 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMing Zhou
Mean Field Multi-Agent Reinforcement Learning
Jul 19, 2018
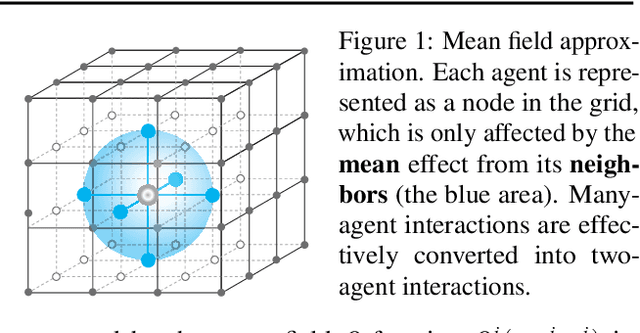
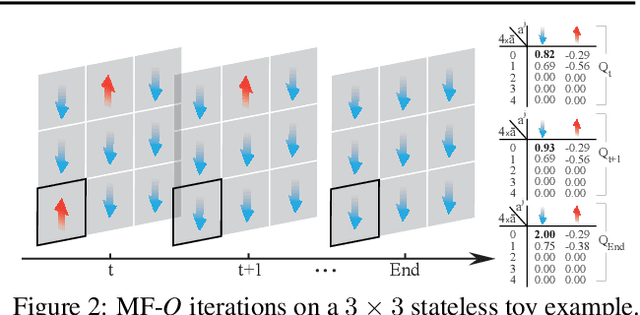
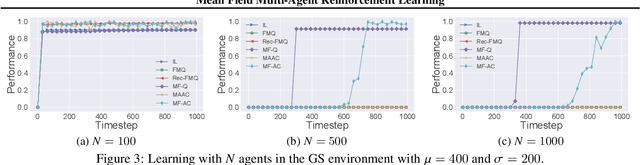
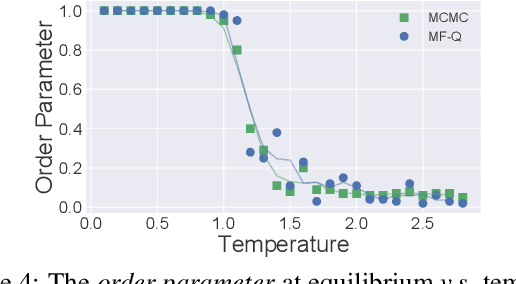
Existing multi-agent reinforcement learning methods are limited typically to a small number of agents. When the agent number increases largely, the learning becomes intractable due to the curse of the dimensionality and the exponential growth of agent interactions. In this paper, we present Mean Field Reinforcement Learning where the interactions within the population of agents are approximated by those between a single agent and the average effect from the overall population or neighboring agents; the interplay between the two entities is mutually reinforced: the learning of the individual agent's optimal policy depends on the dynamics of the population, while the dynamics of the population change according to the collective patterns of the individual policies. We develop practical mean field Q-learning and mean field Actor-Critic algorithms and analyze the convergence of the solution to Nash equilibrium. Experiments on Gaussian squeeze, Ising model, and battle games justify the learning effectiveness of our mean field approaches. In addition, we report the first result to solve the Ising model via model-free reinforcement learning methods.
