 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMehryar Mohri
Multiple-Source Adaptation with Domain Classifiers
Aug 25, 2020
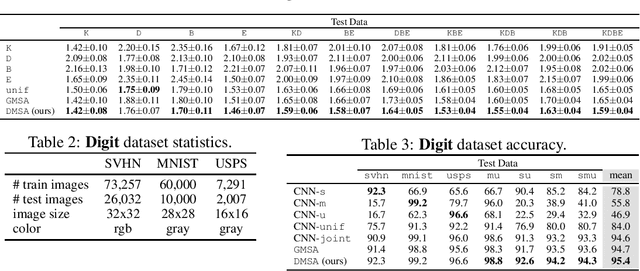
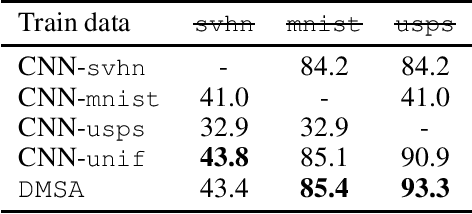
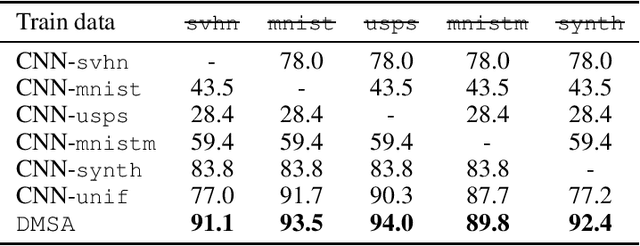
We consider the multiple-source adaptation (MSA) problem and improve a previously proposed MSA solution, where accurate density estimation per domain is required to obtain favorable learning guarantees. In this work, we replace the difficult task of density estimation per domain with a much easier task of domain classification, and show that the two solutions are equivalent given the true densities and domain classifier, yet the newer approach benefits from more favorable guarantees when densities and domain classifier are estimated from finite samples. Our experiments with real-world applications demonstrate that the new discriminative MSA solution outperforms the previous solution with density estimation, as well as other domain adaptation baselines.
Beyond Individual and Group Fairness
Aug 21, 2020



We present a new data-driven model of fairness that, unlike existing static definitions of individual or group fairness is guided by the unfairness complaints received by the system. Our model supports multiple fairness criteria and takes into account their potential incompatibilities. We consider both a stochastic and an adversarial setting of our model. In the stochastic setting, we show that our framework can be naturally cast as a Markov Decision Process with stochastic losses, for which we give efficient vanishing regret algorithmic solutions. In the adversarial setting, we design efficient algorithms with competitive ratio guarantees. We also report the results of experiments with our algorithms and the stochastic framework on artificial datasets, to demonstrate their effectiveness empirically.
Mime: Mimicking Centralized Stochastic Algorithms in Federated Learning
Aug 08, 2020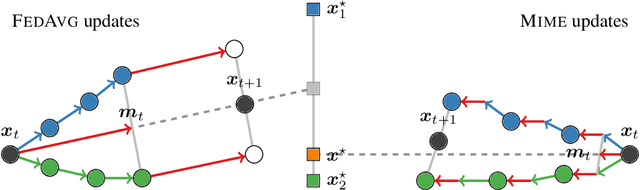

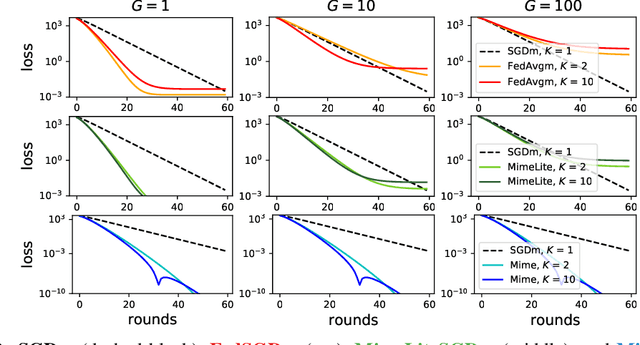

Federated learning is a challenging optimization problem due to the heterogeneity of the data across different clients. Such heterogeneity has been observed to induce client drift and significantly degrade the performance of algorithms designed for this setting. In contrast, centralized learning with centrally collected data does not experience such drift, and has seen great empirical and theoretical progress with innovations such as momentum, adaptivity, etc. In this work, we propose a general framework Mime which mitigates client-drift and adapts arbitrary centralized optimization algorithms (e.g.\ SGD, Adam, etc.) to federated learning. Mime uses a combination of control-variates and server-level statistics (e.g. momentum) at every client-update step to ensure that each local update mimics that of the centralized method. Our thorough theoretical and empirical analyses strongly establish Mime's superiority over other baselines.
