 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverseNet: When One Right Answer is not Enough
Aug 24, 2020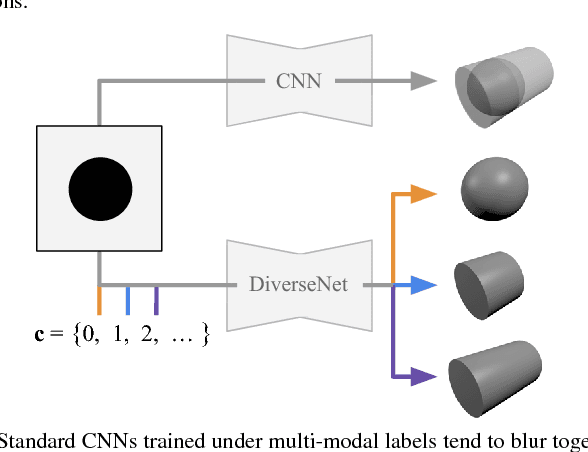
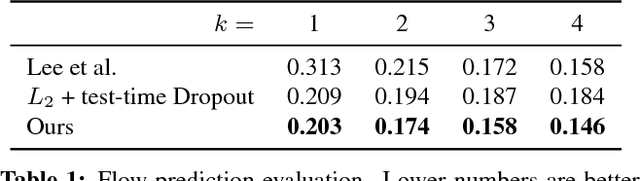
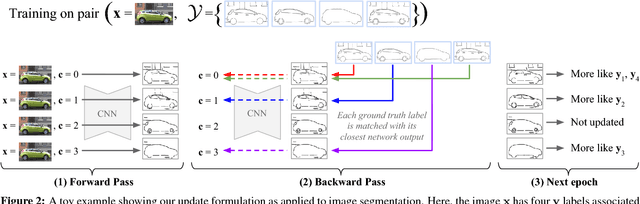
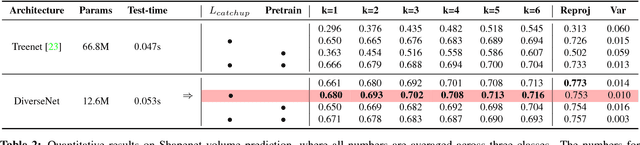
Many structured prediction tasks in machine vision have a collection of acceptable answers, instead of one definitive ground truth answer. Segmentation of images, for example, is subject to human labeling bias. Similarly, there are multiple possible pixel values that could plausibly complete occluded image regions. State-of-the art supervised learning methods are typically optimized to make a single test-time prediction for each query, failing to find other modes in the output space. Existing methods that allow for sampling often sacrifice speed or accuracy. We introduce a simple method for training a neural network, which enables diverse structured predictions to be made for each test-time query. For a single input, we learn to predict a range of possible answers. We compare favorably to methods that seek diversity through an ensemble of networks. Such stochastic multiple choice learning faces mode collapse, where one or more ensemble members fail to receive any training signal. Our best performing solution can be deployed for various tasks, and just involves small modifications to the existing single-mode architecture, loss function, and training regime. We demonstrate that our method results in quantitative improvements across three challenging tasks: 2D image completion, 3D volume estimation, and flow prediction.
Learning Stereo from Single Images
Aug 20, 2020
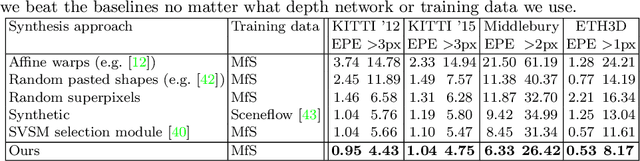
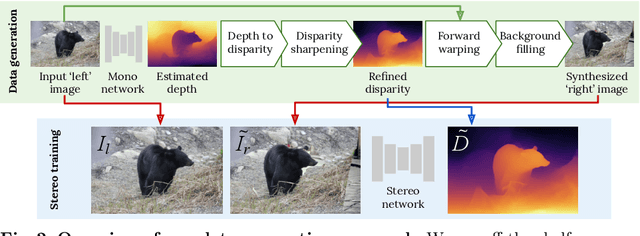

Supervised deep networks are among the best methods for finding correspondences in stereo image pairs. Like all supervised approaches, these networks require ground truth data during training. However, collecting large quantities of accurate dense correspondence data is very challenging. We propose that it is unnecessary to have such a high reliance on ground truth depths or even corresponding stereo pairs. Inspired by recent progress in monocular depth estimation, we generate plausible disparity maps from single images. In turn, we use those flawed disparity maps in a carefully designed pipeline to generate stereo training pairs. Training in this manner makes it possible to convert any collection of single RGB images into stereo training data. This results in a significant reduction in human effort, with no need to collect real depths or to hand-design synthetic data. We can consequently train a stereo matching network from scratch on datasets like COCO, which were previously hard to exploit for stereo. Through extensive experiments we show that our approach outperforms stereo networks trained with standard synthetic datasets, when evaluated on KITTI, ETH3D, and Middlebury.
