 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying multi-angled parallelism to Spanish topographical maps
Feb 24, 2022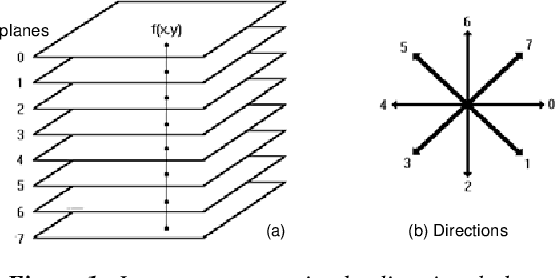
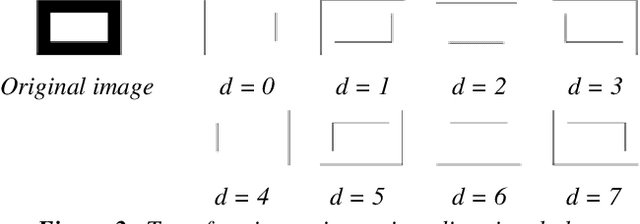

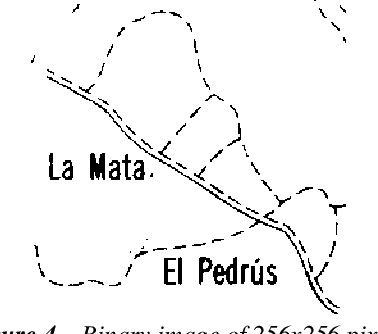
Multi-Angled Parallelism (MAP) is a method to recognize lines in binary images. It is suitable to be implemented in parallel processing and image processing hardware. The binary image is transformed into directional planes, upon which, directional operators of erosion-dilation are iteratively applyed. From a set of basic operators, more complex ones are created, which let to extract the several types of lines. Each type is extracted with a different set of operations and so the lines are identified when extracted. In this paper, an overview of MAP is made, and it is adapted to line recognition in Spanish topographical maps, with the double purpose of testing the method in a real case and studying the process of adapting it to a custom application.
* 4 pages
Interblock redundancy reduction using QUADTREES
Feb 24, 2022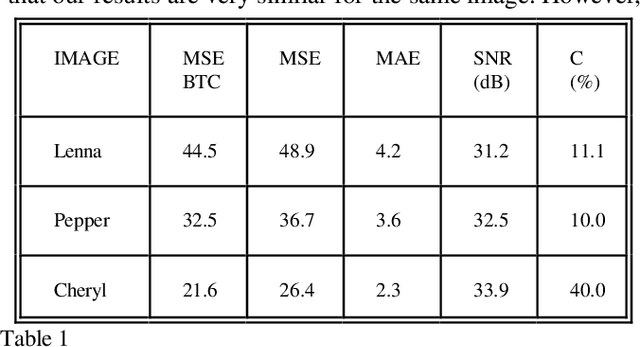
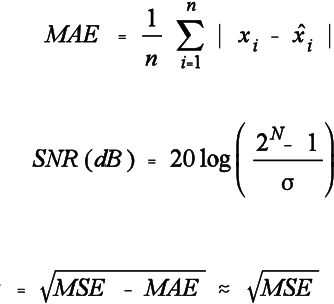
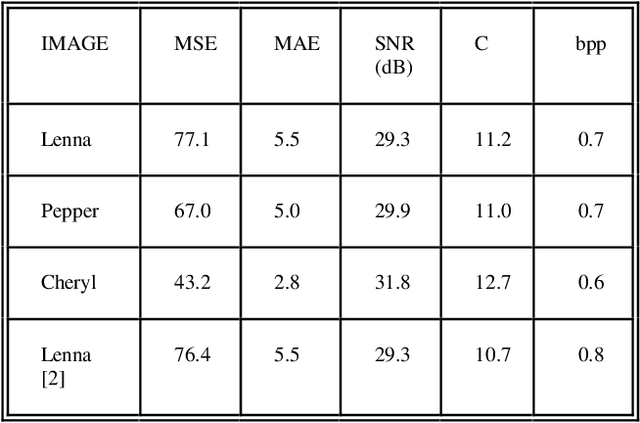
This paper applies the quadtree structure for image coding. The goal is to adapt the block size and thus to increase the compression ratio (without reducing SNR). Also, the computational time is not significatively increased. It has been applied to Block Truncation Coding of still images, and motion vector coding (interframe). An inter/intraframe application is also discussed.
