 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificially Evolved Chunks for Morphosyntactic Analysis
Aug 21, 2019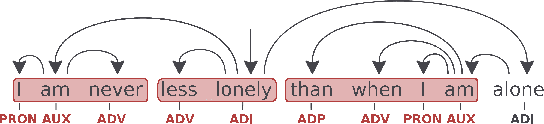
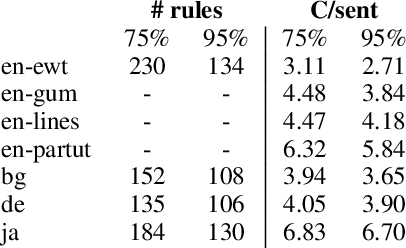
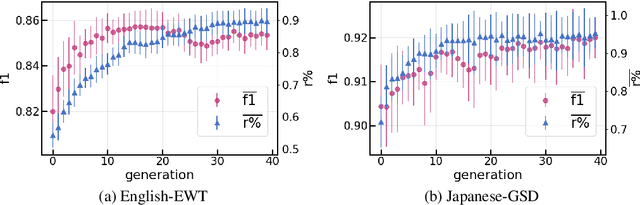
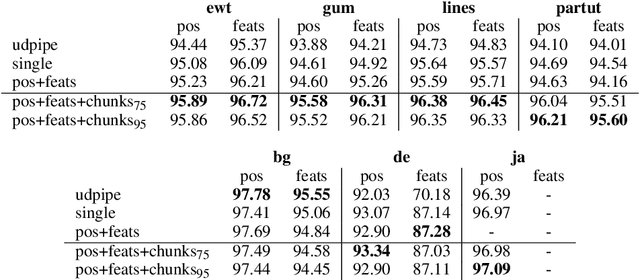
We introduce a language-agnostic evolutionary technique for automatically extracting chunks from dependency treebanks. We evaluate these chunks on a number of morphosyntactic tasks, namely POS tagging, morphological feature tagging, and dependency parsing. We test the utility of these chunks in a host of different ways. We first learn chunking as one task in a shared multi-task framework together with POS and morphological feature tagging. The predictions from this network are then used as input to augment sequence-labelling dependency parsing. Finally, we investigate the impact chunks have on dependency parsing in a multi-task framework. Our results from these analyses show that these chunks improve performance at different levels of syntactic abstraction on English UD treebanks and a small, diverse subset of non-English UD treebanks.