 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDExT: Detector Explanation Toolkit
Dec 21, 2022



State-of-the-art object detectors are treated as black boxes due to their highly non-linear internal computations. Even with unprecedented advancements in detector performance, the inability to explain how their outputs are generated limits their use in safety-critical applications. Previous work fails to produce explanations for both bounding box and classification decisions, and generally make individual explanations for various detectors. In this paper, we propose an open-source Detector Explanation Toolkit (DExT) which implements the proposed approach to generate a holistic explanation for all detector decisions using certain gradient-based explanation methods. We suggests various multi-object visualization methods to merge the explanations of multiple objects detected in an image as well as the corresponding detections in a single image. The quantitative evaluation show that the Single Shot MultiBox Detector (SSD) is more faithfully explained compared to other detectors regardless of the explanation methods. Both quantitative and human-centric evaluations identify that SmoothGrad with Guided Backpropagation (GBP) provides more trustworthy explanations among selected methods across all detectors. We expect that DExT will motivate practitioners to evaluate object detectors from the interpretability perspective by explaining both bounding box and classification decisions.
Disentangled Uncertainty and Out of Distribution Detection in Medical Generative Models
Nov 11, 2022



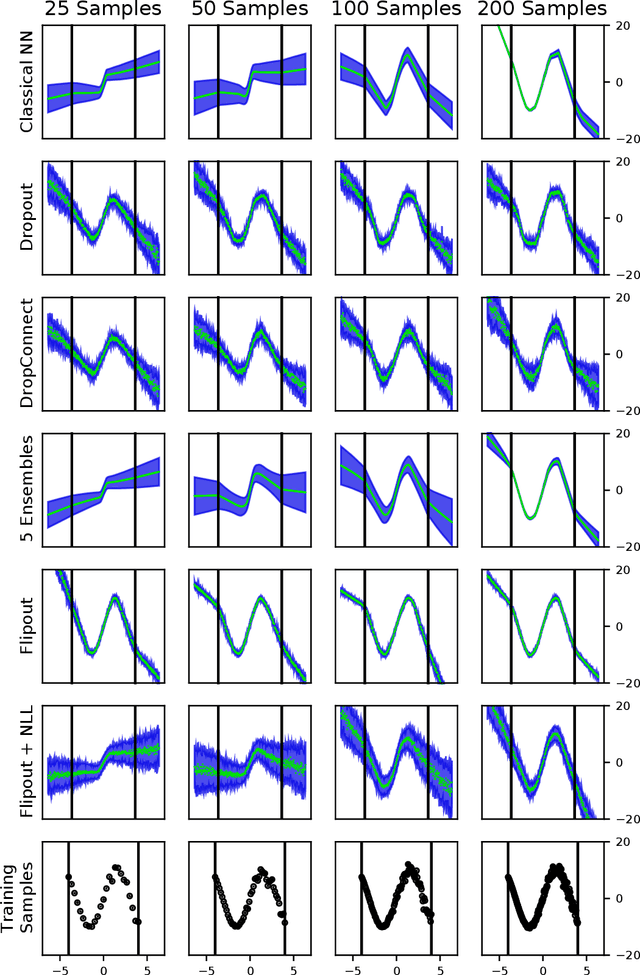
Trusting the predictions of deep learning models in safety critical settings such as the medical domain is still not a viable option. Distentangled uncertainty quantification in the field of medical imaging has received little attention. In this paper, we study disentangled uncertainties in image to image translation tasks in the medical domain. We compare multiple uncertainty quantification methods, namely Ensembles, Flipout, Dropout, and DropConnect, while using CycleGAN to convert T1-weighted brain MRI scans to T2-weighted brain MRI scans. We further evaluate uncertainty behavior in the presence of out of distribution data (Brain CT and RGB Face Images), showing that epistemic uncertainty can be used to detect out of distribution inputs, which should increase reliability of model outputs.
A Benchmark for Out of Distribution Detection in Point Cloud 3D Semantic Segmentation
Nov 11, 2022Safety-critical applications like autonomous driving use Deep Neural Networks (DNNs) for object detection and segmentation. The DNNs fail to predict when they observe an Out-of-Distribution (OOD) input leading to catastrophic consequences. Existing OOD detection methods were extensively studied for image inputs but have not been explored much for LiDAR inputs. So in this study, we proposed two datasets for benchmarking OOD detection in 3D semantic segmentation. We used Maximum Softmax Probability and Entropy scores generated using Deep Ensembles and Flipout versions of RandLA-Net as OOD scores. We observed that Deep Ensembles out perform Flipout model in OOD detection with greater AUROC scores for both datasets.