* 4 pages
Speech segmentation using multilevel hybrid filters
Feb 24, 2022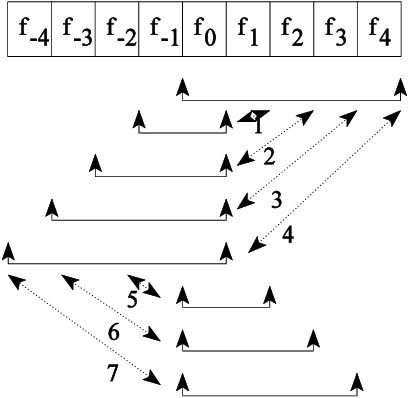
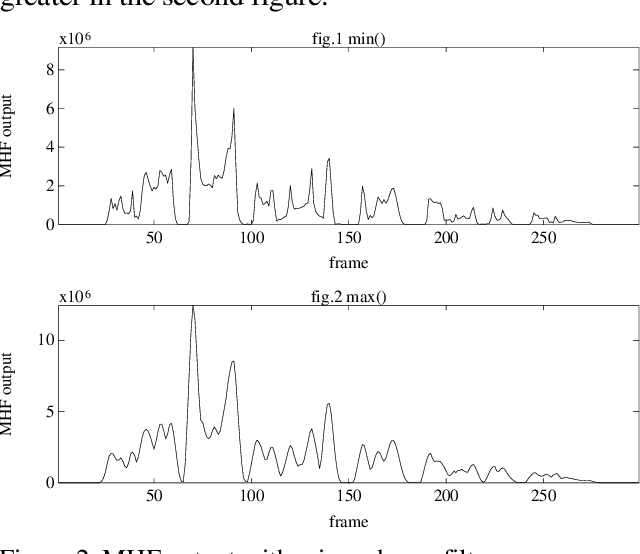
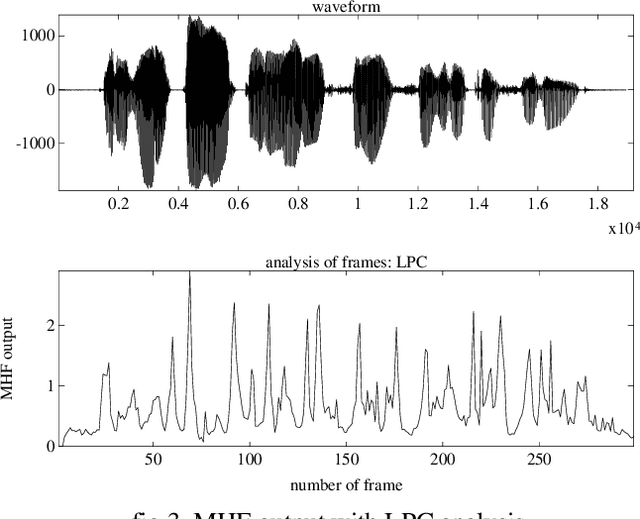
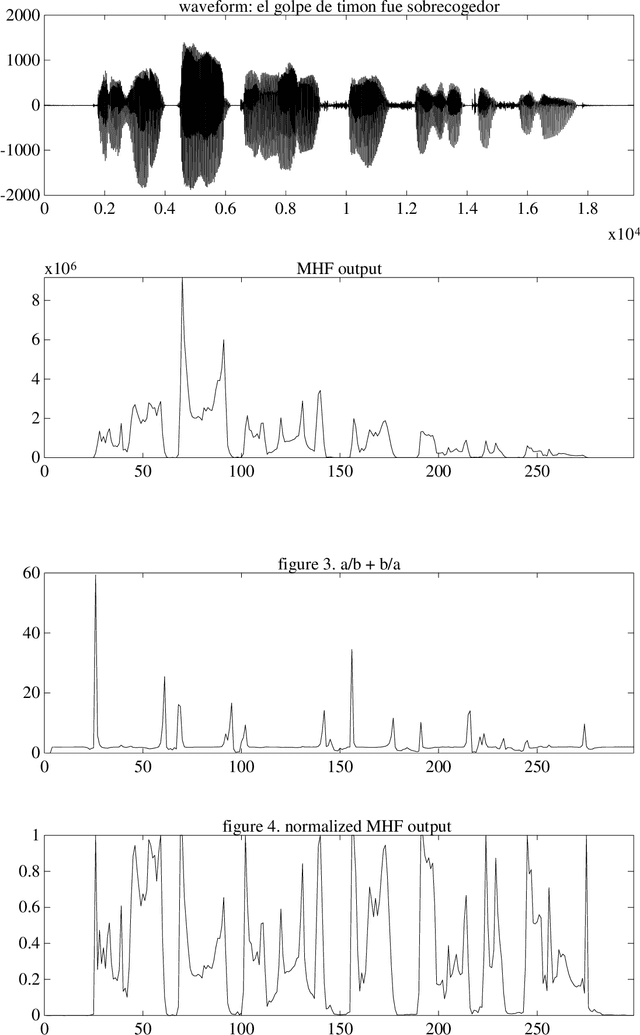
A novel approach for speech segmentation is proposed, based on Multilevel Hybrid (mean/min) Filters (MHF) with the following features: An accurate transition location. Good performance in noisy environments (gaussian and impulsive noise). The proposed method is based on spectral changes, with the goal of segmenting the voice into homogeneous acoustic segments. This algorithm is being used for phoneticallysegmented speech coder, with successful results.
* 4 pages
A modification of the conjugate direction method for motion estimation
Feb 23, 2022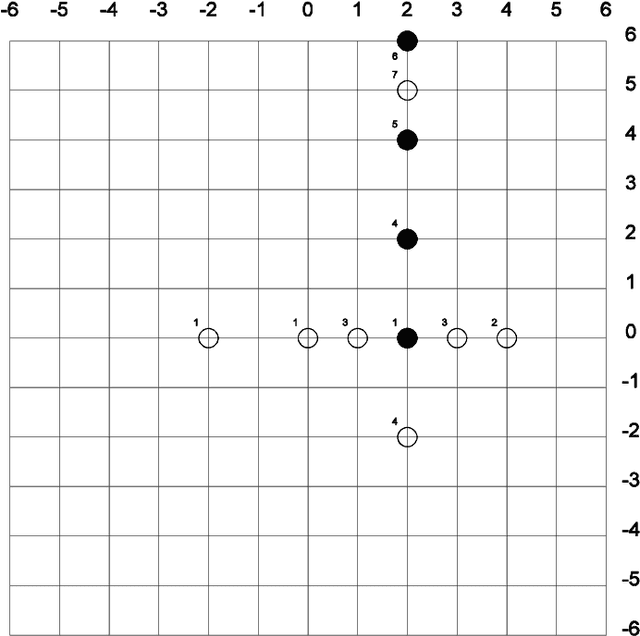
