 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Space Semantics for Lambek Calculus with Soft Subexponentials
Nov 22, 2021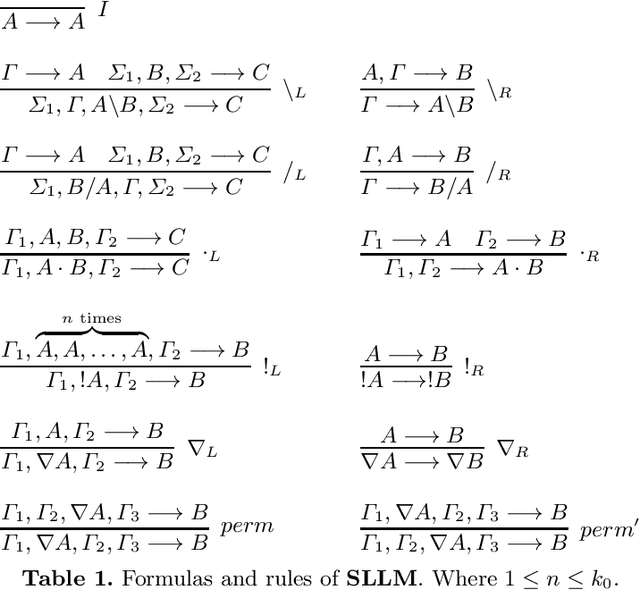
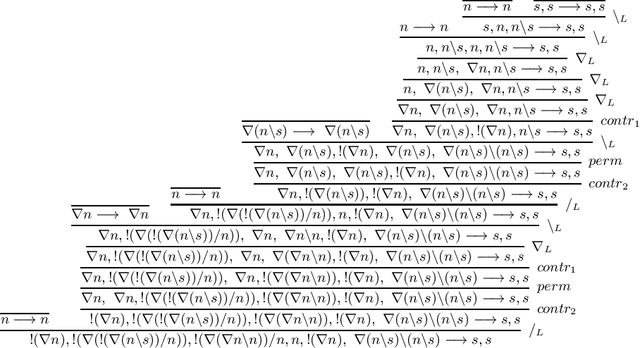


We develop a vector space semantics for Lambek Calculus with Soft Subexponentials, apply the calculus to construct compositional vector interpretations for parasitic gap noun phrases and discourse units with anaphora and ellipsis, and experiment with the constructions in a distributional sentence similarity task. As opposed to previous work, which used Lambek Calculus with a Relevant Modality the calculus used in this paper uses a bounded version of the modality and is decidable. The vector space semantics of this new modality allows us to meaningfully define contraction as projection and provide a linear theory behind what we could previously only achieve via nonlinear maps.
Pregroup Grammars, their Syntax and Semantics
Sep 23, 2021

Pregroup grammars were developed in 1999 and stayed Lambek's preferred algebraic model of grammar. The set-theoretic semantics of pregroups, however, faces an ambiguity problem. In his latest book, Lambek suggests that this problem might be overcome using finite dimensional vector spaces rather than sets. What is the right notion of composition in this setting, direct sum or tensor product of spaces?
* https://doi.org/10.1007/978-3-030-66545-6_1
Fuzzy Generalised Quantifiers for Natural Language in Categorical Compositional Distributional Semantics
Sep 23, 2021Recent work on compositional distributional models shows that bialgebras over finite dimensional vector spaces can be applied to treat generalised quantifiers for natural language. That technique requires one to construct the vector space over powersets, and therefore is computationally costly. In this paper, we overcome this problem by considering fuzzy versions of quantifiers along the lines of Zadeh, within the category of many valued relations. We show that this category is a concrete instantiation of the compositional distributional model. We show that the semantics obtained in this model is equivalent to the semantics of the fuzzy quantifiers of Zadeh. As a result, we are now able to treat fuzzy quantification without requiring a powerset construction.
