 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeng Zhang
A Deep-Learning Intelligent System Incorporating Data Augmentation for Short-Term Voltage Stability Assessment of Power Systems
Dec 05, 2021
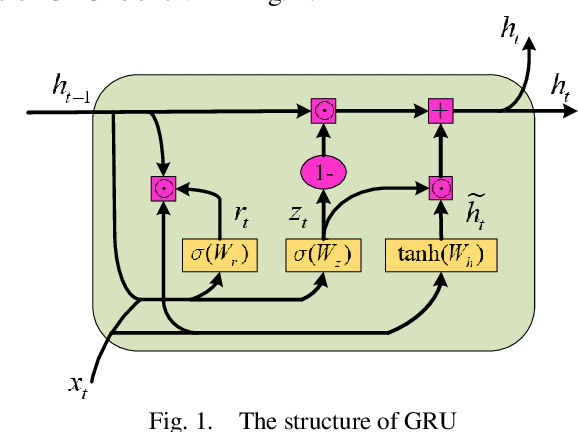
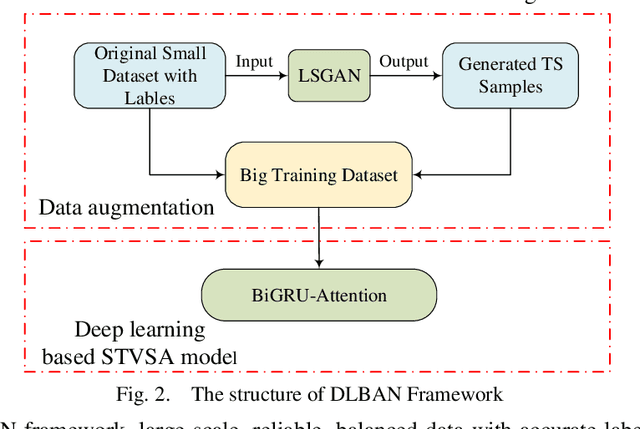
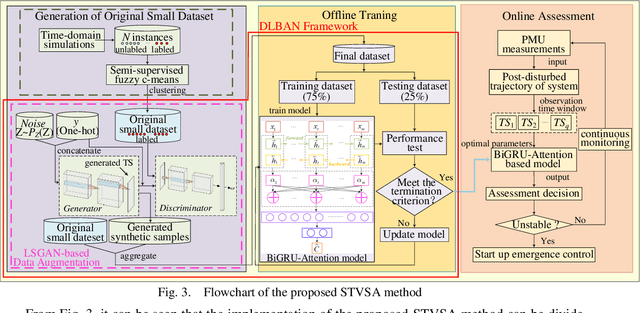
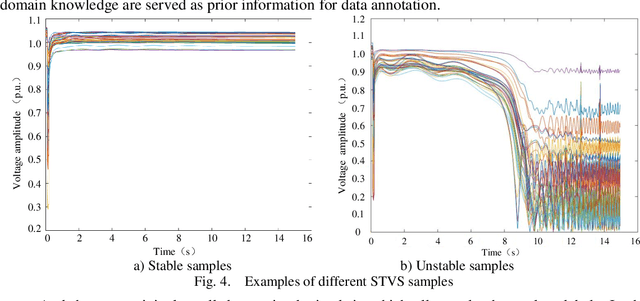
Facing the difficulty of expensive and trivial data collection and annotation, how to make a deep learning-based short-term voltage stability assessment (STVSA) model work well on a small training dataset is a challenging and urgent problem. Although a big enough dataset can be directly generated by contingency simulation, this data generation process is usually cumbersome and inefficient; while data augmentation provides a low-cost and efficient way to artificially inflate the representative and diversified training datasets with label preserving transformations. In this respect, this paper proposes a novel deep-learning intelligent system incorporating data augmentation for STVSA of power systems. First, due to the unavailability of reliable quantitative criteria to judge the stability status for a specific power system, semi-supervised cluster learning is leveraged to obtain labeled samples in an original small dataset. Second, to make deep learning applicable to the small dataset, conditional least squares generative adversarial networks (LSGAN)-based data augmentation is introduced to expand the original dataset via artificially creating additional valid samples. Third, to extract temporal dependencies from the post-disturbance dynamic trajectories of a system, a bi-directional gated recurrent unit with attention mechanism based assessment model is established, which bi-directionally learns the significant time dependencies and automatically allocates attention weights. The test results demonstrate the presented approach manages to achieve better accuracy and a faster response time with original small datasets. Besides classification accuracy, this work employs statistical measures to comprehensively examine the performance of the proposal.