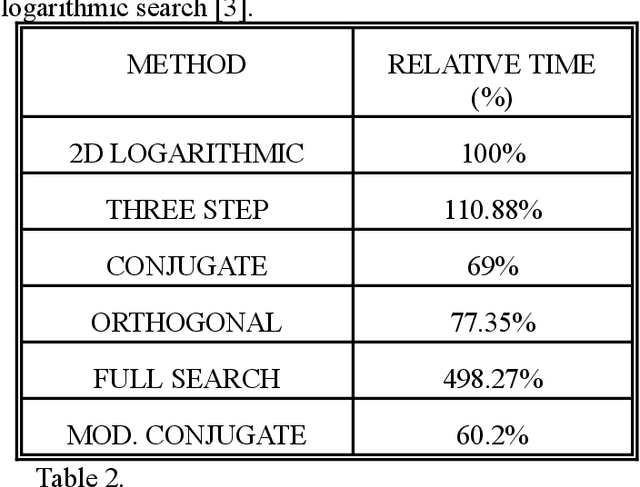
A comparative study of different block matching alternatives for motion estimation is presented. The study is focused on computational burden and objective measures on the accuracy of prediction. Together with existing algorithms several new variations have been tested. An interesting modification of the conjugate direction method previously related in literature is reported. This new algorithm shows a good trade-off between computational complexity and accuracy of motion vector estimation. Computational complexity is evaluated using a sequence of artificial images designed to incorporate a great variety of motion vectors. The performance of block matching methods has been measured in terms of the entropy in the error signal between the motion compensated and the original frames.
