 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMd Saiful Islam
TextMI: Textualize Multimodal Information for Integrating Non-verbal Cues in Pre-trained Language Models
Mar 27, 2023
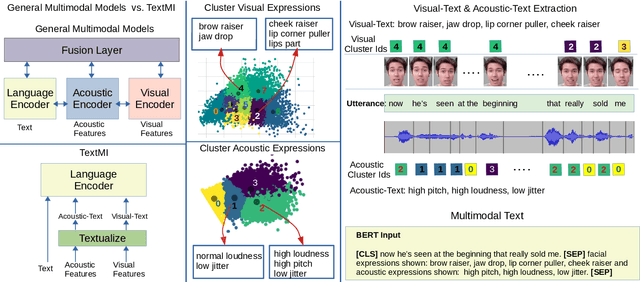
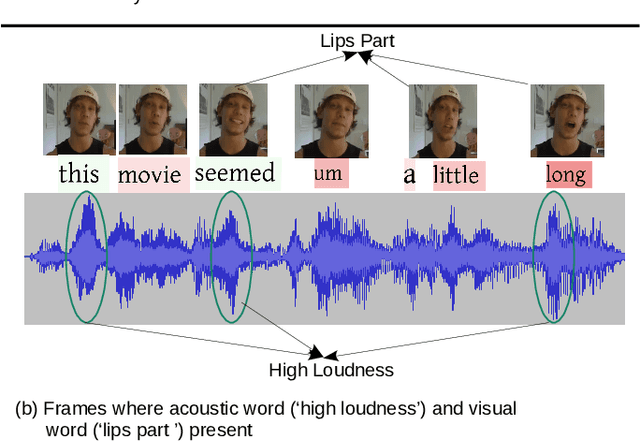

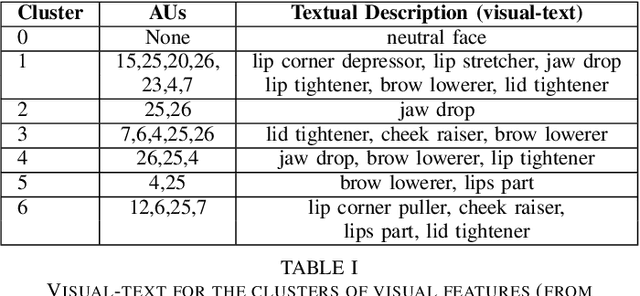
Pre-trained large language models have recently achieved ground-breaking performance in a wide variety of language understanding tasks. However, the same model can not be applied to multimodal behavior understanding tasks (e.g., video sentiment/humor detection) unless non-verbal features (e.g., acoustic and visual) can be integrated with language. Jointly modeling multiple modalities significantly increases the model complexity, and makes the training process data-hungry. While an enormous amount of text data is available via the web, collecting large-scale multimodal behavioral video datasets is extremely expensive, both in terms of time and money. In this paper, we investigate whether large language models alone can successfully incorporate non-verbal information when they are presented in textual form. We present a way to convert the acoustic and visual information into corresponding textual descriptions and concatenate them with the spoken text. We feed this augmented input to a pre-trained BERT model and fine-tune it on three downstream multimodal tasks: sentiment, humor, and sarcasm detection. Our approach, TextMI, significantly reduces model complexity, adds interpretability to the model's decision, and can be applied for a diverse set of tasks while achieving superior (multimodal sarcasm detection) or near SOTA (multimodal sentiment analysis and multimodal humor detection) performance. We propose TextMI as a general, competitive baseline for multimodal behavioral analysis tasks, particularly in a low-resource setting.
