 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-Connected Multilayer Perceptron Networks
Dec 20, 2019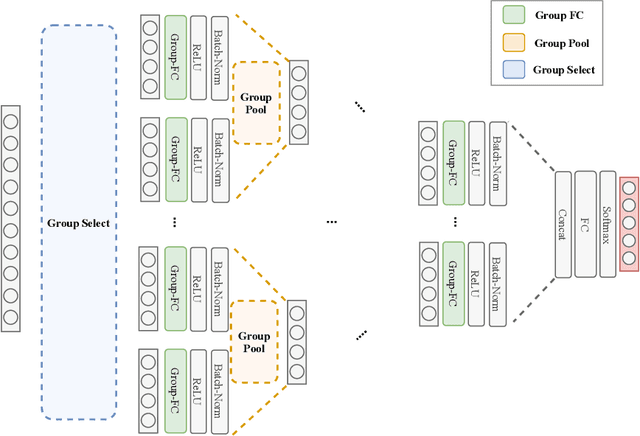
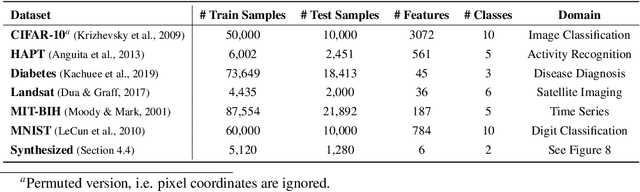
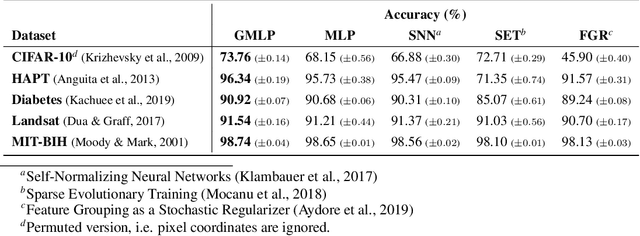
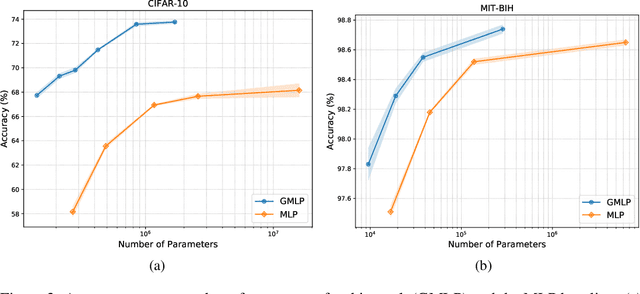
Despite the success of deep learning in domains such as image, voice, and graphs, there has been little progress in deep representation learning for domains without a known structure between features. For instance, a tabular dataset of different demographic and clinical factors where the feature interactions are not given as a prior. In this paper, we propose Group-Connected Multilayer Perceptron (GMLP) networks to enable deep representation learning in these domains. GMLP is based on the idea of learning expressive feature combinations (groups) and exploiting them to reduce the network complexity by defining local group-wise operations. During the training phase, GMLP learns a sparse feature grouping matrix using temperature annealing softmax with an added entropy loss term to encourage the sparsity. Furthermore, an architecture is suggested which resembles binary trees, where group-wise operations are followed by pooling operations to combine information; reducing the number of groups as the network grows in depth. To evaluate the proposed method, we conducted experiments on five different real-world datasets covering various application areas. Additionally, we provide visualizations on MNIST and synthesized data. According to the results, GMLP is able to successfully learn and exploit expressive feature combinations and achieve state-of-the-art classification performance on different datasets.
