 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in the Frequency Domain
Mar 12, 2020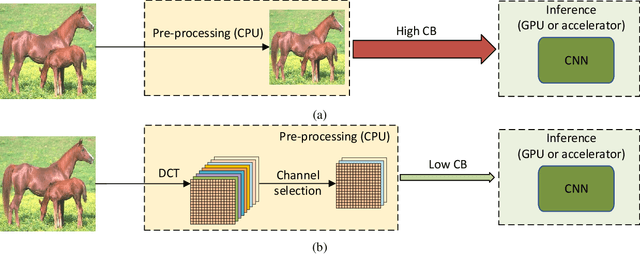
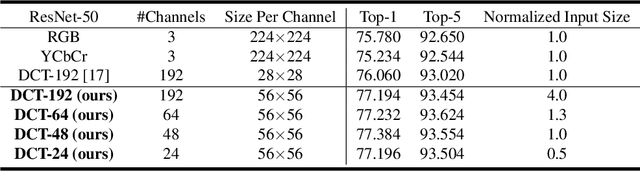
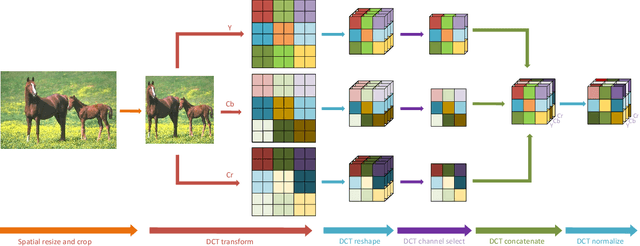
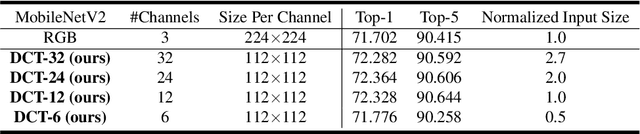
Deep neural networks have achieved remarkable success in computer vision tasks. Existing neural networks mainly operate in the spatial domain with fixed input sizes. For practical applications, images are usually large and have to be downsampled to the predetermined input size of neural networks. Even though the downsampling operations reduce computation and the required communication bandwidth, it removes both redundant and salient information obliviously, which results in accuracy degradation. Inspired by digital signal processing theories, we analyze the spectral bias from the frequency perspective and propose a learning-based frequency selection method to identify the trivial frequency components which can be removed without accuracy loss. The proposed method of learning in the frequency domain leverages identical structures of the well-known neural networks, such as ResNet-50, MobileNetV2, and Mask R-CNN, while accepting the frequency-domain information as the input. Experiment results show that learning in the frequency domain with static channel selection can achieve higher accuracy than the conventional spatial downsampling approach and meanwhile further reduce the input data size. Specifically for ImageNet classification with the same input size, the proposed method achieves 1.41% and 0.66% top-1 accuracy improvements on ResNet-50 and MobileNetV2, respectively. Even with half input size, the proposed method still improves the top-1 accuracy on ResNet-50 by 1%. In addition, we observe a 0.8% average precision improvement on Mask R-CNN for instance segmentation on the COCO dataset.