NADBenchmarks -- a compilation of Benchmark Datasets for Machine Learning Tasks related to Natural Disasters
Dec 21, 2022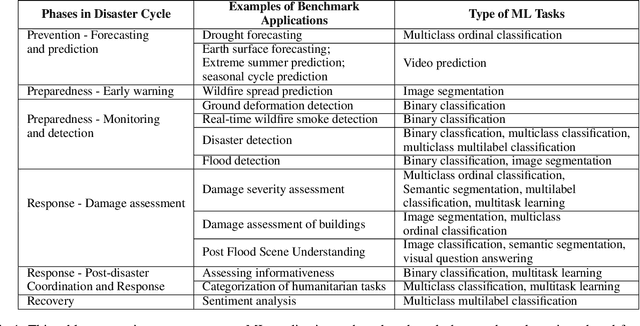
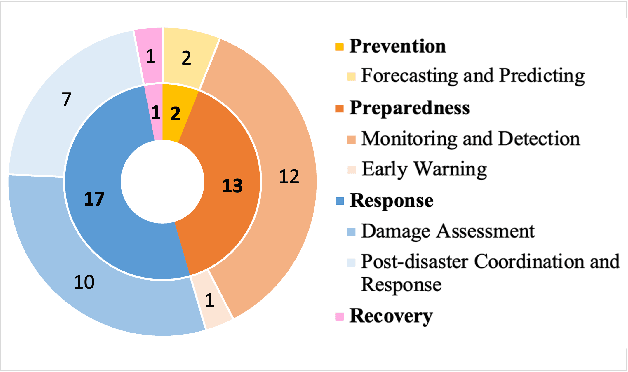
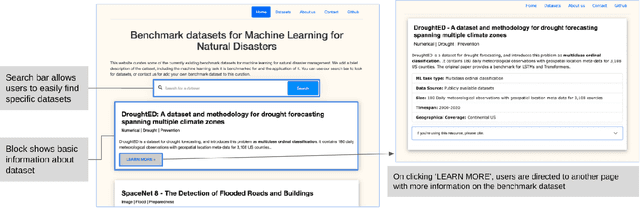
Climate change has increased the intensity, frequency, and duration of extreme weather events and natural disasters across the world. While the increased data on natural disasters improves the scope of machine learning (ML) in this field, progress is relatively slow. One bottleneck is the lack of benchmark datasets that would allow ML researchers to quantify their progress against a standard metric. The objective of this short paper is to explore the state of benchmark datasets for ML tasks related to natural disasters, categorizing them according to the disaster management cycle. We compile a list of existing benchmark datasets introduced in the past five years. We propose a web platform - NADBenchmarks - where researchers can search for benchmark datasets for natural disasters, and we develop a preliminary version of such a platform using our compiled list. This paper is intended to aid researchers in finding benchmark datasets to train their ML models on, and provide general directions for topics where they can contribute new benchmark datasets.
BAN-Cap: A Multi-Purpose English-Bangla Image Descriptions Dataset
May 28, 2022

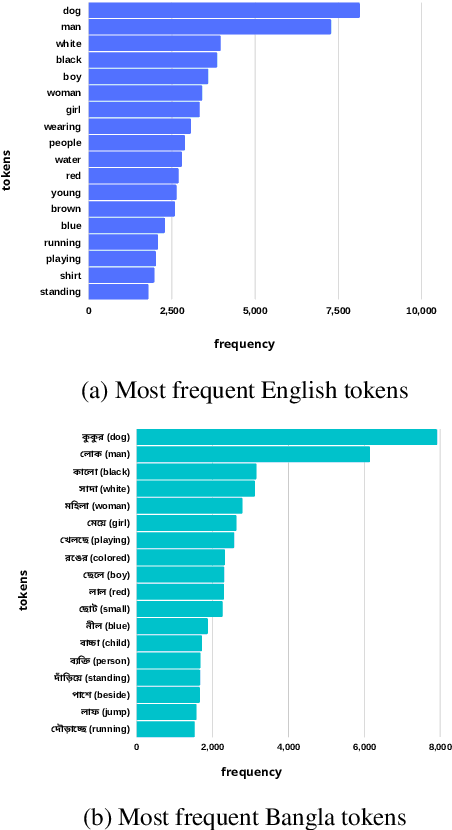

As computers have become efficient at understanding visual information and transforming it into a written representation, research interest in tasks like automatic image captioning has seen a significant leap over the last few years. While most of the research attention is given to the English language in a monolingual setting, resource-constrained languages like Bangla remain out of focus, predominantly due to a lack of standard datasets. Addressing this issue, we present a new dataset BAN-Cap following the widely used Flickr8k dataset, where we collect Bangla captions of the images provided by qualified annotators. Our dataset represents a wider variety of image caption styles annotated by trained people from different backgrounds. We present a quantitative and qualitative analysis of the dataset and the baseline evaluation of the recent models in Bangla image captioning. We investigate the effect of text augmentation and demonstrate that an adaptive attention-based model combined with text augmentation using Contextualized Word Replacement (CWR) outperforms all state-of-the-art models for Bangla image captioning. We also present this dataset's multipurpose nature, especially on machine translation for Bangla-English and English-Bangla. This dataset and all the models will be useful for further research.
