 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMing Sun
Multi-Task Self-Supervised Pre-Training for Music Classification
Feb 05, 2021
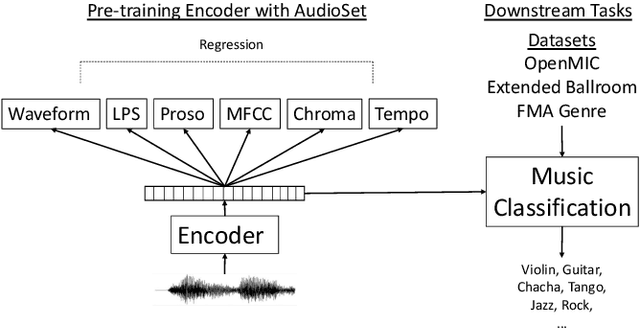
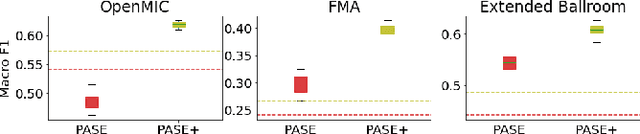
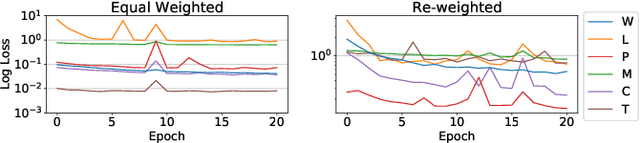
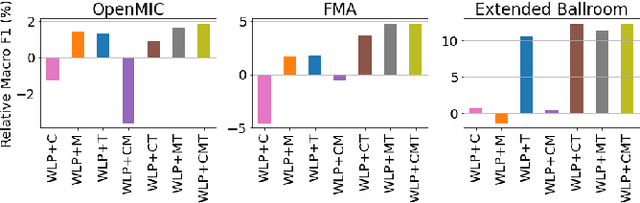
Deep learning is very data hungry, and supervised learning especially requires massive labeled data to work well. Machine listening research often suffers from limited labeled data problem, as human annotations are costly to acquire, and annotations for audio are time consuming and less intuitive. Besides, models learned from labeled dataset often embed biases specific to that particular dataset. Therefore, unsupervised learning techniques become popular approaches in solving machine listening problems. Particularly, a self-supervised learning technique utilizing reconstructions of multiple hand-crafted audio features has shown promising results when it is applied to speech domain such as emotion recognition and automatic speech recognition (ASR). In this paper, we apply self-supervised and multi-task learning methods for pre-training music encoders, and explore various design choices including encoder architectures, weighting mechanisms to combine losses from multiple tasks, and worker selections of pretext tasks. We investigate how these design choices interact with various downstream music classification tasks. We find that using various music specific workers altogether with weighting mechanisms to balance the losses during pre-training helps improve and generalize to the downstream tasks.
Inception Convolution with Efficient Dilation Search
Dec 25, 2020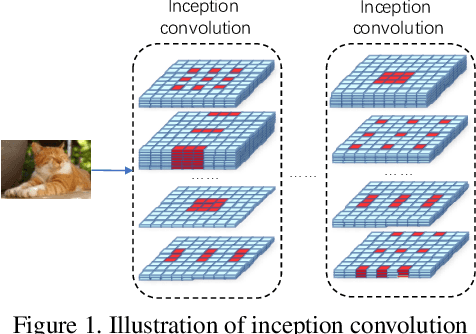
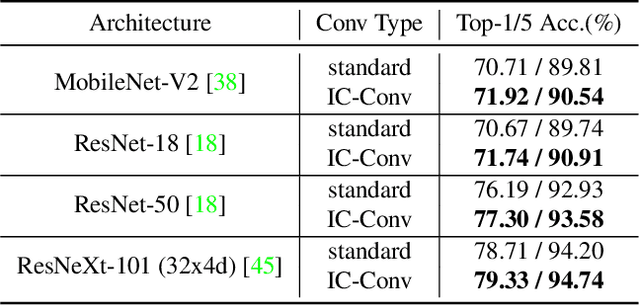
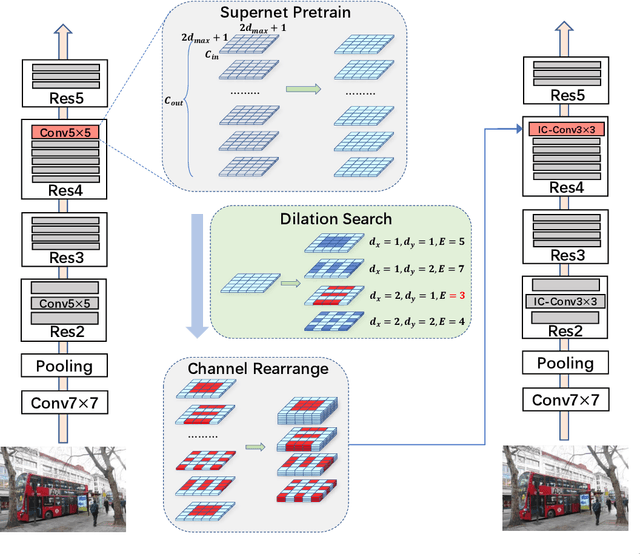

Dilation convolution is a critical mutant of standard convolution neural network to control effective receptive fields and handle large scale variance of objects without introducing additional computation. However, fitting the effective reception field to data with dilated convolution is less discussed in the literature. To fully explore its potentials, we proposed a new mutant of dilated convolution, namely inception (dilated) convolution where the convolutions have independent dilation among different axes, channels