Comparison of Uncertainty Quantification with Deep Learning in Time Series Regression
Nov 11, 2022



Increasingly high-stakes decisions are made using neural networks in order to make predictions. Specifically, meteorologists and hedge funds apply these techniques to time series data. When it comes to prediction, there are certain limitations for machine learning models (such as lack of expressiveness, vulnerability of domain shifts and overconfidence) which can be solved using uncertainty estimation. There is a set of expectations regarding how uncertainty should ``behave". For instance, a wider prediction horizon should lead to more uncertainty or the model's confidence should be proportional to its accuracy. In this paper, different uncertainty estimation methods are compared to forecast meteorological time series data and evaluate these expectations. The results show how each uncertainty estimation method performs on the forecasting task, which partially evaluates the robustness of predicted uncertainty.
Machine Learning Students Overfit to Overfitting
Sep 07, 2022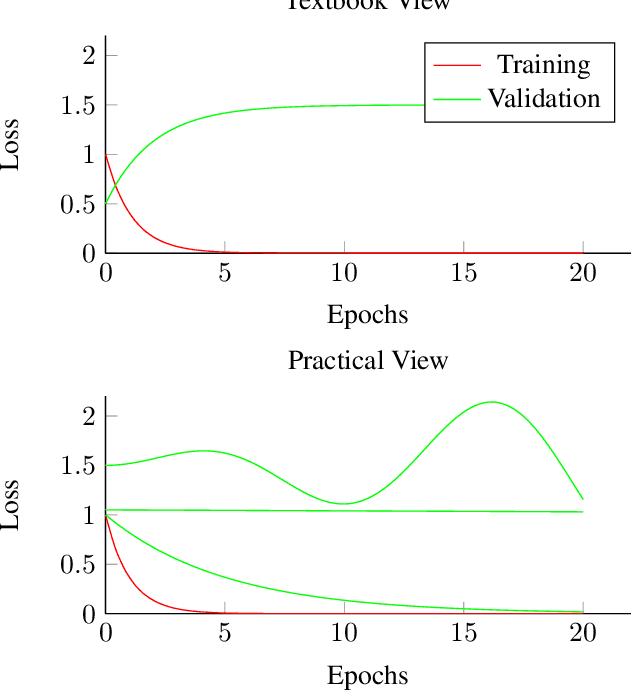


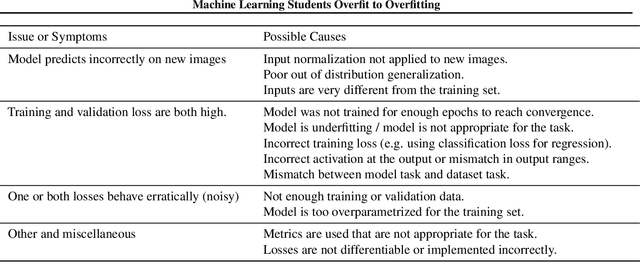
Overfitting and generalization is an important concept in Machine Learning as only models that generalize are interesting for general applications. Yet some students have trouble learning this important concept through lectures and exercises. In this paper we describe common examples of students misunderstanding overfitting, and provide recommendations for possible solutions. We cover student misconceptions about overfitting, about solutions to overfitting, and implementation mistakes that are commonly confused with overfitting issues. We expect that our paper can contribute to improving student understanding and lectures about this important topic.