Auto-Gait: Automatic Ataxia Risk Assessment with Computer Vision on Gait Task Videos
Mar 15, 2022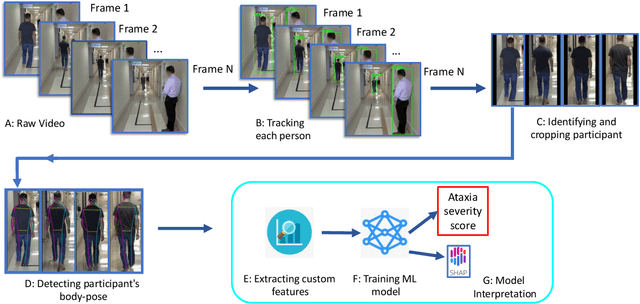


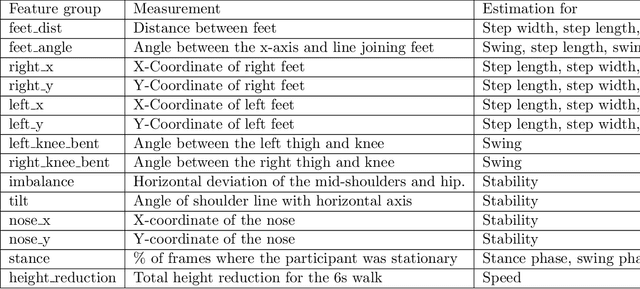
In this paper, we investigated whether we can 1) detect participants with ataxia-specific gait characteristics (risk-prediction), and 2) assess severity of ataxia from gait (severity-assessment). We collected 155 videos from 89 participants, 24 controls and 65 diagnosed with (or are pre-manifest) spinocerebellar ataxias (SCAs), performing the gait task of the Scale for the Assessment and Rating of Ataxia (SARA) from 11 medical sites located in 8 different states in the United States. We developed a method to separate the participants from their surroundings and constructed several features to capture gait characteristics like step width, step length, swing, stability, speed, etc. Our risk-prediction model achieves 83.06% accuracy and an 80.23% F1 score. Similarly, our severity-assessment model achieves a mean absolute error (MAE) score of 0.6225 and a Pearson's correlation coefficient score of 0.7268. Our models still performed competitively when evaluated on data from sites not used during training. Furthermore, through feature importance analysis, we found that our models associate wider steps, decreased walking speed, and increased instability with greater ataxia severity, which is consistent with previously established clinical knowledge. Our models create possibilities for remote ataxia assessment in non-clinical settings in the future, which could significantly improve accessibility of ataxia care. Furthermore, our underlying dataset was assembled from a geographically diverse cohort, highlighting its potential to further increase equity. The code used in this study is open to the public, and the anonymized body pose landmark dataset could be released upon approval from our Institutional Review Board (IRB).
HS-BAN: A Benchmark Dataset of Social Media Comments for Hate Speech Detection in Bangla
Dec 03, 2021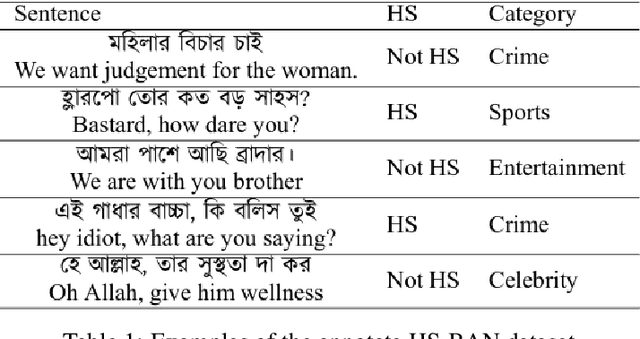
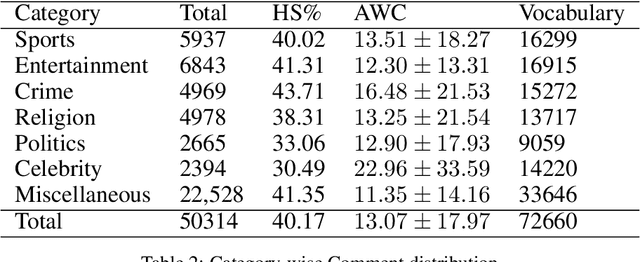
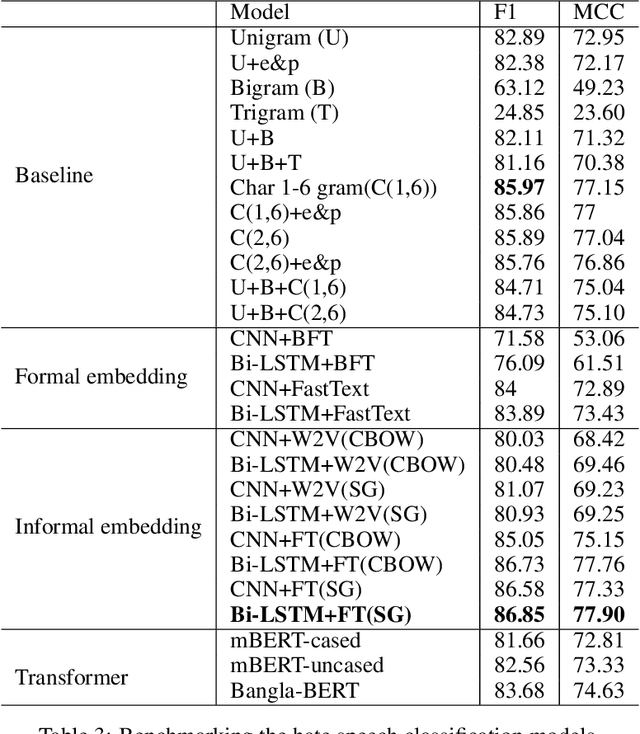