Uncertainty-Aware Balancing for Multilingual and Multi-Domain Neural Machine Translation Training
Sep 06, 2021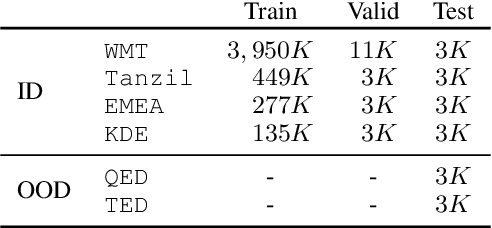
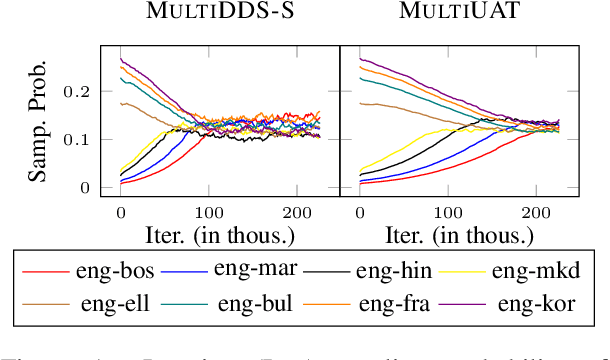
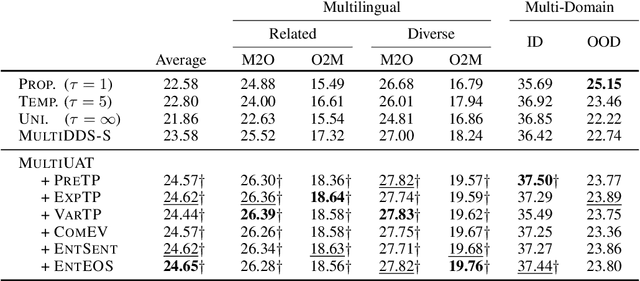
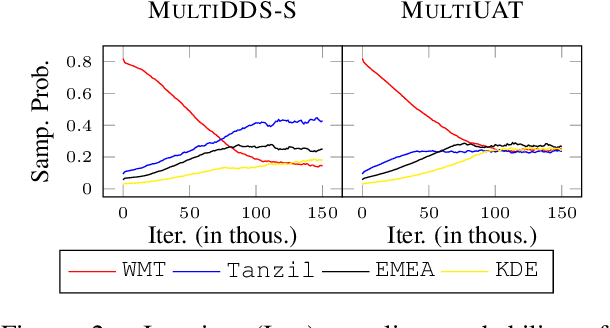
Learning multilingual and multi-domain translation model is challenging as the heterogeneous and imbalanced data make the model converge inconsistently over different corpora in real world. One common practice is to adjust the share of each corpus in the training, so that the learning process is balanced and low-resource cases can benefit from the high resource ones. However, automatic balancing methods usually depend on the intra- and inter-dataset characteristics, which is usually agnostic or requires human priors. In this work, we propose an approach, MultiUAT, that dynamically adjusts the training data usage based on the model's uncertainty on a small set of trusted clean data for multi-corpus machine translation. We experiments with two classes of uncertainty measures on multilingual (16 languages with 4 settings) and multi-domain settings (4 for in-domain and 2 for out-of-domain on English-German translation) and demonstrate our approach MultiUAT substantially outperforms its baselines, including both static and dynamic strategies. We analyze the cross-domain transfer and show the deficiency of static and similarity based methods.