Footprints and Free Space from a Single Color Image
Apr 14, 2020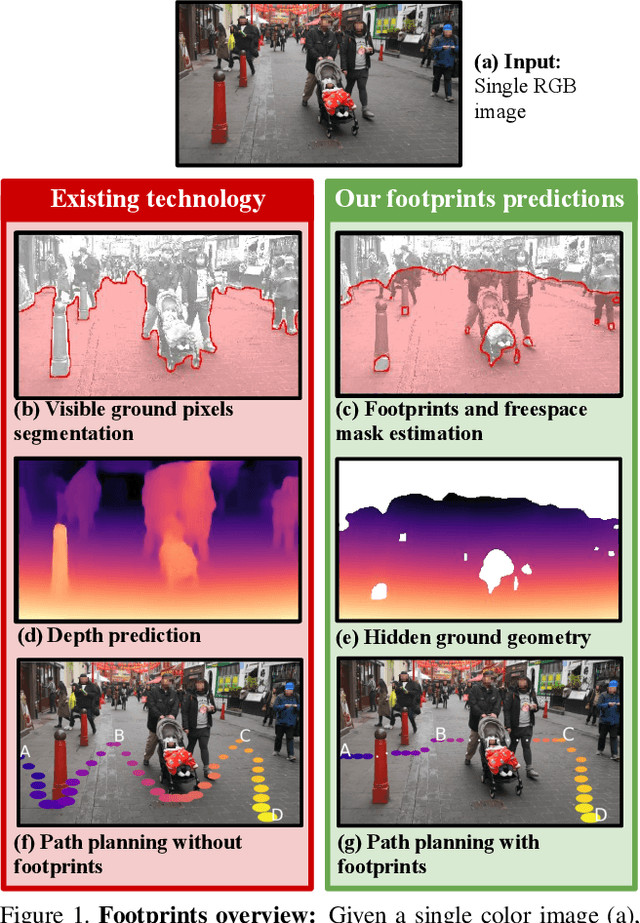
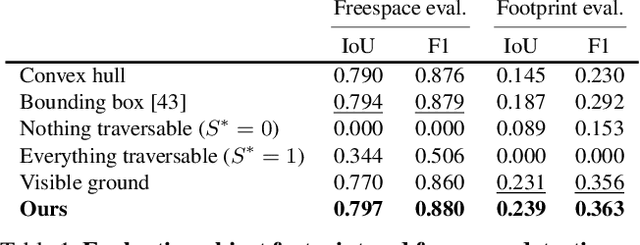
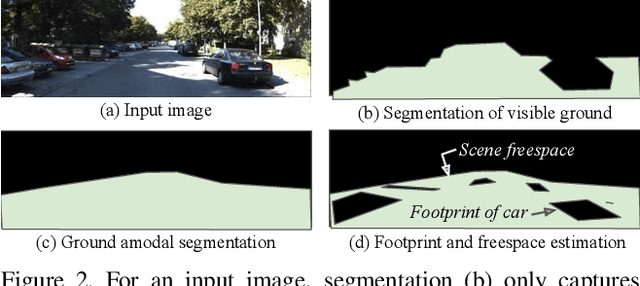
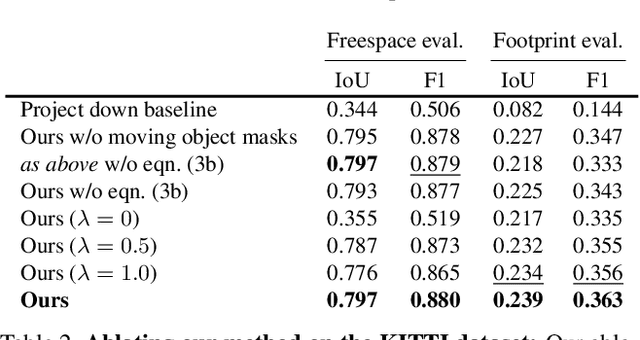
Understanding the shape of a scene from a single color image is a formidable computer vision task. However, most methods aim to predict the geometry of surfaces that are visible to the camera, which is of limited use when planning paths for robots or augmented reality agents. Such agents can only move when grounded on a traversable surface, which we define as the set of classes which humans can also walk over, such as grass, footpaths and pavement. Models which predict beyond the line of sight often parameterize the scene with voxels or meshes, which can be expensive to use in machine learning frameworks. We introduce a model to predict the geometry of both visible and occluded traversable surfaces, given a single RGB image as input. We learn from stereo video sequences, using camera poses, per-frame depth and semantic segmentation to form training data, which is used to supervise an image-to-image network. We train models from the KITTI driving dataset, the indoor Matterport dataset, and from our own casually captured stereo footage. We find that a surprisingly low bar for spatial coverage of training scenes is required. We validate our algorithm against a range of strong baselines, and include an assessment of our predictions for a path-planning task.