Reaching Human-level Performance in Automatic Grammatical Error Correction: An Empirical Study
Jul 11, 2018
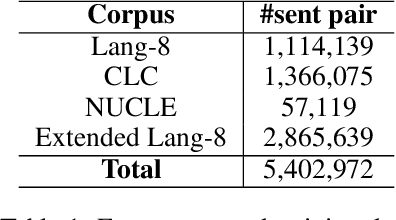

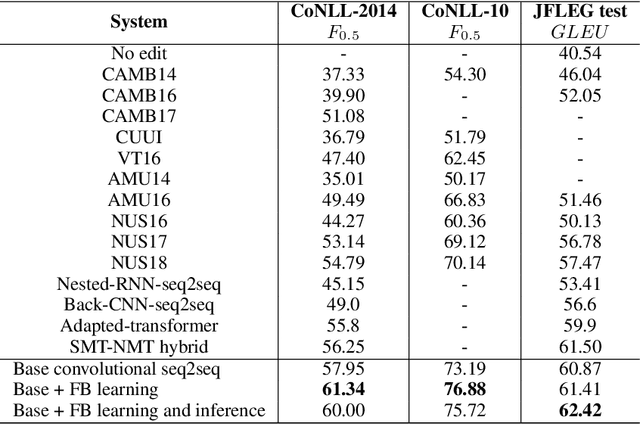
Neural sequence-to-sequence (seq2seq) approaches have proven to be successful in grammatical error correction (GEC). Based on the seq2seq framework, we propose a novel fluency boost learning and inference mechanism. Fluency boosting learning generates diverse error-corrected sentence pairs during training, enabling the error correction model to learn how to improve a sentence's fluency from more instances, while fluency boosting inference allows the model to correct a sentence incrementally with multiple inference steps. Combining fluency boost learning and inference with convolutional seq2seq models, our approach achieves the state-of-the-art performance: 75.72 (F_{0.5}) on CoNLL-2014 10 annotation dataset and 62.42 (GLEU) on JFLEG test set respectively, becoming the first GEC system that reaches human-level performance (72.58 for CoNLL and 62.37 for JFLEG) on both of the benchmarks.
Triangular Architecture for Rare Language Translation
Jul 11, 2018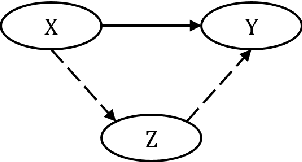
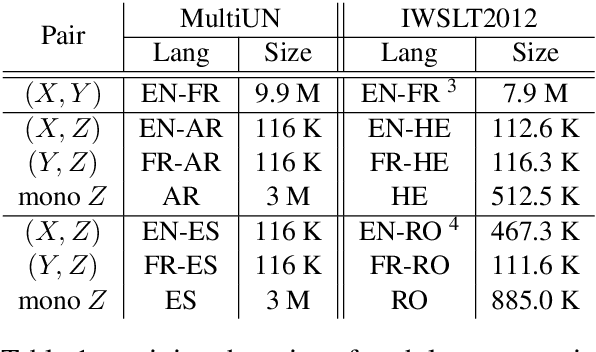
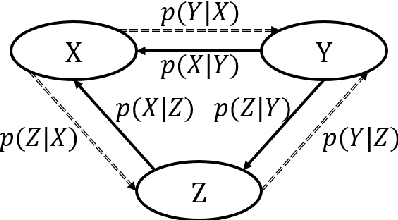

Neural Machine Translation (NMT) performs poor on the low-resource language pair $(X,Z)$, especially when $Z$ is a rare language. By introducing another rich language $Y$, we propose a novel triangular training architecture (TA-NMT) to leverage bilingual data $(Y,Z)$ (may be small) and $(X,Y)$ (can be rich) to improve the translation performance of low-resource pairs. In this triangular architecture, $Z$ is taken as the intermediate latent variable, and translation models of $Z$ are jointly optimized with a unified bidirectional EM algorithm under the goal of maximizing the translation likelihood of $(X,Y)$. Empirical results demonstrate that our method significantly improves the translation quality of rare languages on MultiUN and IWSLT2012 datasets, and achieves even better performance combining back-translation methods.