SimulLR: Simultaneous Lip Reading Transducer with Attention-Guided Adaptive Memory
Aug 31, 2021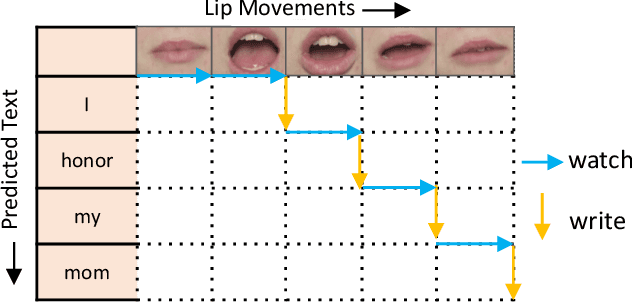
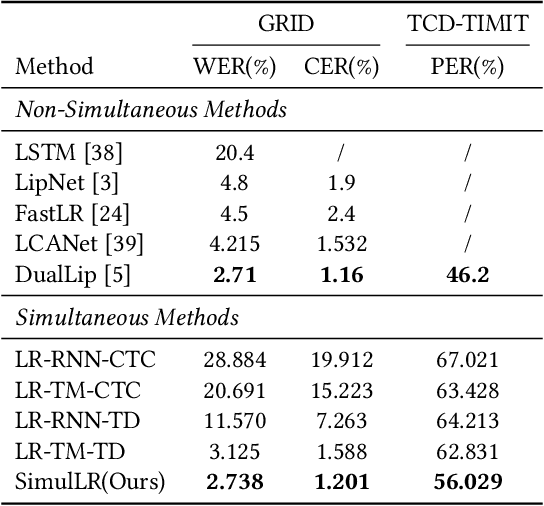
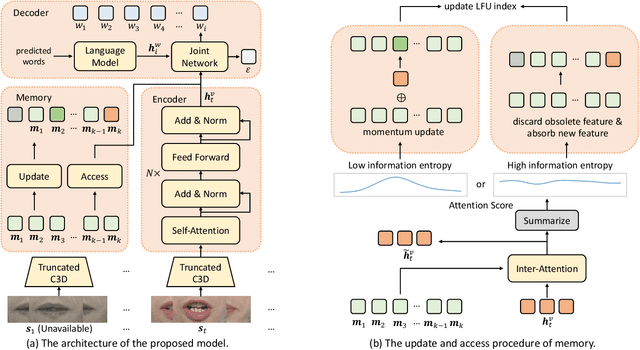
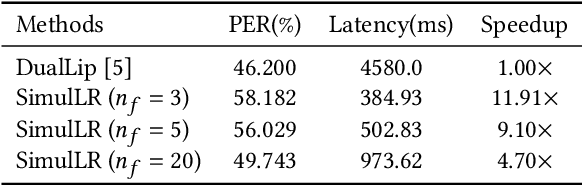
Lip reading, aiming to recognize spoken sentences according to the given video of lip movements without relying on the audio stream, has attracted great interest due to its application in many scenarios. Although prior works that explore lip reading have obtained salient achievements, they are all trained in a non-simultaneous manner where the predictions are generated requiring access to the full video. To breakthrough this constraint, we study the task of simultaneous lip reading and devise SimulLR, a simultaneous lip Reading transducer with attention-guided adaptive memory from three aspects: (1) To address the challenge of monotonic alignments while considering the syntactic structure of the generated sentences under simultaneous setting, we build a transducer-based model and design several effective training strategies including CTC pre-training, model warm-up and curriculum learning to promote the training of the lip reading transducer. (2) To learn better spatio-temporal representations for simultaneous encoder, we construct a truncated 3D convolution and time-restricted self-attention layer to perform the frame-to-frame interaction within a video segment containing fixed number of frames. (3) The history information is always limited due to the storage in real-time scenarios, especially for massive video data. Therefore, we devise a novel attention-guided adaptive memory to organize semantic information of history segments and enhance the visual representations with acceptable computation-aware latency. The experiments show that the SimulLR achieves the translation speedup 9.10$\times$ compared with the state-of-the-art non-simultaneous methods, and also obtains competitive results, which indicates the effectiveness of our proposed methods.