On the Rademacher Complexity of Linear Hypothesis Sets
Jul 21, 2020

Linear predictors form a rich class of hypotheses used in a variety of learning algorithms. We present a tight analysis of the empirical Rademacher complexity of the family of linear hypothesis classes with weight vectors bounded in $\ell_p$-norm for any $p \geq 1$. This provides a tight analysis of generalization using these hypothesis sets and helps derive sharp data-dependent learning guarantees. We give both upper and lower bounds on the Rademacher complexity of these families and show that our bounds improve upon or match existing bounds, which are known only for $1 \leq p \leq 2$.
A Theory of Multiple-Source Adaptation with Limited Target Labeled Data
Jul 19, 2020
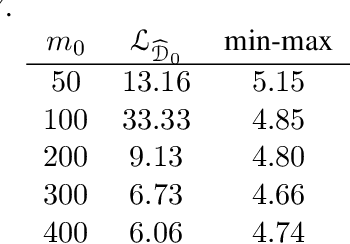
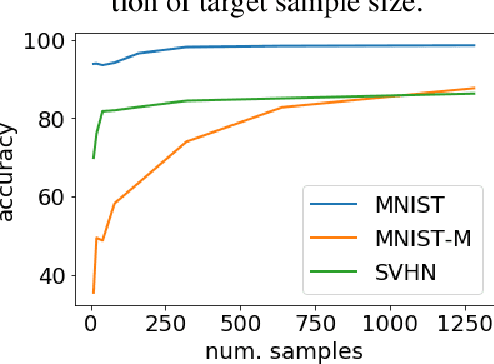
We study multiple-source domain adaptation, when the learner has access to abundant labeled data from multiple-source domains and limited labeled data from the target domain. We analyze existing algorithms for this problem, and propose a novel algorithm based on model selection. Our algorithms are efficient, and experiments on real data-sets empirically demonstrate their benefits.
Corralling Stochastic Bandit Algorithms
Jun 28, 2020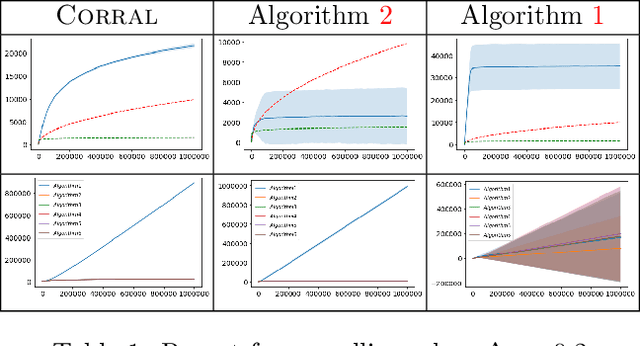