Neural Document Summarization by Jointly Learning to Score and Select Sentences
Jul 06, 2018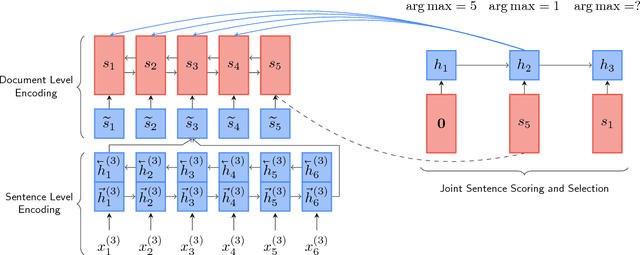
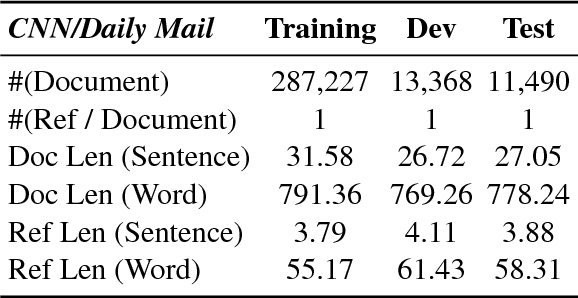
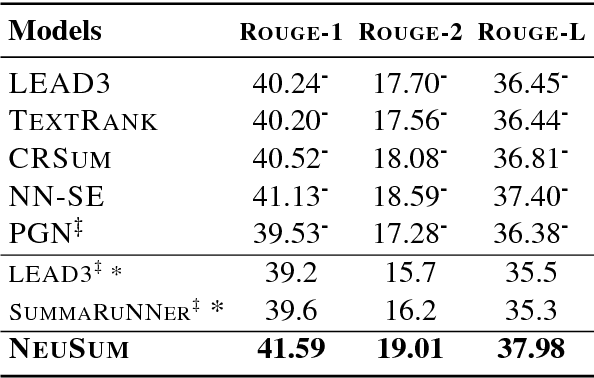
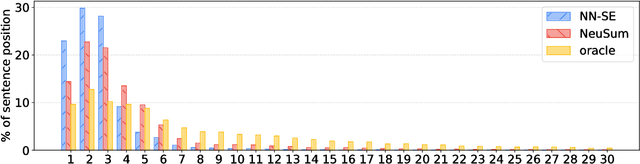
Sentence scoring and sentence selection are two main steps in extractive document summarization systems. However, previous works treat them as two separated subtasks. In this paper, we present a novel end-to-end neural network framework for extractive document summarization by jointly learning to score and select sentences. It first reads the document sentences with a hierarchical encoder to obtain the representation of sentences. Then it builds the output summary by extracting sentences one by one. Different from previous methods, our approach integrates the selection strategy into the scoring model, which directly predicts the relative importance given previously selected sentences. Experiments on the CNN/Daily Mail dataset show that the proposed framework significantly outperforms the state-of-the-art extractive summarization models.
Sequential Copying Networks
Jul 06, 2018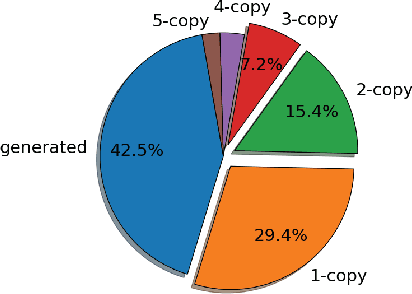
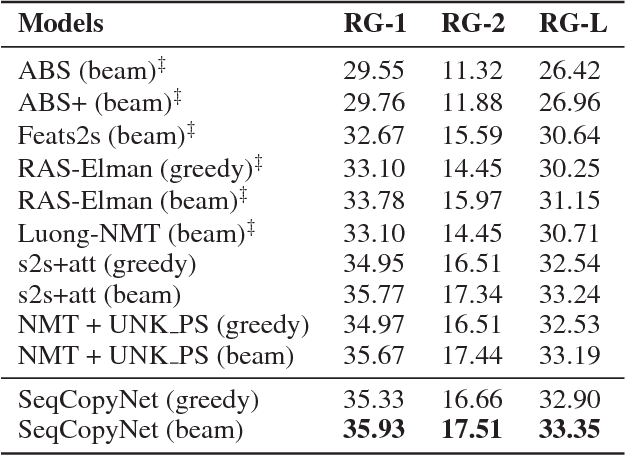
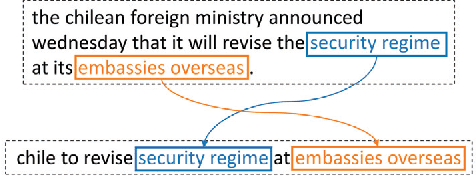
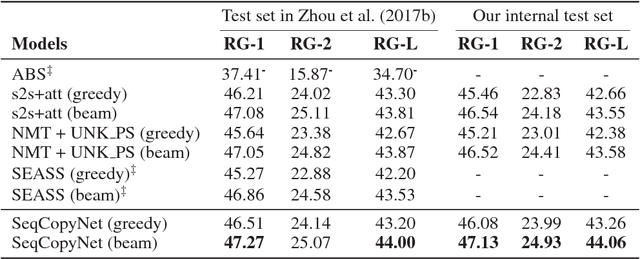