Autoencoder-based Semantic Novelty Detection: Towards Dependable AI-based Systems
Aug 25, 2021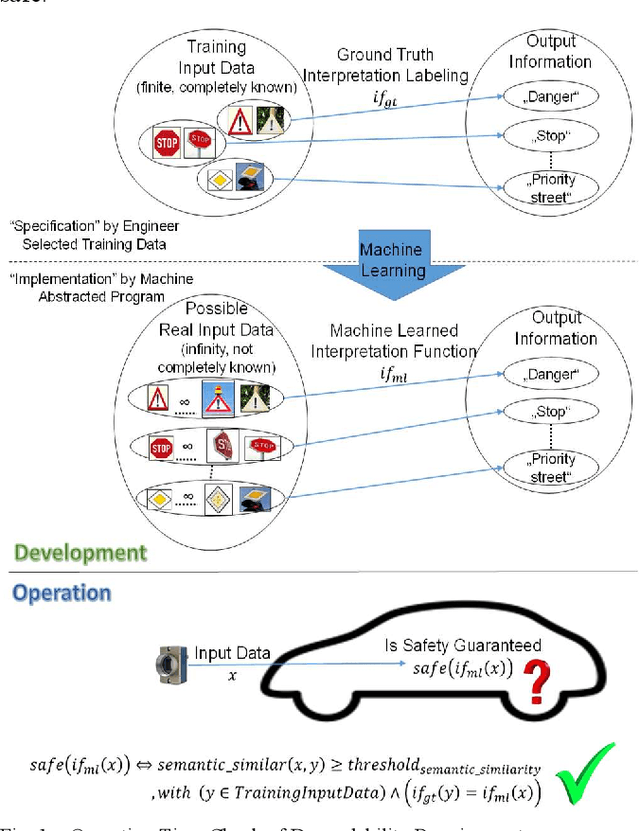
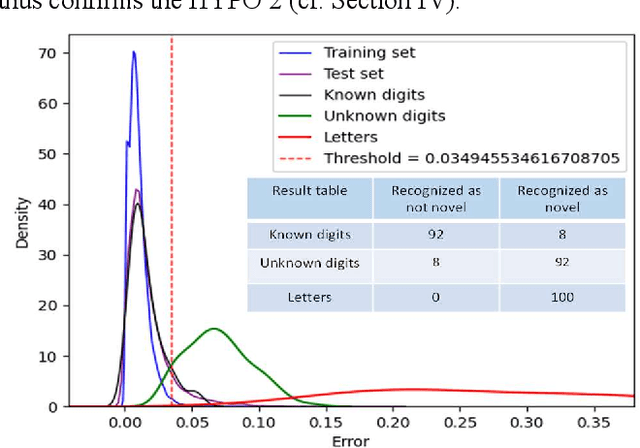
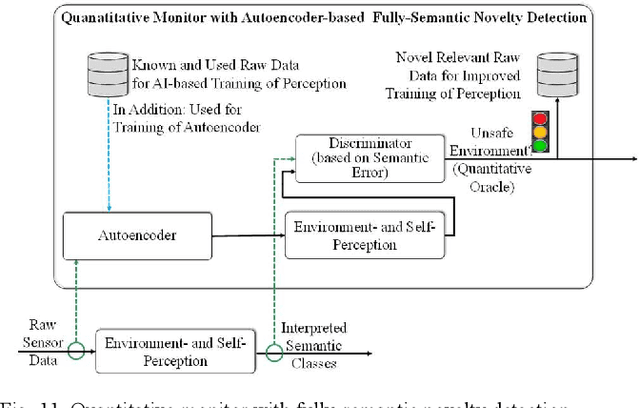
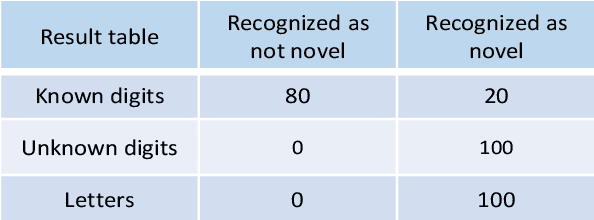
Many autonomous systems, such as driverless taxis, perform safety critical functions. Autonomous systems employ artificial intelligence (AI) techniques, specifically for the environment perception. Engineers cannot completely test or formally verify AI-based autonomous systems. The accuracy of AI-based systems depends on the quality of training data. Thus, novelty detection - identifying data that differ in some respect from the data used for training - becomes a safety measure for system development and operation. In this paper, we propose a new architecture for autoencoder-based semantic novelty detection with two innovations: architectural guidelines for a semantic autoencoder topology and a semantic error calculation as novelty criteria. We demonstrate that such a semantic novelty detection outperforms autoencoder-based novelty detection approaches known from literature by minimizing false negatives.
Faithful Edge Federated Learning: Scalability and Privacy
Jun 30, 2021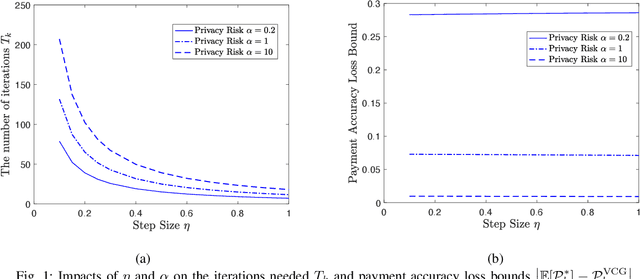
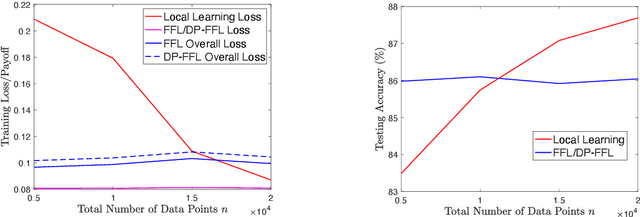
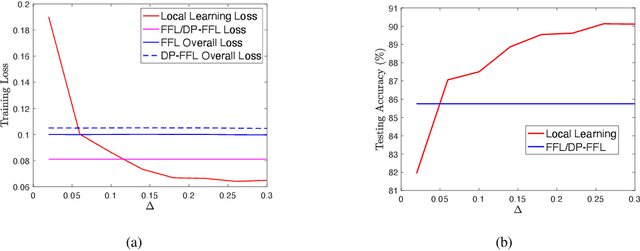
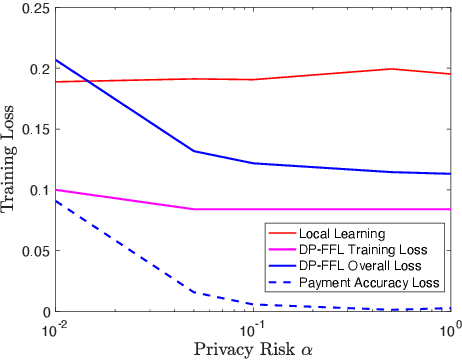