and layers. To explore a practical method for fitting the complex inception convolution to the data, a simple while effective dilation search algorithm(EDO) based on statistical optimization is developed. The search method operates in a zero-cost manner which is extremely fast to apply on large scale datasets. Empirical results reveal that our method obtains consistent performance gains in an extensive range of benchmarks. For instance, by simply replace the 3 x 3 standard convolutions in ResNet-50 backbone with inception convolution, we improve the mAP of Faster-RCNN on MS-COCO from 36.4% to 39.2%. Furthermore, using the same replacement in ResNet-101 backbone, we achieve a huge improvement over AP score from 60.2% to 68.5% on COCO val2017 for the bottom up human pose estimation.
DETR for Pedestrian Detection
Dec 12, 2020
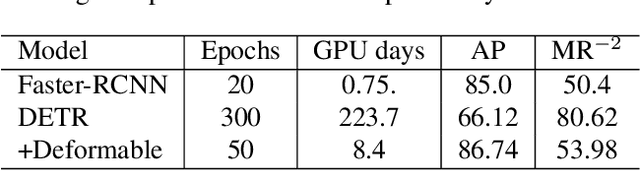
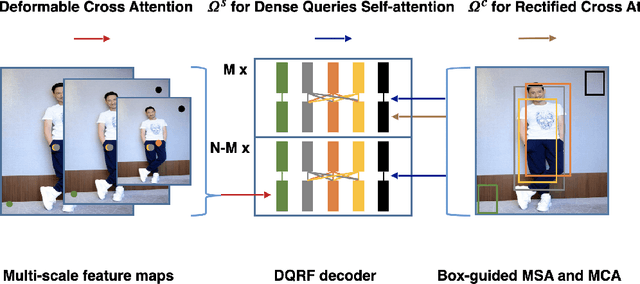

Pedestrian detection in crowd scenes poses a challenging problem due to the heuristic defined mapping from anchors to pedestrians and the conflict between NMS and highly overlapped pedestrians. The recently proposed end-to-end detectors(ED), DETR and deformable DETR, replace hand designed components such as NMS and anchors using the transformer architecture, which gets rid of duplicate predictions by computing all pairwise interactions between queries. Inspired by these works, we explore their performance on crowd pedestrian detection. Surprisingly, compared to Faster-RCNN with FPN, the results are opposite to those obtained on COCO. Furthermore, the bipartite match of ED harms the training efficiency due to the large ground truth number in crowd scenes. In this work, we identify the underlying motives driving ED's poor performance and propose a new decoder to address them. Moreover, we design a mechanism to leverage the less occluded visible parts of pedestrian specifically for ED, and achieve further improvements. A faster bipartite match algorithm is also introduced to make ED training on crowd dataset more practical. The proposed detector PED(Pedestrian End-to-end Detector) outperforms both previous EDs and the baseline Faster-RCNN on CityPersons and CrowdHuman. It also achieves comparable performance with state-of-the-art pedestrian detection methods. Code will be released soon.