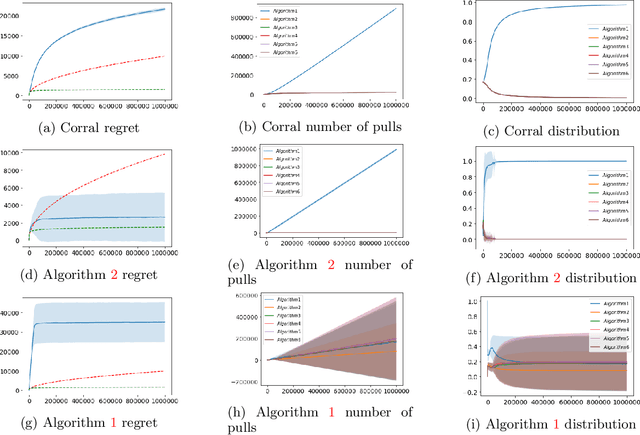
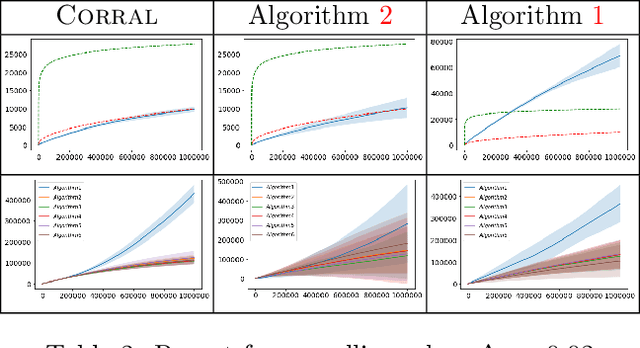
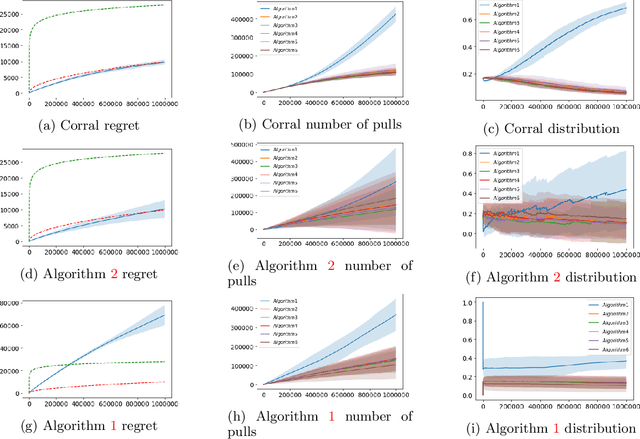
We study the problem of corralling stochastic bandit algorithms, that is combining multiple bandit algorithms designed for a stochastic environment, with the goal of devising a corralling algorithm that performs almost as well as the best base algorithm. We give two general algorithms for this setting, which we show benefit from favorable regret guarantees. We show that the regret of the corralling algorithms is no worse than that of the best algorithm containing the arm with the highest reward, and depends on the gap between the highest reward and other rewards. We also provide lower bounds for this problem that further justify our approach.
Relative Deviation Margin Bounds
Jun 26, 2020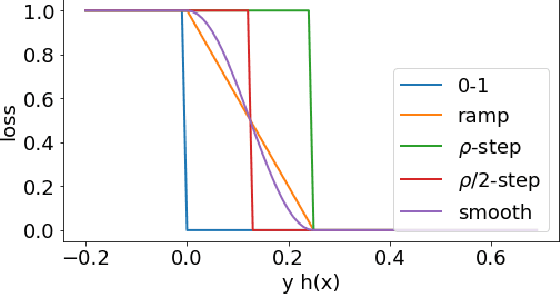
We present a series of new and more favorable margin-based learning guarantees that depend on the empirical margin loss of a predictor. We give two types of learning bounds, both data-dependent ones and bounds valid for general families, in terms of the Rademacher complexity or the empirical $\ell_\infty$ covering number of the hypothesis set used. We also briefly highlight several applications of these bounds and discuss their connection with existing results.