Cost-Sensitive Feature-Value Acquisition Using Feature Relevance
Dec 19, 2019



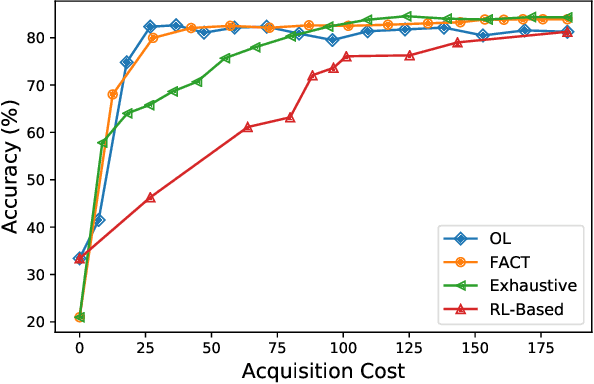
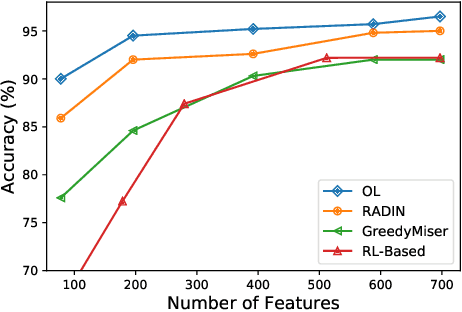
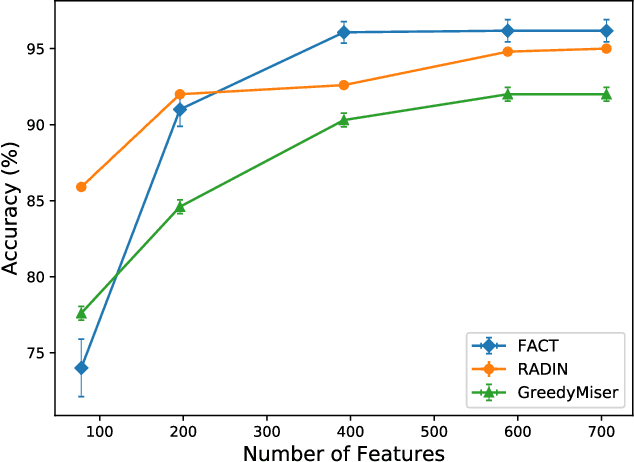
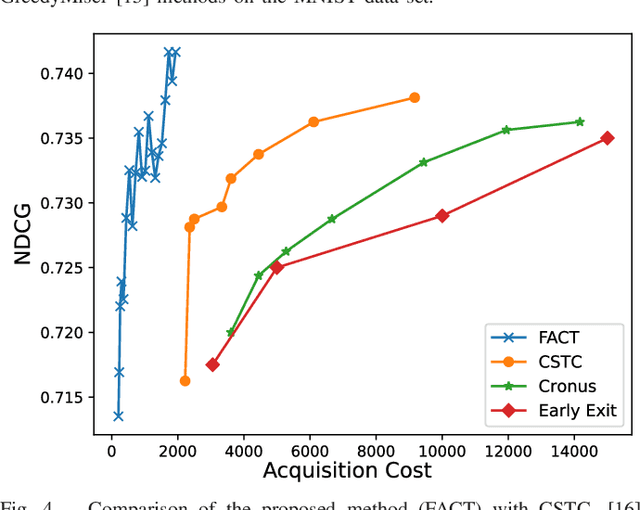
In many real-world machine learning problems, feature values are not readily available. To make predictions, some of the missing features have to be acquired, which can incur a cost in money, computational time, or human time, depending on the problem domain. This leads us to the problem of choosing which features to use at the prediction time. The chosen features should increase the prediction accuracy for a low cost, but determining which features will do that is challenging. The choice should take into account the previously acquired feature values as well as the feature costs. This paper proposes a novel approach to address this problem. The proposed approach chooses the most useful features adaptively based on how relevant they are for the prediction task as well as what the corresponding feature costs are. Our approach uses a generic neural network architecture, which is suitable for a wide range of problems. We evaluate our approach on three cost-sensitive datasets, including Yahoo! Learning to Rank Competition dataset as well as two health datasets. We show that our approach achieves high accuracy with a lower cost than the current state-of-the-art approaches.
