 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrnstein-Uhlenbeck Adaptation as a Mechanism for Learning in Brains and Machines
Oct 17, 2024



Learning is a fundamental property of intelligent systems, observed across biological organisms and engineered systems. While modern intelligent systems typically rely on gradient descent for learning, the need for exact gradients and complex information flow makes its implementation in biological and neuromorphic systems challenging. This has motivated the exploration of alternative learning mechanisms that can operate locally and do not rely on exact gradients. In this work, we introduce a novel approach that leverages noise in the parameters of the system and global reinforcement signals. Using an Ornstein-Uhlenbeck process with adaptive dynamics, our method balances exploration and exploitation during learning, driven by deviations from error predictions, akin to reward prediction error. Operating in continuous time, Orstein-Uhlenbeck adaptation (OUA) is proposed as a general mechanism for learning dynamic, time-evolving environments. We validate our approach across diverse tasks, including supervised learning and reinforcement learning in feedforward and recurrent systems. Additionally, we demonstrate that it can perform meta-learning, adjusting hyper-parameters autonomously. Our results indicate that OUA provides a viable alternative to traditional gradient-based methods, with potential applications in neuromorphic computing. It also hints at a possible mechanism for noise-driven learning in the brain, where stochastic neurotransmitter release may guide synaptic adjustments.
Energy-Efficient Spiking Recurrent Neural Network for Gesture Recognition on Embedded GPUs
Aug 23, 2024Implementing AI algorithms on event-based embedded devices enables real-time processing of data, minimizes latency, and enhances power efficiency in edge computing. This research explores the deployment of a spiking recurrent neural network (SRNN) with liquid time constant neurons for gesture recognition. We focus on the energy efficiency and computational efficacy of NVIDIA Jetson Nano embedded GPU platforms. The embedded GPU showcases a 14-fold increase in power efficiency relative to a conventional GPU, making a compelling argument for its use in energy-constrained applications. The study's empirical findings also highlight that batch processing significantly boosts frame rates across various batch sizes while maintaining accuracy levels well above the baseline. These insights validate the SRNN with liquid time constant neurons as a robust model for interpreting temporal-spatial data in gesture recognition, striking a critical balance between processing speed and power frugality.
Discovering Dynamic Symbolic Policies with Genetic Programming
Jun 04, 2024Artificial intelligence (AI) techniques are increasingly being applied to solve control problems. However, control systems developed in AI are often black-box methods, in that it is not clear how and why they generate their outputs. A lack of transparency can be problematic for control tasks in particular, because it complicates the identification of biases or errors, which in turn negatively influences the user's confidence in the system. To improve the interpretability and transparency in control systems, the black-box structure can be replaced with white-box symbolic policies described by mathematical expressions. Genetic programming offers a gradient-free method to optimise the structure of non-differentiable mathematical expressions. In this paper, we show that genetic programming can be used to discover symbolic control systems. This is achieved by learning a symbolic representation of a function that transforms observations into control signals. We consider both systems that implement static control policies without memory and systems that implement dynamic memory-based control policies. In case of the latter, the discovered function becomes the state equation of a differential equation, which allows for evidence integration. Our results show that symbolic policies are discovered that perform comparably with black-box policies on a variety of control tasks. Furthermore, the additional value of the memory capacity in the dynamic policies is demonstrated on experiments where static policies fall short. Overall, we demonstrate that white-box symbolic policies can be optimised with genetic programming, while offering interpretability and transparency that lacks in black-box models.
