 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning for COVID-19 diagnosis based feature selection using binary differential evolution algorithm
Apr 15, 2021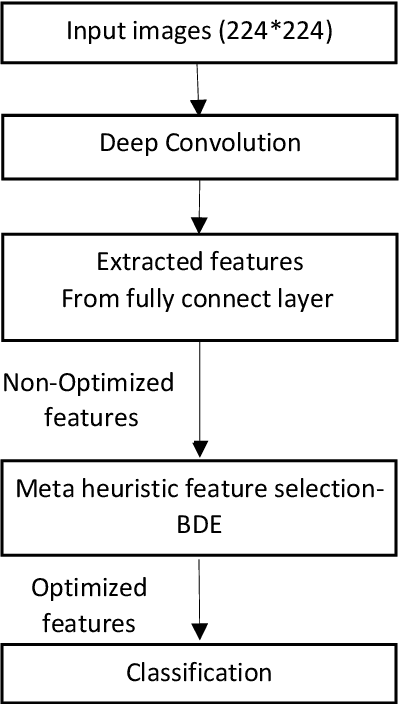
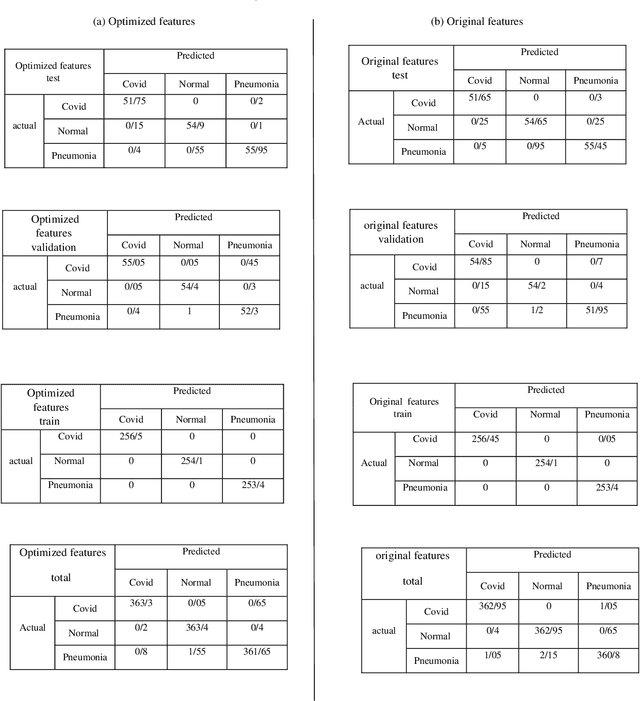
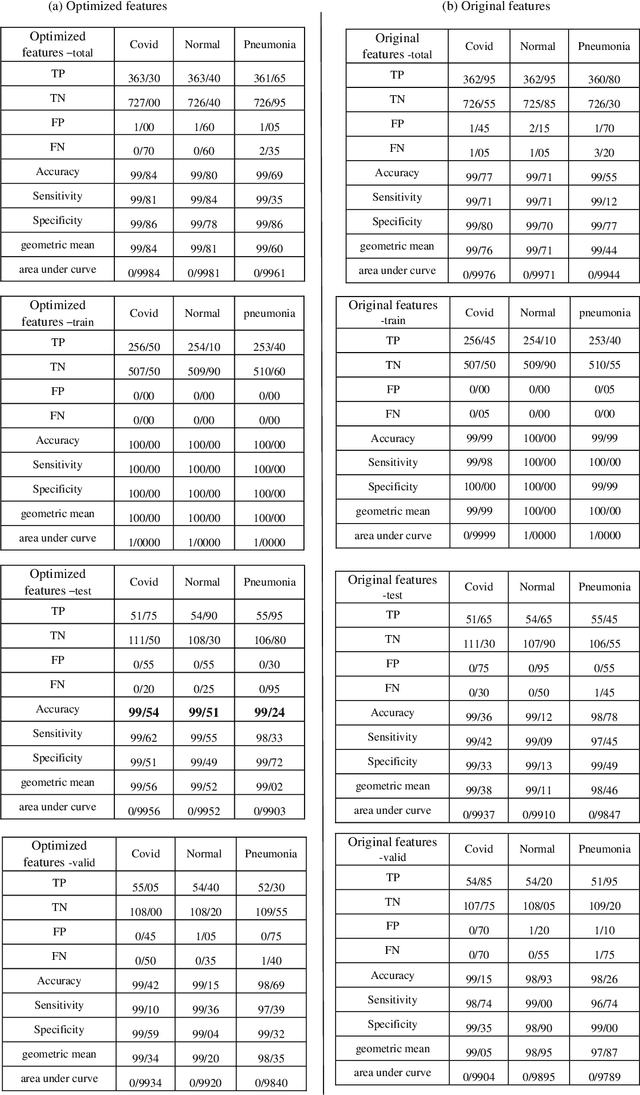
The new Coronavirus is spreading rapidly and it has taken the lives of many people so far. The virus has destructive effects on the human lung and early detection is very important. Deep Convolution neural networks are a powerful tool in classifying images. Therefore, in this paper a hybrid approach based on a deep network is presented. Feature vectors were extracted by applying a deep convolution neural network on the images and effective features were selected by the binary differential meta-heuristic algorithm. These optimized features were given to the SVM classifier. A database consisting of three categories of images as COVID-19, pneumonia, and healthy included 1092 X-ray samples was considered. The proposed method achieved an accuracy of 99.43%, a sensitivity of 99.16%, and a specificity of 99.57%. Our results demonstrate the suggested approach is better than recent studies on COVID-19 detection with X-ray images.