Federated learning enables machine learning algorithms to be trained over a network of multiple decentralized edge devices without requiring the exchange of local datasets. Successfully deploying federated learning requires ensuring that agents (e.g., mobile devices) faithfully execute the intended algorithm, which has been largely overlooked in the literature. In this study, we first use risk bounds to analyze how the key feature of federated learning, unbalanced and non-i.i.d. data, affects agents' incentives to voluntarily participate and obediently follow traditional federated learning algorithms. To be more specific, our analysis reveals that agents with less typical data distributions and relatively more samples are more likely to opt out of or tamper with federated learning algorithms. To this end, we formulate the first faithful implementation problem of federated learning and design two faithful federated learning mechanisms which satisfy economic properties, scalability, and privacy. Further, the time complexity of computing all agents' payments in the number of agents is $\mathcal{O}(1)$. First, we design a Faithful Federated Learning (FFL) mechanism which approximates the Vickrey-Clarke-Groves (VCG) payments via an incremental computation. We show that it achieves (probably approximate) optimality, faithful implementation, voluntary participation, and some other economic properties (such as budget balance). Second, by partitioning agents into several subsets, we present a scalable VCG mechanism approximation. We further design a scalable and Differentially Private FFL (DP-FFL) mechanism, the first differentially private faithful mechanism, that maintains the economic properties. Our mechanism enables one to make three-way performance tradeoffs among privacy, the iterations needed, and payment accuracy loss.
Dynamic Neural Garments