Subspace Node Pruning
May 26, 2024A significant increase in the commercial use of deep neural network models increases the need for efficient AI. Node pruning is the art of removing computational units such as neurons, filters, attention heads, or even entire layers while keeping network performance at a maximum. This can significantly reduce the inference time of a deep network and thus enhance its efficiency. Few of the previous works have exploited the ability to recover performance by reorganizing network parameters while pruning. In this work, we propose to create a subspace from unit activations which enables node pruning while recovering maximum accuracy. We identify that for effective node pruning, a subspace can be created using a triangular transformation matrix, which we show to be equivalent to Gram-Schmidt orthogonalization, which automates this procedure. We further improve this method by reorganizing the network prior to subspace formation. Finally, we leverage the orthogonal subspaces to identify layer-wise pruning ratios appropriate to retain a significant amount of the layer-wise information. We show that this measure outperforms existing pruning methods on VGG networks. We further show that our method can be extended to other network architectures such as residual networks.
Perturbation-based Learning for Recurrent Neural Networks
May 14, 2024



Recurrent neural networks (RNNs) hold immense potential for computations due to their Turing completeness and sequential processing capabilities, yet existing methods for their training encounter efficiency challenges. Backpropagation through time (BPTT), the prevailing method, extends the backpropagation (BP) algorithm by unrolling the RNN over time. However, this approach suffers from significant drawbacks, including the need to interleave forward and backward phases and store exact gradient information. Furthermore, BPTT has been shown to struggle with propagating gradient information for long sequences, leading to vanishing gradients. An alternative strategy to using gradient-based methods like BPTT involves stochastically approximating gradients through perturbation-based methods. This learning approach is exceptionally simple, necessitating only forward passes in the network and a global reinforcement signal as feedback. Despite its simplicity, the random nature of its updates typically leads to inefficient optimization, limiting its effectiveness in training neural networks. In this study, we present a new approach to perturbation-based learning in RNNs whose performance is competitive with BPTT, while maintaining the inherent advantages over gradient-based learning. To this end, we extend the recently introduced activity-based node perturbation (ANP) method to operate in the time domain, leading to more efficient learning and generalization. Subsequently, we conduct a range of experiments to validate our approach. Our results show similar performance, convergence time and scalability when compared to BPTT, strongly outperforming standard node perturbation and weight perturbation methods. These findings suggest that perturbation-based learning methods offer a versatile alternative to gradient-based methods for training RNNs.
Efficient Deep Learning with Decorrelated Backpropagation
May 03, 2024



The backpropagation algorithm remains the dominant and most successful method for training deep neural networks (DNNs). At the same time, training DNNs at scale comes at a significant computational cost and therefore a high carbon footprint. Converging evidence suggests that input decorrelation may speed up deep learning. However, to date, this has not yet translated into substantial improvements in training efficiency in large-scale DNNs. This is mainly caused by the challenge of enforcing fast and stable network-wide decorrelation. Here, we show for the first time that much more efficient training of very deep neural networks using decorrelated backpropagation is feasible. To achieve this goal we made use of a novel algorithm which induces network-wide input decorrelation using minimal computational overhead. By combining this algorithm with careful optimizations, we obtain a more than two-fold speed-up and higher test accuracy compared to backpropagation when training a 18-layer deep residual network. This demonstrates that decorrelation provides exciting prospects for efficient deep learning at scale.
Effective Learning with Node Perturbation in Deep Neural Networks
Oct 02, 2023



Backpropagation (BP) is the dominant and most successful method for training parameters of deep neural network models. However, BP relies on two computationally distinct phases, does not provide a satisfactory explanation of biological learning, and can be challenging to apply for training of networks with discontinuities or noisy node dynamics. By comparison, node perturbation (NP) proposes learning by the injection of noise into the network activations, and subsequent measurement of the induced loss change. NP relies on two forward (inference) passes, does not make use of network derivatives, and has been proposed as a model for learning in biological systems. However, standard NP is highly data inefficient and unstable due to its unguided, noise-based, activity search. In this work, we investigate different formulations of NP and relate it to the concept of directional derivatives as well as combining it with a decorrelating mechanism for layer-wise inputs. We find that a closer alignment with directional derivatives, and induction of decorrelation of inputs at every layer significantly enhances performance of NP learning making it competitive with BP.