Evolving Search Space for Neural Architecture Search
Nov 22, 2020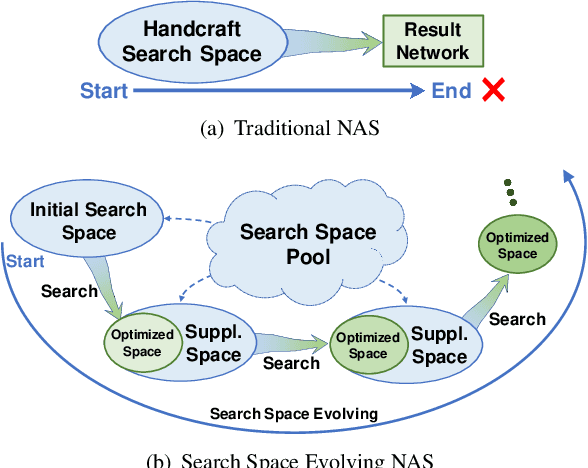
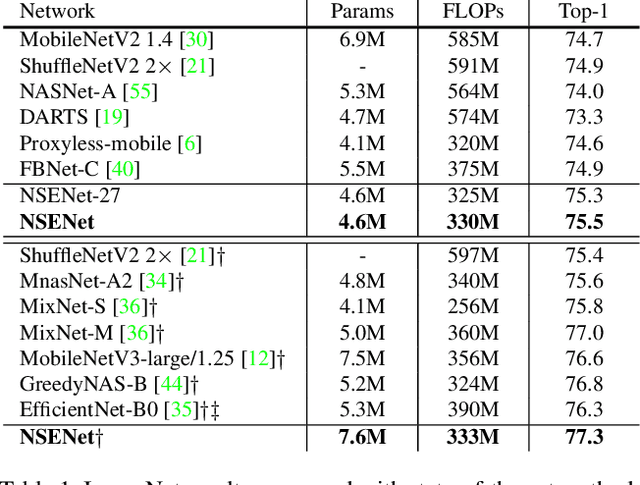
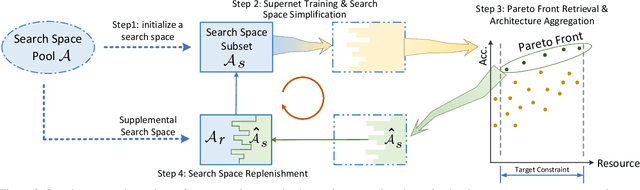
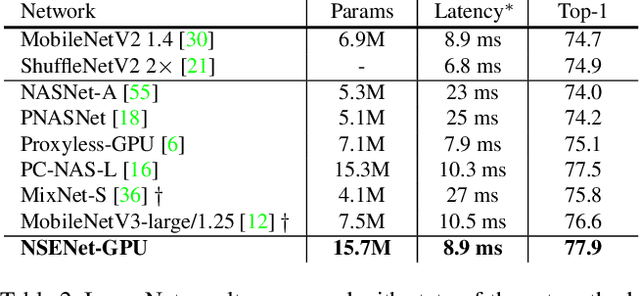
The automation of neural architecture design has been a coveted alternative to human experts. Recent works have small search space, which is easier to optimize but has a limited upper bound of the optimal solution. Extra human design is needed for those methods to propose a more suitable space with respect to the specific task and algorithm capacity. To further enhance the degree of automation for neural architecture search, we present a Neural Search-space Evolution (NSE) scheme that iteratively amplifies the results from the previous effort by maintaining an optimized search space subset. This design minimizes the necessity of a well-designed search space. We further extend the flexibility of obtainable architectures by introducing a learnable multi-branch setting. By employing the proposed method, a consistent performance gain is achieved during a progressive search over upcoming search spaces. We achieve 77.3% top-1 retrain accuracy on ImageNet with 333M FLOPs, which yielded a state-of-the-art performance among previous auto-generated architectures that do not involve knowledge distillation or weight pruning. When the latency constraint is adopted, our result also performs better than the previous best-performing mobile models with a 77.9% Top-1 retrain accuracy.
