 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMichael Laskin
Reinforcement Learning with Augmented Data
Apr 30, 2020
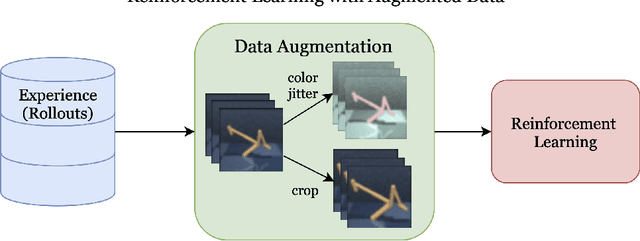
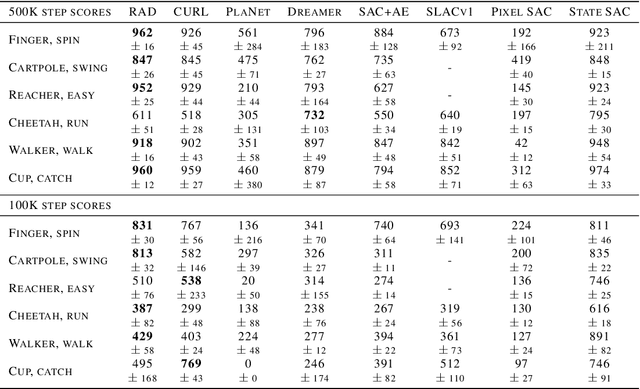

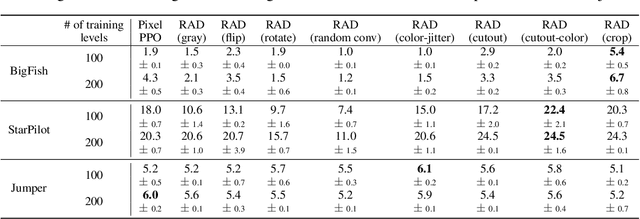
Learning from visual observations is a fundamental yet challenging problem in reinforcement learning (RL). Although algorithmic advancements combined with convolutional neural networks have proved to be a recipe for success, current methods are still lacking on two fronts: (a) sample efficiency of learning and (b) generalization to new environments. To this end, we present RAD: Reinforcement Learning with Augmented Data, a simple plug-and-play module that can enhance any RL algorithm. We show that data augmentations such as random crop, color jitter, patch cutout, and random convolutions can enable simple RL algorithms to match and even outperform complex state-of-the-art methods across common benchmarks in terms of data-efficiency, generalization, and wall-clock speed. We find that data diversity alone can make agents focus on meaningful information from high-dimensional observations without any changes to the reinforcement learning method. On the DeepMind Control Suite, we show that RAD is state-of-the-art in terms of data-efficiency and performance across 15 environments. We further demonstrate that RAD can significantly improve the test-time generalization on several OpenAI ProcGen benchmarks. Finally, our customized data augmentation modules enable faster wall-clock speed compared to competing RL techniques. Our RAD module and training code are available at https://www.github.com/MishaLaskin/rad.
CURL: Contrastive Unsupervised Representations for Reinforcement Learning
Apr 28, 2020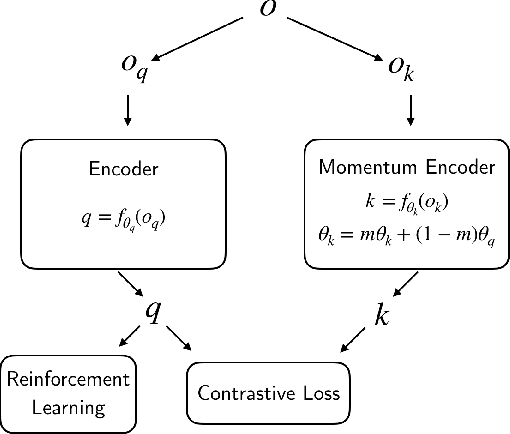
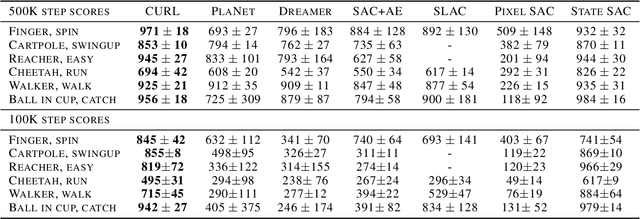
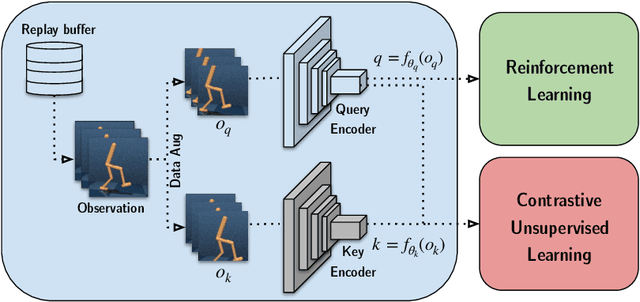
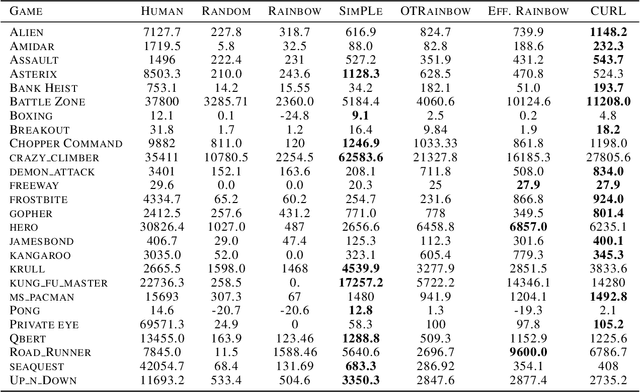