Unsupervised Representation for EHR Signals and Codes as Patient Status Vector
Oct 04, 2019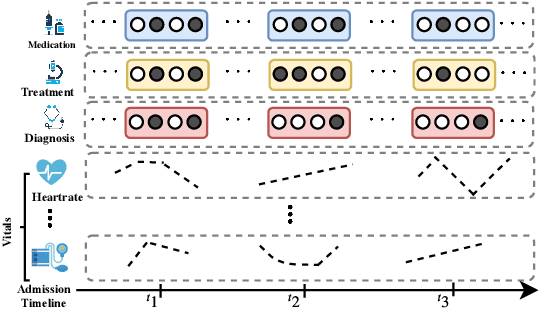
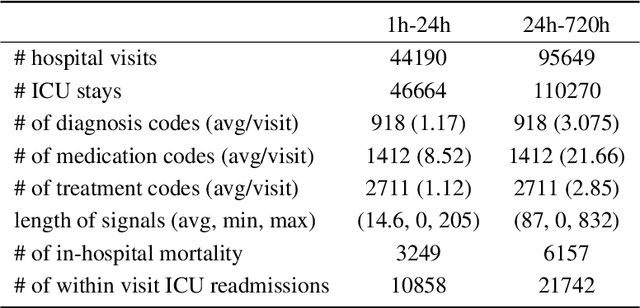
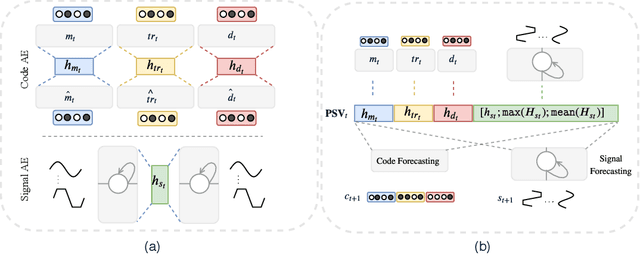
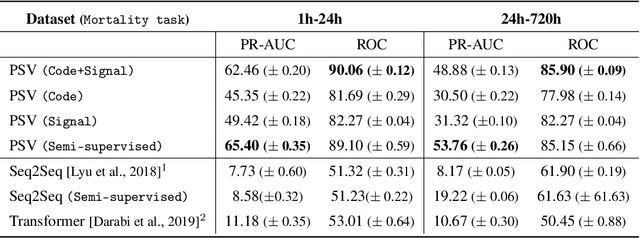
Effective modeling of electronic health records presents many challenges as they contain large amounts of irregularity most of which are due to the varying procedures and diagnosis a patient may have. Despite the recent progress in machine learning, unsupervised learning remains largely at open, especially in the healthcare domain. In this work, we present a two-step unsupervised representation learning scheme to summarize the multi-modal clinical time series consisting of signals and medical codes into a patient status vector. First, an auto-encoder step is used to reduce sparse medical codes and clinical time series into a distributed representation. Subsequently, the concatenation of the distributed representations is further fine-tuned using a forecasting task. We evaluate the usefulness of the representation on two downstream tasks: mortality and readmission. Our proposed method shows improved generalization performance for both short duration ICU visits and long duration ICU visits.
Target-Focused Feature Selection Using a Bayesian Approach
Sep 15, 2019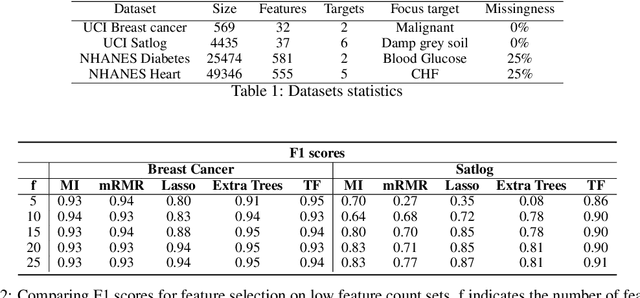
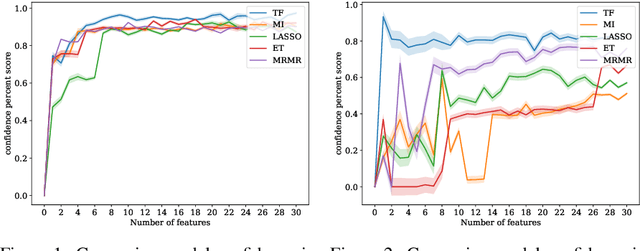
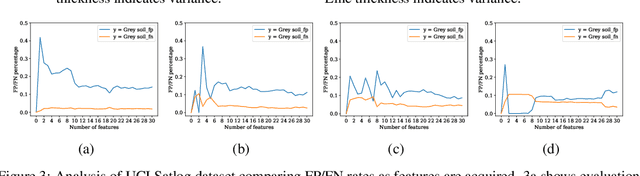
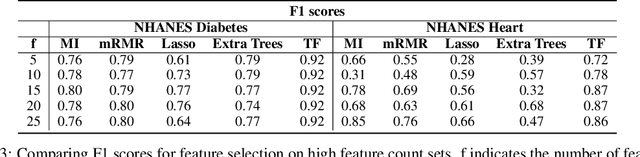
In many real-world scenarios where data is high dimensional, test time acquisition of features is a non-trivial task due to costs associated with feature acquisition and evaluating feature value. The need for highly confident models with an extremely frugal acquisition of features can be addressed by allowing a feature selection method to become target aware. We introduce an approach to feature selection that is based on Bayesian learning, allowing us to report target-specific levels of uncertainty, false positive, and false negative rates. In addition, measuring uncertainty lifts the restriction on feature selection being target agnostic, allowing for feature acquisition based on a single target of focus out of many. We show that acquiring features for a specific target is at least as good as common linear feature selection approaches for small non-sparse datasets, and surpasses these when faced with real-world healthcare data that is larger in scale and in sparseness.
