 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMayank Singh
Augmented Convolutional LSTMs for Generation of High-Resolution Climate Change Projections
Sep 23, 2020
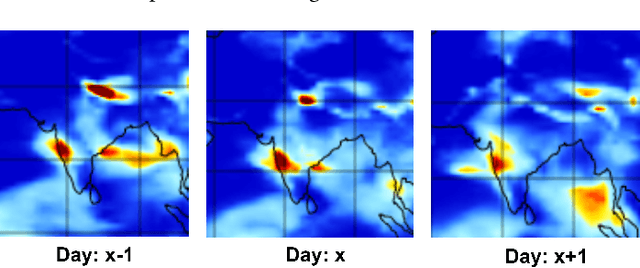
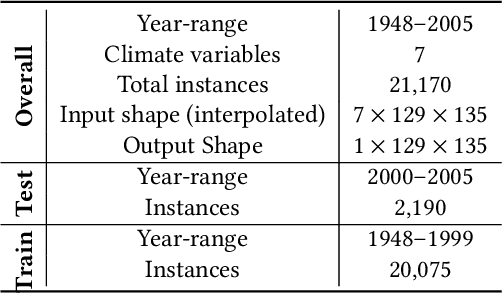
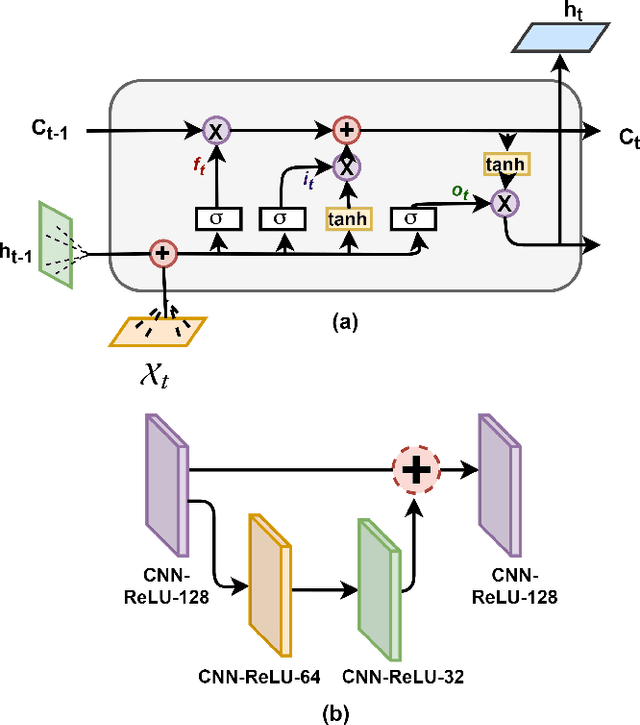
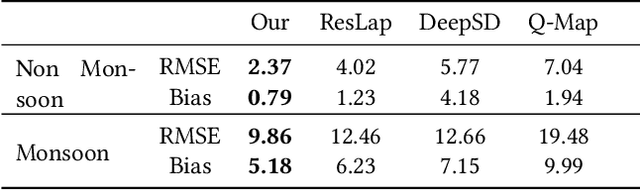
Projection of changes in extreme indices of climate variables such as temperature and precipitation are critical to assess the potential impacts of climate change on human-made and natural systems, including critical infrastructures and ecosystems. While impact assessment and adaptation planning rely on high-resolution projections (typically in the order of a few kilometers), state-of-the-art Earth System Models (ESMs) are available at spatial resolutions of few hundreds of kilometers. Current solutions to obtain high-resolution projections of ESMs include downscaling approaches that consider the information at a coarse-scale to make predictions at local scales. Complex and non-linear interdependence among local climate variables (e.g., temperature and precipitation) and large-scale predictors (e.g., pressure fields) motivate the use of neural network-based super-resolution architectures. In this work, we present auxiliary variables informed spatio-temporal neural architecture for statistical downscaling. The current study performs daily downscaling of precipitation variable from an ESM output at 1.15 degrees (~115 km) to 0.25 degrees (25 km) over the world's most climatically diversified country, India. We showcase significant improvement gain against three popular state-of-the-art baselines with a better ability to predict extreme events. To facilitate reproducible research, we make available all the codes, processed datasets, and trained models in the public domain.