Improving Auto-Augment via Augmentation-Wise Weight Sharing
Oct 22, 2020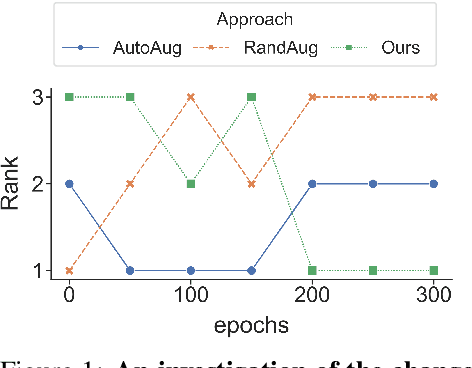
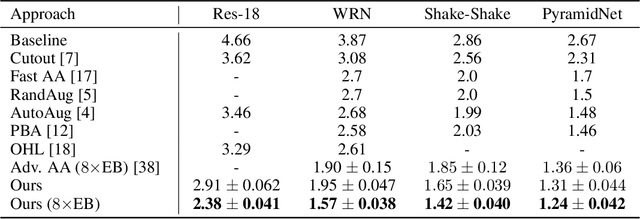
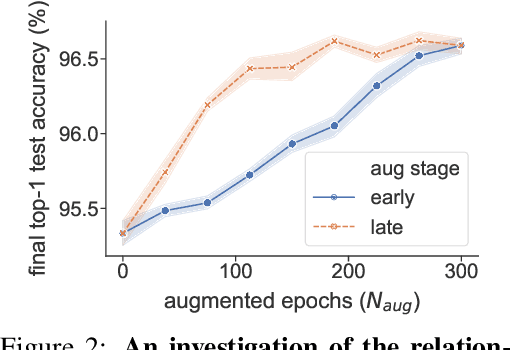
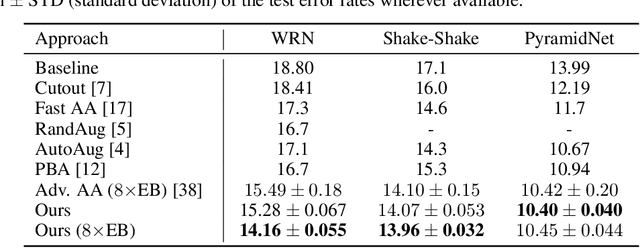
The recent progress on automatically searching augmentation policies has boosted the performance substantially for various tasks. A key component of automatic augmentation search is the evaluation process for a particular augmentation policy, which is utilized to return reward and usually runs thousands of times. A plain evaluation process, which includes full model training and validation, would be time-consuming. To achieve efficiency, many choose to sacrifice evaluation reliability for speed. In this paper, we dive into the dynamics of augmented training of the model. This inspires us to design a powerful and efficient proxy task based on the Augmentation-Wise Weight Sharing (AWS) to form a fast yet accurate evaluation process in an elegant way. Comprehensive analysis verifies the superiority of this approach in terms of effectiveness and efficiency. The augmentation policies found by our method achieve superior accuracies compared with existing auto-augmentation search methods. On CIFAR-10, we achieve a top-1 error rate of 1.24%, which is currently the best performing single model without extra training data. On ImageNet, we get a top-1 error rate of 20.36% for ResNet-50, which leads to 3.34% absolute error rate reduction over the baseline augmentation.
