 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Step Regression Learning for Compositional Distributional Semantics
Jan 30, 2013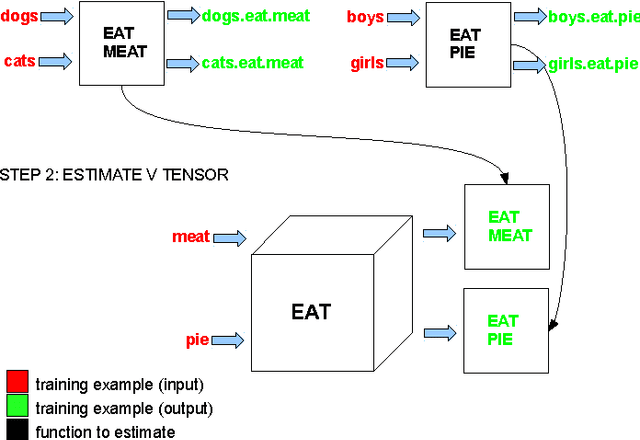
We present a model for compositional distributional semantics related to the framework of Coecke et al. (2010), and emulating formal semantics by representing functions as tensors and arguments as vectors. We introduce a new learning method for tensors, generalising the approach of Baroni and Zamparelli (2010). We evaluate it on two benchmark data sets, and find it to outperform existing leading methods. We argue in our analysis that the nature of this learning method also renders it suitable for solving more subtle problems compositional distributional models might face.
Experimenting with Transitive Verbs in a DisCoCat
Jul 23, 2011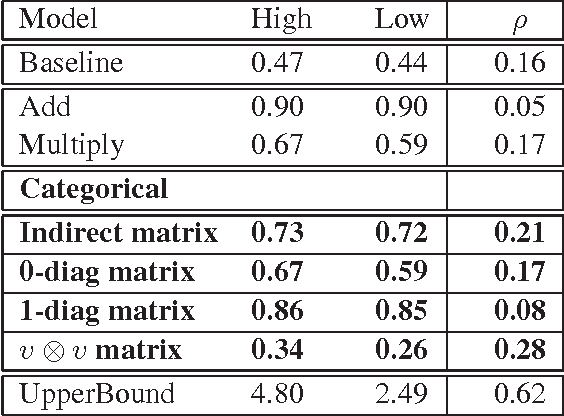
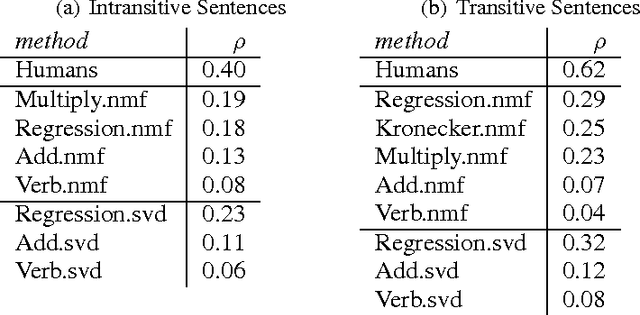
Formal and distributional semantic models offer complementary benefits in modeling meaning. The categorical compositional distributional (DisCoCat) model of meaning of Coecke et al. (arXiv:1003.4394v1 [cs.CL]) combines aspected of both to provide a general framework in which meanings of words, obtained distributionally, are composed using methods from the logical setting to form sentence meaning. Concrete consequences of this general abstract setting and applications to empirical data are under active study (Grefenstette et al., arxiv:1101.0309; Grefenstette and Sadrzadeh, arXiv:1106.4058v1 [cs.CL]). . In this paper, we extend this study by examining transitive verbs, represented as matrices in a DisCoCat. We discuss three ways of constructing such matrices, and evaluate each method in a disambiguation task developed by Grefenstette and Sadrzadeh (arXiv:1106.4058v1 [cs.CL]).
Experimental Support for a Categorical Compositional Distributional Model of Meaning
Jun 20, 2011
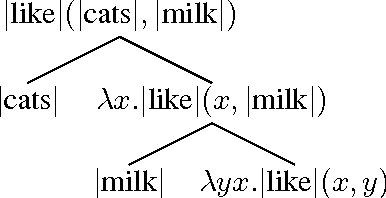
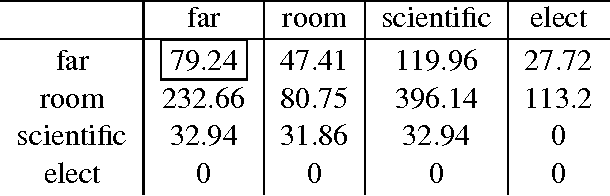
Modelling compositional meaning for sentences using empirical distributional methods has been a challenge for computational linguists. We implement the abstract categorical model of Coecke et al. (arXiv:1003.4394v1 [cs.CL]) using data from the BNC and evaluate it. The implementation is based on unsupervised learning of matrices for relational words and applying them to the vectors of their arguments. The evaluation is based on the word disambiguation task developed by Mitchell and Lapata (2008) for intransitive sentences, and on a similar new experiment designed for transitive sentences. Our model matches the results of its competitors in the first experiment, and betters them in the second. The general improvement in results with increase in syntactic complexity showcases the compositional power of our model.