Copying mechanism shows effectiveness in sequence-to-sequence based neural network models for text generation tasks, such as abstractive sentence summarization and question generation. However, existing works on modeling copying or pointing mechanism only considers single word copying from the source sentences. In this paper, we propose a novel copying framework, named Sequential Copying Networks (SeqCopyNet), which not only learns to copy single words, but also copies sequences from the input sentence. It leverages the pointer networks to explicitly select a sub-span from the source side to target side, and integrates this sequential copying mechanism to the generation process in the encoder-decoder paradigm. Experiments on abstractive sentence summarization and question generation tasks show that the proposed SeqCopyNet can copy meaningful spans and outperforms the baseline models.
Achieving Human Parity on Automatic Chinese to English News Translation
Jun 29, 2018


Machine translation has made rapid advances in recent years. Millions of people are using it today in online translation systems and mobile applications in order to communicate across language barriers. The question naturally arises whether such systems can approach or achieve parity with human translations. In this paper, we first address the problem of how to define and accurately measure human parity in translation. We then describe Microsoft's machine translation system and measure the quality of its translations on the widely used WMT 2017 news translation task from Chinese to English. We find that our latest neural machine translation system has reached a new state-of-the-art, and that the translation quality is at human parity when compared to professional human translations. We also find that it significantly exceeds the quality of crowd-sourced non-professional translations.
Dictionary-Guided Editing Networks for Paraphrase Generation
Jun 21, 2018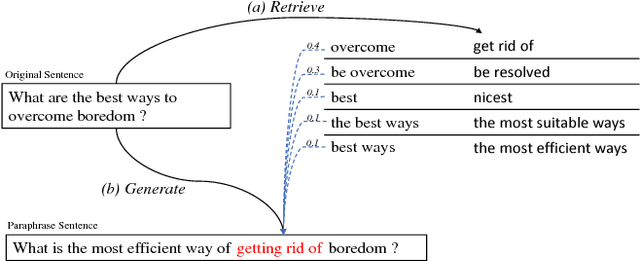
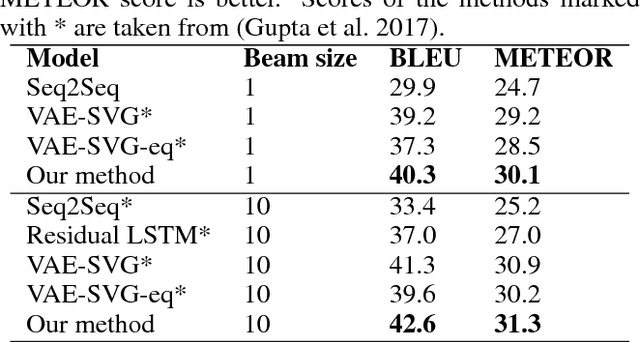
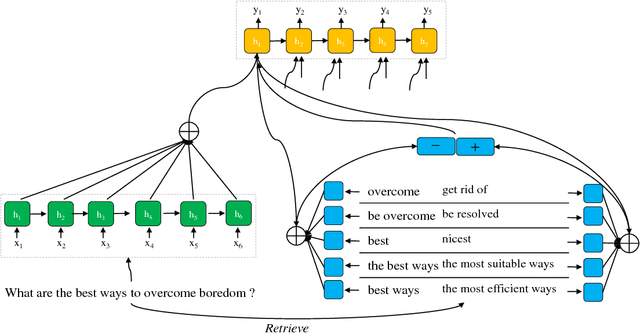
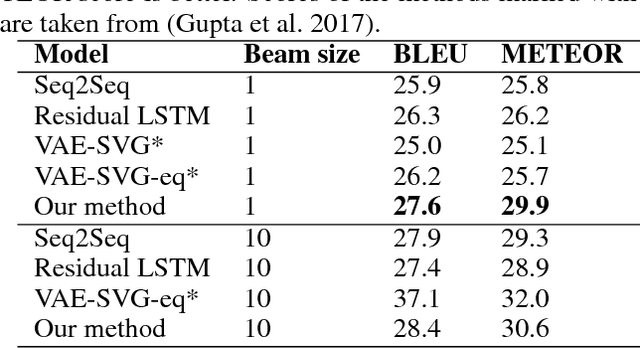
An intuitive way for a human to write paraphrase sentences is to replace words or phrases in the original sentence with their corresponding synonyms and make necessary changes to ensure the new sentences are fluent and grammatically correct. We propose a novel approach to modeling the process with dictionary-guided editing networks which effectively conduct rewriting on the source sentence to generate paraphrase sentences. It jointly learns the selection of the appropriate word level and phrase level paraphrase pairs in the context of the original sentence from an off-the-shelf dictionary as well as the generation of fluent natural language sentences. Specifically, the system retrieves a set of word level and phrase level araphrased pairs derived from the Paraphrase Database (PPDB) for the original sentence, which is used to guide the decision of which the words might be deleted or inserted with the soft attention mechanism under the sequence-to-sequence