 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Embeddings as Individuality Proxy for Voice Stress Detection
Jun 09, 2023



Since the mental states of the speaker modulate speech, stress introduced by cognitive or physical loads could be detected in the voice. The existing voice stress detection benchmark has shown that the audio embeddings extracted from the Hybrid BYOL-S self-supervised model perform well. However, the benchmark only evaluates performance separately on each dataset, but does not evaluate performance across the different types of stress and different languages. Moreover, previous studies found strong individual differences in stress susceptibility. This paper presents the design and development of voice stress detection, trained on more than 100 speakers from 9 language groups and five different types of stress. We address individual variabilities in voice stress analysis by adding speaker embeddings to the hybrid BYOL-S features. The proposed method significantly improves voice stress detection performance with an input audio length of only 3-5 seconds.
ALO-VC: Any-to-any Low-latency One-shot Voice Conversion
Jun 01, 2023



This paper presents ALO-VC, a non-parallel low-latency one-shot phonetic posteriorgrams (PPGs) based voice conversion method. ALO-VC enables any-to-any voice conversion using only one utterance from the target speaker, with only 47.5 ms future look-ahead. The proposed hybrid signal processing and machine learning pipeline combines a pre-trained speaker encoder, a pitch predictor to predict the converted speech's prosody, and positional encoding to convey the phoneme's location information. We introduce two system versions: ALO-VC-R, which uses a pre-trained d-vector speaker encoder, and ALO-VC-E, which improves performance using the ECAPA-TDNN speaker encoder. The experimental results demonstrate both ALO-VC-R and ALO-VC-E can achieve comparable performance to non-causal baseline systems on the VCTK dataset and two out-of-domain datasets. Furthermore, both proposed systems can be deployed on a single CPU core with 55 ms latency and 0.78 real-time factor. Our demo is available online.
BC-VAD: A Robust Bone Conduction Voice Activity Detection
Dec 06, 2022Voice Activity Detection (VAD) is a fundamental module in many audio applications. Recent state-of-the-art VAD systems are often based on neural networks, but they require a computational budget that usually exceeds the capabilities of a small battery-operated device when preserving the performance of larger models. In this work, we rely on the input from a bone conduction microphone (BCM) to design an efficient VAD (BC-VAD) robust against residual non-stationary noises originating from the environment or speakers not wearing the BCM.We first show that a larger VAD system (58k parameters) achieves state-of-the-art results on a publicly available benchmark but fails when running on bone conduction signals. We then compare its variant BC-VAD (5k parameters and trained on BC data) with a baseline especially designed for a BCM and show that the proposed method achieves better performances under various metrics while keeping the realtime processing requirement for a microcontroller.
Efficient Speech Quality Assessment using Self-supervised Framewise Embeddings
Nov 12, 2022



Automatic speech quality assessment is essential for audio researchers, developers, speech and language pathologists, and system quality engineers. The current state-of-the-art systems are based on framewise speech features (hand-engineered or learnable) combined with time dependency modeling. This paper proposes an efficient system with results comparable to the best performing model in the ConferencingSpeech 2022 challenge. Our proposed system is characterized by a smaller number of parameters (40-60x), fewer FLOPS (100x), lower memory consumption (10-15x), and lower latency (30x). Speech quality practitioners can therefore iterate much faster, deploy the system on resource-limited hardware, and, overall, the proposed system contributes to sustainable machine learning. The paper also concludes that framewise embeddings outperform utterance-level embeddings and that multi-task training with acoustic conditions modeling does not degrade speech quality prediction while providing better interpretation.
BYOL-S: Learning Self-supervised Speech Representations by Bootstrapping
Jun 30, 2022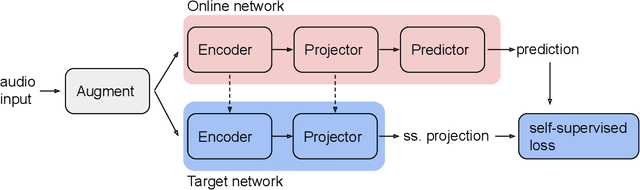

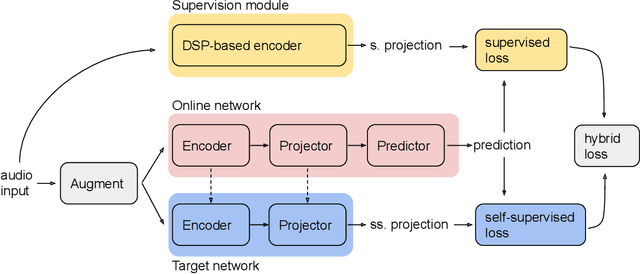
Methods for extracting audio and speech features have been studied since pioneering work on spectrum analysis decades ago. Recent efforts are guided by the ambition to develop general-purpose audio representations. For example, deep neural networks can extract optimal embeddings if they are trained on large audio datasets. This work extends existing methods based on self-supervised learning by bootstrapping, proposes various encoder architectures, and explores the effects of using different pre-training datasets. Lastly, we present a novel training framework to come up with a hybrid audio representation, which combines handcrafted and data-driven learned audio features. All the proposed representations were evaluated within the HEAR NeurIPS 2021 challenge for auditory scene classification and timestamp detection tasks. Our results indicate that the hybrid model with a convolutional transformer as the encoder yields superior performance in most HEAR challenge tasks.