* 11 pages, to be presented at EMNLP 2011, to be published in Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing
A Compositional Distributional Semantics, Two Concrete Constructions, and some Experimental Evaluations
Jun 07, 2011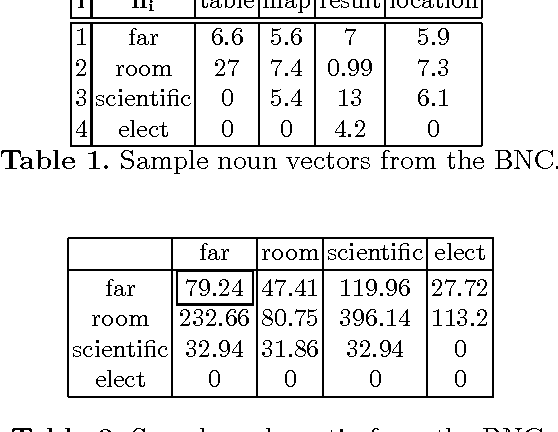
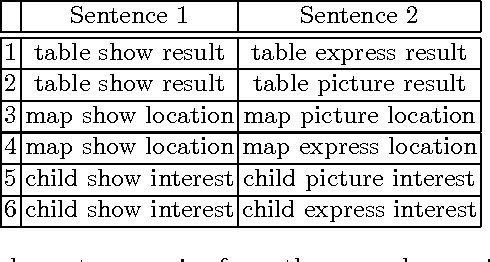

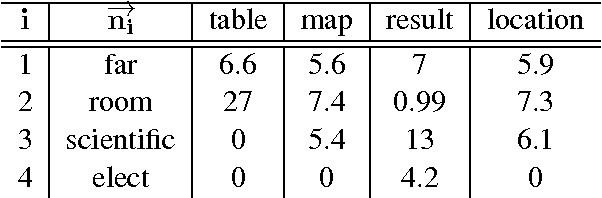
We provide an overview of the hybrid compositional distributional model of meaning, developed in Coecke et al. (arXiv:1003.4394v1 [cs.CL]), which is based on the categorical methods also applied to the analysis of information flow in quantum protocols. The mathematical setting stipulates that the meaning of a sentence is a linear function of the tensor products of the meanings of its words. We provide concrete constructions for this definition and present techniques to build vector spaces for meaning vectors of words, as well as that of sentences. The applicability of these methods is demonstrated via a toy vector space as well as real data from the British National Corpus and two disambiguation experiments.
Concrete Sentence Spaces for Compositional Distributional Models of Meaning
Dec 31, 2010Coecke, Sadrzadeh, and Clark (arXiv:1003.4394v1 [cs.CL]) developed a compositional model of meaning for distributional semantics, in which each word in a sentence has a meaning vector and the distributional meaning of the sentence is a function of the tensor products of the word vectors. Abstractly speaking, this function is the morphism corresponding to the grammatical structure of the sentence in the category of finite dimensional vector spaces. In this paper, we provide a concrete method for implementing this linear meaning map, by constructing a corpus-based vector space for the type of sentence. Our construction method is based on structured vector spaces whereby meaning vectors of all sentences, regardless of their grammatical structure, live in the same vector space. Our proposed sentence space is the tensor product of two noun spaces, in which the basis vectors are pairs of words each augmented with a grammatical role. This enables us to compare meanings of sentences by simply taking the inner product of their vectors.
* 10 pages, presented at the International Conference on Computational Semantics 2011 (IWCS'11), to be published in proceedings
Mathematical Foundations for a Compositional Distributional Model of Meaning
Mar 23, 2010We propose a mathematical framework for a unification of the distributional theory of meaning in terms of vector space models, and a compositional theory for grammatical types, for which we rely on the algebra of Pregroups, introduced by Lambek. This mathematical framework enables us to compute the meaning of a well-typed sentence from the meanings of its constituents. Concretely, the type reductions of Pregroups are `lifted' to morphisms in a category, a procedure that transforms meanings of constituents into a meaning of the (well-typed) whole. Importantly, meanings of whole sentences live in a single space, independent of the grammatical structure of the sentence. Hence the inner-product can be used to compare meanings of arbitrary sentences, as it is for comparing the meanings of words in the distributional model. The mathematical structure we employ admits a purely diagrammatic calculus which exposes how the information flows between the words in a sentence in order to make up the meaning of the whole sentence. A variation of our `categorical model' which involves constraining the scalars of the vector spaces to the semiring of Booleans results in a Montague-style Boolean-valued semantics.
* to appear