TAPER: Time-Aware Patient EHR Representation
Aug 16, 2019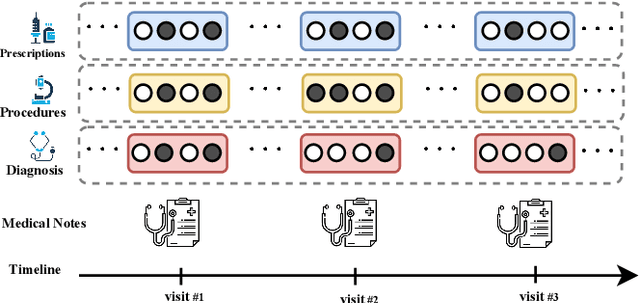
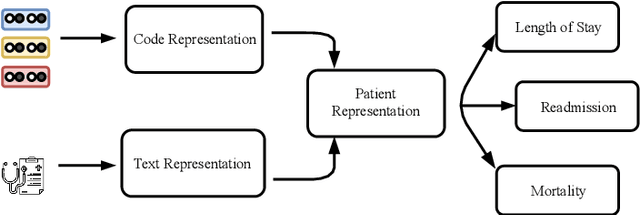
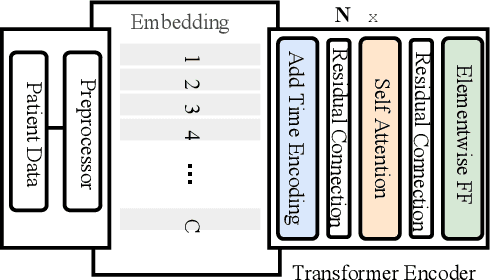
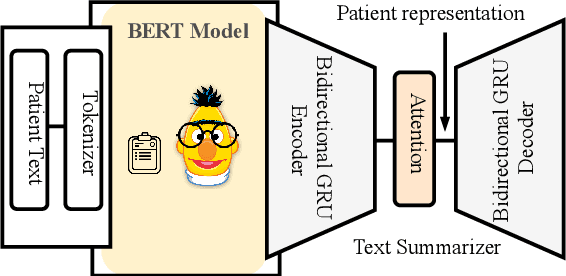
Effective representation learning of electronic health records is a challenging task and is becoming more important as the availability of such data is becoming pervasive. The data contained in these records are irregular and contain multiple modalities such as notes, and medical codes. They are preempted by medical conditions the patient may have, and are typically jotted down by medical staff. Accompanying codes are notes containing valuable information about patients beyond the structured information contained in electronic health records. We use transformer networks and the recently proposed BERT language model to embed these data streams into a unified vector representation. The presented approach effectively encodes a patient's visit data into a single distributed representation, which can be used for downstream tasks. Our model demonstrates superior performance and generalization on mortality, readmission and length of stay tasks using the publicly available MIMIC-III ICU dataset.