MOSRA: Joint Mean Opinion Score and Room Acoustics Speech Quality Assessment
Apr 04, 2022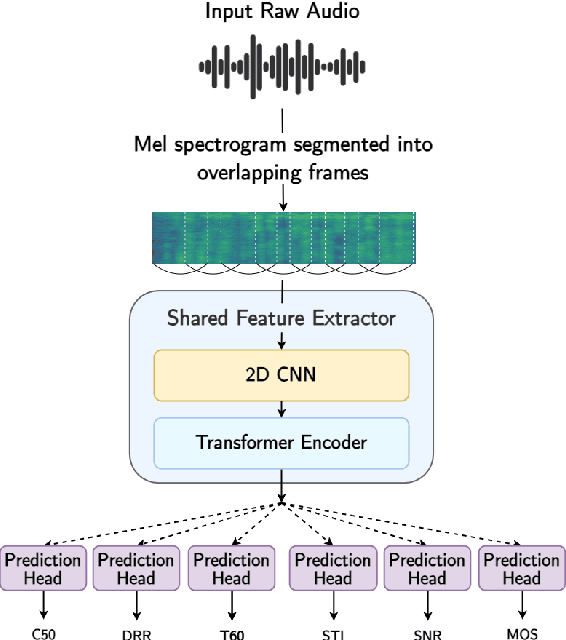
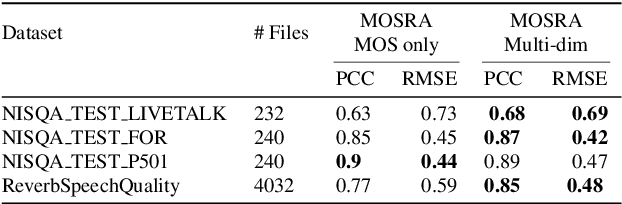
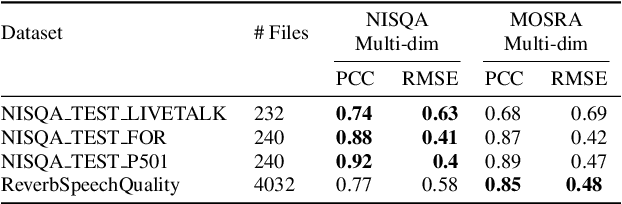
The acoustic environment can degrade speech quality during communication (e.g., video call, remote presentation, outside voice recording), and its impact is often unknown. Objective metrics for speech quality have proven challenging to develop given the multi-dimensionality of factors that affect speech quality and the difficulty of collecting labeled data. Hypothesizing the impact of acoustics on speech quality, this paper presents MOSRA: a non-intrusive multi-dimensional speech quality metric that can predict room acoustics parameters (SNR, STI, T60, DRR, and C50) alongside the overall mean opinion score (MOS) for speech quality. By explicitly optimizing the model to learn these room acoustics parameters, we can extract more informative features and improve the generalization for the MOS task when the training data is limited. Furthermore, we also show that this joint training method enhances the blind estimation of room acoustics, improving the performance of current state-of-the-art models. An additional side-effect of this joint prediction is the improvement in the explainability of the predictions, which is a valuable feature for many applications.