Feb 23, 2021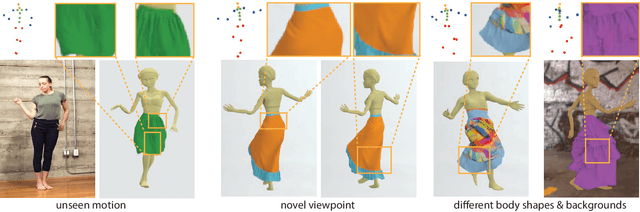
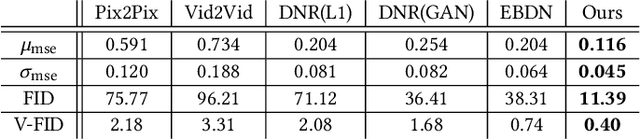
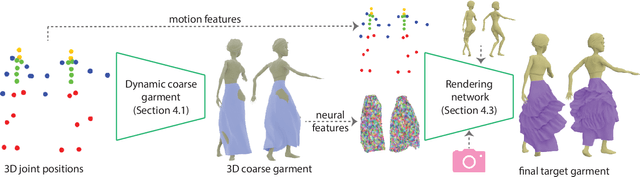

A vital task of the wider digital human effort is the creation of realistic garments on digital avatars, both in the form of characteristic fold patterns and wrinkles in static frames as well as richness of garment dynamics under avatars' motion. Existing workflow of modeling, simulation, and rendering closely replicates the physics behind real garments, but is tedious and requires repeating most of the workflow under changes to characters' motion, camera angle, or garment resizing. Although data-driven solutions exist, they either focus on static scenarios or only handle dynamics of tight garments. We present a solution that, at test time, takes in body joint motion to directly produce realistic dynamic garment image sequences. Specifically, given the target joint motion sequence of an avatar, we propose dynamic neural garments to jointly simulate and render plausible dynamic garment appearance from an unseen viewpoint. Technically, our solution generates a coarse garment proxy sequence, learns deep dynamic features attached to this template, and neurally renders the features to produce appearance changes such as folds, wrinkles, and silhouettes. We demonstrate generalization behavior to both unseen motion and unseen camera views. Further, our network can be fine-tuned to adopt to new body shape and/or background images. We also provide comparisons against existing neural rendering and image sequence translation approaches, and report clear quantitative improvements.