Generative Imputation and Stochastic Prediction
May 22, 2019
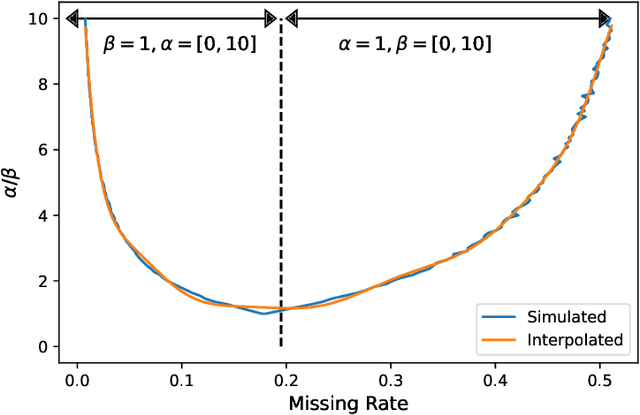
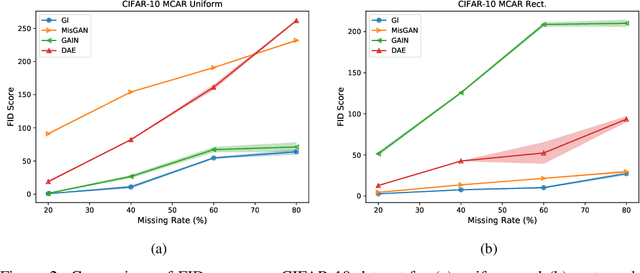
In many machine learning applications, we are faced with incomplete datasets. In the literature, missing data imputation techniques have been mostly concerned with filling missing values. However, the existence of missing values is synonymous with uncertainties not only over the distribution of missing values but also over target class assignments that require careful consideration. The objectives of this paper are twofold. First, we proposed a method for generating imputations from the conditional distribution of missing values given observed values. Second, we use the generated samples to estimate the distribution of target assignments given incomplete data. In order to generate imputations, we train a simple and effective generator network to generate imputations that a discriminator network is tasked to distinguish. Following this, a predictor network is trained using imputed samples from the generator network to capture the classification uncertainties and make predictions accordingly. The proposed method is evaluated on CIFAR-10 image dataset as well as two real-world tabular classification datasets, under various missingness rates and structures. Our experimental results show the effectiveness of the proposed method in generating imputations, as well as providing estimates for the class uncertainties in a classification task when faced with missing values.
Nutrition and Health Data for Cost-Sensitive Learning
Feb 19, 2019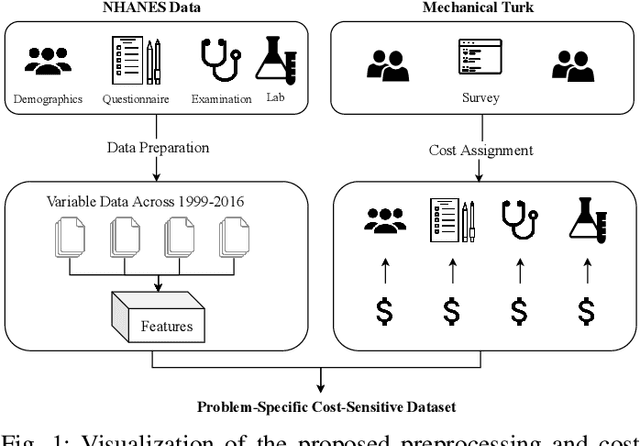
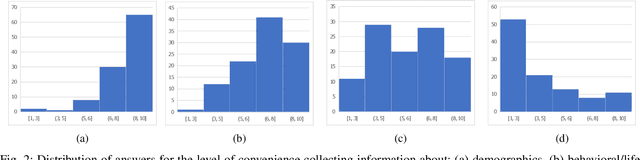
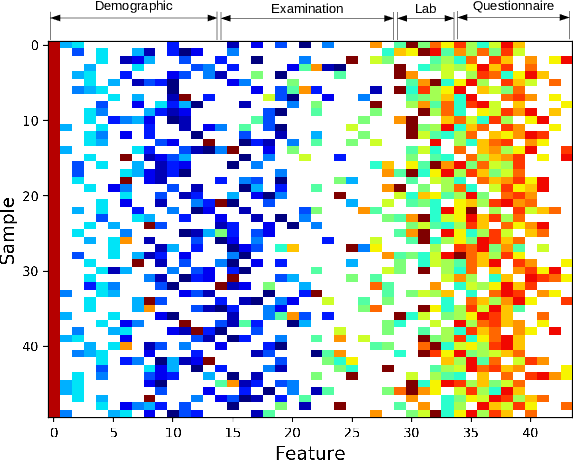
Traditionally, machine learning algorithms have been focused on modeling dynamics of a certain dataset at hand for which all features are available for free. However, there are many concerns such as monetary data collection costs, patient discomfort in medical procedures, and privacy impacts of data collection that require careful consideration in any health analytics system. An efficient solution would only acquire a subset of features based on the value it provides whilst considering acquisition costs. Moreover, datasets that provide feature costs are very limited, especially in healthcare. In this paper, we provide a health dataset as well as a method for assigning feature costs based on the total level of inconvenience asking for each feature entails. Furthermore, based on the suggested dataset, we provide a comparison of recent and state-of-the-art approaches to cost-sensitive feature acquisition and learning. Specifically, we analyze the performance of major sensitivity-based and reinforcement learning based methods in the literature on three different problems in the health domain, including diabetes, heart disease, and hypertension classification.
