 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching CLIP to Count to Ten
Feb 23, 2023



Large vision-language models (VLMs), such as CLIP, learn rich joint image-text representations, facilitating advances in numerous downstream tasks, including zero-shot classification and text-to-image generation. Nevertheless, existing VLMs exhibit a prominent well-documented limitation - they fail to encapsulate compositional concepts such as counting. We introduce a simple yet effective method to improve the quantitative understanding of VLMs, while maintaining their overall performance on common benchmarks. Specifically, we propose a new counting-contrastive loss used to finetune a pre-trained VLM in tandem with its original objective. Our counting loss is deployed over automatically-created counterfactual examples, each consisting of an image and a caption containing an incorrect object count. For example, an image depicting three dogs is paired with the caption "Six dogs playing in the yard". Our loss encourages discrimination between the correct caption and its counterfactual variant which serves as a hard negative example. To the best of our knowledge, this work is the first to extend CLIP's capabilities to object counting. Furthermore, we introduce "CountBench" - a new image-text counting benchmark for evaluating a model's understanding of object counting. We demonstrate a significant improvement over state-of-the-art baseline models on this task. Finally, we leverage our count-aware CLIP model for image retrieval and text-conditioned image generation, demonstrating that our model can produce specific counts of objects more reliably than existing ones.
SinFusion: Training Diffusion Models on a Single Image or Video
Nov 21, 2022



Diffusion models exhibited tremendous progress in image and video generation, exceeding GANs in quality and diversity. However, they are usually trained on very large datasets and are not naturally adapted to manipulate a given input image or video. In this paper we show how this can be resolved by training a diffusion model on a single input image or video. Our image/video-specific diffusion model (SinFusion) learns the appearance and dynamics of the single image or video, while utilizing the conditioning capabilities of diffusion models. It can solve a wide array of image/video-specific manipulation tasks. In particular, our model can learn from few frames the motion and dynamics of a single input video. It can then generate diverse new video samples of the same dynamic scene, extrapolate short videos into long ones (both forward and backward in time) and perform video upsampling. When trained on a single image, our model shows comparable performance and capabilities to previous single-image models in various image manipulation tasks.
Imagic: Text-Based Real Image Editing with Diffusion Models
Oct 17, 2022
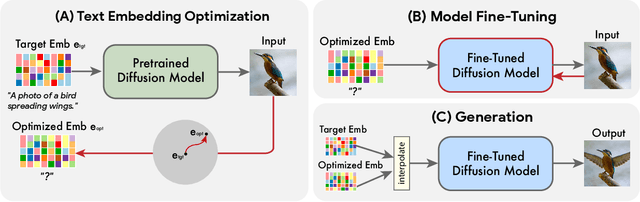


Text-conditioned image editing has recently attracted considerable interest. However, most methods are currently either limited to specific editing types (e.g., object overlay, style transfer), or apply to synthetically generated images, or require multiple input images of a common object. In this paper we demonstrate, for the very first time, the ability to apply complex (e.g., non-rigid) text-guided semantic edits to a single real image. For example, we can change the posture and composition of one or multiple objects inside an image, while preserving its original characteristics. Our method can make a standing dog sit down or jump, cause a bird to spread its wings, etc. -- each within its single high-resolution natural image provided by the user. Contrary to previous work, our proposed method requires only a single input image and a target text (the desired edit). It operates on real images, and does not require any additional inputs (such as image masks or additional views of the object). Our method, which we call "Imagic", leverages a pre-trained text-to-image diffusion model for this task. It produces a text embedding that aligns with both the input image and the target text, while fine-tuning the diffusion model to capture the image-specific appearance. We demonstrate the quality and versatility of our method on numerous inputs from various domains, showcasing a plethora of high quality complex semantic image edits, all within a single unified framework.