Bollyrics: Automatic Lyrics Generator for Romanised Hindi
Jul 25, 2020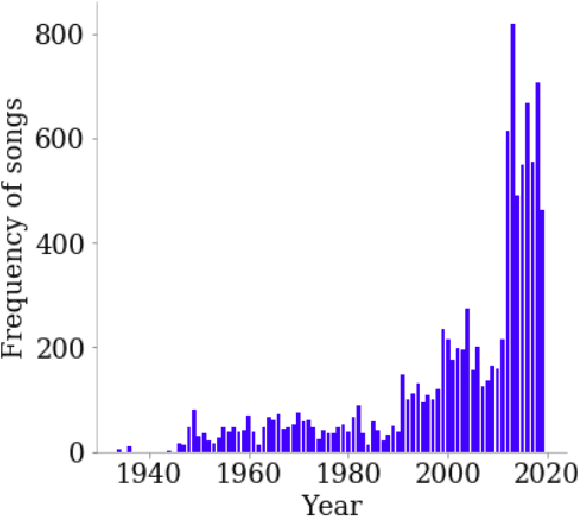
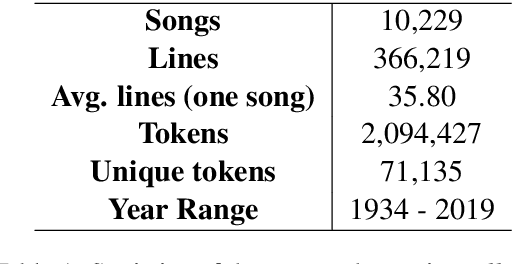
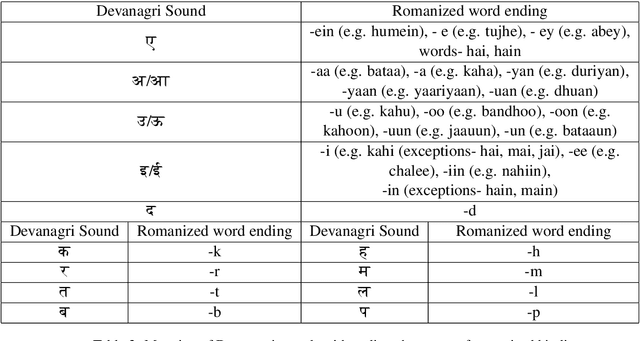

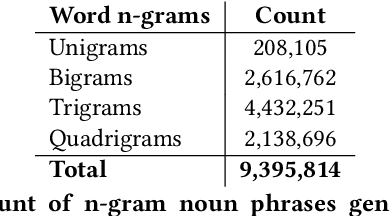
Song lyrics convey a meaningful story in a creative manner with complex rhythmic patterns. Researchers have been successful in generating and analyisng lyrics for poetry and songs in English and Chinese. But there are no works which explore the Hindi language datasets. Given the popularity of Hindi songs across the world and the ambiguous nature of romanized Hindi script, we propose Bollyrics, an automatic lyric generator for romanized Hindi songs. We propose simple techniques to capture rhyming patterns before and during the model training process in Hindi language. The dataset and codes are available publicly at https://github.com/lingo-iitgn/Bollyrics.
Identification, Tracking and Impact: Understanding the trade secret of catchphrases
Jul 20, 2020

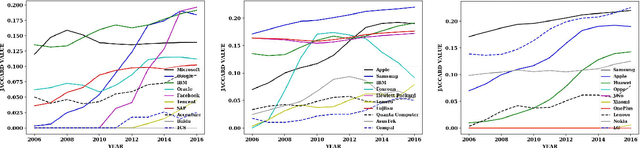
Understanding the topical evolution in industrial innovation is a challenging problem. With the advancement in the digital repositories in the form of patent documents, it is becoming increasingly more feasible to understand the innovation secrets -- "catchphrases" of organizations. However, searching and understanding this enormous textual information is a natural bottleneck. In this paper, we propose an unsupervised method for the extraction of catchphrases from the abstracts of patents granted by the U.S. Patent and Trademark Office over the years. Our proposed system achieves substantial improvement, both in terms of precision and recall, against state-of-the-art techniques. As a second objective, we conduct an extensive empirical study to understand the temporal evolution of the catchphrases across various organizations. We also show how the overall innovation evolution in the form of introduction of newer catchphrases in an organization's patents correlates with the future citations received by the patents filed by that organization. Our code and data sets will be placed in the public domain soon.
