 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning the Scheduling of Distributed Stochastic Gradient Descent with Bayesian Optimization
Dec 01, 2016
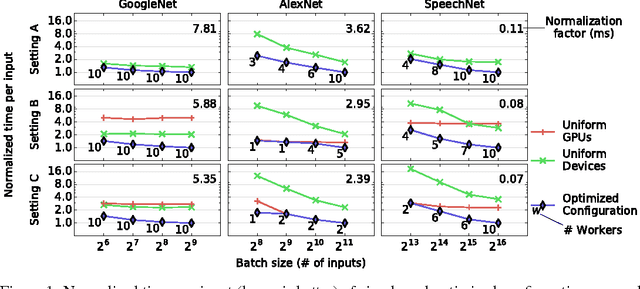

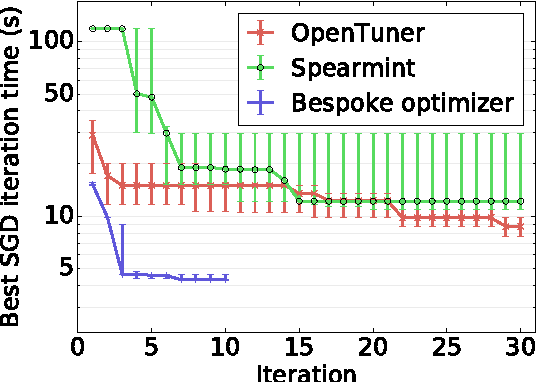
We present an optimizer which uses Bayesian optimization to tune the system parameters of distributed stochastic gradient descent (SGD). Given a specific context, our goal is to quickly find efficient configurations which appropriately balance the load between the available machines to minimize the average SGD iteration time. Our experiments consider setups with over thirty parameters. Traditional Bayesian optimization, which uses a Gaussian process as its model, is not well suited to such high dimensional domains. To reduce convergence time, we exploit the available structure. We design a probabilistic model which simulates the behavior of distributed SGD and use it within Bayesian optimization. Our model can exploit many runtime measurements for inference per evaluation of the objective function. Our experiments show that our resulting optimizer converges to efficient configurations within ten iterations, the optimized configurations outperform those found by generic optimizer in thirty iterations by up to 2X.
Learning Runtime Parameters in Computer Systems with Delayed Experience Injection
Oct 31, 2016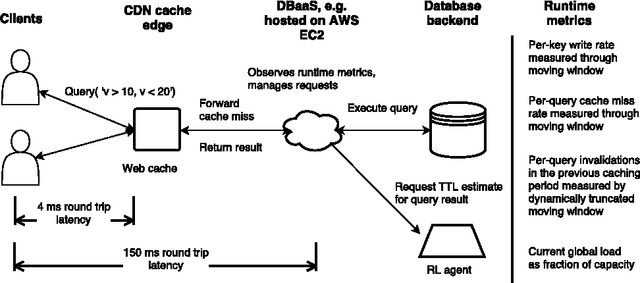
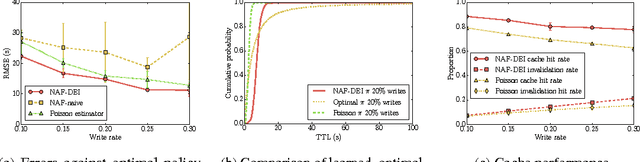
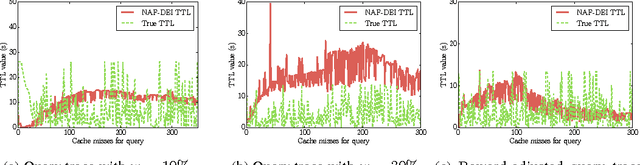
Learning effective configurations in computer systems without hand-crafting models for every parameter is a long-standing problem. This paper investigates the use of deep reinforcement learning for runtime parameters of cloud databases under latency constraints. Cloud services serve up to thousands of concurrent requests per second and can adjust critical parameters by leveraging performance metrics. In this work, we use continuous deep reinforcement learning to learn optimal cache expirations for HTTP caching in content delivery networks. To this end, we introduce a technique for asynchronous experience management called delayed experience injection, which facilitates delayed reward and next-state computation in concurrent environments where measurements are not immediately available. Evaluation results show that our approach based on normalized advantage functions and asynchronous CPU-only training outperforms a statistical estimator.