In this paper, we present HS-BAN, a binary class hate speech (HS) dataset in Bangla language consisting of more than 50,000 labeled comments, including 40.17% hate and rest are non hate speech. While preparing the dataset a strict and detailed annotation guideline was followed to reduce human annotation bias. The HS dataset was also preprocessed linguistically to extract different types of slang currently people write using symbols, acronyms, or alternative spellings. These slang words were further categorized into traditional and non-traditional slang lists and included in the results of this paper. We explored traditional linguistic features and neural network-based methods to develop a benchmark system for hate speech detection for the Bangla language. Our experimental results show that existing word embedding models trained with informal texts perform better than those trained with formal text. Our benchmark shows that a Bi-LSTM model on top of the FastText informal word embedding achieved 86.78% F1-score. We will make the dataset available for public use.
Feature Selection for Causal Inference from High Dimensional Observational Data with Outcome Adaptive Elastic Net
Nov 27, 2021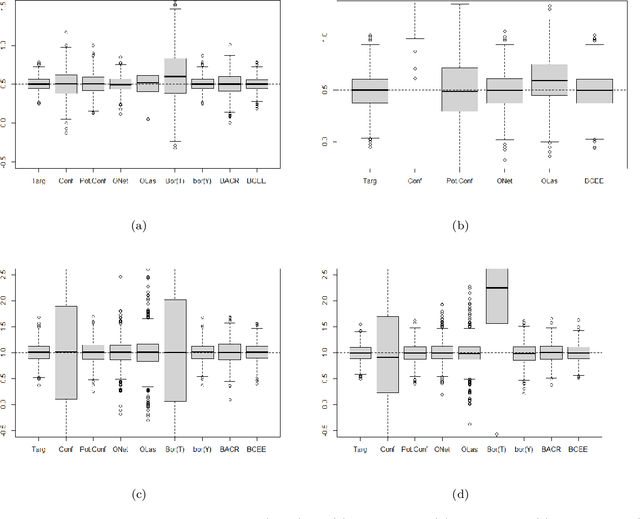
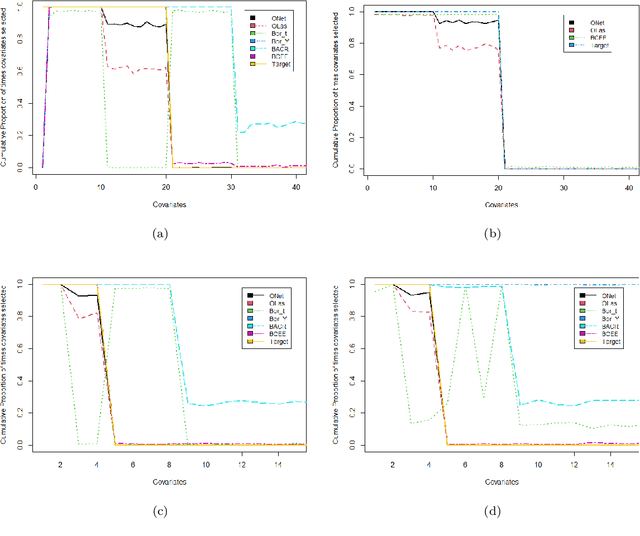
Feature selection is an extensively studied technique in the machine learning literature where the main objective is to identify the subset of features that provides the highest predictive power. However, in causal inference, our goal is to identify the set of variables that are associated with both the treatment variable and outcome (i.e., the confounders). While controlling for the confounding variables helps us to achieve an unbiased estimate of causal effect, recent research shows that controlling for purely outcome predictors along with the confounders can reduce the variance of the estimate. In this paper, we propose an Outcome Adaptive Elastic-Net (OAENet) method specifically designed for causal inference to select the confounders and outcome predictors for inclusion in the propensity score model or in the matching mechanism. OAENet provides two major advantages over existing methods: it performs superiorly on correlated data, and it can be applied to any matching method and any estimates. In addition, OAENet is computationally efficient compared to state-of-the-art methods.