FRAKE: Fusional Real-time Automatic Keyword Extraction
Apr 10, 2021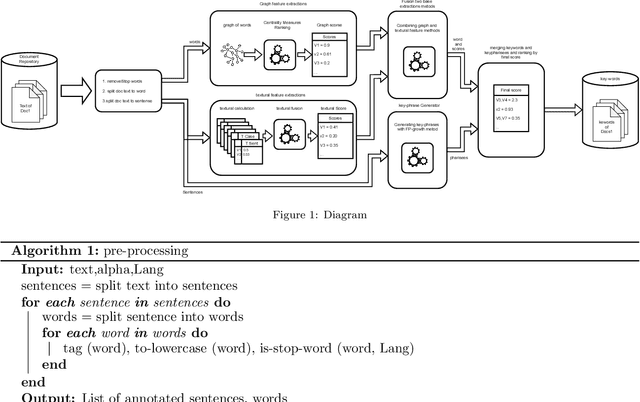
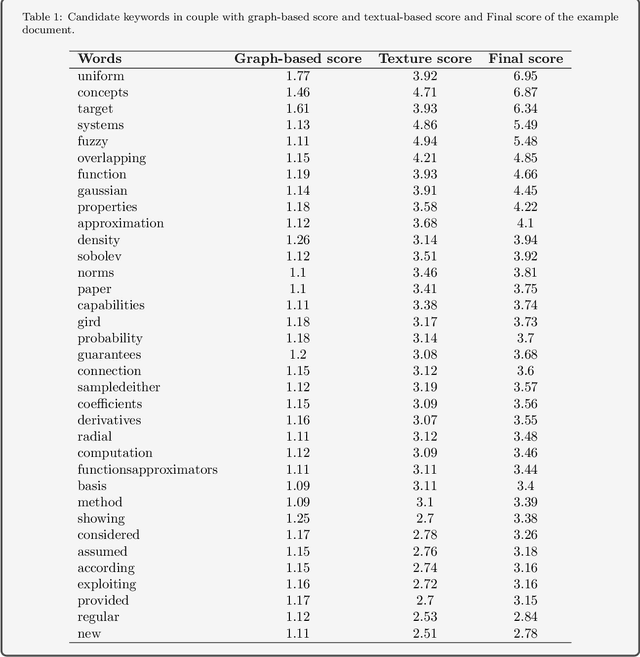

Keyword extraction is called identifying words or phrases that express the main concepts of texts in best. There is a huge amount of texts that are created every day and at all times through electronic infrastructure. So, it is practically impossible for humans to study and manage this volume of documents. However, the need for efficient and effective access to these documents is evident in various purposes. Weblogs, News, and technical notes are almost long texts, while the reader seeks to understand the concepts by topics or keywords to decide for reading the full text. To this aim, we use a combined approach that consists of two models of graph centrality features and textural features. In the following, graph centralities, such as degree, betweenness, eigenvector, and closeness centrality, have been used to optimally combine them to extract the best keyword among the candidate keywords extracted by the proposed method. Also, another approach has been introduced to distinguishing keywords among candidate phrases and considering them as a separate keyword. To evaluate the proposed method, seven datasets named, Semeval2010, SemEval2017, Inspec, fao30, Thesis100, pak2018 and WikiNews have been used, and results reported Precision, Recall, and F- measure.