Opportunistic Learning: Budgeted Cost-Sensitive Learning from Data Streams
Jan 02, 2019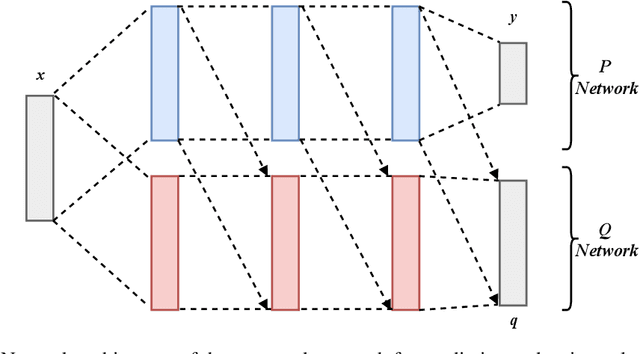

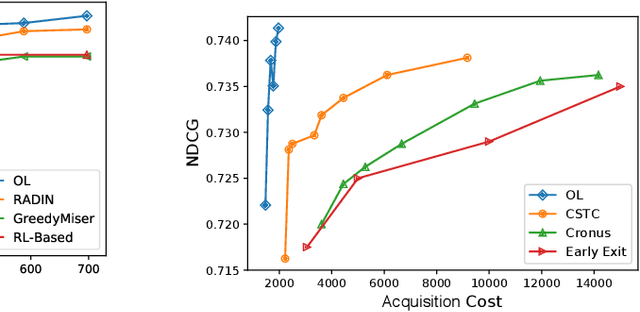
In many real-world learning scenarios, features are only acquirable at a cost constrained under a budget. In this paper, we propose a novel approach for cost-sensitive feature acquisition at the prediction-time. The suggested method acquires features incrementally based on a context-aware feature-value function. We formulate the problem in the reinforcement learning paradigm, and introduce a reward function based on the utility of each feature. Specifically, MC dropout sampling is used to measure expected variations of the model uncertainty which is used as a feature-value function. Furthermore, we suggest sharing representations between the class predictor and value function estimator networks. The suggested approach is completely online and is readily applicable to stream learning setups. The solution is evaluated on three different datasets including the well-known MNIST dataset as a benchmark as well as two cost-sensitive datasets: Yahoo Learning to Rank and a dataset in the medical domain for diabetes classification. According to the results, the proposed method is able to efficiently acquire features and make accurate predictions.