Pointer over Attention: An Improved Bangla Text Summarization Approach Using Hybrid Pointer Generator Network
Nov 19, 2021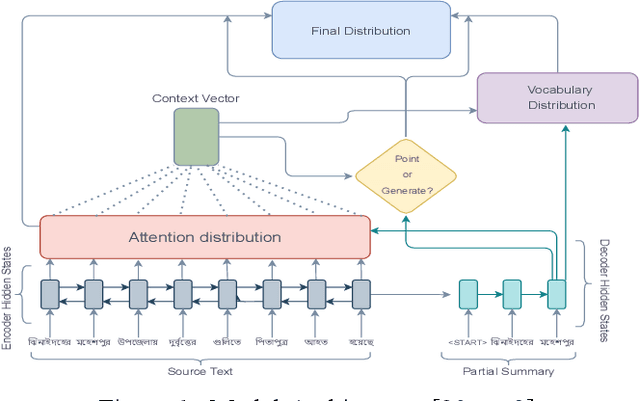
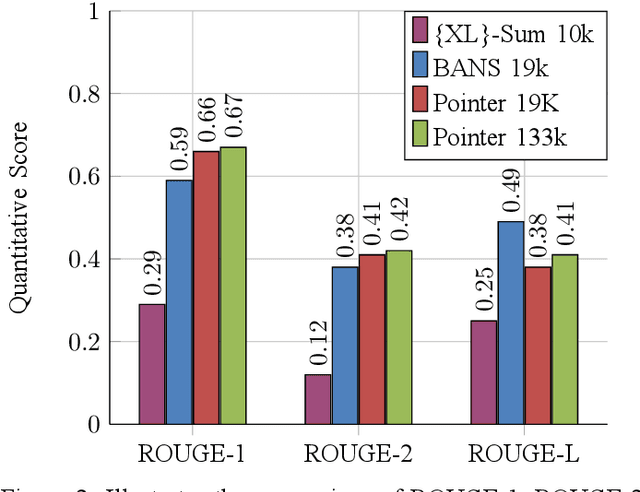
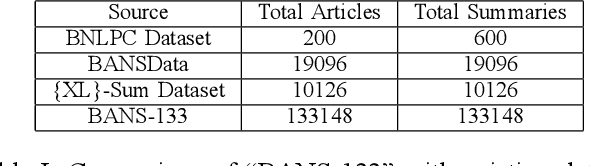
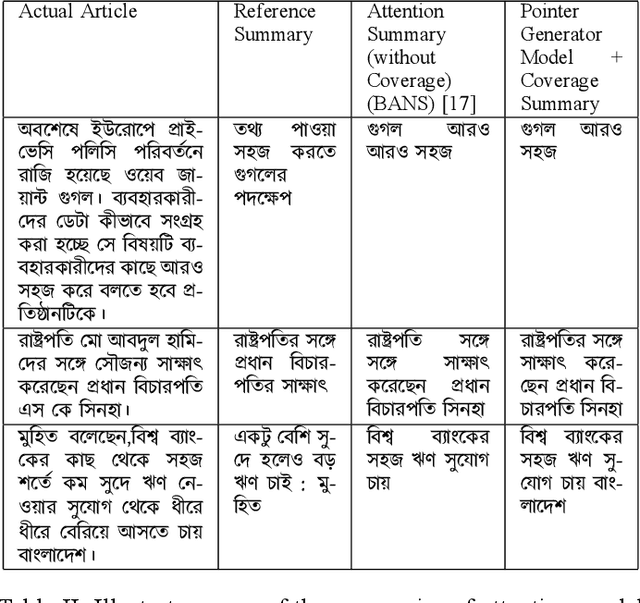
Despite the success of the neural sequence-to-sequence model for abstractive text summarization, it has a few shortcomings, such as repeating inaccurate factual details and tending to repeat themselves. We propose a hybrid pointer generator network to solve the shortcomings of reproducing factual details inadequately and phrase repetition. We augment the attention-based sequence-to-sequence using a hybrid pointer generator network that can generate Out-of-Vocabulary words and enhance accuracy in reproducing authentic details and a coverage mechanism that discourages repetition. It produces a reasonable-sized output text that preserves the conceptual integrity and factual information of the input article. For evaluation, we primarily employed "BANSData" - a highly adopted publicly available Bengali dataset. Additionally, we prepared a large-scale dataset called "BANS-133" which consists of 133k Bangla news articles associated with human-generated summaries. Experimenting with the proposed model, we achieved ROUGE-1 and ROUGE-2 scores of 0.66, 0.41 for the "BANSData" dataset and 0.67, 0.42 for the BANS-133k" dataset, respectively. We demonstrated that the proposed system surpasses previous state-of-the-art Bengali abstractive summarization techniques and its stability on a larger dataset. "BANS-133" datasets and code-base will be publicly available for research.
XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages
Jun 25, 2021
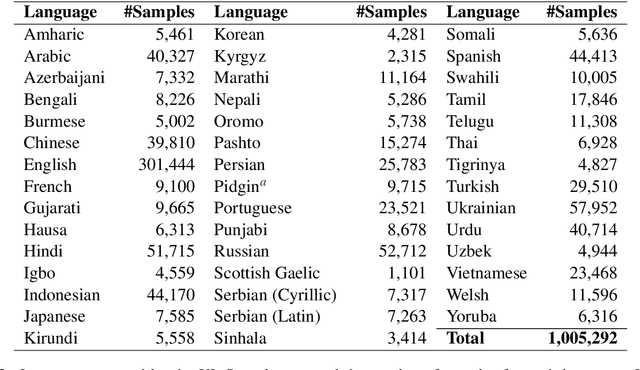
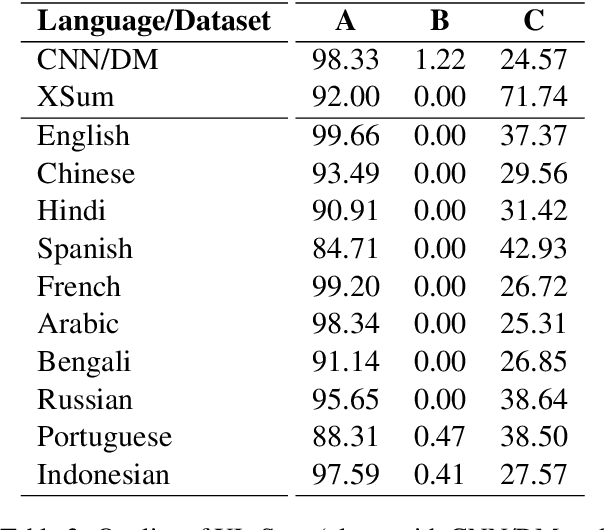
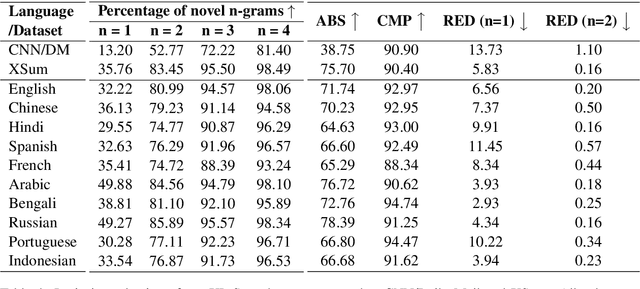
Contemporary works on abstractive text summarization have focused primarily on high-resource languages like English, mostly due to the limited availability of datasets for low/mid-resource ones. In this work, we present XL-Sum, a comprehensive and diverse dataset comprising 1 million professionally annotated article-summary pairs from BBC, extracted using a set of carefully designed heuristics. The dataset covers 44 languages ranging from low to high-resource, for many of which no public dataset is currently available. XL-Sum is highly abstractive, concise, and of high quality, as indicated by human and intrinsic evaluation. We fine-tune mT5, a state-of-the-art pretrained multilingual model, with XL-Sum and experiment on multilingual and low-resource summarization tasks. XL-Sum induces competitive results compared to the ones obtained using similar monolingual datasets: we show higher than 11 ROUGE-2 scores on 10 languages we benchmark on, with some of them exceeding 15, as obtained by multilingual training. Additionally, training on low-resource languages individually also provides competitive performance. To the best of our knowledge, XL-Sum is the largest abstractive summarization dataset in terms of the number of samples collected from a single source and the number of languages covered. We are releasing our dataset and models to encourage future research on multilingual abstractive summarization. The resources can be found at \url{https://github.com/csebuetnlp/xl-sum}.