Combining Internal and External Constraints for Unrolling Shutter in Videos
Jul 24, 2022
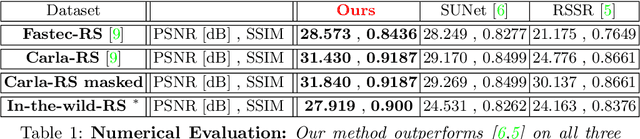

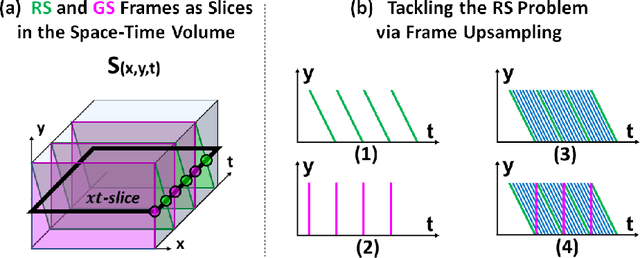
Videos obtained by rolling-shutter (RS) cameras result in spatially-distorted frames. These distortions become significant under fast camera/scene motions. Undoing effects of RS is sometimes addressed as a spatial problem, where objects need to be rectified/displaced in order to generate their correct global shutter (GS) frame. However, the cause of the RS effect is inherently temporal, not spatial. In this paper we propose a space-time solution to the RS problem. We observe that despite the severe differences between their xy frames, a RS video and its corresponding GS video tend to share the exact same xt slices -- up to a known sub-frame temporal shift. Moreover, they share the same distribution of small 2D xt-patches, despite the strong temporal aliasing within each video. This allows to constrain the GS output video using video-specific constraints imposed by the RS input video. Our algorithm is composed of 3 main components: (i) Dense temporal upsampling between consecutive RS frames using an off-the-shelf method, (which was trained on regular video sequences), from which we extract GS "proposals". (ii) Learning to correctly merge an ensemble of such GS "proposals" using a dedicated MergeNet. (iii) A video-specific zero-shot optimization which imposes the similarity of xt-patches between the GS output video and the RS input video. Our method obtains state-of-the-art results on benchmark datasets, both numerically and visually, despite being trained on a small synthetic RS/GS dataset. Moreover, it generalizes well to new complex RS videos with motion types outside the distribution of the training set (e.g., complex non-rigid motions) -- videos which competing methods trained on much more data cannot handle well. We attribute these generalization capabilities to the combination of external and internal constraints.
Reconstructing Training Data from Trained Neural Networks
Jun 15, 2022
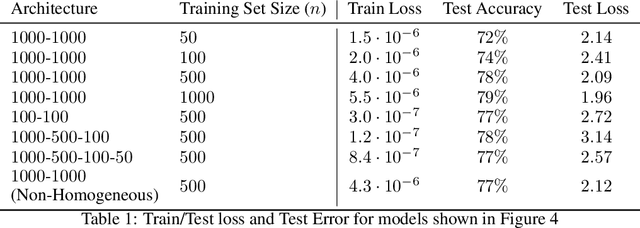
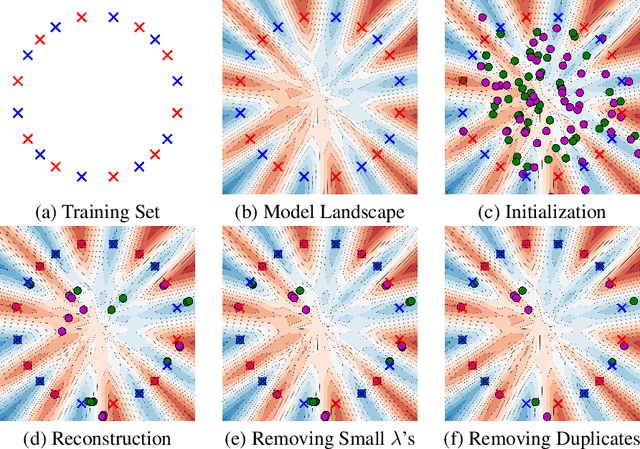
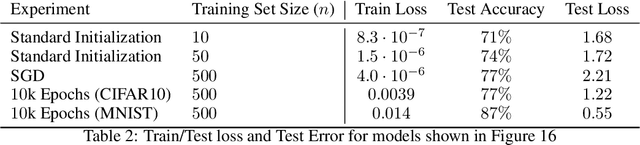
Understanding to what extent neural networks memorize training data is an intriguing question with practical and theoretical implications. In this paper we show that in some cases a significant fraction of the training data can in fact be reconstructed from the parameters of a trained neural network classifier. We propose a novel reconstruction scheme that stems from recent theoretical results about the implicit bias in training neural networks with gradient-based methods. To the best of our knowledge, our results are the first to show that reconstructing a large portion of the actual training samples from a trained neural network classifier is generally possible. This has negative implications on privacy, as it can be used as an attack for revealing sensitive training data. We demonstrate our method for binary MLP classifiers on a few standard computer vision datasets.