We present CURL: Contrastive Unsupervised Representations for Reinforcement Learning. CURL extracts high-level features from raw pixels using contrastive learning and performs off-policy control on top of the extracted features. CURL outperforms prior pixel-based methods, both model-based and model-free, on complex tasks in the DeepMind Control Suite and Atari Games showing 1.9x and 1.6x performance gains at the 100K environment and interaction steps benchmarks respectively. On the DeepMind Control Suite, CURL is the first image-based algorithm to nearly match the sample-efficiency and performance of methods that use state-based features.
Sparse Graphical Memory for Robust Planning
Mar 13, 2020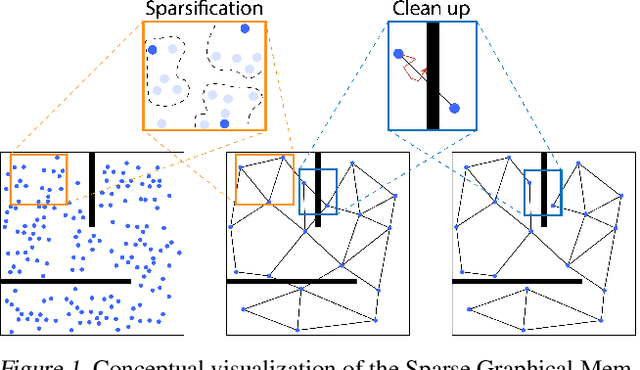
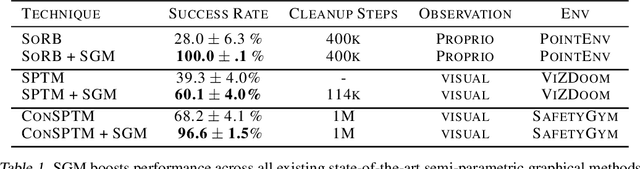
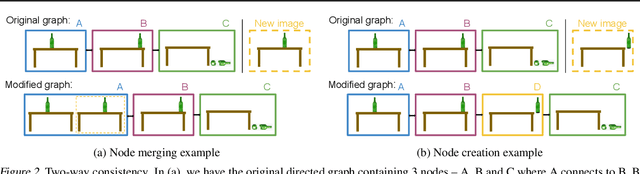
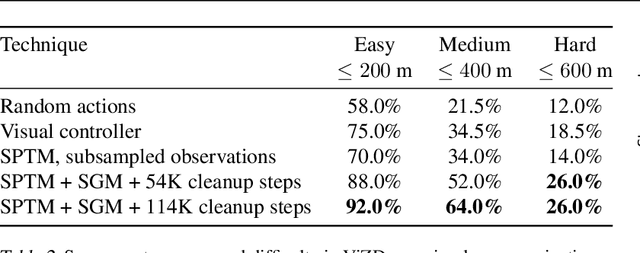
To operate effectively in the real world, artificial agents must act from raw sensory input such as images and achieve diverse goals across long time-horizons. On the one hand, recent strides in deep reinforcement and imitation learning have demonstrated impressive ability to learn goal-conditioned policies from high-dimensional image input, though only for short-horizon tasks. On the other hand, classical graphical methods like A* search are able to solve long-horizon tasks, but assume that the graph structure is abstracted away from raw sensory input and can only be constructed with task-specific priors. We wish to combine the strengths of deep learning and classical planning to solve long-horizon tasks from raw sensory input. To this end, we introduce Sparse Graphical Memory (SGM), a new data structure that stores observations and feasible transitions in a sparse memory. SGM can be combined with goal-conditioned RL or imitative agents to solve long-horizon tasks across a diverse set of domains. We show that SGM significantly outperforms current state of the art methods on long-horizon, sparse-reward visual navigation tasks. Project video and code are available at https://mishalaskin.github.io/sgm/