Self-supervised Learning for Sonar Image Classification
Apr 20, 2022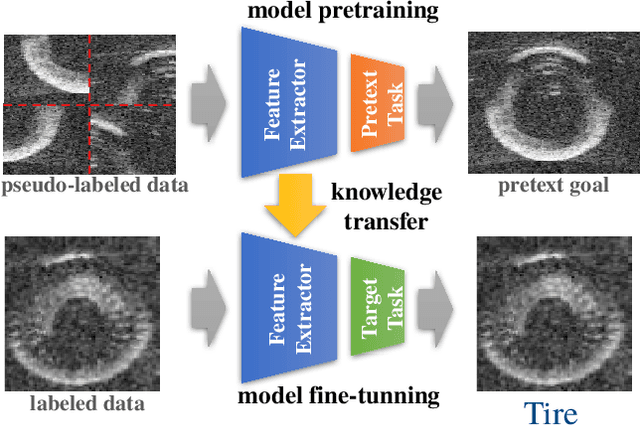

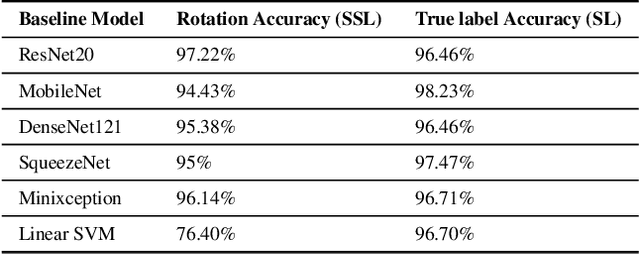
Self-supervised learning has proved to be a powerful approach to learn image representations without the need of large labeled datasets. For underwater robotics, it is of great interest to design computer vision algorithms to improve perception capabilities such as sonar image classification. Due to the confidential nature of sonar imaging and the difficulty to interpret sonar images, it is challenging to create public large labeled sonar datasets to train supervised learning algorithms. In this work, we investigate the potential of three self-supervised learning methods (RotNet, Denoising Autoencoders, and Jigsaw) to learn high-quality sonar image representation without the need of human labels. We present pre-training and transfer learning results on real-life sonar image datasets. Our results indicate that self-supervised pre-training yields classification performance comparable to supervised pre-training in a few-shot transfer learning setup across all three methods. Code and self-supervised pre-trained models are be available at https://github.com/agrija9/ssl-sonar-images
A Deeper Look into Aleatoric and Epistemic Uncertainty Disentanglement
Apr 20, 2022
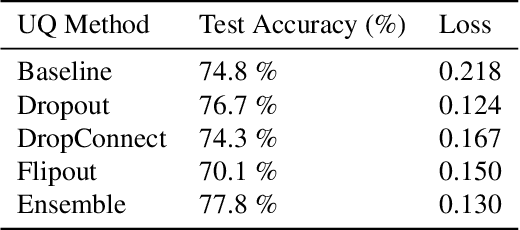
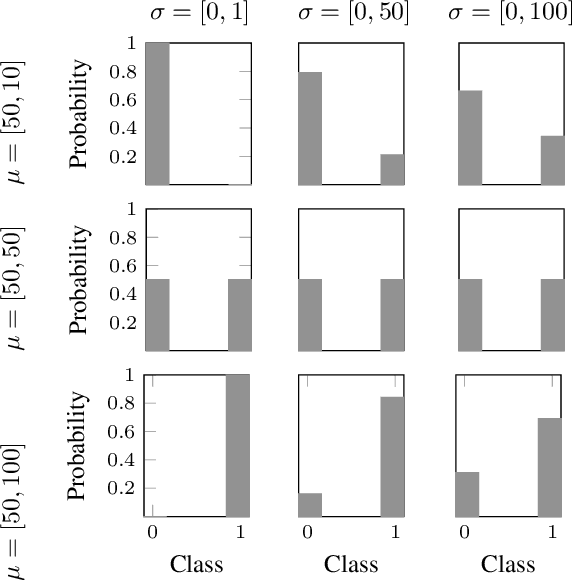
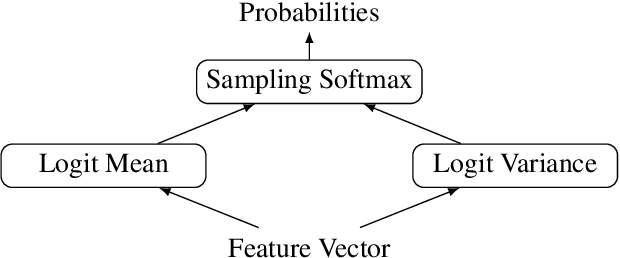
Neural networks are ubiquitous in many tasks, but trusting their predictions is an open issue. Uncertainty quantification is required for many applications, and disentangled aleatoric and epistemic uncertainties are best. In this paper, we generalize methods to produce disentangled uncertainties to work with different uncertainty quantification methods, and evaluate their capability to produce disentangled uncertainties. Our results show that: there is an interaction between learning aleatoric and epistemic uncertainty, which is unexpected and violates assumptions on aleatoric uncertainty, some methods like Flipout produce zero epistemic uncertainty, aleatoric uncertainty is unreliable in the out-of-distribution setting, and Ensembles provide overall the best disentangling quality. We also explore the error produced by the number of samples hyper-parameter in the sampling softmax function, recommending N > 100 samples. We expect that our formulation and results help practitioners and researchers choose uncertainty methods and expand the use of disentangled uncertainties, as well as motivate additional research into this topic.