Algorithms for Solving Nonlinear Binary Optimization Problems in Robust Causal Inference
Dec 22, 2020
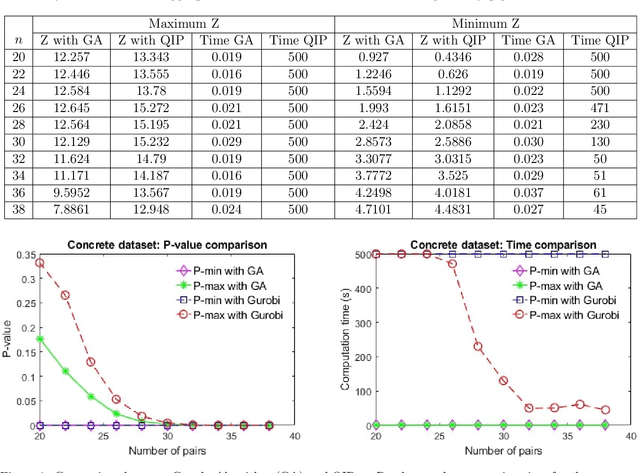

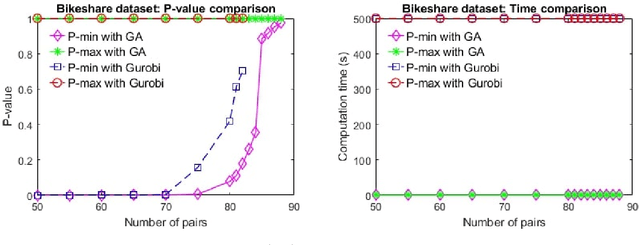
Identifying cause-effect relation among variables is a key step in the decision-making process. While causal inference requires randomized experiments, researchers and policymakers are increasingly using observational studies to test causal hypotheses due to the wide availability of observational data and the infeasibility of experiments. The matching method is the most used technique to make causal inference from observational data. However, the pair assignment process in one-to-one matching creates uncertainty in the inference because of different choices made by the experimenter. Recently, discrete optimization models are proposed to tackle such uncertainty. Although a robust inference is possible with discrete optimization models, they produce nonlinear problems and lack scalability. In this work, we propose greedy algorithms to solve the robust causal inference test instances from observational data with continuous outcomes. We propose a unique framework to reformulate the nonlinear binary optimization problems as feasibility problems. By leveraging the structure of the feasibility formulation, we develop greedy schemes that are efficient in solving robust test problems. In many cases, the proposed algorithms achieve global optimal solution. We perform experiments on three real-world datasets to demonstrate the effectiveness of the proposed algorithms and compare our result with the state-of-the-art solver. Our experiments show that the proposed algorithms significantly outperform the exact method in terms of computation time while achieving the same conclusion for causal tests. Both numerical experiments and complexity analysis demonstrate that the proposed algorithms ensure the scalability required for harnessing the power of big data in the decision-making process.