TopicBERT: A Transformer transfer learning based memory-graph approach for multimodal streaming social media topic detection
Aug 16, 2020

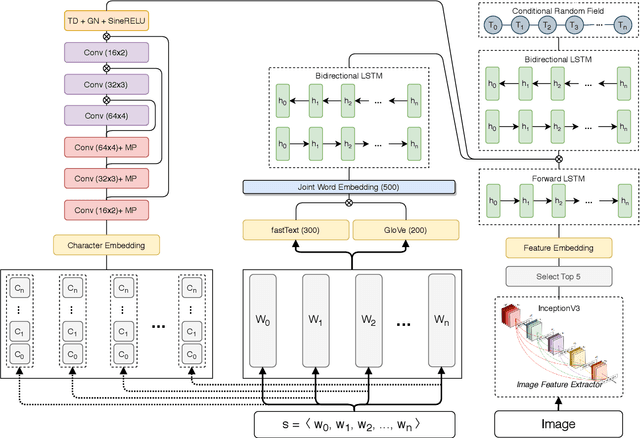

Real time nature of social networks with bursty short messages and their respective large data scale spread among vast variety of topics are research interest of many researchers. These properties of social networks which are known as 5'Vs of big data has led to many unique and enlightenment algorithms and techniques applied to large social networking datasets and data streams. Many of these researches are based on detection and tracking of hot topics and trending social media events that help revealing many unanswered questions. These algorithms and in some cases software products mostly rely on the nature of the language itself. Although, other techniques such as unsupervised data mining methods are language independent but many requirements for a comprehensive solution are not met. Many research issues such as noisy sentences that adverse grammar and new online user invented words are challenging maintenance of a good social network topic detection and tracking methodology; The semantic relationship between words and in most cases, synonyms are also ignored by many of these researches. In this research, we use Transformers combined with an incremental community detection algorithm. Transformer in one hand, provides the semantic relation between words in different contexts. On the other hand, the proposed graph mining technique enhances the resulting topics with aid of simple structural rules. Named entity recognition from multimodal data, image and text, labels the named entities with entity type and the extracted topics are tuned using them. All operations of proposed system has been applied with big social data perspective under NoSQL technologies. In order to present a working and systematic solution, we combined MongoDB with Neo4j as two major database systems of our work. The proposed system shows higher precision and recall compared to other methods in three different datasets.
Automatic Personality Prediction; an Enhanced Method Using Ensemble Modeling
Jul 09, 2020
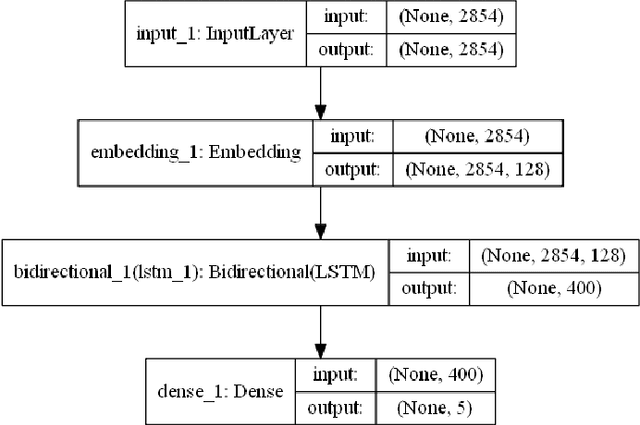
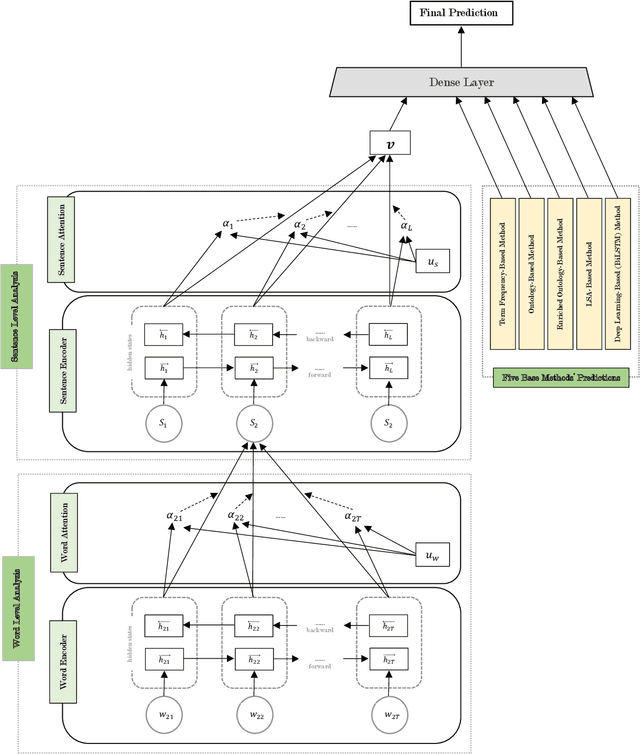
Human personality is significantly represented by those words which he/she uses in his/her speech or writing. As a consequence of spreading the information infrastructures (specifically the Internet and social media), human communications have reformed notably from face to face communication. Generally, Automatic Personality Prediction (or Perception) (APP) is the automated forecasting of the personality on different types of human generated/exchanged contents (like text, speech, image, video, etc.). The major objective of this study is to enhance the accuracy of APP from the text. To this end, we suggest five new APP methods including term frequency vector-based, ontology-based, enriched ontology-based, latent semantic analysis (LSA)-based, and deep learning-based (BiLSTM) methods. These methods as the base ones, contribute to each other to enhance the APP accuracy through ensemble modeling (stacking) based on a hierarchical attention network (HAN) as the meta-model. The results show that ensemble modeling enhances the accuracy of APP.