Feature Disentanglement of Robot Trajectories
Dec 06, 2021
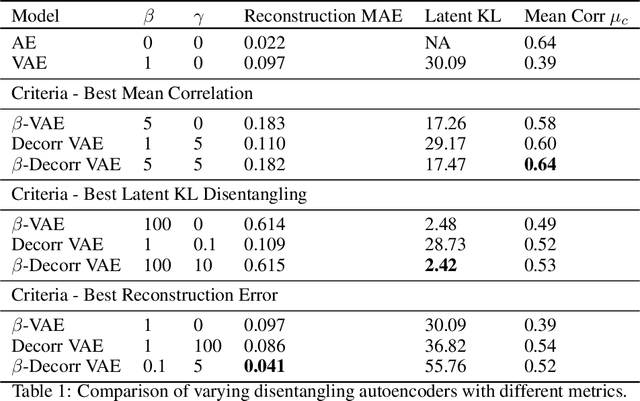

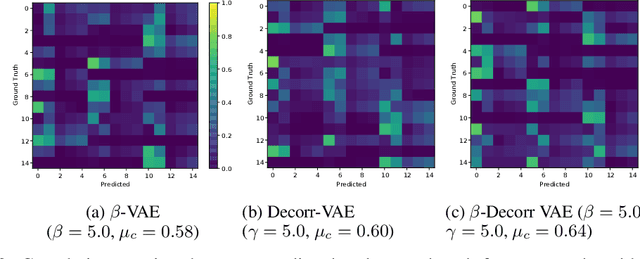
Modeling trajectories generated by robot joints is complex and required for high level activities like trajectory generation, clustering, and classification. Disentagled representation learning promises advances in unsupervised learning, but they have not been evaluated in robot-generated trajectories. In this paper we evaluate three disentangling VAEs ($\beta$-VAE, Decorr VAE, and a new $\beta$-Decorr VAE) on a dataset of 1M robot trajectories generated from a 3 DoF robot arm. We find that the decorrelation-based formulations perform the best in terms of disentangling metrics, trajectory quality, and correlation with ground truth latent features. We expect that these results increase the use of unsupervised learning in robot control.
Benchmark for Out-of-Distribution Detection in Deep Reinforcement Learning
Dec 05, 2021
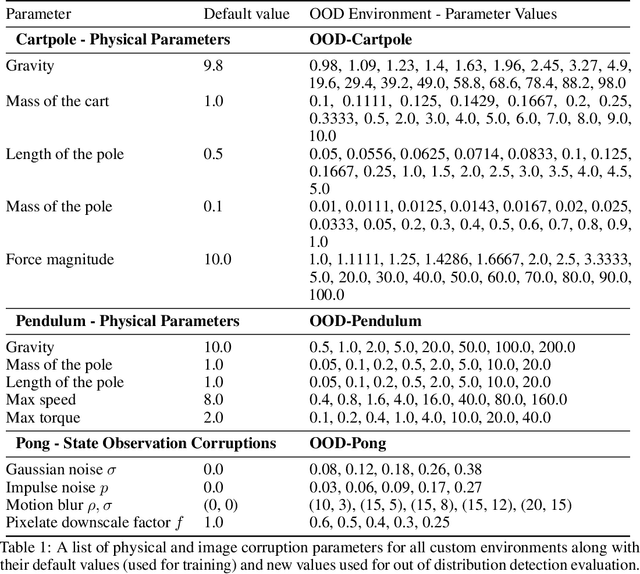
