 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Experimental Comparison of Several Clustering and Initialization Methods
May 16, 2015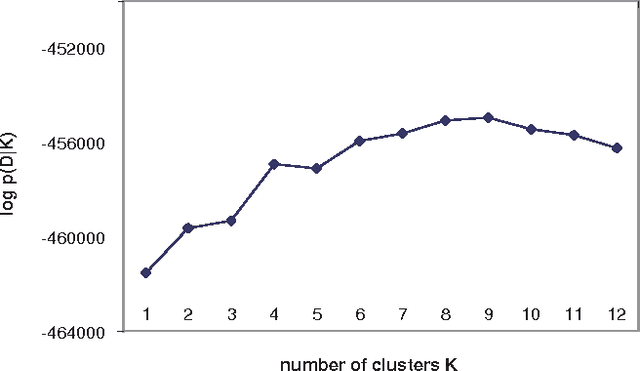

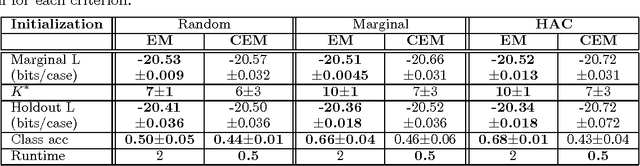
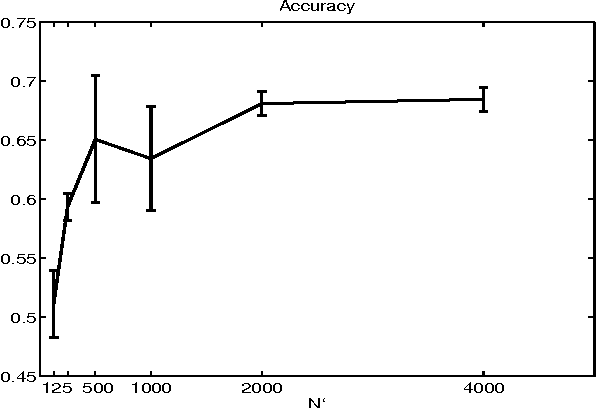
We examine methods for clustering in high dimensions. In the first part of the paper, we perform an experimental comparison between three batch clustering algorithms: the Expectation-Maximization (EM) algorithm, a winner take all version of the EM algorithm reminiscent of the K-means algorithm, and model-based hierarchical agglomerative clustering. We learn naive-Bayes models with a hidden root node, using high-dimensional discrete-variable data sets (both real and synthetic). We find that the EM algorithm significantly outperforms the other methods, and proceed to investigate the effect of various initialization schemes on the final solution produced by the EM algorithm. The initializations that we consider are (1) parameters sampled from an uninformative prior, (2) random perturbations of the marginal distribution of the data, and (3) the output of hierarchical agglomerative clustering. Although the methods are substantially different, they lead to learned models that are strikingly similar in quality.
Graph Sensitive Indices for Comparing Clusterings
Nov 27, 2014
This report discusses two new indices for comparing clusterings of a set of points. The motivation for looking at new ways for comparing clusterings stems from the fact that the existing clustering indices are based on set cardinality alone and do not consider the positions of data points. The new indices, namely, the Random Walk index (RWI) and Variation of Information with Neighbors (VIN), are both inspired by the clustering metric Variation of Information (VI). VI possesses some interesting theoretical properties which are also desirable in a metric for comparing clusterings. We define our indices and discuss some of their explored properties which appear relevant for a clustering index. We also include the results of these indices on clusterings of some example data sets.