A Model to Measure the Spread Power of Rumors
Feb 27, 2020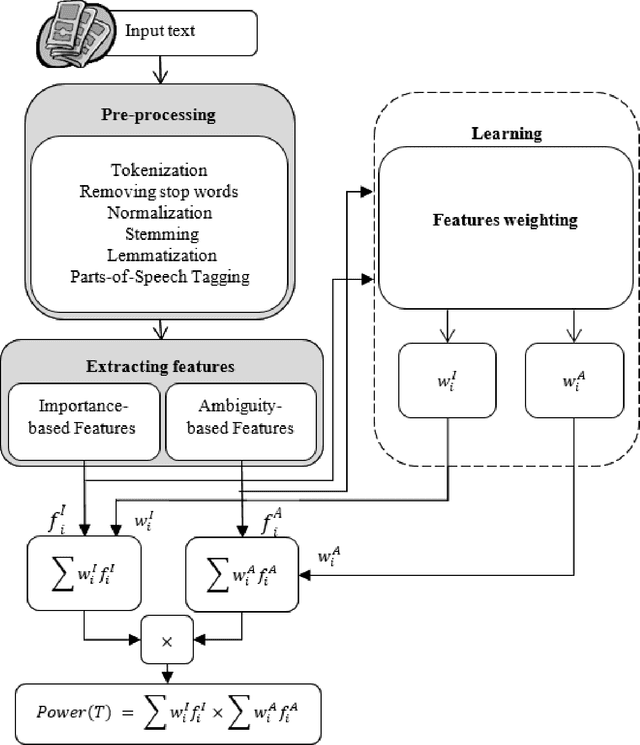
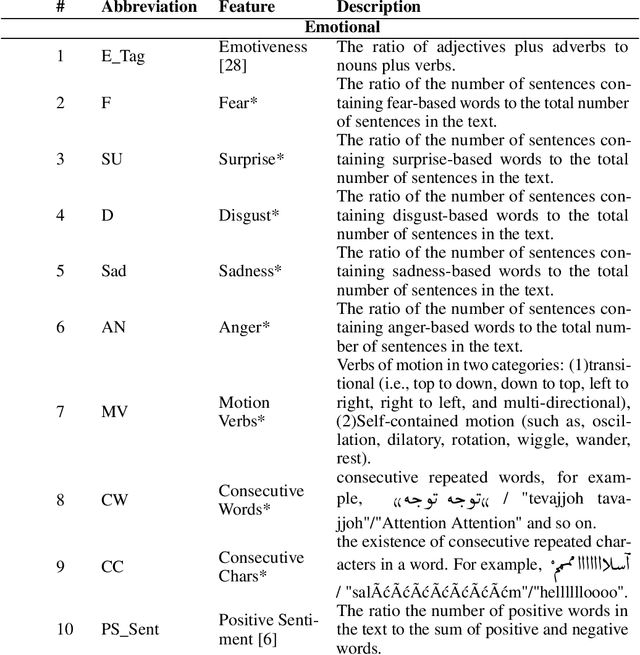
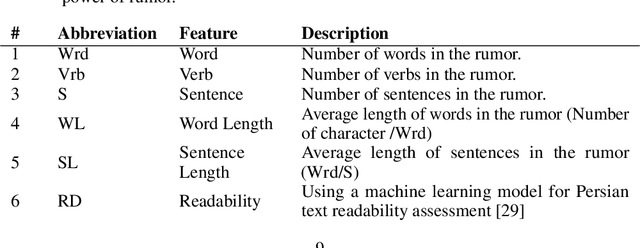

Nowadays, a significant portion of daily interacted posts in social media are infected by rumors. This study investigates the problem of rumor analysis in different areas from other researches. It tackles the unaddressed problem related to calculating the Spread Power of Rumor (SPR) for the first time and seeks to examine the spread power as the function of multi-contextual features. For this purpose, the theory of Allport and Postman will be adopted. In which it claims that there are two key factors determinant to the spread power of rumors, namely importance and ambiguity. The proposed Rumor Spread Power Measurement Model (RSPMM) computes SPR by utilizing a textual-based approach, which entails contextual features to compute the spread power of the rumors in two categories: False Rumor (FR) and True Rumor (TR). Totally 51 contextual features are introduced to measure SPR and their impact on classification are investigated, then 42 features in two categories "importance" (28 features) and "ambiguity" (14 features) are selected to compute SPR. The proposed RSPMM is verified on two labelled datasets, which are collected from Twitter and Telegram. The results show that (i) the proposed new features are effective and efficient to discriminate between FRs and TRs. (ii) the proposed RSPMM approach focused only on contextual features while existing techniques are based on Structure and Content features, but RSPMM achieves considerably outstanding results (F-measure=83%). (iii) The result of T-Test shows that SPR criteria can significantly distinguish between FR and TR, besides it can be useful as a new method to verify the trueness of rumors.