Efficient Deep Reinforcement Learning with Predictive Processing Proximal Policy Optimization
Nov 11, 2022



Advances in reinforcement learning (RL) often rely on massive compute resources and remain notoriously sample inefficient. In contrast, the human brain is able to efficiently learn effective control strategies using limited resources. This raises the question whether insights from neuroscience can be used to improve current RL methods. Predictive processing is a popular theoretical framework which maintains that the human brain is actively seeking to minimize surprise. We show that recurrent neural networks which predict their own sensory states can be leveraged to minimise surprise, yielding substantial gains in cumulative reward. Specifically, we present the Predictive Processing Proximal Policy Optimization (P4O) agent; an actor-critic reinforcement learning agent that applies predictive processing to a recurrent variant of the PPO algorithm by integrating a world model in its hidden state. P4O significantly outperforms a baseline recurrent variant of the PPO algorithm on multiple Atari games using a single GPU. It also outperforms other state-of-the-art agents given the same wall-clock time and exceeds human gamer performance on multiple games including Seaquest, which is a particularly challenging environment in the Atari domain. Altogether, our work underscores how insights from the field of neuroscience may support the development of more capable and efficient artificial agents.
Learning Policies for Continuous Control via Transition Models
Sep 16, 2022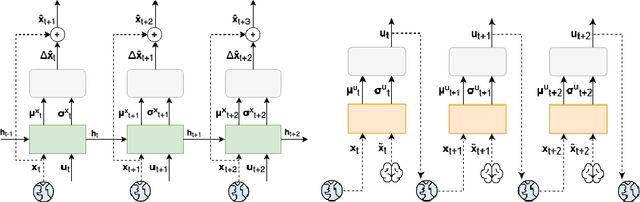
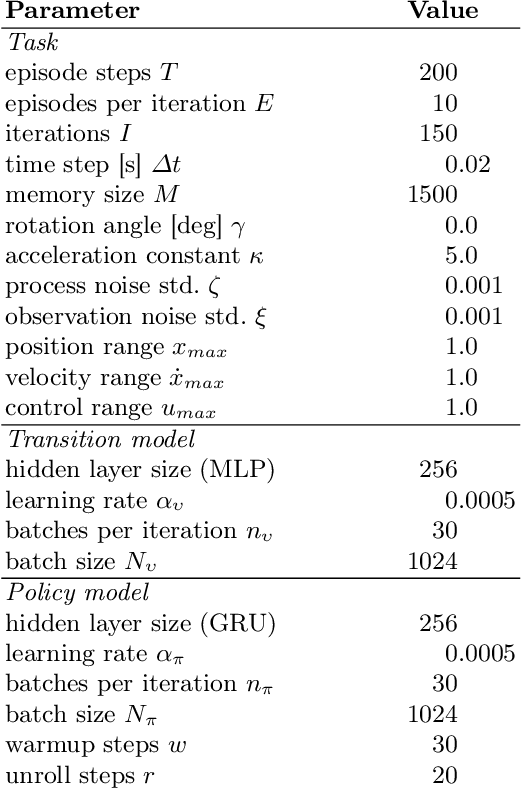
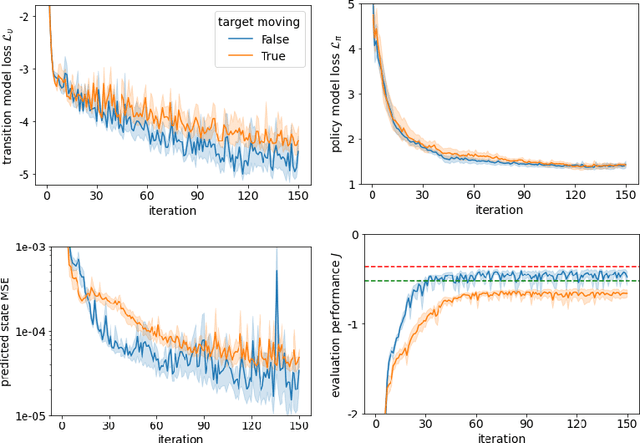
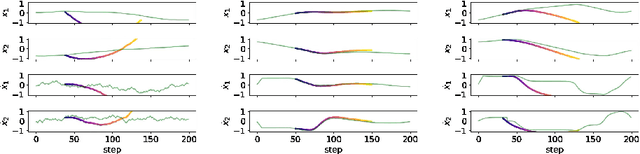
It is doubtful that animals have perfect inverse models of their limbs (e.g., what muscle contraction must be applied to every joint to reach a particular location in space). However, in robot control, moving an arm's end-effector to a target position or along a target trajectory requires accurate forward and inverse models. Here we show that by learning the transition (forward) model from interaction, we can use it to drive the learning of an amortized policy. Hence, we revisit policy optimization in relation to the deep active inference framework and describe a modular neural network architecture that simultaneously learns the system dynamics from prediction errors and the stochastic policy that generates suitable continuous control commands to reach a desired reference position. We evaluated the model by comparing it against the baseline of a linear quadratic regulator, and conclude with additional steps to take toward human-like motor control.