Adaptive Gradient Method with Resilience and Momentum
Oct 21, 2020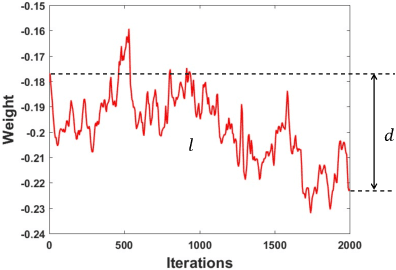
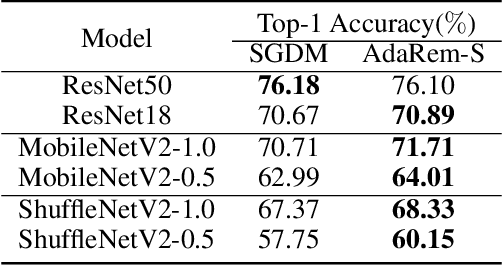
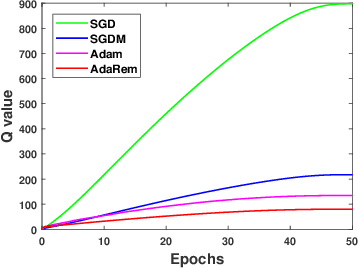

Several variants of stochastic gradient descent (SGD) have been proposed to improve the learning effectiveness and efficiency when training deep neural networks, among which some recent influential attempts would like to adaptively control the parameter-wise learning rate (e.g., Adam and RMSProp). Although they show a large improvement in convergence speed, most adaptive learning rate methods suffer from compromised generalization compared with SGD. In this paper, we proposed an Adaptive Gradient Method with Resilience and Momentum (AdaRem), motivated by the observation that the oscillations of network parameters slow the training, and give a theoretical proof of convergence. For each parameter, AdaRem adjusts the parameter-wise learning rate according to whether the direction of one parameter changes in the past is aligned with the direction of the current gradient, and thus encourages long-term consistent parameter updating with much fewer oscillations. Comprehensive experiments have been conducted to verify the effectiveness of AdaRem when training various models on a large-scale image recognition dataset, e.g., ImageNet, which also demonstrate that our method outperforms previous adaptive learning rate-based algorithms in terms of the training speed and the test error, respectively.
On Front-end Gain Invariant Modeling for Wake Word Spotting
Oct 13, 2020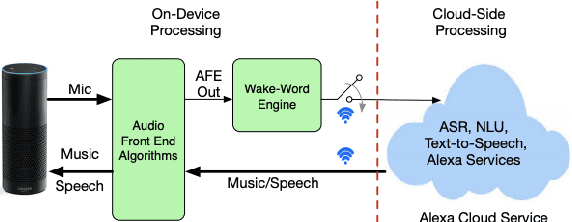
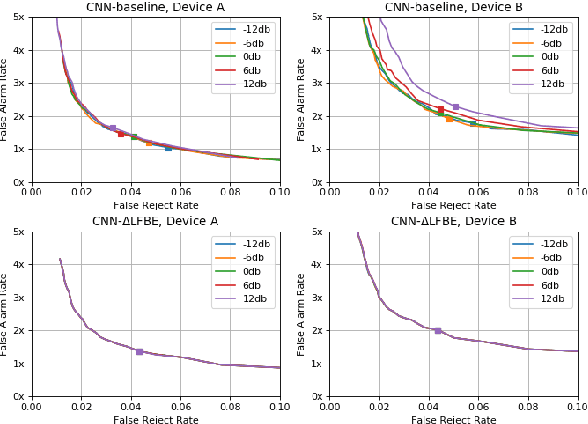
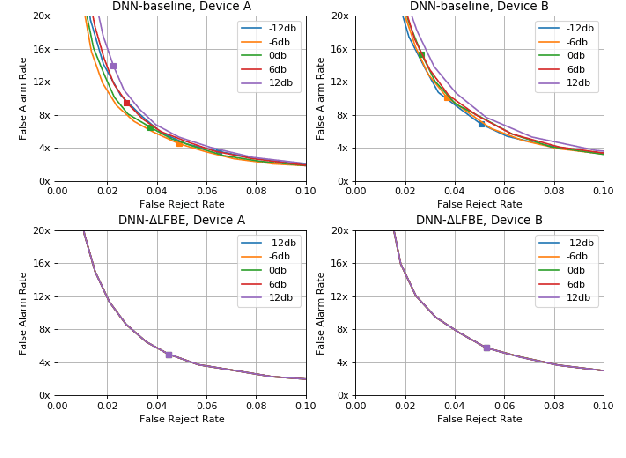
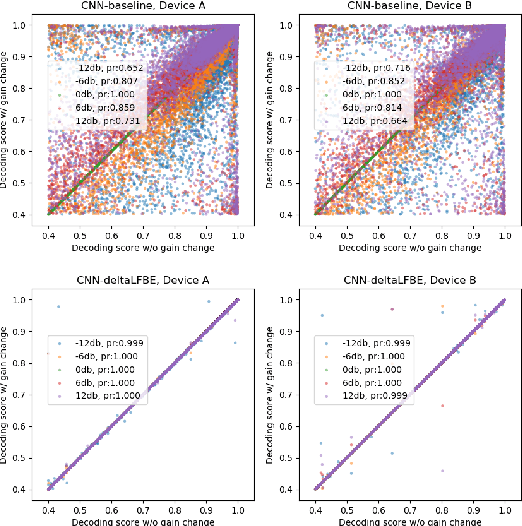
Wake word (WW) spotting is challenging in far-field due to the complexities and variations in acoustic conditions and the environmental interference in signal transmission. A suite of carefully designed and optimized audio front-end (AFE) algorithms help mitigate these challenges and provide better quality audio signals to the downstream modules such as WW spotter. Since the WW model is trained with the AFE-processed audio data, its performance is sensitive to AFE variations, such as