A Speech Act Classifier for Persian Texts and its Application in Identify Speech Act of Rumors
Jan 12, 2019
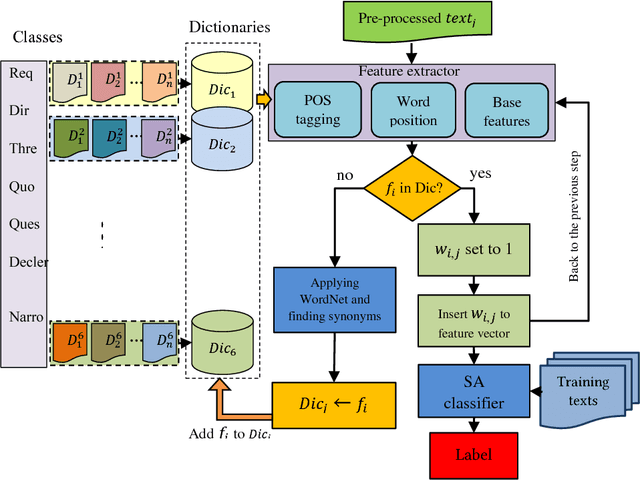


Speech Acts (SAs) are one of the important areas of pragmatics, which give us a better understanding of the state of mind of the people and convey an intended language function. Knowledge of the SA of a text can be helpful in analyzing that text in natural language processing applications. This study presents a dictionary-based statistical technique for Persian SA recognition. The proposed technique classifies a text into seven classes of SA based on four criteria: lexical, syntactic, semantic, and surface features. WordNet as the tool for extracting synonym and enriching features dictionary is utilized. To evaluate the proposed technique, we utilized four classification methods including Random Forest (RF), Support Vector Machine (SVM), Naive Bayes (NB), and K-Nearest Neighbors (KNN). The experimental results demonstrate that the proposed method using RF and SVM as the best classifiers achieved a state-of-the-art performance with an accuracy of 0.95 for classification of Persian SAs. Our original vision of this work is introducing an application of SA recognition on social media content, especially the common SA in rumors. Therefore, the proposed system utilized to determine the common SAs in rumors. The results showed that Persian rumors are often expressed in three SA classes including narrative, question, and threat, and in some cases with the request SA.