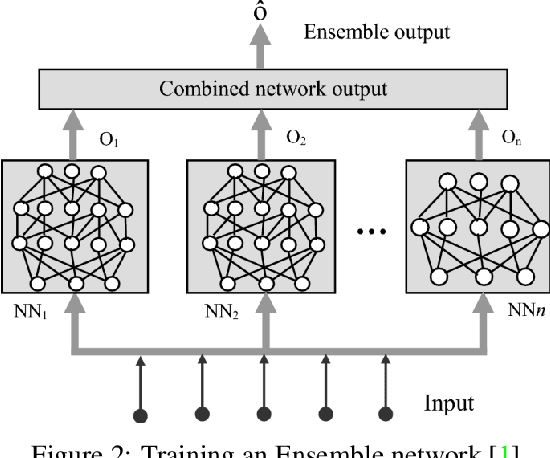

Reinforcement Learning (RL) based solutions are being adopted in a variety of domains including robotics, health care and industrial automation. Most focus is given to when these solutions work well, but they fail when presented with out of distribution inputs. RL policies share the same faults as most machine learning models. Out of distribution detection for RL is generally not well covered in the literature, and there is a lack of benchmarks for this task. In this work we propose a benchmark to evaluate OOD detection methods in a Reinforcement Learning setting, by modifying the physical parameters of non-visual standard environments or corrupting the state observation for visual environments. We discuss ways to generate custom RL environments that can produce OOD data, and evaluate three uncertainty methods for the OOD detection task. Our results show that ensemble methods have the best OOD detection performance with a lower standard deviation across multiple environments.