Improved graph Laplacian via geometric self-consistency
May 31, 2014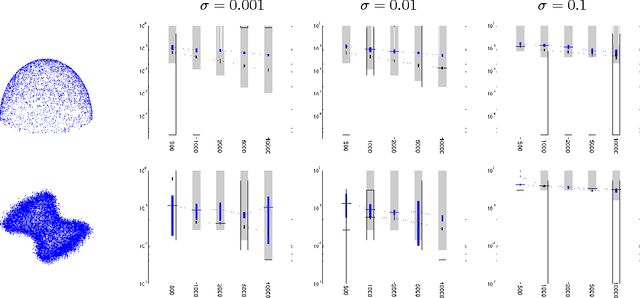
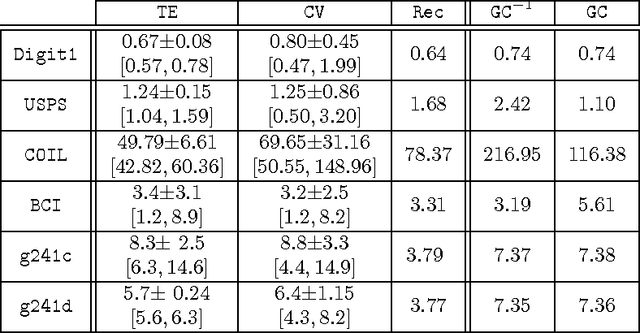
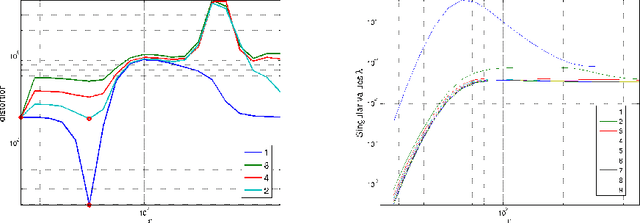
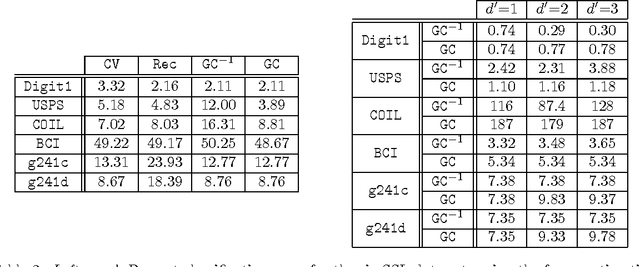
We address the problem of setting the kernel bandwidth used by Manifold Learning algorithms to construct the graph Laplacian. Exploiting the connection between manifold geometry, represented by the Riemannian metric, and the Laplace-Beltrami operator, we set the bandwidth by optimizing the Laplacian's ability to preserve the geometry of the data. Experiments show that this principled approach is effective and robust.
Estimating Vector Fields on Manifolds and the Embedding of Directed Graphs
May 30, 2014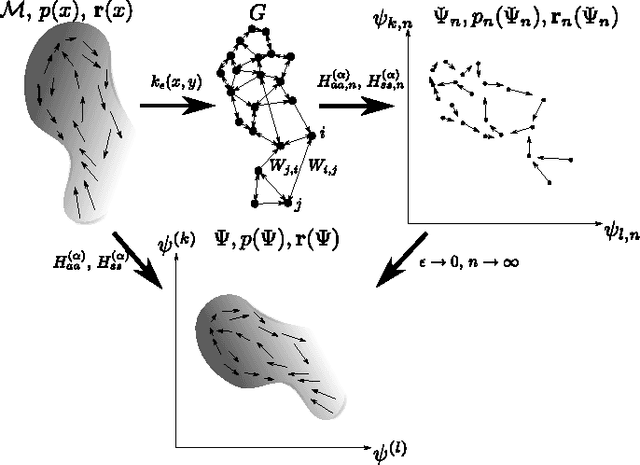
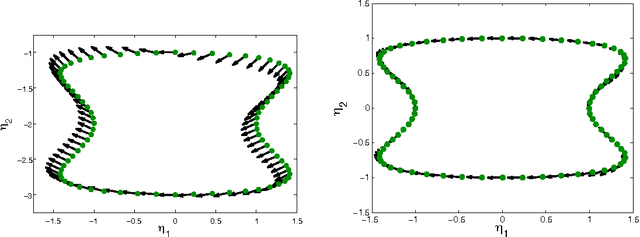

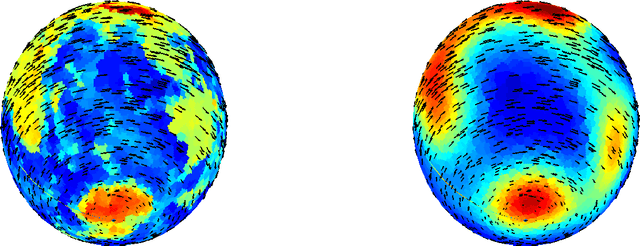
This paper considers the problem of embedding directed graphs in Euclidean space while retaining directional information. We model a directed graph as a finite set of observations from a diffusion on a manifold endowed with a vector field. This is the first generative model of its kind for directed graphs. We introduce a graph embedding algorithm that estimates all three features of this model: the low-dimensional embedding of the manifold, the data density and the vector field. In the process, we also obtain new theoretical results on the limits of "Laplacian type" matrices derived from directed graphs. The application of our method to both artificially constructed and real data highlights its strengths.