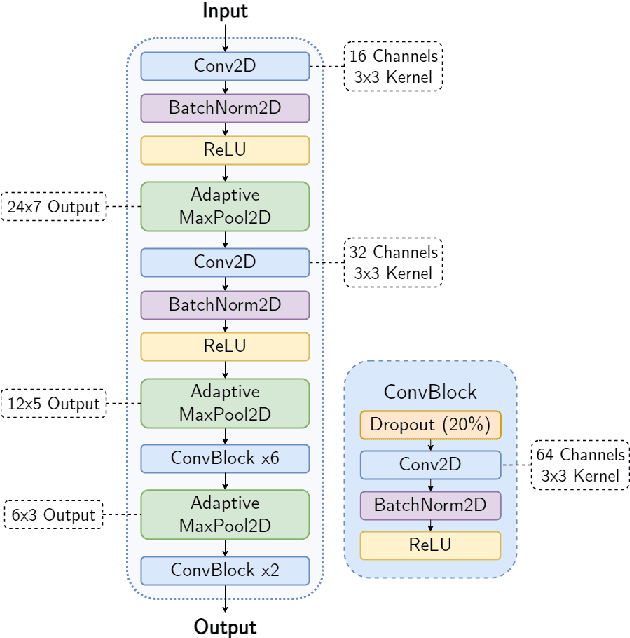
Hybrid Handcrafted and Learnable Audio Representation for Analysis of Speech Under Cognitive and Physical Load
Mar 30, 2022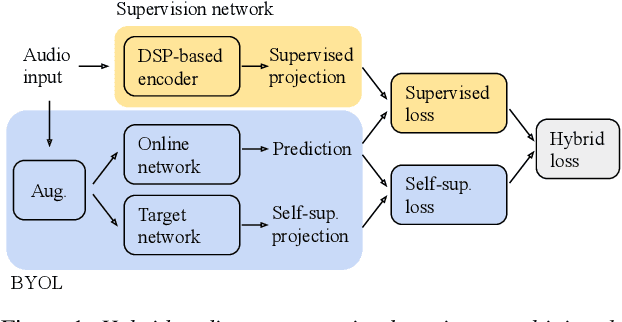

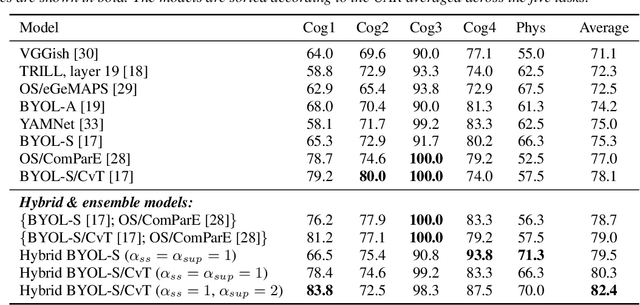
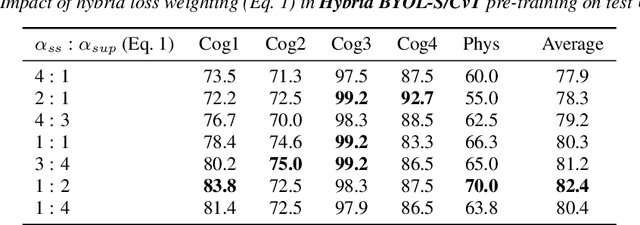
As a neurophysiological response to threat or adverse conditions, stress can affect cognition, emotion and behaviour with potentially detrimental effects on health in the case of sustained exposure. Since the affective content of speech is inherently modulated by an individual's physical and mental state, a substantial body of research has been devoted to the study of paralinguistic correlates of stress-inducing task load. Historically, voice stress analysis (VSA) has been conducted using conventional digital signal processing (DSP) techniques. Despite the development of modern methods based on deep neural networks (DNNs), accurately detecting stress in speech remains difficult due to the wide variety of stressors and considerable variability in the individual stress perception. To that end, we introduce a set of five datasets for task load detection in speech. The voice recordings were collected as either cognitive or physical stress was induced in the cohort of volunteers, with a cumulative number of more than a hundred speakers. We used the datasets to design and evaluate a novel self-supervised audio representation that leverages the effectiveness of handcrafted features (DSP-based) and the complexity of data-driven DNN representations. Notably, the proposed approach outperformed both extensive handcrafted feature sets and novel DNN-based audio representation learning approaches.