IIT Gandhinagar at SemEval-2020 Task 9: Code-Mixed Sentiment Classification Using Candidate Sentence Generation and Selection
Jun 26, 2020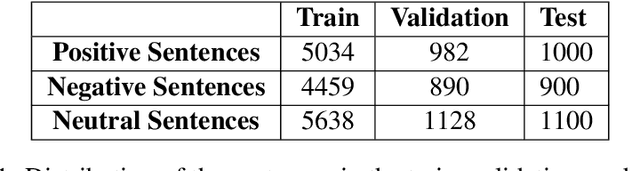


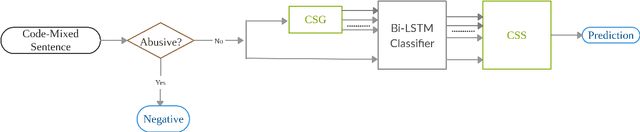
Code-mixing is the phenomenon of using multiple languages in the same utterance of a text or speech. It is a frequently used pattern of communication on various platforms such as social media sites, online gaming, product reviews, etc. Sentiment analysis of the monolingual text is a well-studied task. Code-mixing adds to the challenge of analyzing the sentiment of the text due to the non-standard writing style. We present a candidate sentence generation and selection based approach on top of the Bi-LSTM based neural classifier to classify the Hinglish code-mixed text into one of the three sentiment classes positive, negative, or neutral. The proposed approach shows an improvement in the system performance as compared to the Bi-LSTM based neural classifier. The results present an opportunity to understand various other nuances of code-mixing in the textual data, such as humor-detection, intent classification, etc.
SEAL: Scientific Keyphrase Extraction and Classification
Jun 05, 2020
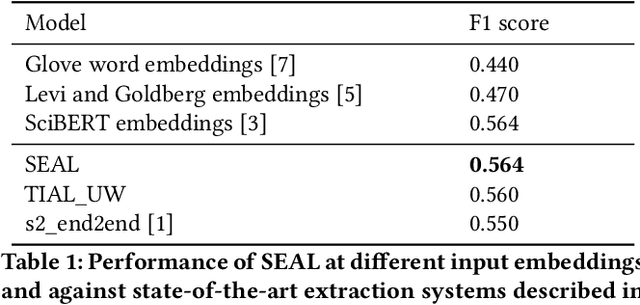

Automatic scientific keyphrase extraction is a challenging problem facilitating several downstream scholarly tasks like search, recommendation, and ranking. In this paper, we introduce SEAL, a scholarly tool for automatic keyphrase extraction and classification. The keyphrase extraction module comprises two-stage neural architecture composed of Bidirectional Long Short-Term Memory cells augmented with Conditional Random Fields. The classification module comprises of a Random Forest classifier. We extensively experiment to showcase the robustness of the system. We evaluate multiple state-of-the-art baselines and show a significant improvement. The current system is hosted at http://lingo.iitgn.ac.in:5000/.
On the Benefits of Models with Perceptually-Aligned Gradients
May 04, 2020



Adversarial robust models have been shown to learn more robust and interpretable features than standard trained models. As shown in [\cite{tsipras2018robustness}], such robust models inherit useful interpretable properties where the gradient aligns perceptually well with images, and adding a large targeted adversarial perturbation leads to an image resembling the target class. We perform experiments to show that interpretable and perceptually aligned gradients are present even in models that do not show high robustness to adversarial attacks. Specifically, we perform adversarial training with attack for different max-perturbation bound. Adversarial training with low max-perturbation bound results in models that have interpretable features with only slight drop in performance over clean samples. In this paper, we leverage models with interpretable perceptually-aligned features and show that adversarial training with low max-perturbation bound can improve the performance of models for zero-shot and weakly supervised localization tasks.