Non-Volatile Memory Array Based Quantization- and Noise-Resilient LSTM Neural Networks
Feb 25, 2020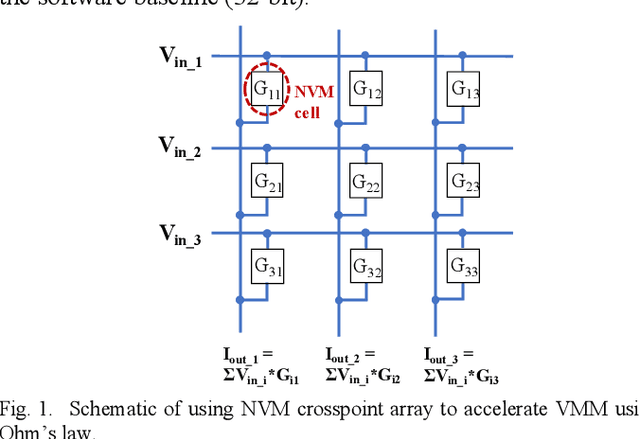
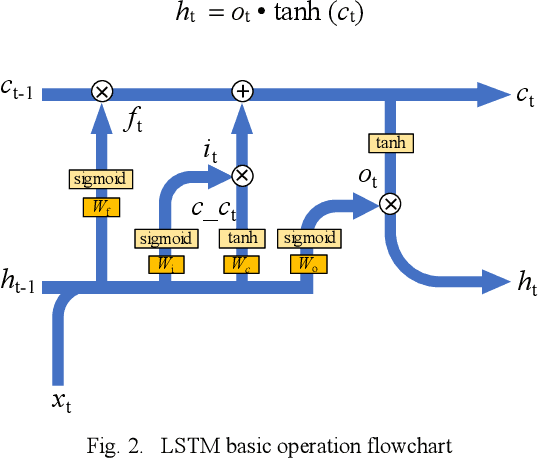
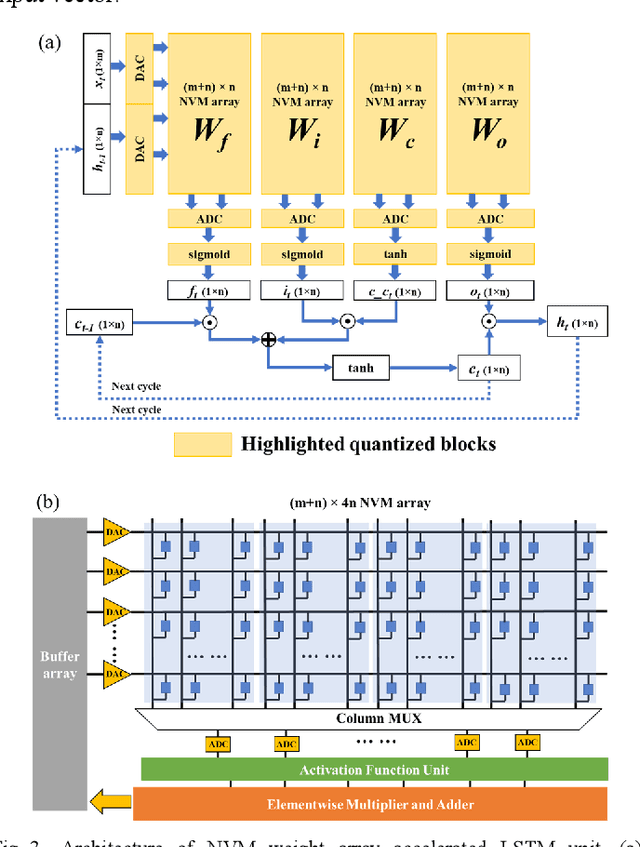
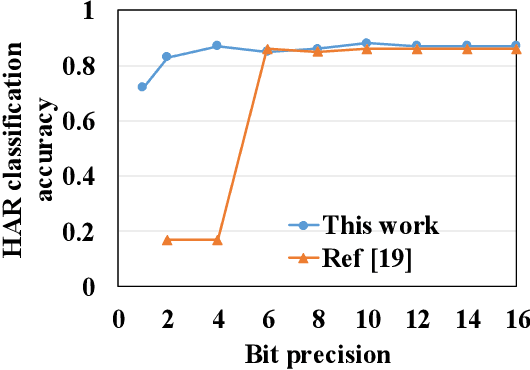
In cloud and edge computing models, it is important that compute devices at the edge be as power efficient as possible. Long short-term memory (LSTM) neural networks have been widely used for natural language processing, time series prediction and many other sequential data tasks. Thus, for these applications there is increasing need for low-power accelerators for LSTM model inference at the edge. In order to reduce power dissipation due to data transfers within inference devices, there has been significant interest in accelerating vector-matrix multiplication (VMM) operations using non-volatile memory (NVM) weight arrays. In NVM array-based hardware, reduced bit-widths also significantly increases the power efficiency. In this paper, we focus on the application of quantization-aware training algorithm to LSTM models, and the benefits these models bring in terms of resilience against both quantization error and analog device noise. We have shown that only 4-bit NVM weights and 4-bit ADC/DACs are needed to produce equivalent LSTM network performance as floating-point baseline. Reasonable levels of ADC quantization noise and weight noise can be naturally tolerated within our NVMbased quantized LSTM network. Benchmark analysis of our proposed LSTM accelerator for inference has shown at least 2.4x better computing efficiency and 40x higher area efficiency than traditional digital approaches (GPU, FPGA, and ASIC). Some other novel approaches based on NVM promise to deliver higher computing efficiency (up to 4.7x) but require larger arrays with potential higher error rates.