AC-VC: Non-parallel Low Latency Phonetic Posteriorgrams Based Voice Conversion
Nov 12, 2021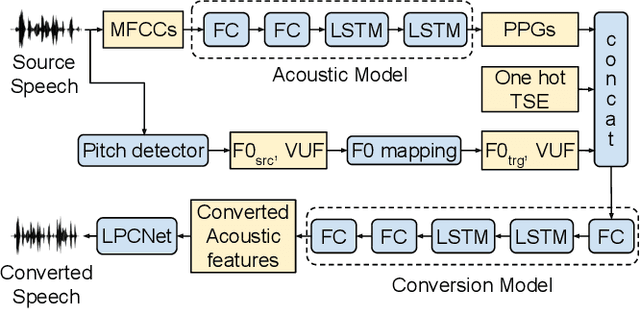
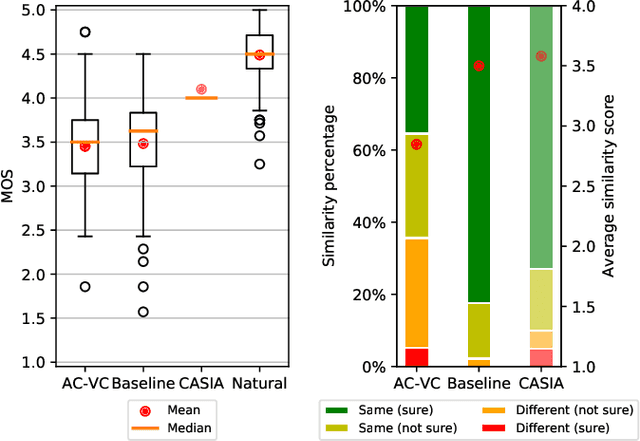
This paper presents AC-VC (Almost Causal Voice Conversion), a phonetic posteriorgrams based voice conversion system that can perform any-to-many voice conversion while having only 57.5 ms future look-ahead. The complete system is composed of three neural networks trained separately with non-parallel data. While most of the current voice conversion systems focus primarily on quality irrespective of algorithmic latency, this work elaborates on designing a method using a minimal amount of future context thus allowing a future real-time implementation. According to a subjective listening test organized in this work, the proposed AC-VC system achieves parity with the non-causal ASR-TTS baseline of the Voice Conversion Challenge 2020 in naturalness with a MOS of 3.5. In contrast, the results indicate that missing future context impacts speaker similarity. Obtained similarity percentage of 65% is lower than the similarity of current best voice conversion systems.
Power efficient analog features for audio recognition
Oct 07, 2021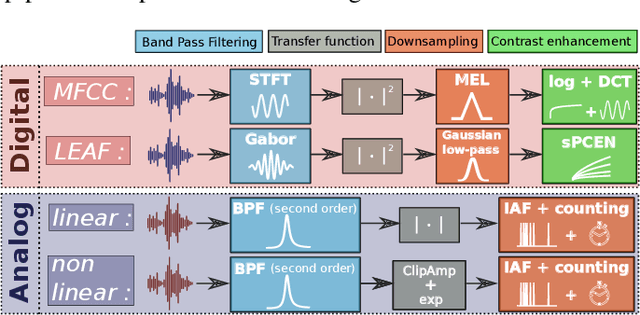
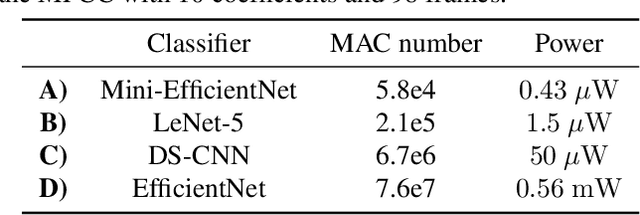
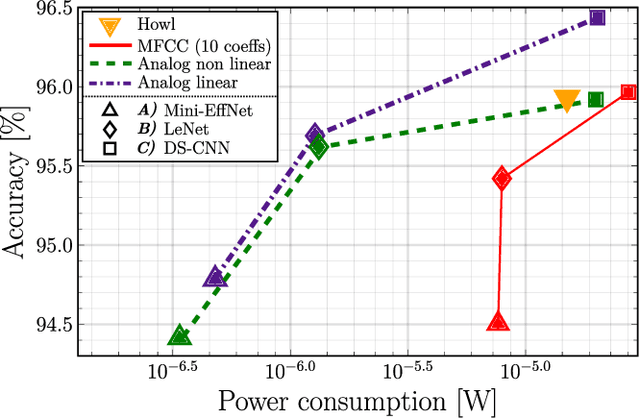
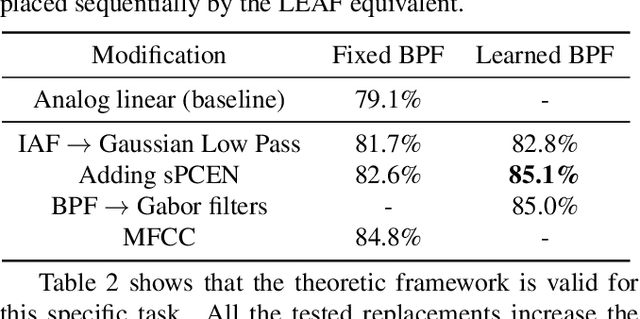
The digital signal processing-based representations like the Mel-Frequency Cepstral Coefficient are well known to be a solid basis for various audio processing tasks. Alternatively, analog feature representations, relying on analog-electronics-feasible bandpass filtering, allow much lower system power consumption compared with the digital counterpart, while parity performance on traditional tasks like voice activity detection can be achieved. This work explores the possibility of using analog features on multiple speech processing tasks that vary in time dependencies: wake word detection, keyword spotting, and speaker identification. The results of this evaluation show that the analog features are still more power-efficient and competitive on simpler tasks than digital features but yield an increasing performance drop on more complex tasks when long-time correlations are present. We also introduce a novel theoretical framework based on information theory to understand this performance drop by quantifying information flow in feature calculation which helps identify the performance bottlenecks. The theoretical claims are experimentally validated, leading to a maximum of 6% increase of keyword spotting accuracy, even surpassing the digital baseline features. The proposed analog-feature-based systems could pave the way to achieving best-in-class accuracy and power consumption simultaneously.