An Algorithmic Theory of Dependent Regularizers, Part 1: Submodular Structure
Dec 06, 2013
We present an exploration of the rich theoretical connections between several classes of regularized models, network flows, and recent results in submodular function theory. This work unifies key aspects of these problems under a common theory, leading to novel methods for working with several important models of interest in statistics, machine learning and computer vision. In Part 1, we review the concepts of network flows and submodular function optimization theory foundational to our results. We then examine the connections between network flows and the minimum-norm algorithm from submodular optimization, extending and improving several current results. This leads to a concise representation of the structure of a large class of pairwise regularized models important in machine learning, statistics and computer vision. In Part 2, we describe the full regularization path of a class of penalized regression problems with dependent variables that includes the graph-guided LASSO and total variation constrained models. This description also motivates a practical algorithm. This allows us to efficiently find the regularization path of the discretized version of TV penalized models. Ultimately, our new algorithms scale up to high-dimensional problems with millions of variables.
Non-linear dimensionality reduction: Riemannian metric estimation and the problem of geometric discovery
May 30, 2013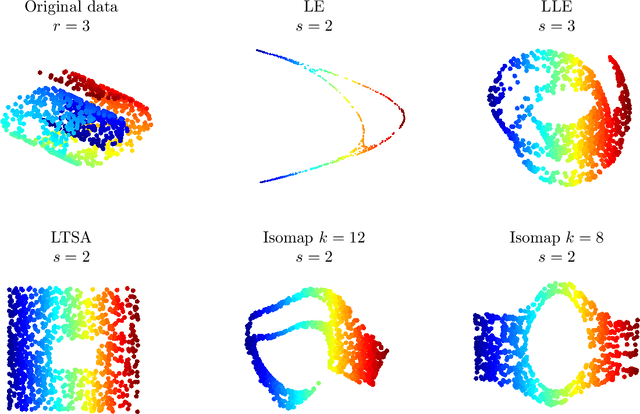



In recent years, manifold learning has become increasingly popular as a tool for performing non-linear dimensionality reduction. This has led to the development of numerous algorithms of varying degrees of complexity that aim to recover man ifold geometry using either local or global features of the data. Building on the Laplacian Eigenmap and Diffusionmaps framework, we propose a new paradigm that offers a guarantee, under reasonable assumptions, that any manifo ld learning algorithm will preserve the geometry of a data set. Our approach is based on augmenting the output of embedding algorithms with geometric informatio n embodied in the Riemannian metric of the manifold. We provide an algorithm for estimating the Riemannian metric from data and demonstrate possible application s of our approach in a variety of examples.
Tractable Bayesian Learning of Tree Belief Networks
Jan 16, 2013In this paper we present decomposable priors, a family of priors over structure and parameters of tree belief nets for which Bayesian learning with complete observations is tractable, in the sense that the posterior is also decomposable and can be completely determined analytically in polynomial time. This follows from two main results: First, we show that factored distributions over spanning trees in a graph can be integrated in closed form. Second, we examine priors over tree parameters and show that a set of assumptions similar to (Heckerman and al. 1995) constrain the tree parameter priors to be a compactly parameterized product of Dirichlet distributions. Beside allowing for exact Bayesian learning, these results permit us to formulate a new class of tractable latent variable models in which the likelihood of a data point is computed through an ensemble average over tree structures.
Unsupervised spectral learning
Jul 04, 2012In spectral clustering and spectral image segmentation, the data is partioned starting from a given matrix of pairwise similarities S. the matrix S is constructed by hand, or learned on a separate training set. In this paper we show how to achieve spectral clustering in unsupervised mode. Our algorithm starts with a set of observed pairwise features, which are possible components of an unknown, parametric similarity function. This function is learned iteratively, at the same time as the clustering of the data. The algorithm shows promosing results on synthetic and real data.