Noisy Computations during Inference: Harmful or Helpful?
Nov 26, 2018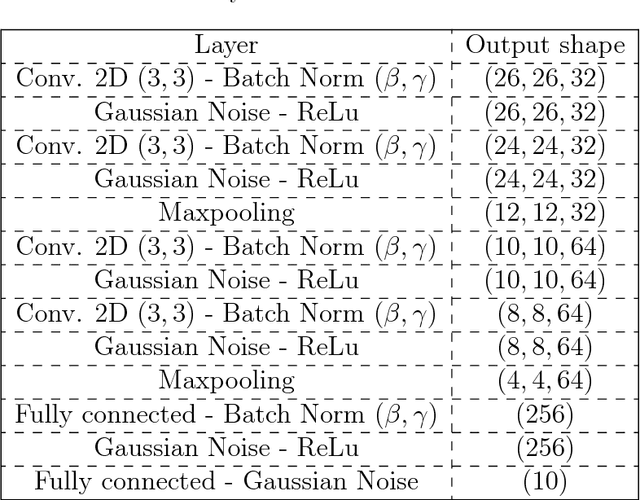

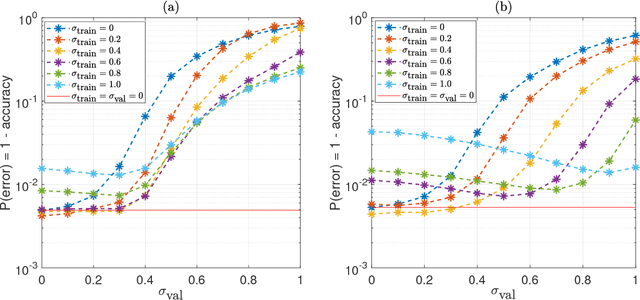
We study two aspects of noisy computations during inference. The first aspect is how to mitigate their side effects for naturally trained deep learning systems. One of the motivations for looking into this problem is to reduce the high power cost of conventional computing of neural networks through the use of analog neuromorphic circuits. Traditional GPU/CPU-centered deep learning architectures exhibit bottlenecks in power-restricted applications (e.g., embedded systems). The use of specialized neuromorphic circuits, where analog signals passed through memory-cell arrays are sensed to accomplish matrix-vector multiplications, promises large power savings and speed gains but brings with it the problems of limited precision of computations and unavoidable analog noise. We manage to improve inference accuracy from 21.1% to 99.5% for MNIST images, from 29.9% to 89.1% for CIFAR10, and from 15.5% to 89.6% for MNIST stroke sequences with the presence of strong noise (with signal-to-noise power ratio being 0 dB) by noise-injected training and a voting method. This observation promises neural networks that are insensitive to inference noise, which reduces the quality requirements on neuromorphic circuits and is crucial for their practical usage. The second aspect is how to utilize the noisy inference as a defensive architecture against black-box adversarial attacks. During inference, by injecting proper noise to signals in the neural networks, the robustness of adversarially-trained neural networks against black-box attacks has been further enhanced by 0.5% and 1.13% for two adversarially trained models for MNIST and CIFAR10, respectively.
