligently allocating a mitigation incentivization budget to the knapsack, and optimizing the loss function. To this end, a team of Learning Automata (LA) drives the budget allocation. Each LA is associated with a user and learns to minimize its exposure to misinformation by performing a non-stationary and stochastic walk over its state space. Our results show how our LA-based method is robust and outperforms similar misinformation mitigation methods in how the mitigation is fairly influencing the network users.