A Penny for Your Thoughts: Self-Supervised Reconstruction of Natural Movies from Brain Activity
Jun 10, 2022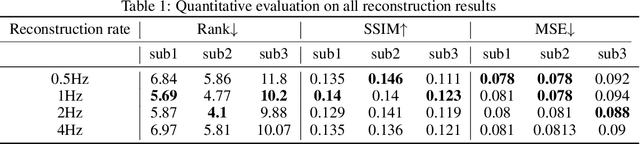
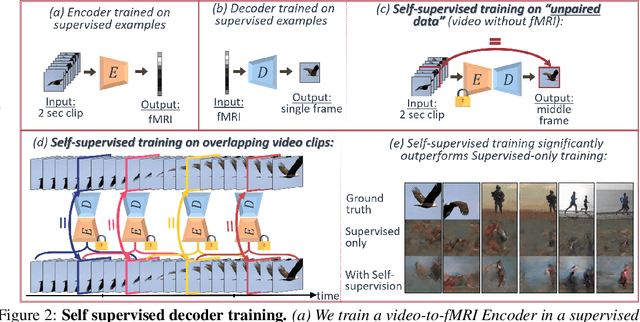


Reconstructing natural videos from fMRI brain recordings is very challenging, for two main reasons: (i) As fMRI data acquisition is difficult, we only have a limited amount of supervised samples, which is not enough to cover the huge space of natural videos; and (ii) The temporal resolution of fMRI recordings is much lower than the frame rate of natural videos. In this paper, we propose a self-supervised approach for natural-movie reconstruction. By employing cycle-consistency over Encoding-Decoding natural videos, we can: (i) exploit the full framerate of the training videos, and not be limited only to clips that correspond to fMRI recordings; (ii) exploit massive amounts of external natural videos which the subjects never saw inside the fMRI machine. These enable increasing the applicable training data by several orders of magnitude, introducing natural video priors to the decoding network, as well as temporal coherence. Our approach significantly outperforms competing methods, since those train only on the limited supervised data. We further introduce a new and simple temporal prior of natural videos, which - when folded into our fMRI decoder further - allows us to reconstruct videos at a higher frame-rate (HFR) of up to x8 of the original fMRI sample rate.
Diverse Video Generation from a Single Video
May 11, 2022

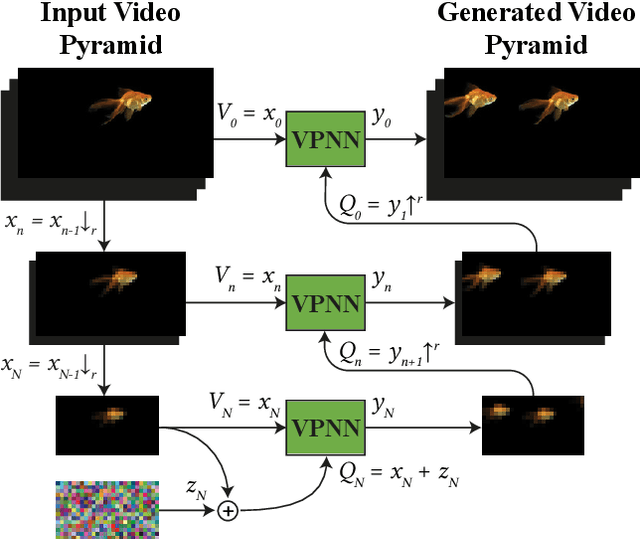
GANs are able to perform generation and manipulation tasks, trained on a single video. However, these single video GANs require unreasonable amount of time to train on a single video, rendering them almost impractical. In this paper we question the necessity of a GAN for generation from a single video, and introduce a non-parametric baseline for a variety of generation and manipulation tasks. We revive classical space-time patches-nearest-neighbors approaches and adapt them to a scalable unconditional generative model, without any learning. This simple baseline surprisingly outperforms single-video GANs in visual quality and realism (confirmed by quantitative and qualitative evaluations), and is disproportionately faster (runtime reduced from several days to seconds). Our approach is easily scaled to Full-HD videos. We also use the same framework to demonstrate video analogies and spatio-temporal retargeting. These observations show that classical approaches significantly outperform heavy deep learning machinery for these tasks. This sets a new baseline for single-video generation and manipulation tasks, and no less important -- makes diverse generation from a single video practically possible for the first time.