An Enhanced Multi-Objective Biogeography-Based Optimization Algorithm for Automatic Detection of Overlapping Communities in a Social Network with Node Attributes
Nov 06, 2018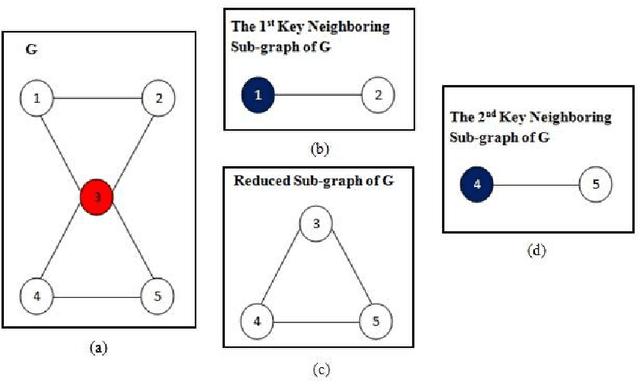
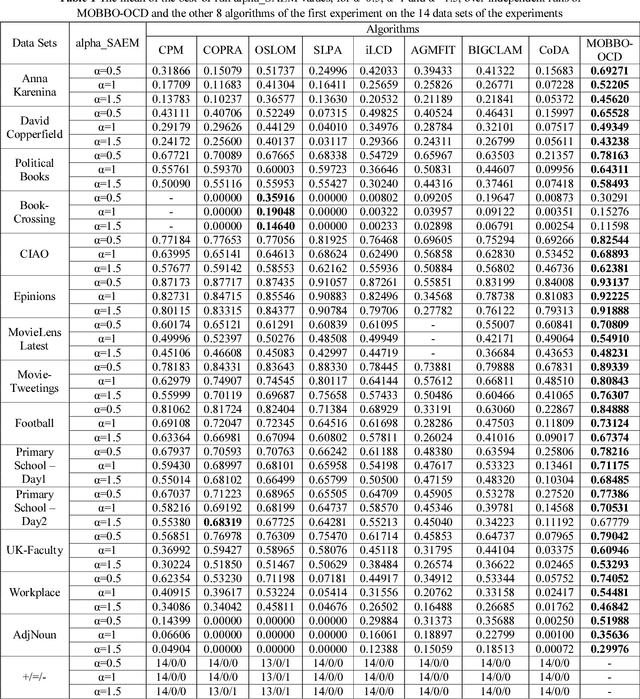
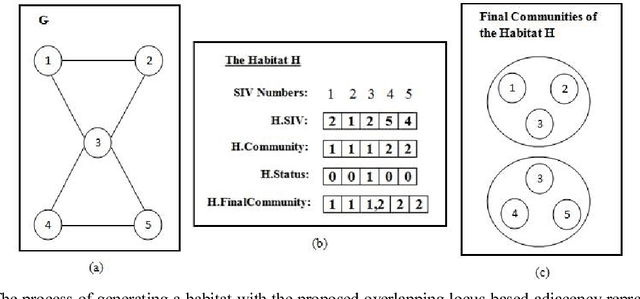
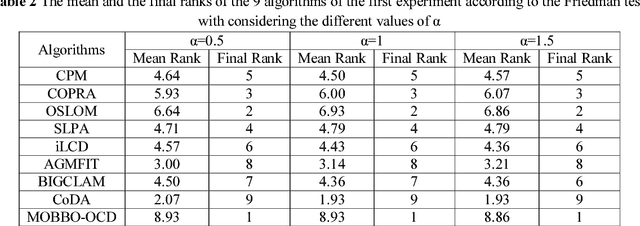
Community detection is one of the most important and interesting issues in social network analysis. In recent years, simultaneous considering of nodes' attributes and topological structures of social networks in the process of community detection has attracted the attentions of many scholars, and this consideration has been recently used in some community detection methods to increase their efficiencies and to enhance their performances in finding meaningful and relevant communities. But the problem is that most of these methods tend to find non-overlapping communities, while many real-world networks include communities that often overlap to some extent. In order to solve this problem, an evolutionary algorithm called MOBBO-OCD, which is based on multi-objective biogeography-based optimization (BBO), is proposed in this paper to automatically find overlapping communities in a social network with node attributes with synchronously considering the density of connections and the similarity of nodes' attributes in the network. In MOBBO-OCD, an extended locus-based adjacency representation called OLAR is introduced to encode and decode overlapping communities. Based on OLAR, a rank-based migration operator along with a novel two-phase mutation strategy and a new double-point crossover are used in the evolution process of MOBBO-OCD to effectively lead the population into the evolution path. In order to assess the performance of MOBBO-OCD, a new metric called alpha_SAEM is proposed in this paper, which is able to evaluate the goodness of both overlapping and non-overlapping partitions with considering the two aspects of node attributes and linkage structure. Quantitative evaluations reveal that MOBBO-OCD achieves favorable results which are quite superior to the results of 15 relevant community detection algorithms in the literature.