Reinforcement Learning with Feedback Graphs
May 07, 2020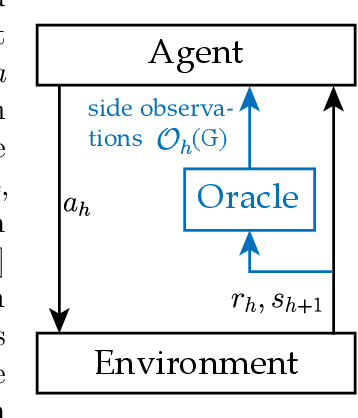


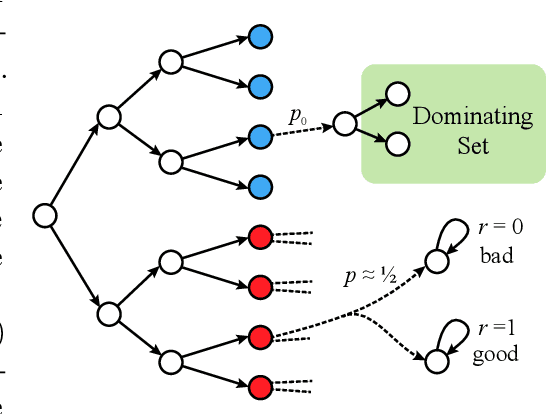
We study episodic reinforcement learning in Markov decision processes when the agent receives additional feedback per step in the form of several transition observations. Such additional observations are available in a range of tasks through extended sensors or prior knowledge about the environment (e.g., when certain actions yield similar outcome). We formalize this setting using a feedback graph over state-action pairs and show that model-based algorithms can leverage the additional feedback for more sample-efficient learning. We give a regret bound that, ignoring logarithmic factors and lower-order terms, depends only on the size of the maximum acyclic subgraph of the feedback graph, in contrast with a polynomial dependency on the number of states and actions in the absence of a feedback graph. Finally, we highlight challenges when leveraging a small dominating set of the feedback graph as compared to the bandit setting and propose a new algorithm that can use knowledge of such a dominating set for more sample-efficient learning of a near-optimal policy.
Adversarial Learning Guarantees for Linear Hypotheses and Neural Networks
Apr 28, 2020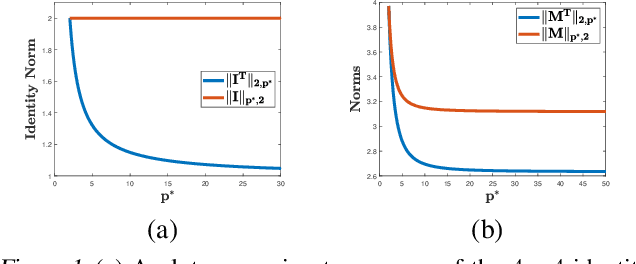
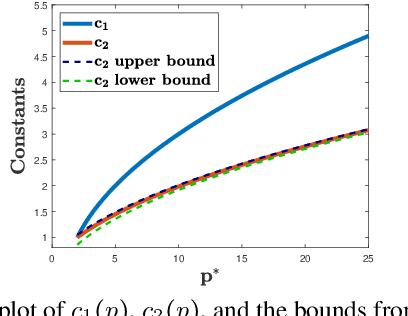
Adversarial or test time robustness measures the susceptibility of a classifier to perturbations to the test input. While there has been a flurry of recent work on designing defenses against such perturbations, the theory of adversarial robustness is not well understood. In order to make progress on this, we focus on the problem of understanding generalization in adversarial settings, via the lens of Rademacher complexity. We give upper and lower bounds for the adversarial empirical Rademacher complexity of linear hypotheses with adversarial perturbations measured in $l_r$-norm for an arbitrary $r \geq 1$. This generalizes the recent result of [Yin et al.'19] that studies the case of $r = \infty$, and provides a finer analysis of the dependence on the input dimensionality as compared to the recent work of [Khim and Loh'19] on linear hypothesis classes. We then extend our analysis to provide Rademacher complexity lower and upper bounds for a single ReLU unit. Finally, we give adversarial Rademacher complexity bounds for feed-forward neural networks with one hidden layer. Unlike previous works we directly provide bounds on the adversarial Rademacher complexity of the given network, as opposed to a bound on a surrogate. A by-product of our analysis also leads to tighter bounds for the Rademacher complexity of linear hypotheses, for which we give a detailed analysis and present a comparison with existing bounds.