gain changes. In addition, when deploying to new devices, the WW performance is not guaranteed because the AFE is unknown to the WW model. To address these issues, we propose a novel approach to use a new feature called $\Delta$LFBE to decouple the AFE gain variations from the WW model. We modified the neural network architectures to accommodate the delta computation, with the feature extraction module unchanged. We evaluate our WW models using data collected from real household settings and showed the models with the $\Delta$LFBE is robust to AFE gain changes. Specifically, when AFE gain changes up to $\pm$12dB, the baseline CNN model lost up to relative 19.0% in false alarm rate or 34.3% in false reject rate, while the model with $\Delta$LFBE demonstrates no performance loss.
Once Quantized for All: Progressively Searching for Quantized Efficient Models
Oct 09, 2020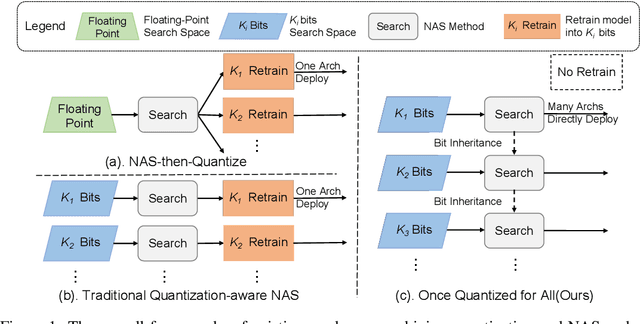

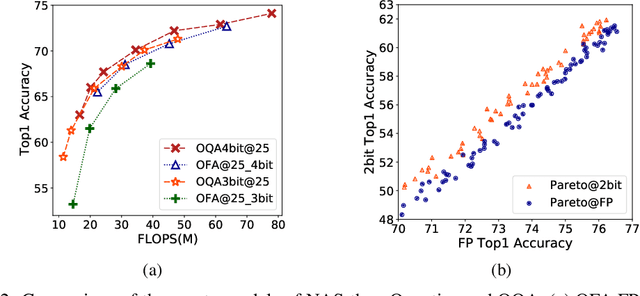
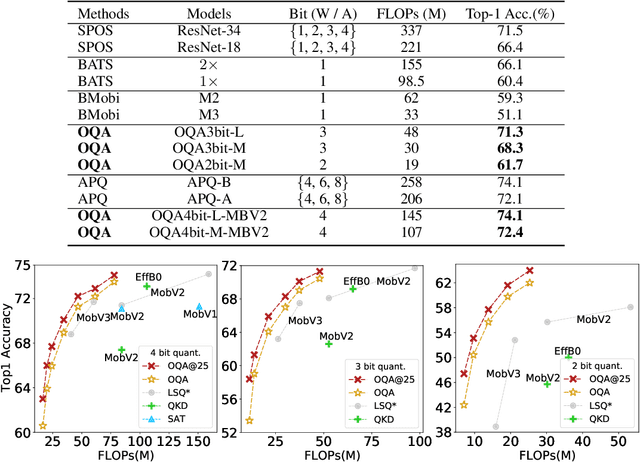
Automatic search of Quantized Neural Networks has attracted a lot of attention. However, the existing quantization aware Neural Architecture Search (NAS) approaches inherit a two-stage search-retrain schema, which is not only time-consuming but also adversely affected by the unreliable ranking of architectures during the search. To avoid the undesirable effect of the search-retrain schema, we present Once Quantized for All (OQA), a novel framework that searches for quantized efficient models and deploys their quantized weights at the same time without additional post-process. While supporting a huge architecture search space, our OQA can produce a series of ultra-low bit-width(e.g. 4/3/2 bit) quantized efficient models. A progressive bit inheritance procedure is introduced to support ultra-low bit-width. Our discovered model family, OQANets, achieves a new state-of-the-art (SOTA) on quantized efficient models compared with various quantization methods and bit-widths. In particular, OQA2bit-L achieves 64.0% ImageNet Top-1 accuracy, outperforming its 2-bit counterpart EfficientNet-B0@QKD by a large margin of 14% using 30% less computation budget. Code is available at https://github.com/LaVieEnRoseSMZ/OQA.