framework. We conduct experiments on two benchmark datasets for paraphrase generation, namely the MSCOCO and Quora dataset. The evaluation results demonstrate that our dictionary-guided editing networks outperforms the baseline methods.
Reinforced Mnemonic Reader for Machine Reading Comprehension
Jun 06, 2018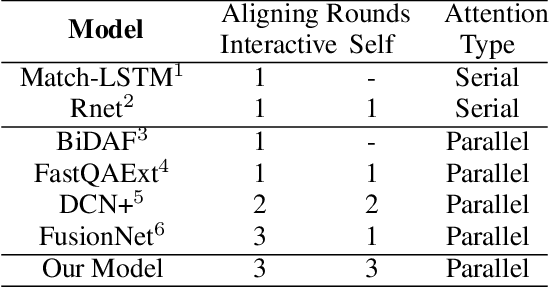
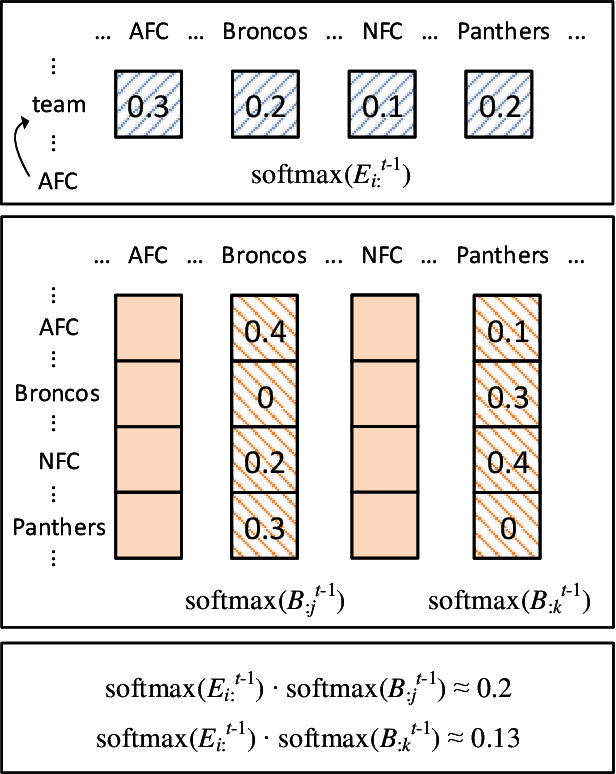
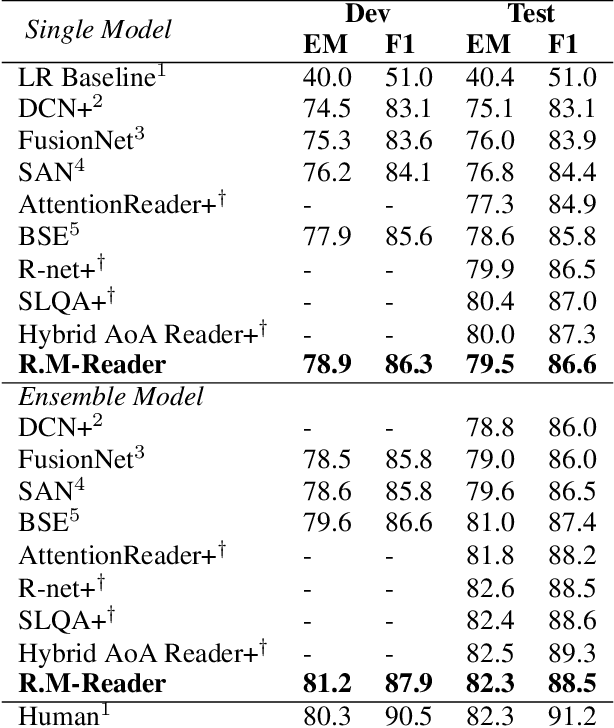
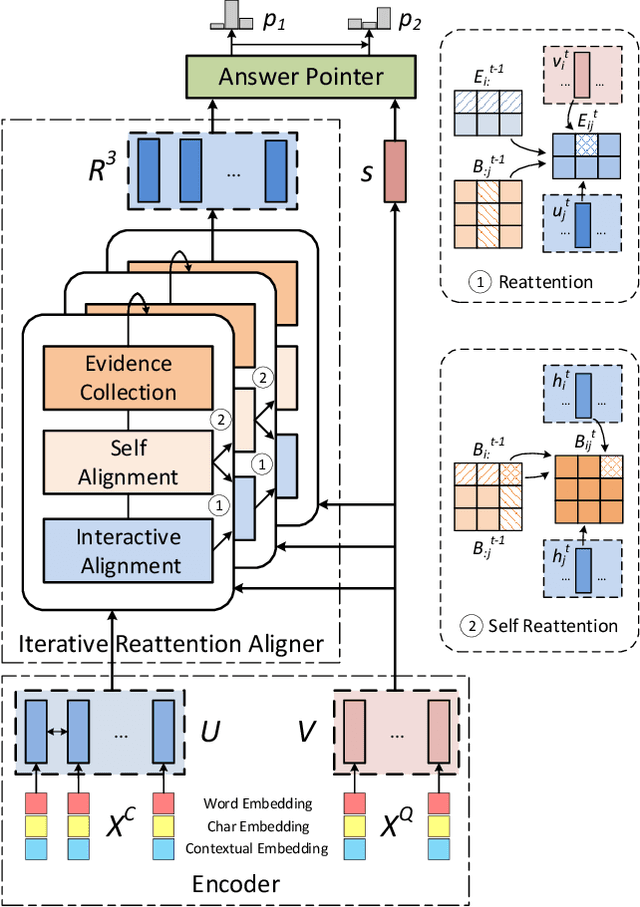
In this paper, we introduce the Reinforced Mnemonic Reader for machine reading comprehension tasks, which enhances previous attentive readers in two aspects. First, a reattention mechanism is proposed to refine current attentions by directly accessing to past attentions that are temporally memorized in a multi-round alignment architecture, so as to avoid the problems of attention redundancy and attention deficiency. Second, a new optimization approach, called dynamic-critical reinforcement learning, is introduced to extend the standard supervised method. It always encourages to predict a more acceptable answer so as to address the convergence suppression problem occurred in traditional reinforcement learning algorithms. Extensive experiments on the Stanford Question Answering Dataset (SQuAD) show that our model achieves state-of-the-art results. Meanwhile, our model outperforms previous systems by over 6% in terms of both Exact Match and F1 metrics on two adversarial SQuAD datasets.