Self-Distilled StyleGAN: Towards Generation from Internet Photos
Feb 24, 2022
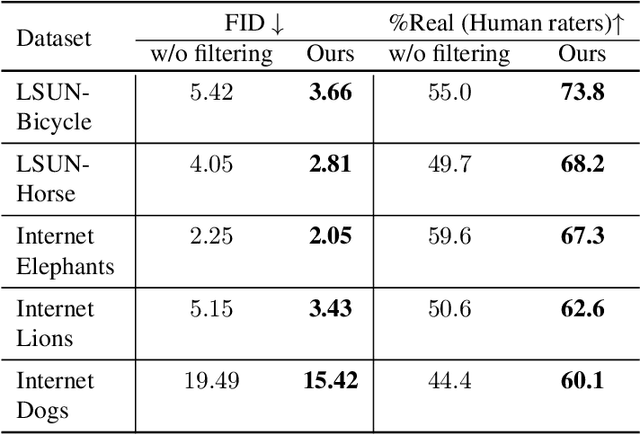
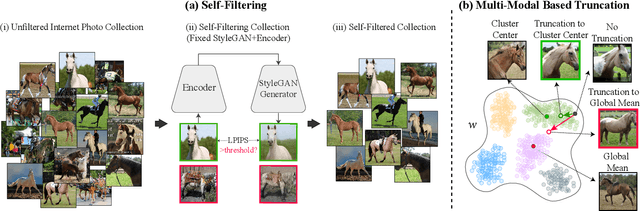
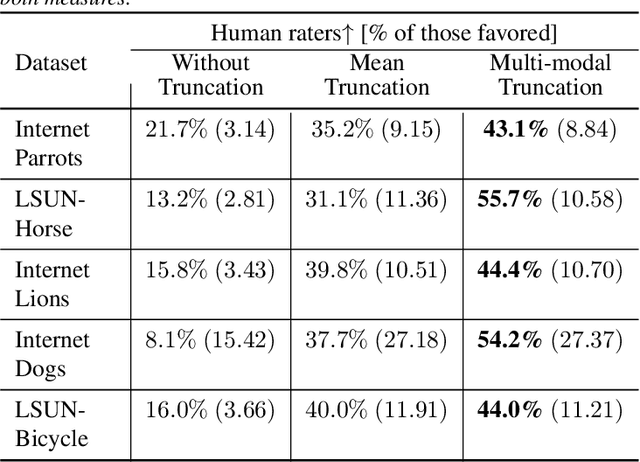
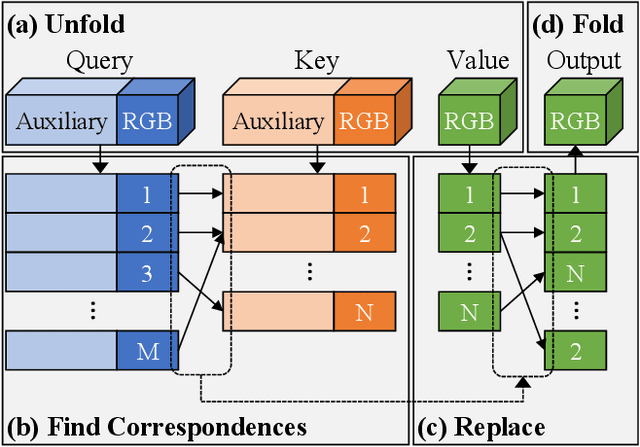
StyleGAN is known to produce high-fidelity images, while also offering unprecedented semantic editing. However, these fascinating abilities have been demonstrated only on a limited set of datasets, which are usually structurally aligned and well curated. In this paper, we show how StyleGAN can be adapted to work on raw uncurated images collected from the Internet. Such image collections impose two main challenges to StyleGAN: they contain many outlier images, and are characterized by a multi-modal distribution. Training StyleGAN on such raw image collections results in degraded image synthesis quality. To meet these challenges, we proposed a StyleGAN-based self-distillation approach, which consists of two main components: (i) A generative-based self-filtering of the dataset to eliminate outlier images, in order to generate an adequate training set, and (ii) Perceptual clustering of the generated images to detect the inherent data modalities, which are then employed to improve StyleGAN's "truncation trick" in the image synthesis process. The presented technique enables the generation of high-quality images, while minimizing the loss in diversity of the data. Through qualitative and quantitative evaluation, we demonstrate the power of our approach to new challenging and diverse domains collected from the Internet. New datasets and pre-trained models are available at https://self-distilled-stylegan.github.io/ .