Constrained Parameter Inference as a Principle for Learning
Apr 01, 2022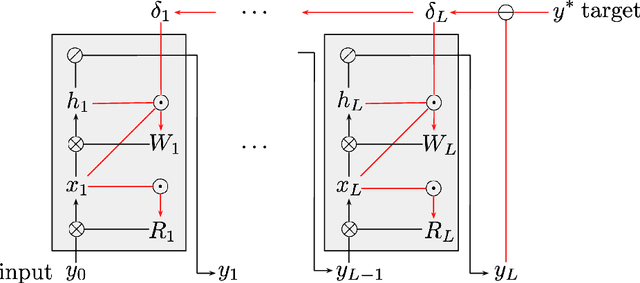
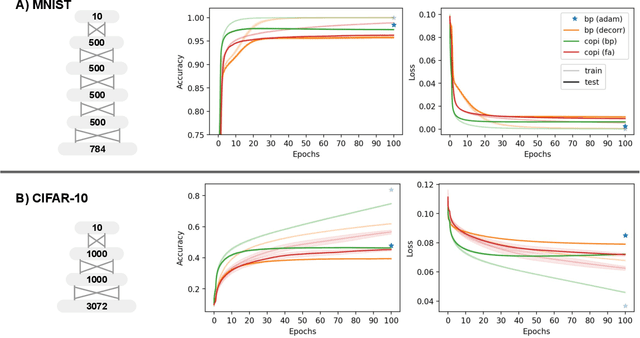
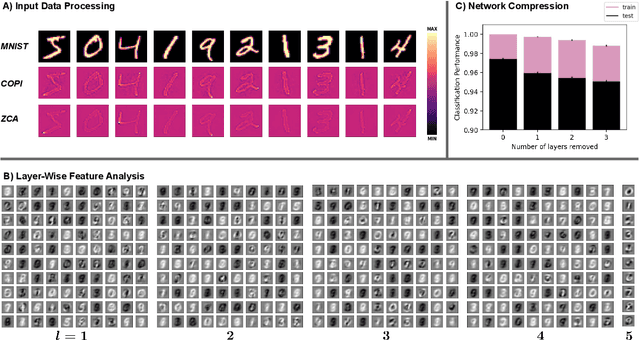
Learning in biological and artificial neural networks is often framed as a problem in which targeted error signals guide parameter updating for more optimal network behaviour. Backpropagation of error (BP) is an example of such an approach and has proven to be a highly successful application of stochastic gradient descent to deep neural networks. However, BP relies on the global transmission of gradient information and has therefore been criticised for its biological implausibility. We propose constrained parameter inference (COPI) as a new principle for learning. COPI allows for the estimation of network parameters under the constraints of decorrelated neural inputs and top-down perturbations of neural states. We show that COPI not only is more biologically plausible but also provides distinct advantages for fast learning, compared with the backpropagation algorithm.