Table-to-Text: Describing Table Region with Natural Language
May 29, 2018
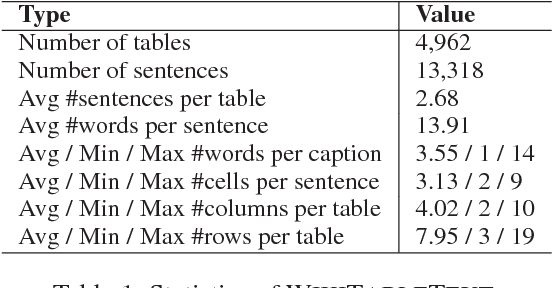
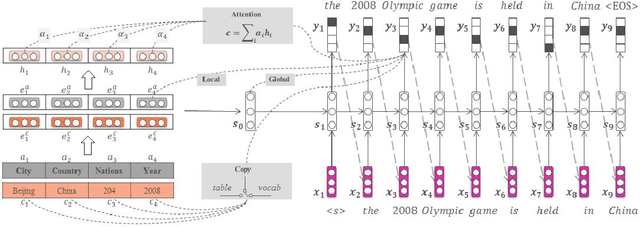

In this paper, we present a generative model to generate a natural language sentence describing a table region, e.g., a row. The model maps a row from a table to a continuous vector and then generates a natural language sentence by leveraging the semantics of a table. To deal with rare words appearing in a table, we develop a flexible copying mechanism that selectively replicates contents from the table in the output sequence. Extensive experiments demonstrate the accuracy of the model and the power of the copying mechanism. On two synthetic datasets, WIKIBIO and SIMPLEQUESTIONS, our model improves the current state-of-the-art BLEU-4 score from 34.70 to 40.26 and from 33.32 to 39.12, respectively. Furthermore, we introduce an open-domain dataset WIKITABLETEXT including 13,318 explanatory sentences for 4,962 tables. Our model achieves a BLEU-4 score of 38.23, which outperforms template based and language model based approaches.
Neural Open Information Extraction
May 11, 2018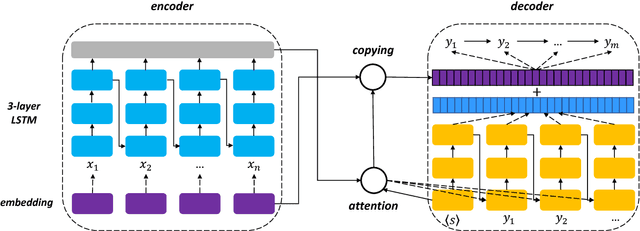
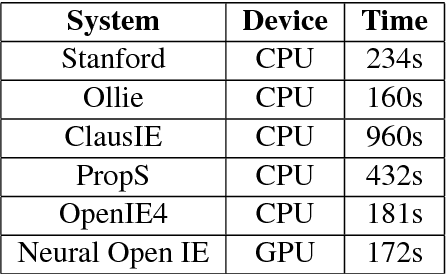
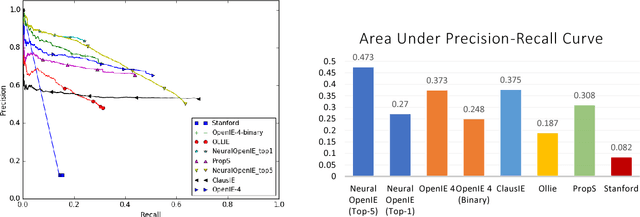
Conventional Open Information Extraction (Open IE) systems are usually built on hand-crafted patterns from other NLP tools such as syntactic parsing, yet they face problems of error propagation. In this paper, we propose a neural Open IE approach with an encoder-decoder framework. Distinct from existing methods, the neural Open IE approach learns highly confident arguments and relation tuples bootstrapped from a state-of-the-art Open IE system. An empirical study on a large benchmark dataset shows that the neural Open IE system significantly outperforms several baselines, while maintaining comparable computational efficiency.