 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMikhail Smelyanskiy
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
Feb 09, 2017
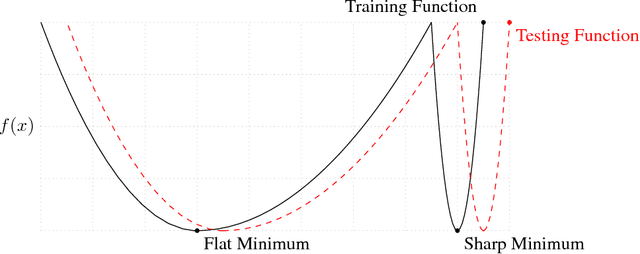
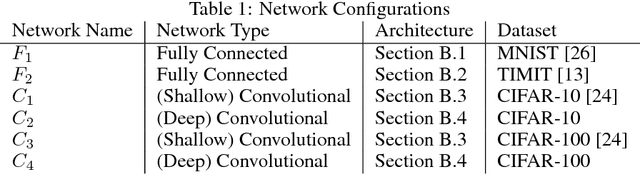
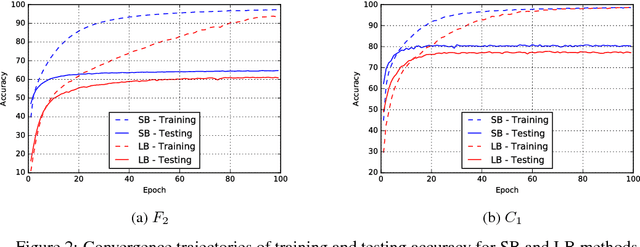
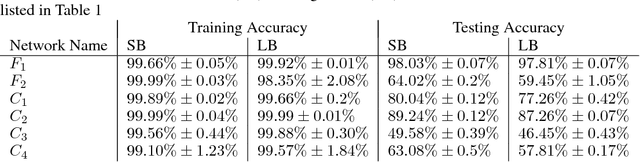
The stochastic gradient descent (SGD) method and its variants are algorithms of choice for many Deep Learning tasks. These methods operate in a small-batch regime wherein a fraction of the training data, say $32$-$512$ data points, is sampled to compute an approximation to the gradient. It has been observed in practice that when using a larger batch there is a degradation in the quality of the model, as measured by its ability to generalize. We investigate the cause for this generalization drop in the large-batch regime and present numerical evidence that supports the view that large-batch methods tend to converge to sharp minimizers of the training and testing functions - and as is well known, sharp minima lead to poorer generalization. In contrast, small-batch methods consistently converge to flat minimizers, and our experiments support a commonly held view that this is due to the inherent noise in the gradient estimation. We discuss several strategies to attempt to help large-batch methods eliminate this generalization gap.
Distributed Hessian-Free Optimization for Deep Neural Network
Jan 15, 2017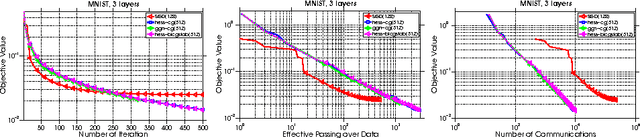
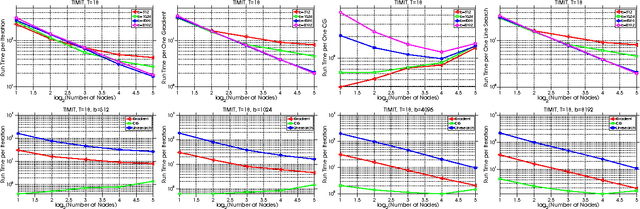
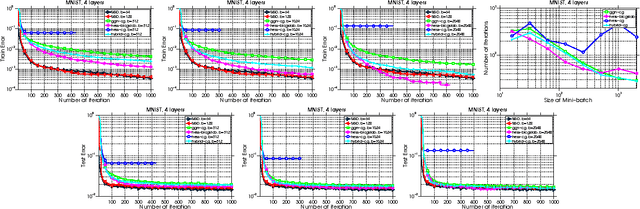
Training deep neural network is a high dimensional and a highly non-convex optimization problem. Stochastic gradient descent (SGD) algorithm and it's variations are the current state-of-the-art solvers for this task. However, due to non-covexity nature of the problem, it was observed that SGD slows down near saddle point. Recent empirical work claim that by detecting and escaping saddle point efficiently, it's more likely to improve training performance. With this objective, we revisit Hessian-free optimization method for deep networks. We also develop its distributed variant and demonstrate superior scaling potential to SGD, which allows more efficiently utilizing larger computing resources thus enabling large models and faster time to obtain desired solution. Furthermore, unlike truncated Newton method (Marten's HF) that ignores negative curvature information by using na\"ive conjugate gradient method and Gauss-Newton Hessian approximation information - we propose a novel algorithm to explore negative curvature direction by solving the sub-problem with stabilized bi-conjugate method involving possible indefinite stochastic Hessian information. We show that these techniques accelerate the training process for both the standard MNIST dataset and also the TIMIT speech recognition problem, demonstrating robust performance with upto an order of magnitude larger batch sizes. This increased scaling potential is illustrated with near linear speed-up on upto 16 CPU nodes for a simple 4-layer network.