SERAB: A multi-lingual benchmark for speech emotion recognition
Oct 07, 2021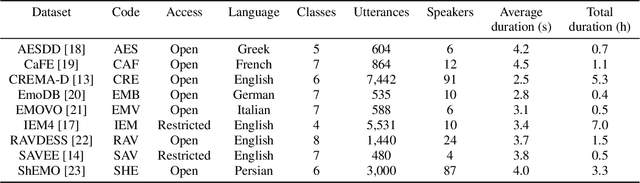
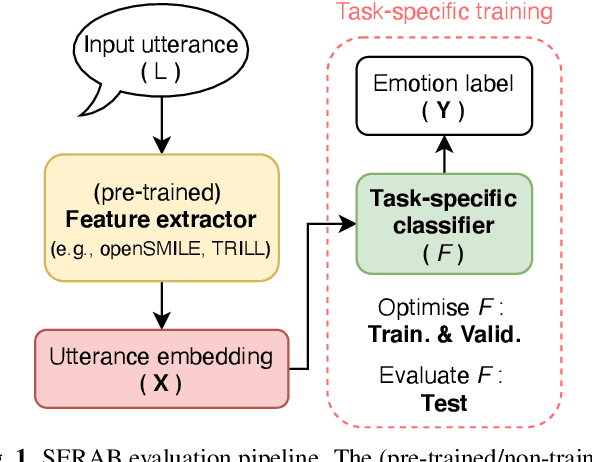
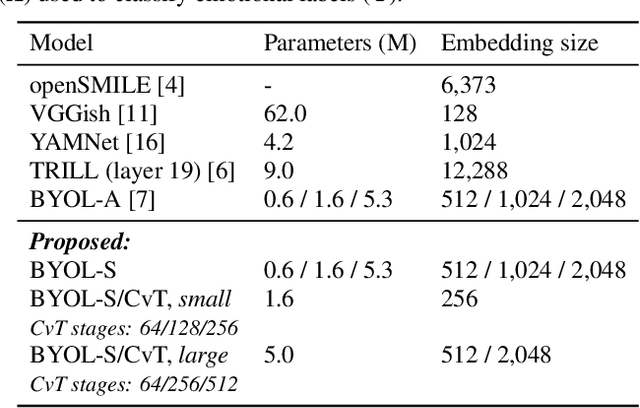
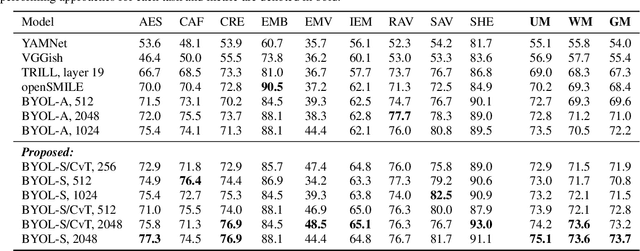
Recent developments in speech emotion recognition (SER) often leverage deep neural networks (DNNs). Comparing and benchmarking different DNN models can often be tedious due to the use of different datasets and evaluation protocols. To facilitate the process, here, we present the Speech Emotion Recognition Adaptation Benchmark (SERAB), a framework for evaluating the performance and generalization capacity of different approaches for utterance-level SER. The benchmark is composed of nine datasets for SER in six languages. Since the datasets have different sizes and numbers of emotional classes, the proposed setup is particularly suitable for estimating the generalization capacity of pre-trained DNN-based feature extractors. We used the proposed framework to evaluate a selection of standard hand-crafted feature sets and state-of-the-art DNN representations. The results highlight that using only a subset of the data included in SERAB can result in biased evaluation, while compliance with the proposed protocol can circumvent this issue.