PHINC: A Parallel Hinglish Social Media Code-Mixed Corpus for Machine Translation
Apr 20, 2020

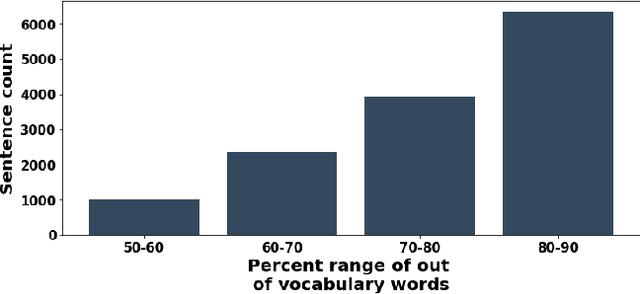
Code-mixing is the phenomenon of using more than one language in a sentence. It is a very frequently observed pattern of communication on social media platforms. Flexibility to use multiple languages in one text message might help to communicate efficiently with the target audience. But, it adds to the challenge of processing and understanding natural language to a much larger extent. This paper presents a parallel corpus of the 13,738 code-mixed English-Hindi sentences and their corresponding translation in English. The translations of sentences are done manually by the annotators. We are releasing the parallel corpus to facilitate future research opportunities in code-mixed machine translation. The annotated corpus is available at https://doi.org/10.5281/zenodo.3605597.
On the Benefits of Attributional Robustness
Dec 10, 2019
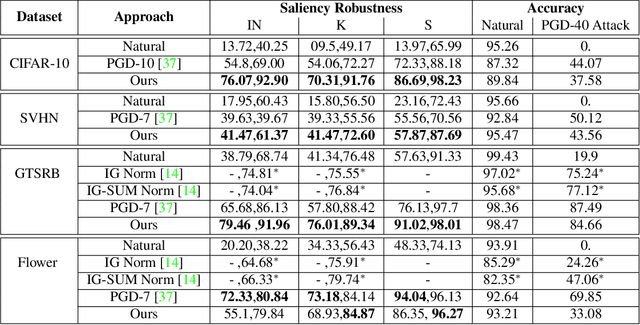
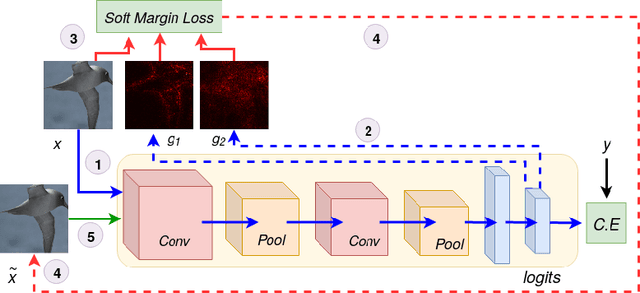
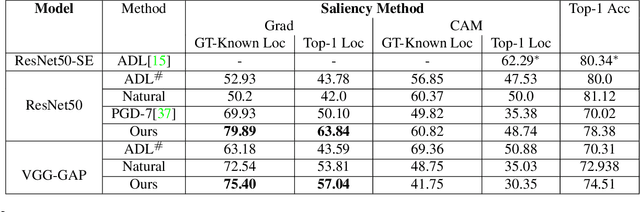
Interpretability is an emerging area of research in trustworthy machine learning. Safe deployment of machine learning system mandates that the prediction and its explanation be reliable and robust. Recently, it was shown that one could craft perturbations that produce perceptually indistinguishable inputs having the same prediction, yet very different interpretations. We tackle the problem of attributional robustness (i.e. models having robust explanations) by maximizing the alignment between the input image and its saliency map using soft-margin triplet loss. We propose a robust attribution training methodology that beats the state-of-the-art attributional robustness measure by a margin of approximately 6-18% on several standard datasets, ie. SVHN, CIFAR-10 and GTSRB. We further show the utility of the proposed robust model in the domain of weakly supervised object localization and segmentation. Our proposed robust model also achieves a new state-of-the-art object localization accuracy on the CUB-200 dataset.