* 4 pages
Speaker recognition improvement using blind inversion of distortions
Feb 23, 2022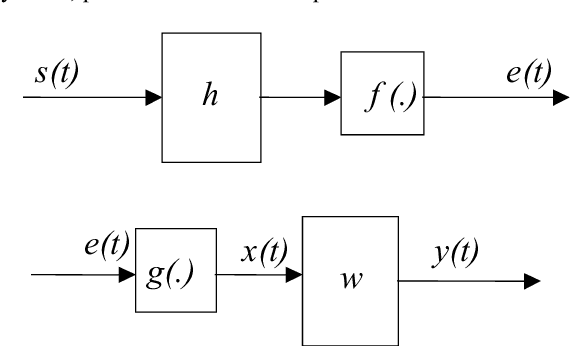
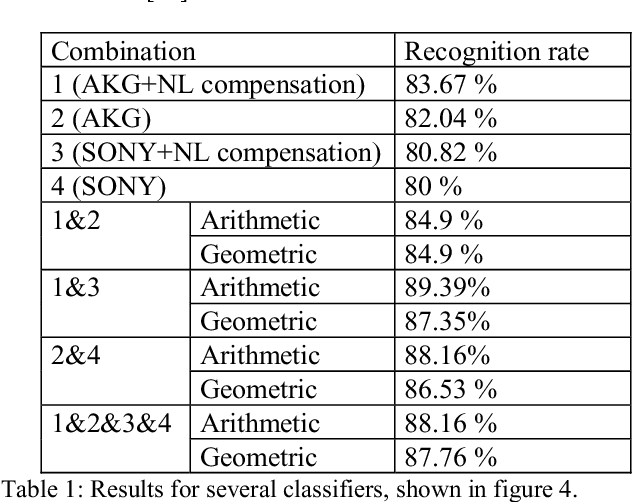
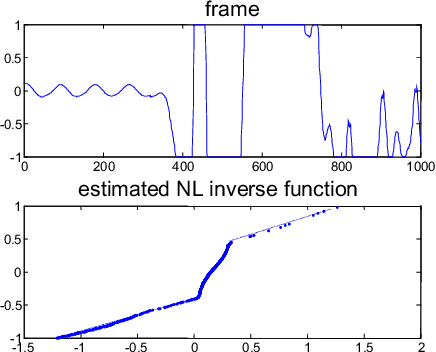
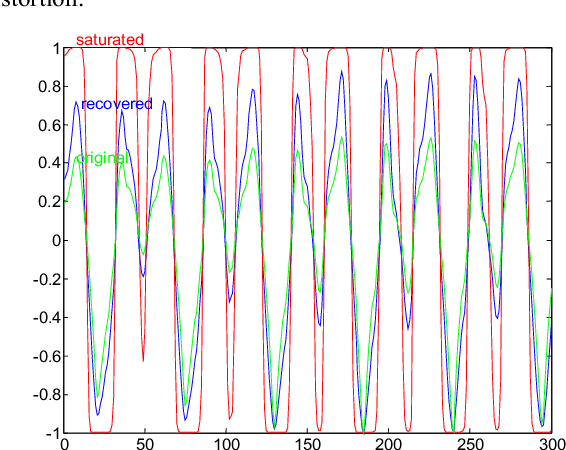
In this paper we propose the inversion of nonlinear distortions in order to improve the recognition rates of a speaker recognizer system. We study the effect of saturations on the test signals, trying to take into account real situations where the training material has been recorded in a controlled situation but the testing signals present some mismatch with the input signal level (saturations). The experimental results shows that a combination of data fusion with and without nonlinear distortion compensation can improve the recognition rates with saturated test sentences from 80% to 88.57%, while the results with clean speech (without saturation) is 87.76% for one microphone.