Pure Noise to the Rescue of Insufficient Data: Improving Imbalanced Classification by Training on Random Noise Images
Dec 16, 2021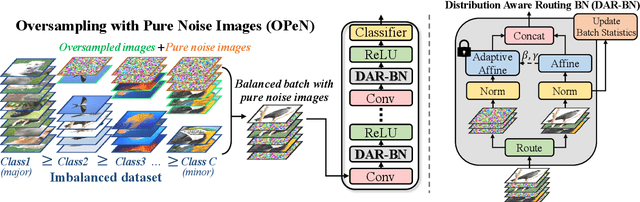

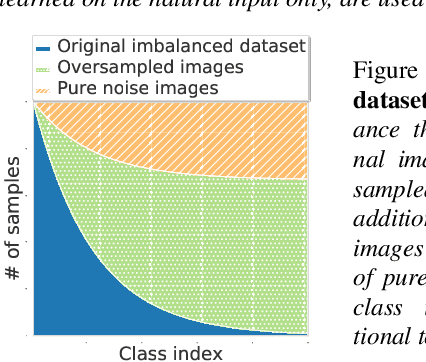
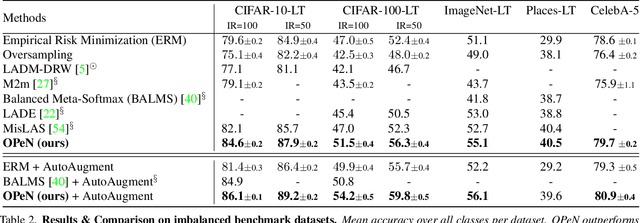
Despite remarkable progress on visual recognition tasks, deep neural-nets still struggle to generalize well when training data is scarce or highly imbalanced, rendering them extremely vulnerable to real-world examples. In this paper, we present a surprisingly simple yet highly effective method to mitigate this limitation: using pure noise images as additional training data. Unlike the common use of additive noise or adversarial noise for data augmentation, we propose an entirely different perspective by directly training on pure random noise images. We present a new Distribution-Aware Routing Batch Normalization layer (DAR-BN), which enables training on pure noise images in addition to natural images within the same network. This encourages generalization and suppresses overfitting. Our proposed method significantly improves imbalanced classification performance, obtaining state-of-the-art results on a large variety of long-tailed image classification datasets (CIFAR-10-LT, CIFAR-100-LT, ImageNet-LT, Places-LT, and CelebA-5). Furthermore, our method is extremely simple and easy to use as a general new augmentation tool (on top of existing augmentations), and can be incorporated in any training scheme. It does not require any specialized data generation or training procedures, thus keeping training fast and efficient
Diverse Generation from a Single Video Made Possible
Sep 17, 2021

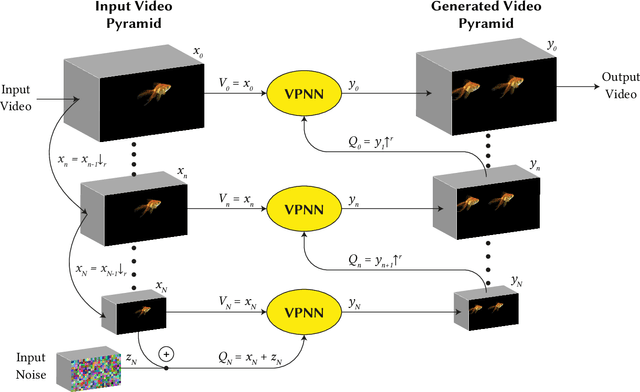
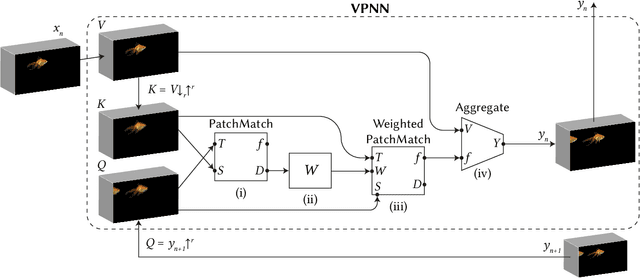
Most advanced video generation and manipulation methods train on a large collection of videos. As such, they are restricted to the types of video dynamics they train on. To overcome this limitation, GANs trained on a single video were recently proposed. While these provide more flexibility to a wide variety of video dynamics, they require days to train on a single tiny input video, rendering them impractical. In this paper we present a fast and practical method for video generation and manipulation from a single natural video, which generates diverse high-quality video outputs within seconds (for benchmark videos). Our method can be further applied to Full-HD video clips within minutes. Our approach is inspired by a recent advanced patch-nearest-neighbor based approach [Granot et al. 2021], which was shown to significantly outperform single-image GANs, both in run-time and in visual quality. Here we generalize this approach from images to videos, by casting classical space-time patch-based methods as a new generative video model. We adapt the generative image patch nearest neighbor approach to efficiently cope with the huge number of space-time patches in a single video. Our method generates more realistic and higher quality results than single-video GANs (confirmed by quantitative and qualitative evaluations). Moreover, it is disproportionally faster (runtime reduced from several days to seconds). Other than diverse video generation, we demonstrate several other challenging video applications, including spatio-temporal video retargeting, video structural analogies and conditional video-inpainting.