L2E: Learning to Exploit Your Opponent
Feb 18, 2021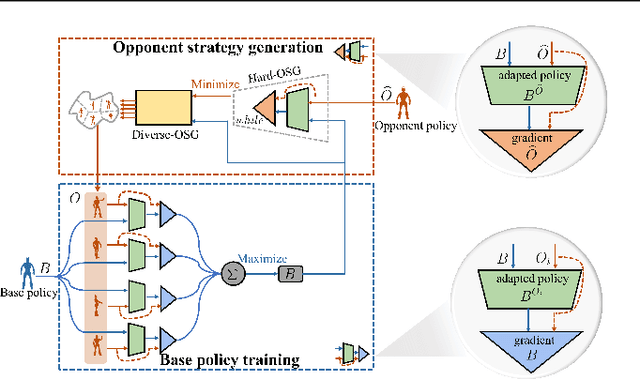


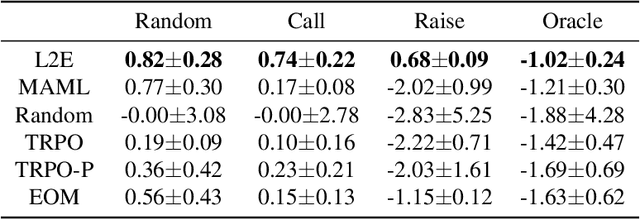
Opponent modeling is essential to exploit sub-optimal opponents in strategic interactions. Most previous works focus on building explicit models to directly predict the opponents' styles or strategies, which require a large amount of data to train the model and lack adaptability to unknown opponents. In this work, we propose a novel Learning to Exploit (L2E) framework for implicit opponent modeling. L2E acquires the ability to exploit opponents by a few interactions with different opponents during training, thus can adapt to new opponents with unknown styles during testing quickly. We propose a novel opponent strategy generation algorithm that produces effective opponents for training automatically. We evaluate L2E on two poker games and one grid soccer game, which are the commonly used benchmarks for opponent modeling. Comprehensive experimental results indicate that L2E quickly adapts to diverse styles of unknown opponents.
Deep Learning for Short-Term Voltage Stability Assessment of Power Systems
Feb 04, 2021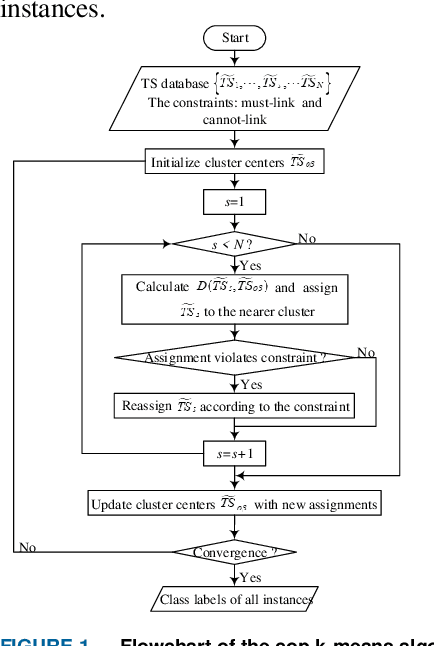
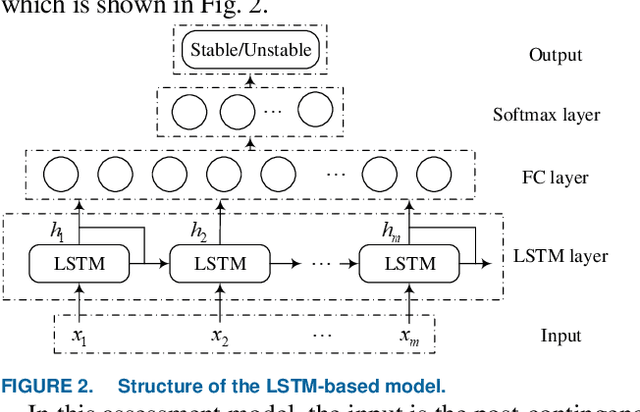
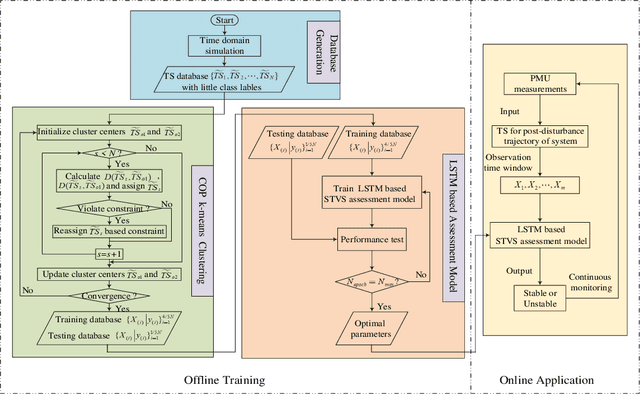
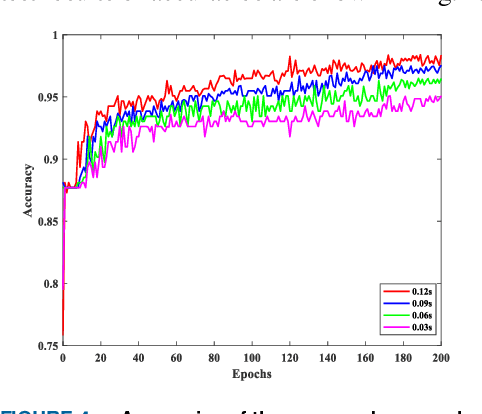
To fully learn the latent temporal dependencies from post-disturbance system dynamic trajectories, deep learning is utilized for short-term voltage stability (STVS) assessment of power systems in this paper. First of all, a semi-supervised cluster algorithm is performed to obtain class labels of STVS instances due to the unavailability of reliable quantitative criteria. Secondly, a long short-term memory (LSTM) based assessment model is built through learning the time