* https://openreview.net/forum?id=S1eOHo09KX
Dynamic Feature Acquisition Using Denoising Autoencoders
Nov 03, 2018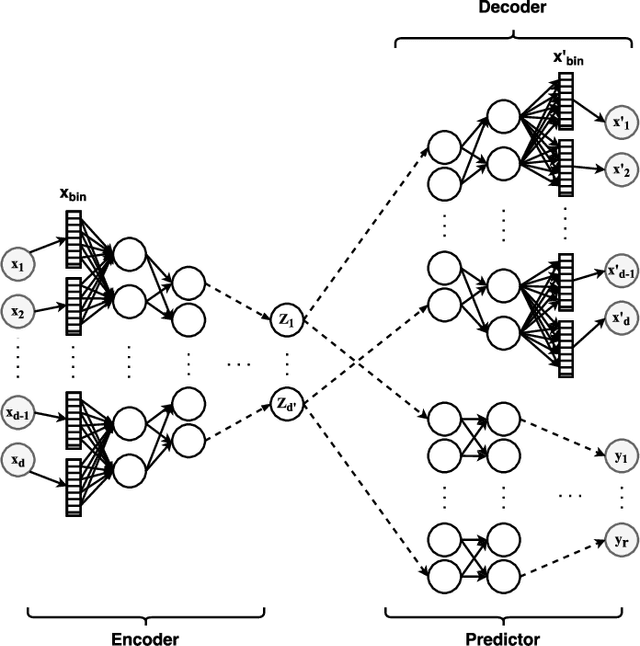
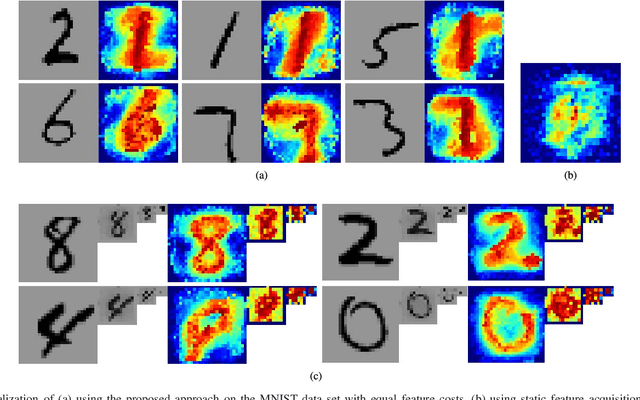
In real-world scenarios, different features have different acquisition costs at test-time which necessitates cost-aware methods to optimize the cost and performance trade-off. This paper introduces a novel and scalable approach for cost-aware feature acquisition at test-time. The method incrementally asks for features based on the available context that are known feature values. The proposed method is based on sensitivity analysis in neural networks and density estimation using denoising autoencoders with binary representation layers. In the proposed architecture, a denoising autoencoder is used to handle unknown features (i.e., features that are yet to be acquired), and the sensitivity of predictions with respect to each unknown feature is used as a context-dependent measure of informativeness. We evaluated the proposed method on eight different real-world datasets as well as one synthesized dataset and compared its performance with several other approaches in the literature. According to the results, the suggested method is capable of efficiently acquiring features at test-time in a cost- and context-aware fashion.