Powering One-shot Topological NAS with Stabilized Share-parameter Proxy
May 21, 2020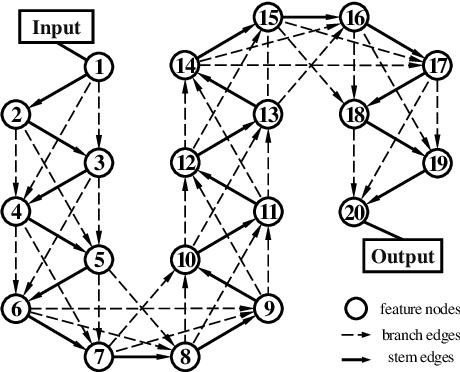

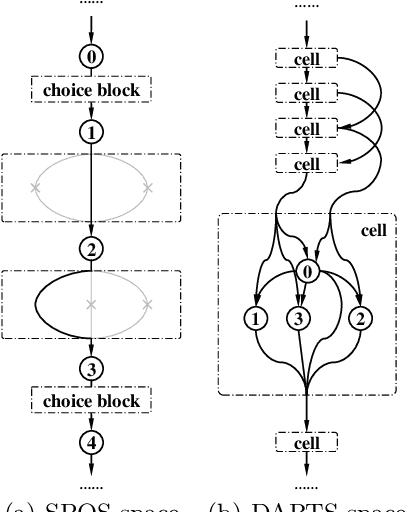
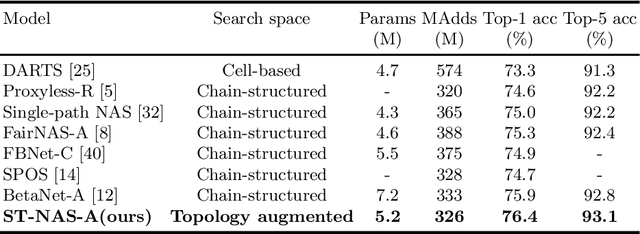
One-shot NAS method has attracted much interest from the research community due to its remarkable training efficiency and capacity to discover high performance models. However, the search spaces of previous one-shot based works usually relied on hand-craft design and were short for flexibility on the network topology. In this work, we try to enhance the one-shot NAS by exploring high-performing network architectures in our large-scale Topology Augmented Search Space (i.e., over 3.4*10^10 different topological structures). Specifically, the difficulties for architecture searching in such a complex space has been eliminated by the proposed stabilized share-parameter proxy, which employs Stochastic Gradient Langevin Dynamics to enable fast shared parameter sampling, so as to achieve stabilized measurement of architecture performance even in search space with complex topological structures. The proposed method, namely Stablized Topological Neural Architecture Search (ST-NAS), achieves state-of-the-art performance under Multiply-Adds (MAdds) constraint on ImageNet. Our lite model ST-NAS-A achieves 76.4% top-1 accuracy with only 326M MAdds. Our moderate model ST-NAS-B achieves 77.9% top-1 accuracy just required 503M MAdds. Both of our models offer superior performances in comparison to other concurrent works on one-shot NAS.