Consensus ranking under the exponential model
Jun 20, 2012
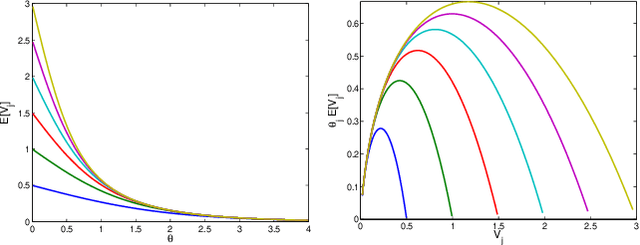
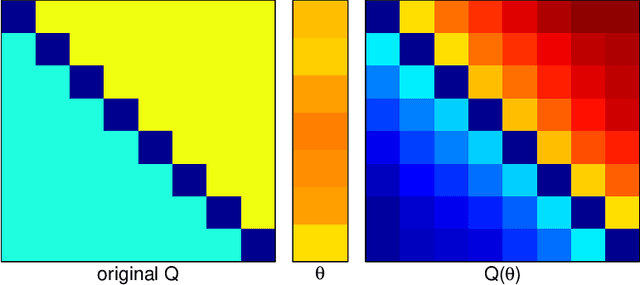
We analyze the generalized Mallows model, a popular exponential model over rankings. Estimating the central (or consensus) ranking from data is NP-hard. We obtain the following new results: (1) We show that search methods can estimate both the central ranking pi0 and the model parameters theta exactly. The search is n! in the worst case, but is tractable when the true distribution is concentrated around its mode; (2) We show that the generalized Mallows model is jointly exponential in (pi0; theta), and introduce the conjugate prior for this model class; (3) The sufficient statistics are the pairwise marginal probabilities that item i is preferred to item j. Preliminary experiments confirm the theoretical predictions and compare the new algorithm and existing heuristics.
Estimation and Clustering with Infinite Rankings
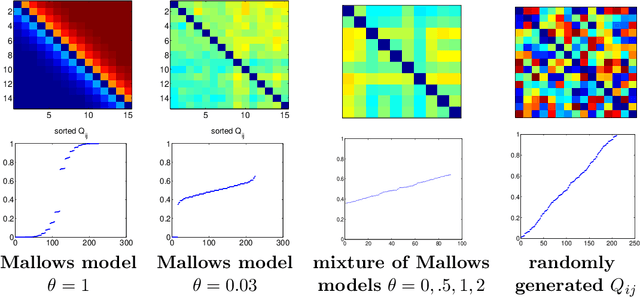
Jun 13, 2012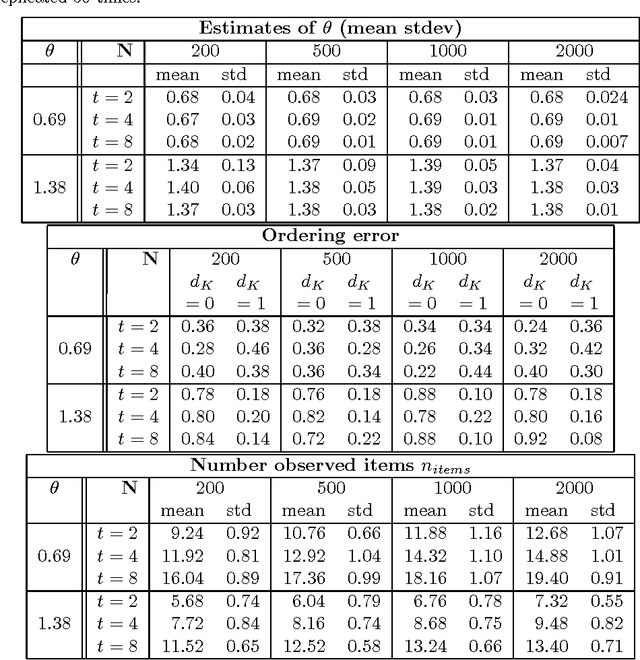
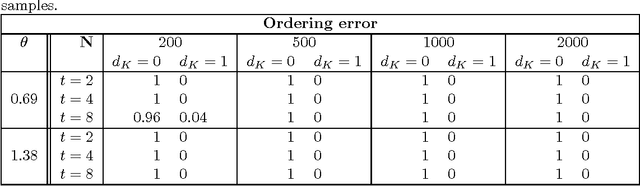


This paper presents a natural extension of stagewise ranking to the the case of infinitely many items. We introduce the infinite generalized Mallows model (IGM), describe its properties and give procedures to estimate it from data. For estimation of multimodal distributions we introduce the Exponential-Blurring-Mean-Shift nonparametric clustering algorithm. The experiments highlight the properties of the new model and demonstrate that infinite models can be simple, elegant and practical.