* https://link.springer.com/chapter/10.1007/978-3-030-53654-1_6
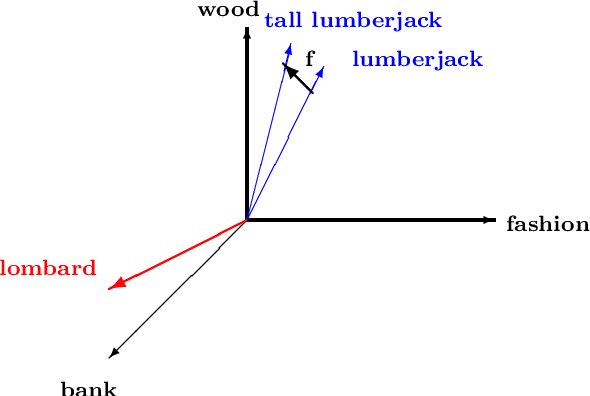
On the Quantum-like Contextuality of Ambiguous Phrases
Jul 19, 2021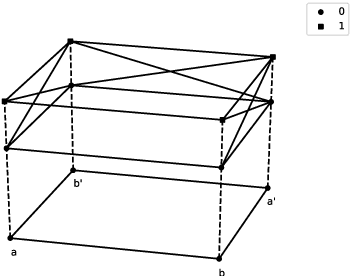
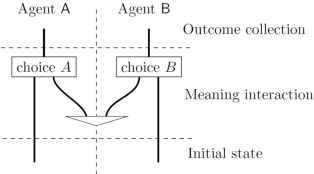
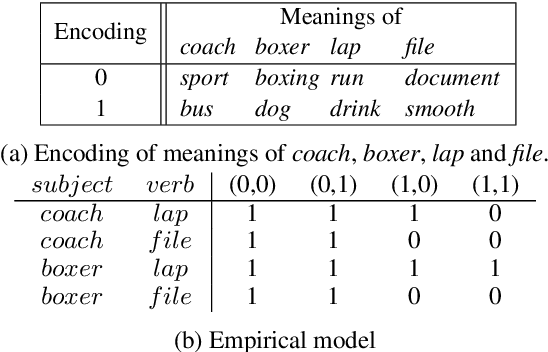
Language is contextual as meanings of words are dependent on their contexts. Contextuality is, concomitantly, a well-defined concept in quantum mechanics where it is considered a major resource for quantum computations. We investigate whether natural language exhibits any of the quantum mechanics' contextual features. We show that meaning combinations in ambiguous phrases can be modelled in the sheaf-theoretic framework for quantum contextuality, where they can become possibilistically contextual. Using the framework of Contextuality-by-Default (CbD), we explore the probabilistic variants of these and show that CbD-contextuality is also possible.
Cosine Similarity of Multimodal Content Vectors for TV Programmes
Sep 23, 2020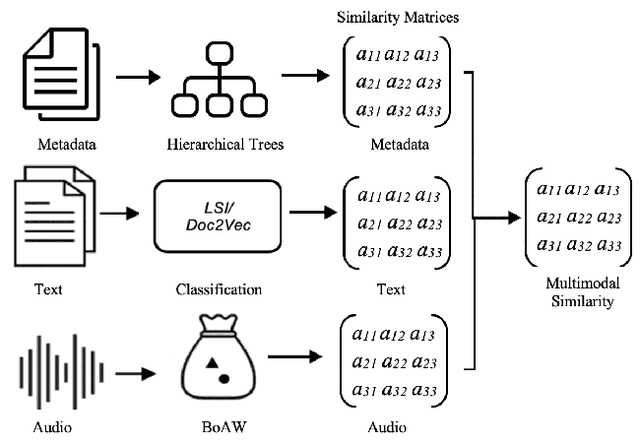
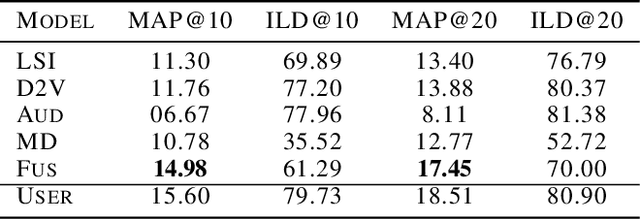
Multimodal information originates from a variety of sources: audiovisual files, textual descriptions, and metadata. We show how one can represent the content encoded by each individual source using vectors, how to combine the vectors via middle and late fusion techniques, and how to compute the semantic similarities between the contents. Our vectorial representations are built from spectral features and Bags of Audio Words, for audio, LSI topics and Doc2vec embeddings for subtitles, and the categorical features, for metadata. We implement our model on a dataset of BBC TV programmes and evaluate the fused representations to provide recommendations. The late fused similarity matrices significantly improve the precision and diversity of recommendations.