Self-Supervised Monocular Depth Hints
Sep 19, 2019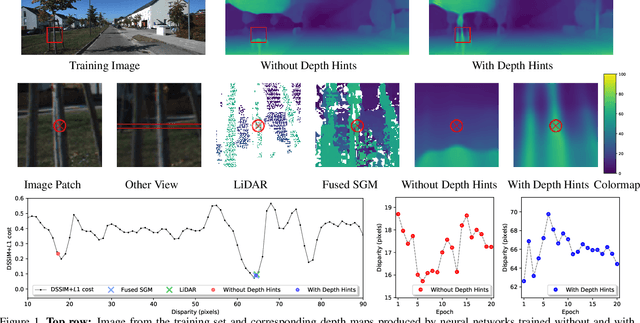
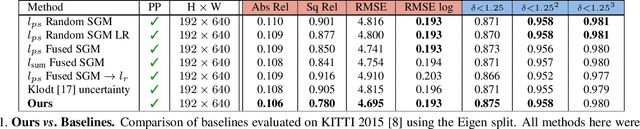
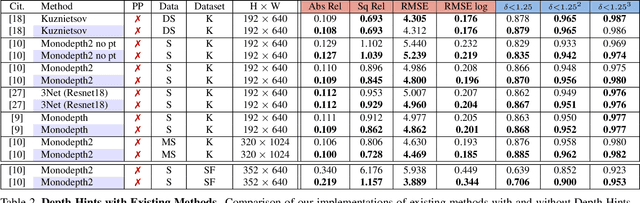
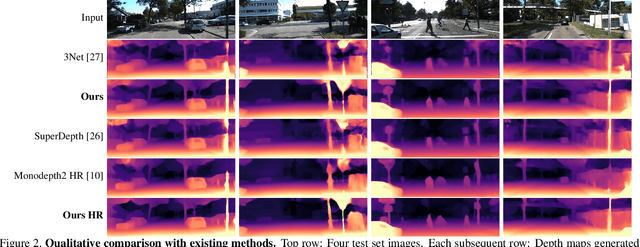
Monocular depth estimators can be trained with various forms of self-supervision from binocular-stereo data to circumvent the need for high-quality laser scans or other ground-truth data. The disadvantage, however, is that the photometric reprojection losses used with self-supervised learning typically have multiple local minima. These plausible-looking alternatives to ground truth can restrict what a regression network learns, causing it to predict depth maps of limited quality. As one prominent example, depth discontinuities around thin structures are often incorrectly estimated by current state-of-the-art methods. Here, we study the problem of ambiguous reprojections in depth prediction from stereo-based self-supervision, and introduce Depth Hints to alleviate their effects. Depth Hints are complementary depth suggestions obtained from simple off-the-shelf stereo algorithms. These hints enhance an existing photometric loss function, and are used to guide a network to learn better weights. They require no additional data, and are assumed to be right only sometimes. We show that using our Depth Hints gives a substantial boost when training several leading self-supervised-from-stereo models, not just our own. Further, combined with other good practices, we produce state-of-the-art depth predictions on the KITTI benchmark.
RGBD Datasets: Past, Present and Future
Apr 13, 2016

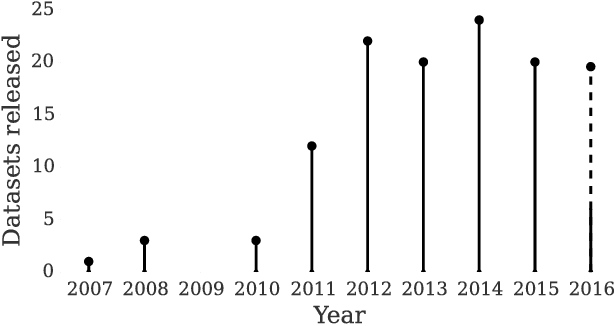
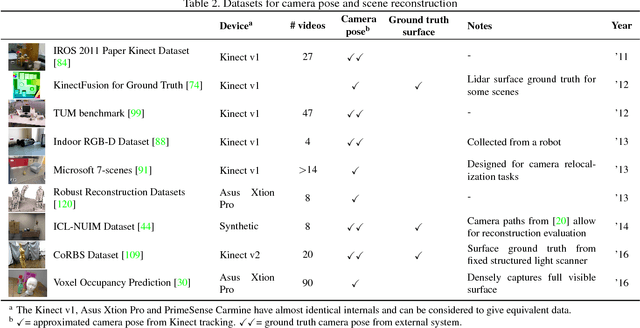
Since the launch of the Microsoft Kinect, scores of RGBD datasets have been released. These have propelled advances in areas from reconstruction to gesture recognition. In this paper we explore the field, reviewing datasets across eight categories: semantics, object pose estimation, camera tracking, scene reconstruction, object tracking, human actions, faces and identification. By extracting relevant information in each category we help researchers to find appropriate data for their needs, and we consider which datasets have succeeded in driving computer vision forward and why. Finally, we examine the future of RGBD datasets. We identify key areas which are currently underexplored, and suggest that future directions may include synthetic data and dense reconstructions of static and dynamic scenes.