Exploring the Limits of Epistemic Uncertainty Quantification in Low-Shot Settings
Nov 18, 2021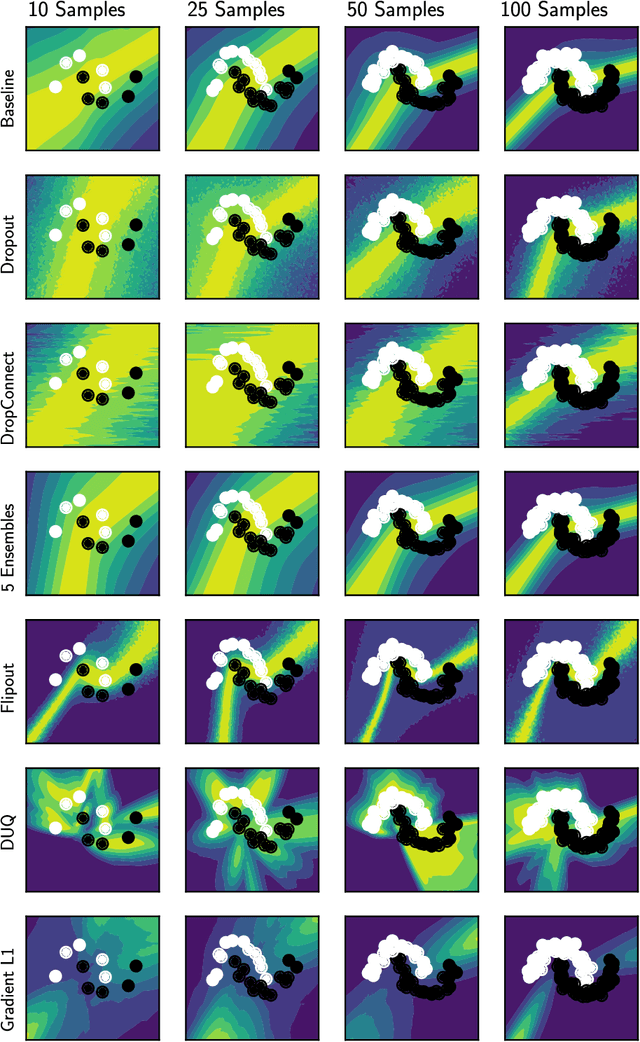
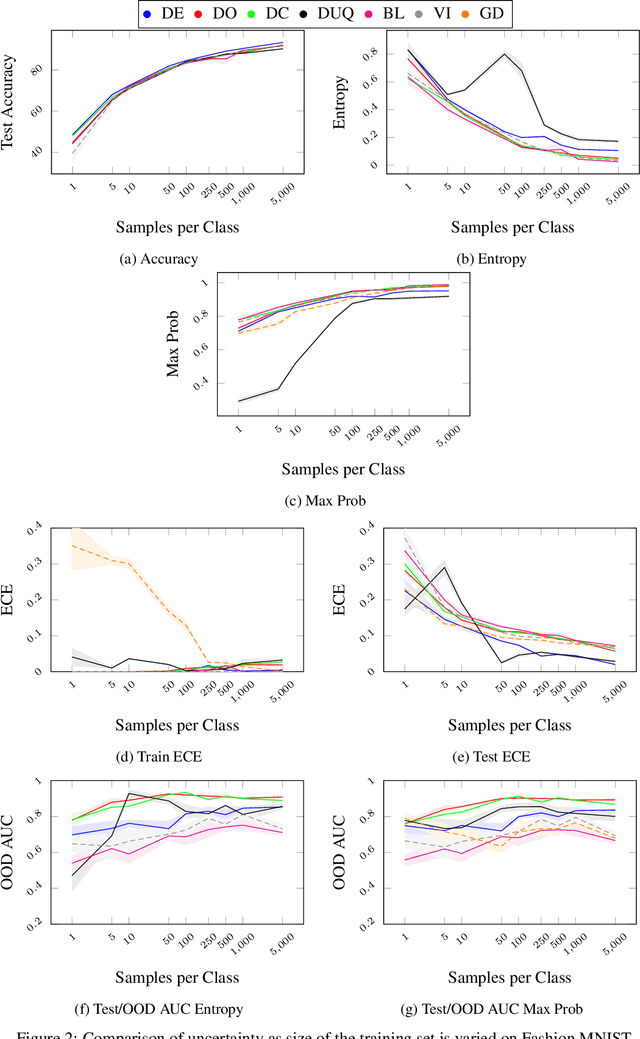
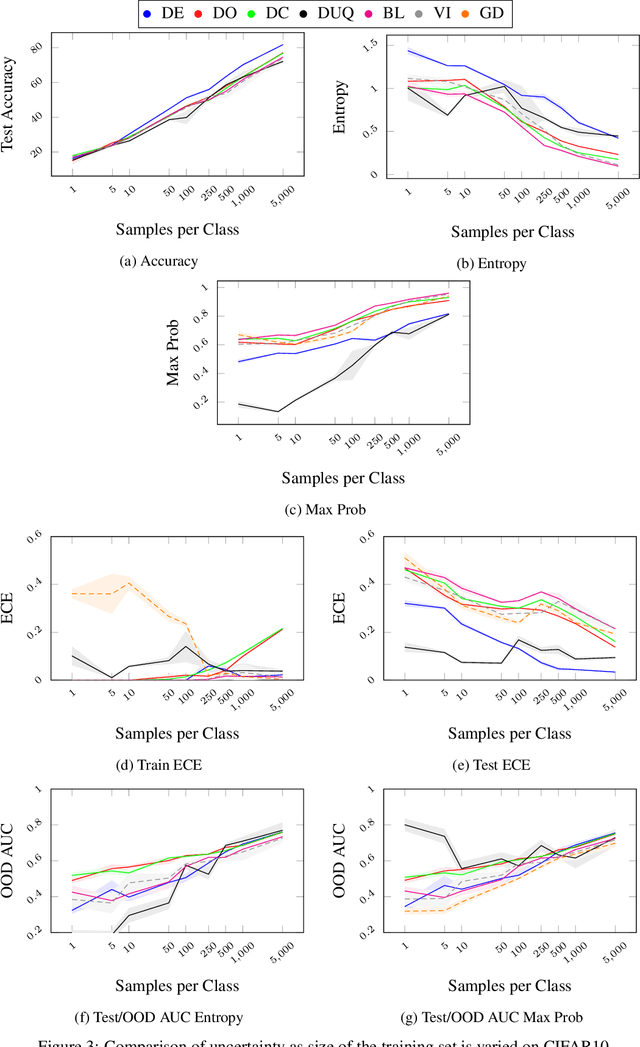
Uncertainty quantification in neural network promises to increase safety of AI systems, but it is not clear how performance might vary with the training set size. In this paper we evaluate seven uncertainty methods on Fashion MNIST and CIFAR10, as we sub-sample and produce varied training set sizes. We find that calibration error and out of distribution detection performance strongly depend on the training set size, with most methods being miscalibrated on the test set with small training sets. Gradient-based methods seem to poorly estimate epistemic uncertainty and are the most affected by training set size. We expect our results can guide future research into uncertainty quantification and help practitioners select methods based on their particular available data.