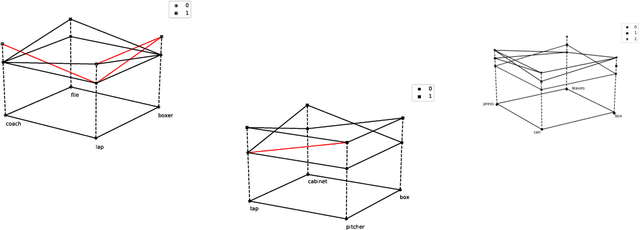
A Frobenius Algebraic Analysis for Parasitic Gaps
May 12, 2020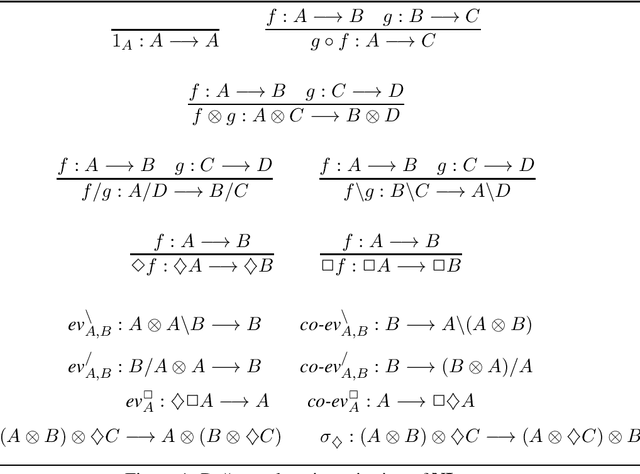
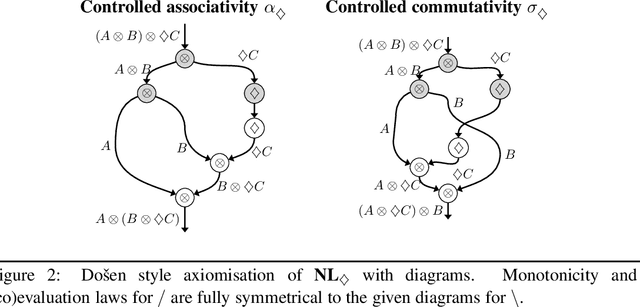
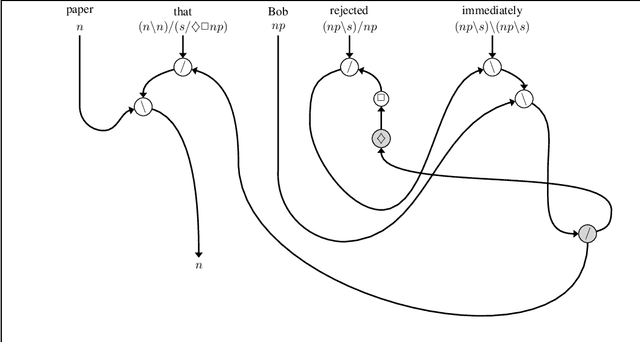
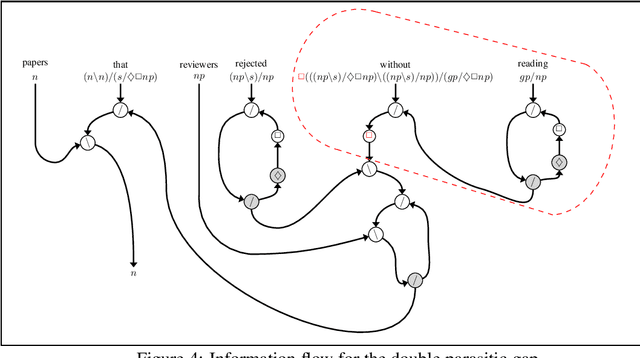
The interpretation of parasitic gaps is an ostensible case of non-linearity in natural language composition. Existing categorial analyses, both in the typelogical and in the combinatory traditions, rely on explicit forms of syntactic copying. We identify two types of parasitic gapping where the duplication of semantic content can be confined to the lexicon. Parasitic gaps in adjuncts are analysed as forms of generalized coordination with a polymorphic type schema for the head of the adjunct phrase. For parasitic gaps affecting arguments of the same predicate, the polymorphism is associated with the lexical item that introduces the primary gap. Our analysis is formulated in terms of Lambek calculus extended with structural control modalities. A compositional translation relates syntactic types and derivations to the interpreting compact closed category of finite dimensional vector spaces and linear maps with Frobenius algebras over it. When interpreted over the necessary semantic spaces, the Frobenius algebras provide the tools to model the proposed instances of lexical polymorphism.