Training Recurrent Neural Networks against Noisy Computations during Inference
Jul 17, 2018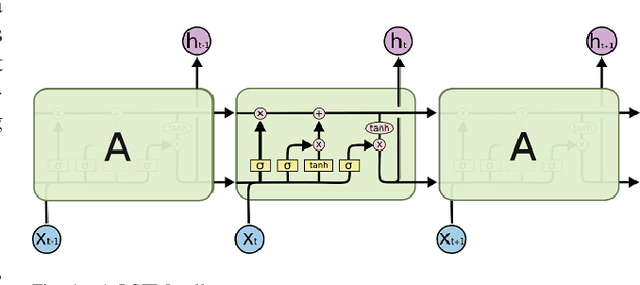
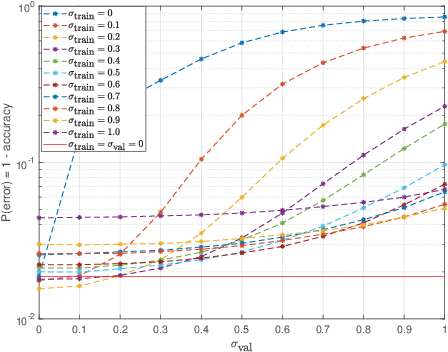
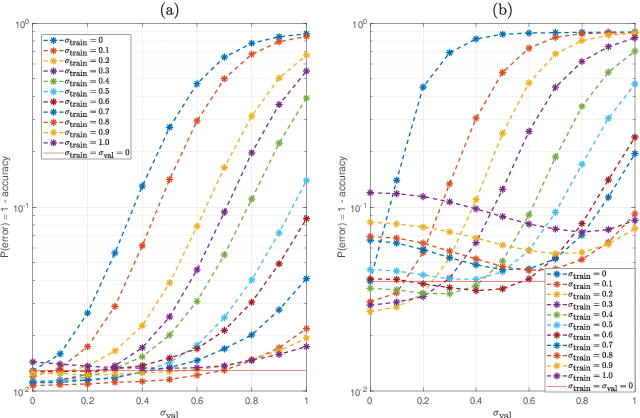
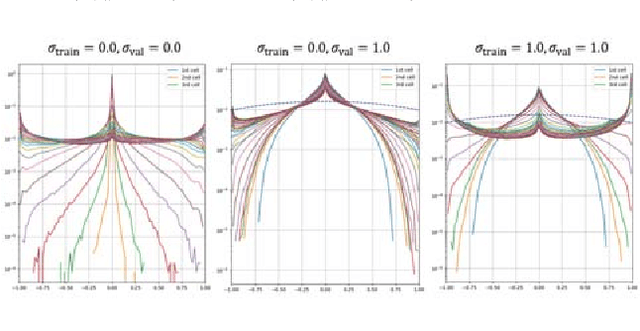
We explore the robustness of recurrent neural networks when the computations within the network are noisy. One of the motivations for looking into this problem is to reduce the high power cost of conventional computing of neural network operations through the use of analog neuromorphic circuits. Traditional GPU/CPU-centered deep learning architectures exhibit bottlenecks in power-restricted applications, such as speech recognition in embedded systems. The use of specialized neuromorphic circuits, where analog signals passed through memory-cell arrays are sensed to accomplish matrix-vector multiplications, promises large power savings and speed gains but brings with it the problems of limited precision of computations and unavoidable analog noise. In this paper we propose a method, called {\em Deep Noise Injection training}, to train RNNs to obtain a set of weights/biases that is much more robust against noisy computation during inference. We explore several RNN architectures, such as vanilla RNN and long-short-term memories (LSTM), and show that after convergence of Deep Noise Injection training the set of trained weights/biases has more consistent performance over a wide range of noise powers entering the network during inference. Surprisingly, we find that Deep Noise Injection training improves overall performance of some networks even for numerically accurate inference.