* 4 pages
A comparative study of in-air trajectories at short and long distances in online handwriting
Feb 23, 2022
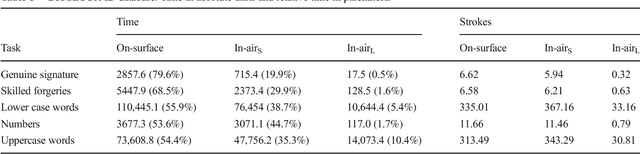
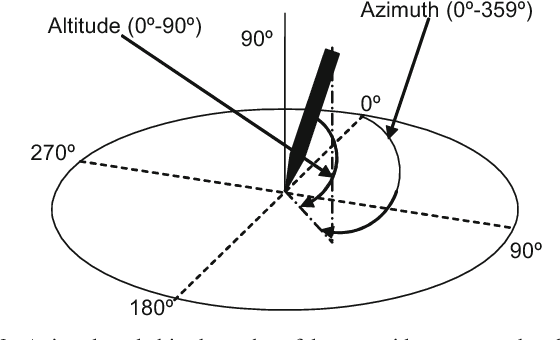
Introduction Existing literature about online handwriting analysis to support pathology diagnosis has taken advantage of in-air trajectories. A similar situation occurred in biometric security applications where the goal is to identify or verify an individual using his signature or handwriting. These studies do not consider the distance of the pen tip to the writing surface. This is due to the fact that current acquisition devices do not provide height formation. However, it is quite straightforward to differentiate movements at two different heights: a) short distance: height lower or equal to 1 cm above a surface of digitizer, the digitizer provides x and y coordinates. b) long distance: height exceeding 1 cm, the only information available is a time stamp that indicates the time that a specific stroke has spent at long distance. Although short distance has been used in several papers, long distances have been ignored and will be investigated in this paper. Methods In this paper, we will analyze a large set of databases (BIOSECURID, EMOTHAW, PaHaW, Oxygen-Therapy and SALT), which contain a total amount of 663 users and 17951 files. We have specifically studied: a) the percentage of time spent on-surface, in-air at short distance, and in-air at long distance for different user profiles (pathological and healthy users) and different tasks; b) The potential use of these signals to improve classification rates. Results and conclusions Our experimental results reveal that long-distance movements represent a very small portion of the total execution time (0.5 % in the case of signatures and 10.4% for uppercase words of BIOSECUR-ID, which is the largest database). In addition, significant differences have been found in the comparison of pathological versus control group for letter l in PaHaW database (p=0.0157) and crossed pentagons in SALT database (p=0.0122)
* 11 pages
On-line signature verification system with failure to enroll managing
Feb 23, 2022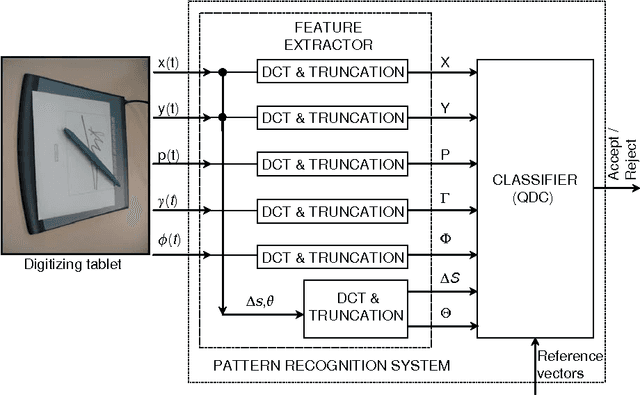
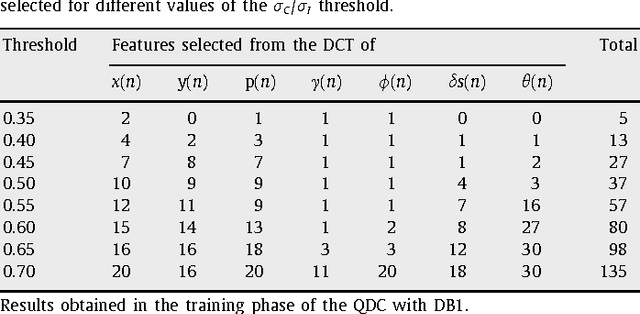