An improved multimodal PSO method based on electrostatic interaction using n- nearest-neighbor local search
Oct 08, 2014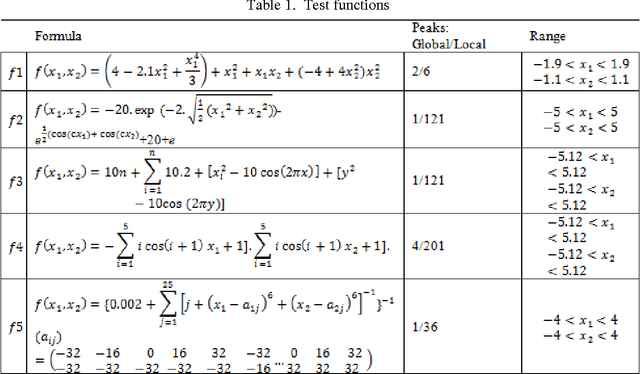
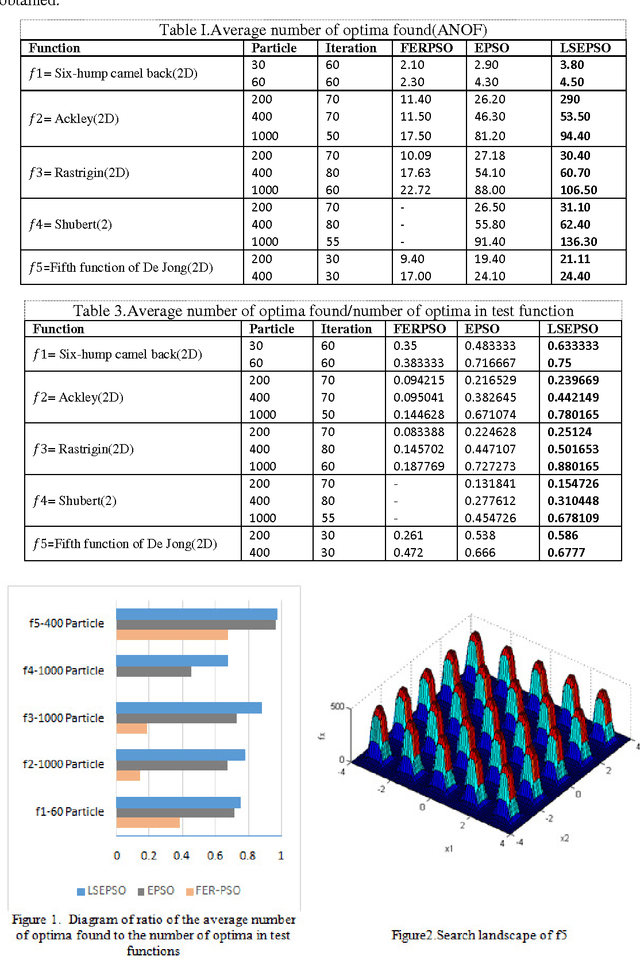
In this paper, an improved multimodal optimization (MMO) algorithm,called LSEPSO,has been proposed. LSEPSO combined Electrostatic Particle Swarm Optimization (EPSO) algorithm and a local search method and then made some modification on them. It has been shown to improve global and local optima finding ability of the algorithm. This algorithm useda modified local search to improve particle's personal best, which used n-nearest-neighbour instead of nearest-neighbour. Then, by creating n new points among each particle and n nearest particles, it tried to find a point which could be the alternative of particle's personal best. This method prevented particle's attenuation and following a specific particle by its neighbours. The performed tests on a number of benchmark functions clearly demonstrated that the improved algorithm is able to solve MMO problems and outperform other tested algorithms in this article.