dependencies from the post-disturbance system dynamics. Finally, the trained assessment model is employed to determine the systems stability status in real time. The test results on the IEEE 39-bus system suggest that the proposed approach manages to assess the stability status of the system accurately and timely. Furthermore, the superiority of the proposed method over traditional shallow learning-based assessment methods has also been proved.
OpenHoldem: An Open Toolkit for Large-Scale Imperfect-Information Game Research
Dec 19, 2020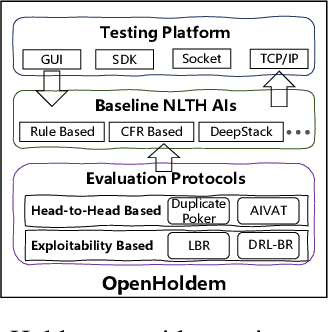


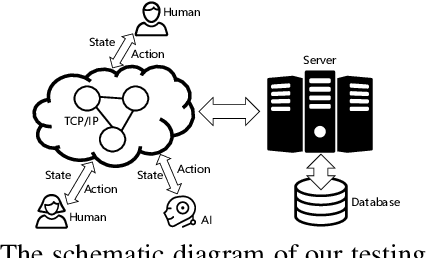
Owning to the unremitting efforts by a few institutes, significant progress has recently been made in designing superhuman AIs in No-limit Texas Hold'em (NLTH), the primary testbed for large-scale imperfect-information game research. However, it remains challenging for new researchers to study this problem since there are no standard benchmarks for comparing with existing methods, which seriously hinders further developments in this research area. In this work, we present OpenHoldem, an integrated toolkit for large-scale imperfect-information game research using NLTH. OpenHoldem makes three main contributions to this research direction: 1) a standardized evaluation protocol for thoroughly evaluating different NLTH AIs, 2) three publicly available strong baselines for NLTH AI, and 3) an online testing platform with easy-to-use APIs for public NLTH AI evaluation. We have released OpenHoldem at http://holdem.ia.ac.cn/, hoping it facilitates further studies on the unsolved theoretical and computational issues in this area and cultivate crucial research problems like opponent modeling, large-scale equilibrium-finding, and human-computer interactive learning.