Categorical Vector Space Semantics for Lambek Calculus with a Relevant Modality
May 10, 2020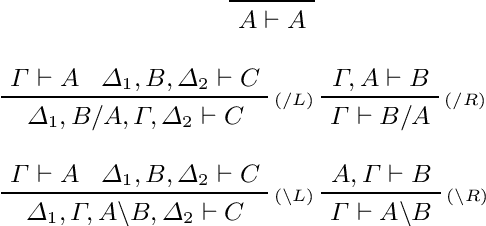
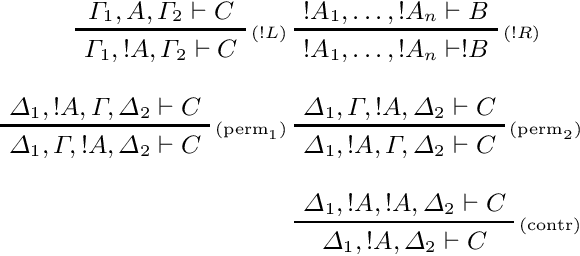
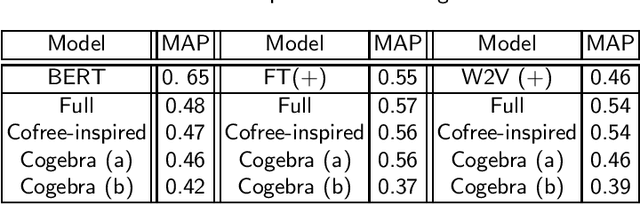
We develop a categorical compositional distributional semantics for Lambek Calculus with a Relevant Modality !L*, which has a limited edition of the contraction and permutation rules. The categorical part of the semantics is a monoidal biclosed category with a coalgebra modality, very similar to the structure of a Differential Category. We instantiate this category to finite dimensional vector spaces and linear maps via "quantisation" functors and work with three concrete interpretations of the coalgebra modality. We apply the model to construct categorical and concrete semantic interpretations for the motivating example of !L*: the derivation of a phrase with a parasitic gap. The effectiveness of the concrete interpretations are evaluated via a disambiguation task, on an extension of a sentence disambiguation dataset to parasitic gap phrases, using BERT, Word2Vec, and FastText vectors and Relational tensors.
Incremental Monoidal Grammars
Jan 10, 2020In this work we define formal grammars in terms of free monoidal categories, along with a functor from the category of formal grammars to the category of automata. Generalising from the Booleans to arbitrary semirings, we extend our construction to weighted formal grammars and weighted automata. This allows us to link the categorical viewpoint on natural language to the standard machine learning notion of probabilistic language model.
Gaussianity and typicality in matrix distributional semantics
Dec 19, 2019



Constructions in type-driven compositional distributional semantics associate large collections of matrices of size $D$ to linguistic corpora. We develop the proposal of analysing the statistical characteristics of this data in the framework of permutation invariant matrix models. The observables in this framework are permutation invariant polynomial functions of the matrix entries, which correspond to directed graphs. Using the general 13-parameter permutation invariant Gaussian matrix models recently solved, we find, using a dataset of matrices constructed via standard techniques in distributional semantics, that the expectation values of a large class of cubic and quartic observables show high gaussianity at levels between 90 to 99 percent. Beyond expectation values, which are averages over words, the dataset allows the computation of standard deviations for each observable, which can be viewed as a measure of typicality for each observable. There is a wide range of magnitudes in the measures of typicality. The permutation invariant matrix models, considered as functions of random couplings, give a very good prediction of the magnitude of the typicality for different observables. We find evidence that observables with similar matrix model characteristics of Gaussianity and typicality also have high degrees of correlation between the ranked lists of words associated to these observables.