ECG Heartbeat Classification: A Deep Transferable Representation
Jul 12, 2018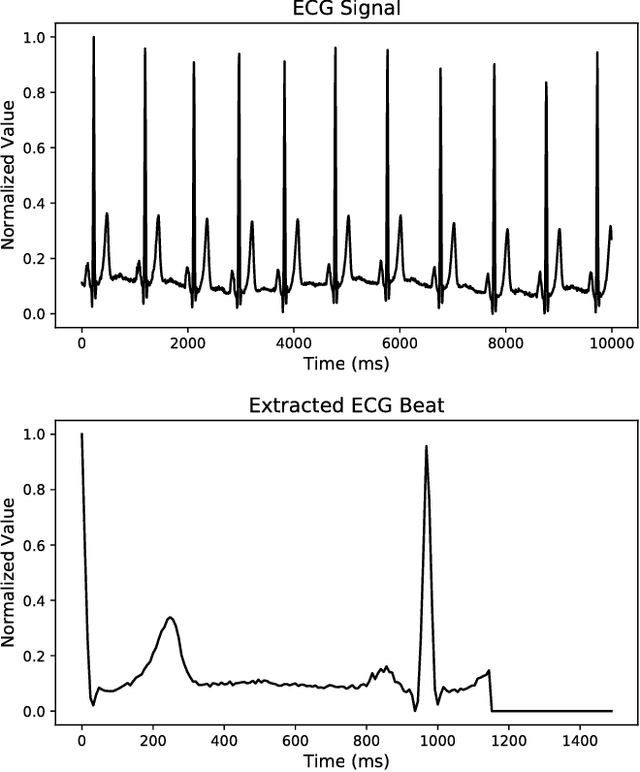
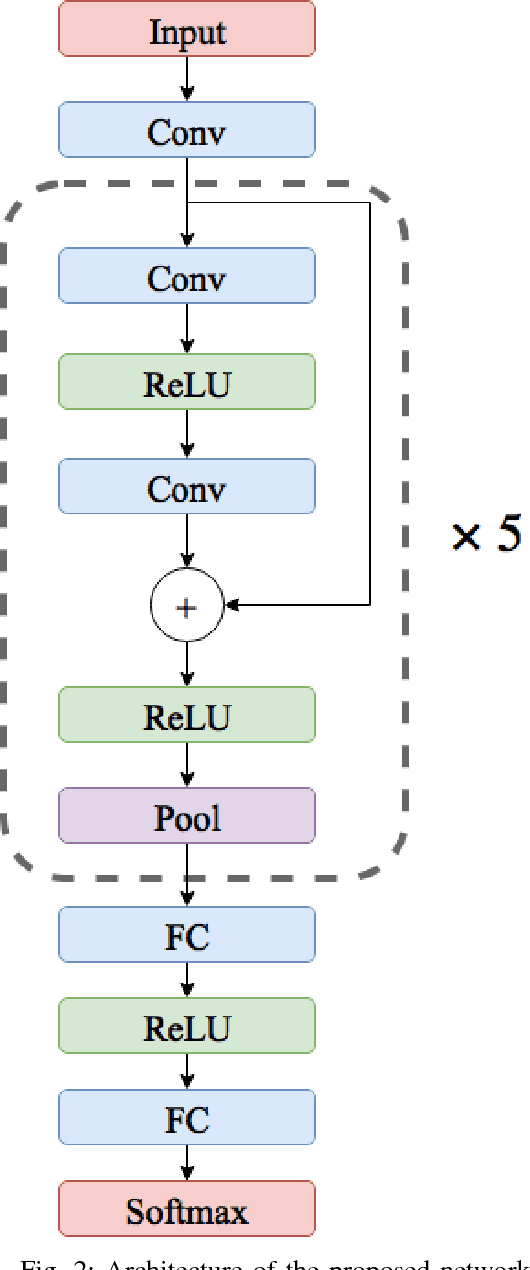
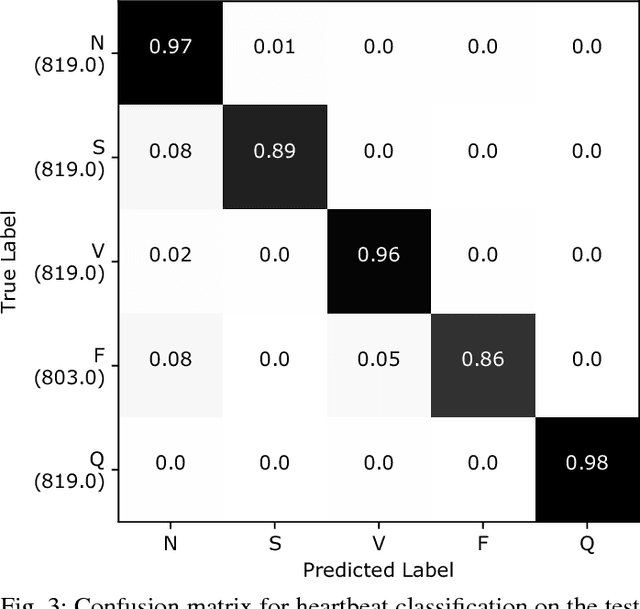
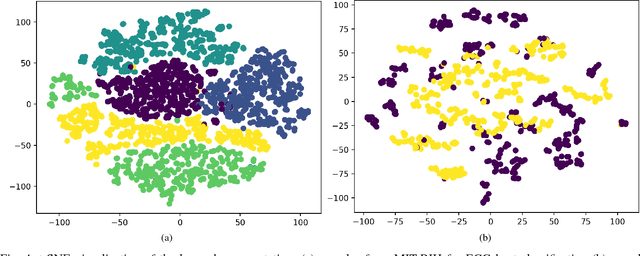
Electrocardiogram (ECG) can be reliably used as a measure to monitor the functionality of the cardiovascular system. Recently, there has been a great attention towards accurate categorization of heartbeats. While there are many commonalities between different ECG conditions, the focus of most studies has been classifying a set of conditions on a dataset annotated for that task rather than learning and employing a transferable knowledge between different tasks. In this paper, we propose a method based on deep convolutional neural networks for the classification of heartbeats which is able to accurately classify five different arrhythmias in accordance with the AAMI EC57 standard. Furthermore, we suggest a method for transferring the knowledge acquired on this task to the myocardial infarction (MI) classification task. We evaluated the proposed method on PhysionNet's MIT-BIH and PTB Diagnostics datasets. According to the results, the suggested method is able to make predictions with the average accuracies of 93.4% and 95.9% on arrhythmia classification and MI classification, respectively.