In this paper we simulate a real biometric verification system based on on-line signatures. For this purpose we have split the MCYT signature database in three subsets: one for classifier training, another for system adjustment and a third one for system testing simulating enrollment and verification. This context corresponds to a real operation, where a new user tries to enroll an existing system and must be automatically guided by the system in order to detect the failure to enroll situations. The main contribution of this work is the management of failure to enroll situations by means of a new proposal, called intelligent enrollment, which consists of consistency checking in order to automatically reject low quality samples. This strategy lets to enhance the verification errors up to 22% when leaving out 8% of the users. In this situation 8% of the people cannot be enrolled in the system and must be verified by other biometrics or by human abilities. These people are identified with intelligent enrollment and the situation can be thus managed. In addition we also propose a DCT-based feature extractor with threshold coding and discriminability criteria.
* 35 pages
EMOTHAW: A novel database for emotional state recognition from handwriting
Feb 23, 2022
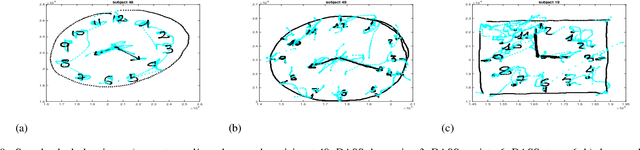


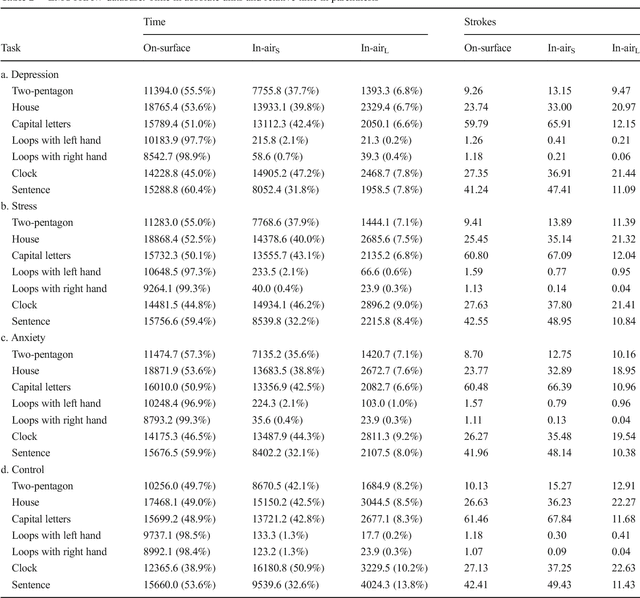
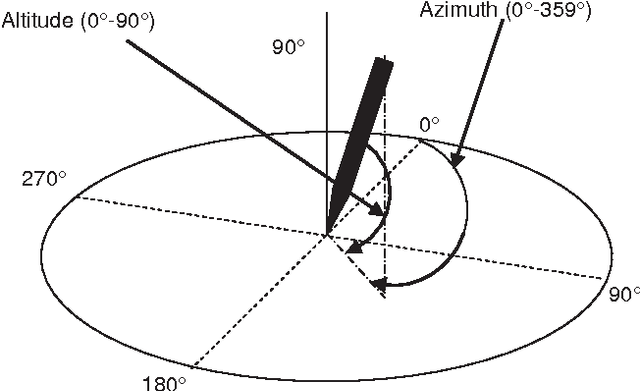
The detection of negative emotions through daily activities such as handwriting is useful for promoting well-being. The spread of human-machine interfaces such as tablets makes the collection of handwriting samples easier. In this context, we present a first publicly available handwriting database which relates emotional states to handwriting, that we call EMOTHAW. This database includes samples of 129 participants whose emotional states, namely anxiety, depression and stress, are assessed by the Depression Anxiety Stress Scales (DASS) questionnaire. Seven tasks are recorded through a digitizing tablet: pentagons and house drawing, words copied in handprint, circles and clock drawing, and one sentence copied in cursive writing. Records consist in pen positions, on-paper and in-air, time stamp, pressure, pen azimuth and altitude. We report our analysis on this database. From collected data, we first compute measurements related to timing and ductus. We compute separate measurements according to the position of the writing device: on paper or in-air. We analyse and classify this set of measurements (referred to as features) using a random forest approach. This latter is a machine learning method [2], based on an ensemble of decision trees, which includes a feature ranking process. We use this ranking process to identify the features which best reveal a targeted emotional state. We then build random forest classifiers associated to each emotional state. Our results, obtained from cross-validation experiments, show that the targeted emotional states can be identified with accuracies ranging from 60% to 71%.