A Typedriven Vector Semantics for Ellipsis with Anaphora using Lambek Calculus with Limited Contraction
May 05, 2019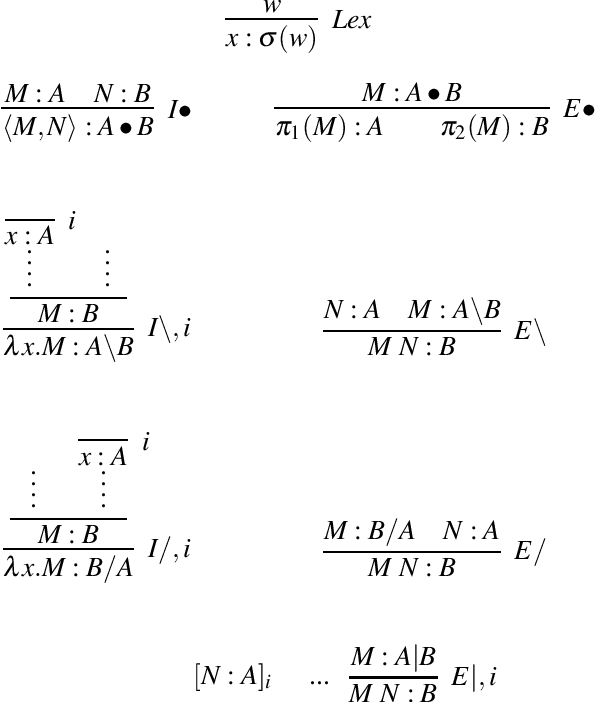

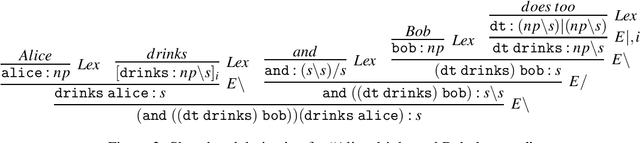
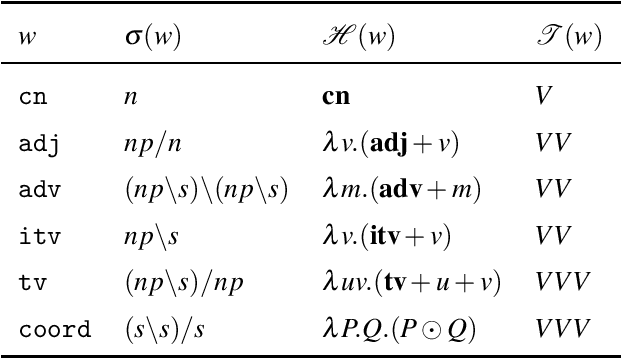
We develop a vector space semantics for verb phrase ellipsis with anaphora using type-driven compositional distributional semantics based on the Lambek calculus with limited contraction (LCC) of J\"ager (2006). Distributional semantics has a lot to say about the statistical collocation-based meanings of content words, but provides little guidance on how to treat function words. Formal semantics on the other hand, has powerful mechanisms for dealing with relative pronouns, coordinators, and the like. Type-driven compositional distributional semantics brings these two models together. We review previous compositional distributional models of relative pronouns, coordination and a restricted account of ellipsis in the DisCoCat framework of Coecke et al. (2010, 2013). We show how DisCoCat cannot deal with general forms of ellipsis, which rely on copying of information, and develop a novel way of connecting typelogical grammar to distributional semantics by assigning vector interpretable lambda terms to derivations of LCC in the style of Muskens & Sadrzadeh (2016). What follows is an account of (verb phrase) ellipsis in which word meanings can be copied: the meaning of a sentence is now a program with non-linear access to individual word embeddings. We present the theoretical setting, work out examples, and demonstrate our results on a toy distributional model motivated by data.