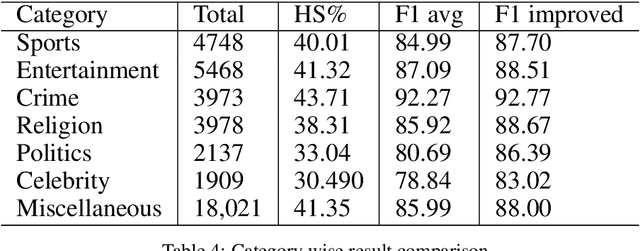
Hate Speech detection in the Bengali language: A dataset and its baseline evaluation
Dec 17, 2020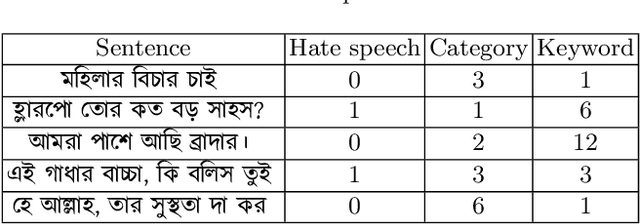
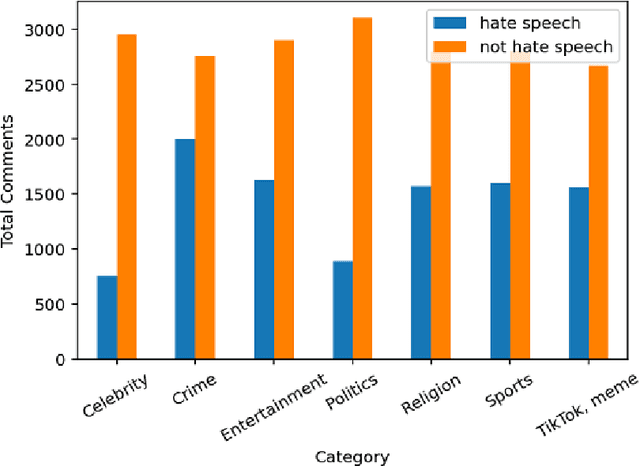
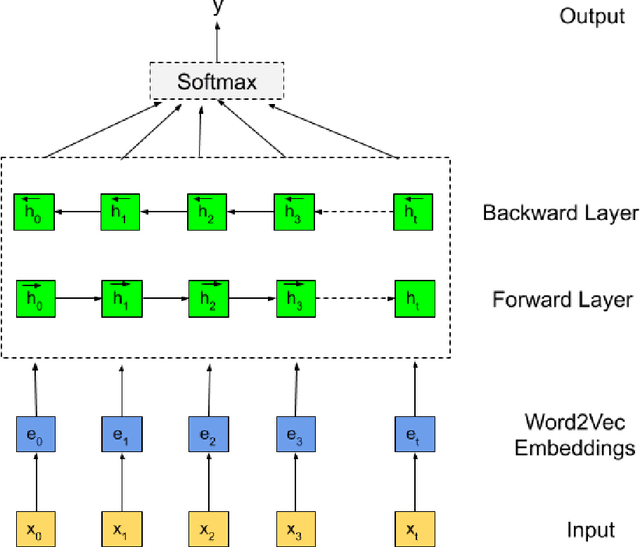
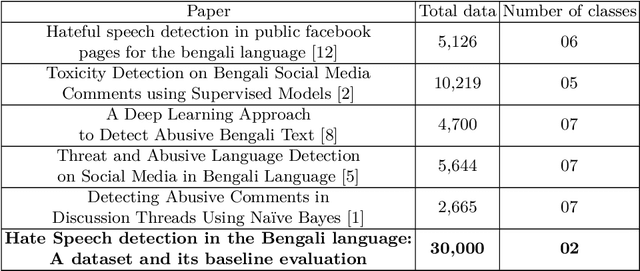
Social media sites such as YouTube and Facebook have become an integral part of everyone's life and in the last few years, hate speech in the social media comment section has increased rapidly. Detection of hate speech on social media websites faces a variety of challenges including small imbalanced data sets, the findings of an appropriate model and also the choice of feature analysis method. further more, this problem is more severe for the Bengali speaking community due to the lack of gold standard labelled datasets. This paper presents a new dataset of 30,000 user comments tagged by crowd sourcing and varified by experts. All the comments are collected from YouTube and Facebook comment section and classified into seven categories: sports, entertainment, religion, politics, crime, celebrity and TikTok & meme. A total of 50 annotators annotated each comment three times and the majority vote was taken as the final annotation. Nevertheless, we have conducted base line experiments and several deep learning models along with extensive pre-trained Bengali word embedding such as Word2Vec, FastText and BengFastText on this dataset to facilitate future research opportunities. The experiment illustrated that although all deep learning models performed well, SVM achieved the best result with 87.5% accuracy. Our core contribution is to make this benchmark dataset available and accessible to facilitate further research in the field of in the field of Bengali hate speech detection.