* 31 pages
Thermal hand image segmentation for biometric recognition
Feb 23, 2022
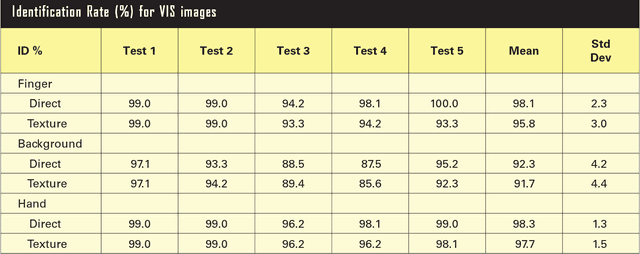
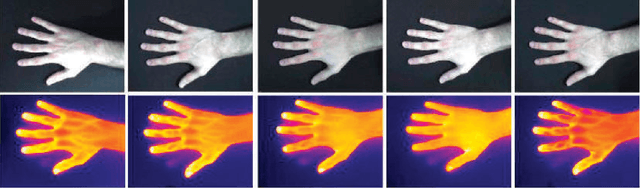

In this paper we present a method to identify people by means of thermal (TH) and visible (VIS) hand images acquired simultaneously with a TESTO 882-3 camera. In addition, we also present a new database specially acquired for this work. The real challenge when dealing with TH images is the cold finger areas, which can be confused with the acquisition surface. This problem is solved by taking advantage of the VIS information. We have performed different tests to show how TH and VIS images work in identification problems. Experimental results reveal that TH hand image is as suitable for biometric recognition systems as VIS hand images, and better results are obtained when combining this information. A Biometric Dispersion Matcher has been used as a feature vector dimensionality reduction technique as well as a classification task. Its selection criteria helps to reduce the length of the vectors used to perform identification up to a hundred measurements. Identification rates reach a maximum value of 98.3% under these conditions, when using a database of 104 people.
* 12 pages
Biometric security technology
Feb 23, 2022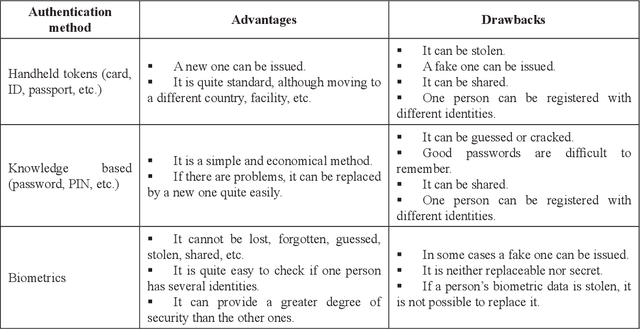
This paper presents an overview of the main topics related to biometric security technology, with the main purpose to provide a primer on this subject. Biometrics can offer greater security and convenience than traditional methods for people recognition. Even if we do not want to replace a classic method (password or handheld token) by a biometric one, for sure, we are potential users of these systems, which will even be mandatory for new passport models. For this reason, to be familiarized with the possibilities of biometric security technology is useful.
* 13 pages