Double four-bar crank-slider mechanism dynamic balancing by meta-heuristic algorithms
Oct 08, 2013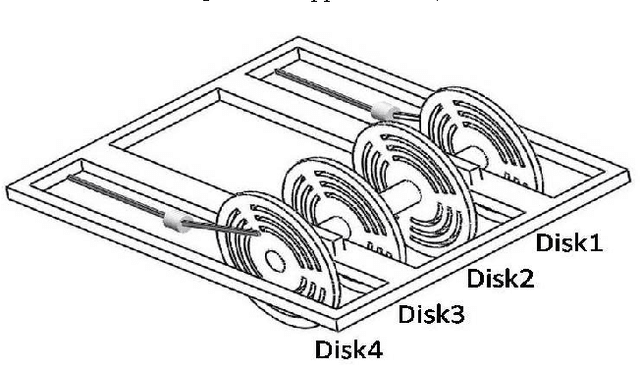
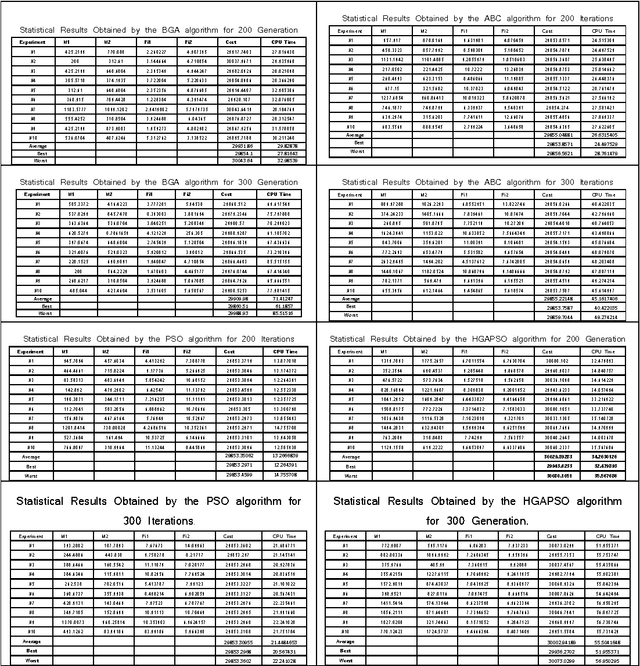
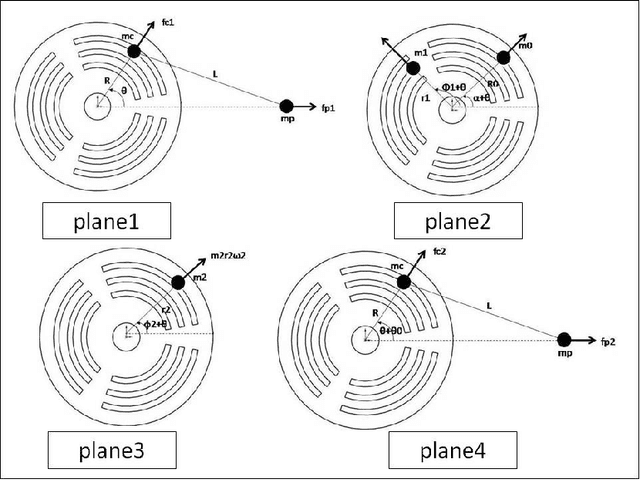
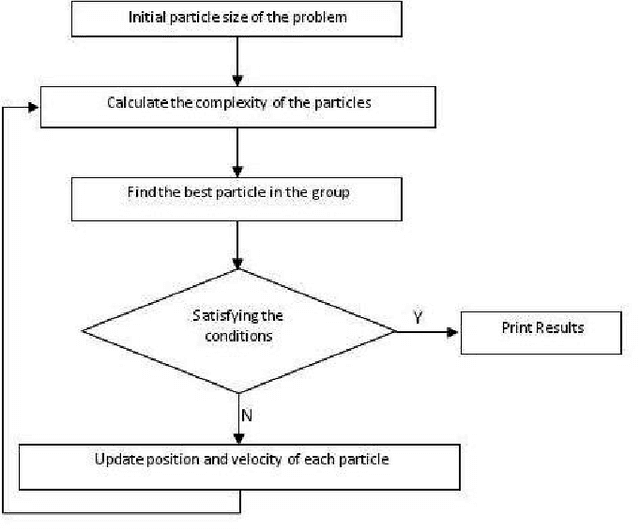
In this paper, a new method for dynamic balancing of double four-bar crank slider mechanism by meta- heuristic-based optimization algorithms is proposed. For this purpose, a proper objective function which is necessary for balancing of this mechanism and corresponding constraints has been obtained by dynamic modeling of the mechanism. Then PSO, ABC, BGA and HGAPSO algorithms have been applied for minimizing the defined cost function in optimization step. The optimization results have been studied completely by extracting the cost function, fitness, convergence speed and runtime values of applied algorithms. It has been shown that PSO and ABC are more efficient than BGA and HGAPSO in terms of convergence speed and result quality. Also, a laboratory scale experimental doublefour-bar crank-slider mechanism was provided for validating the proposed balancing method practically.
* 18 pages-19 figures