 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaithilee Kunda
Creative Captioning: An AI Grand Challenge Based on the Dixit Board Game
Sep 30, 2020

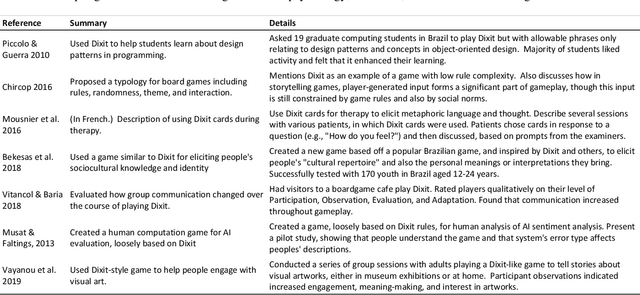

We propose a new class of "grand challenge" AI problems that we call creative captioning---generating clever, interesting, or abstract captions for images, as well as understanding such captions. Creative captioning draws on core AI research areas of vision, natural language processing, narrative reasoning, and social reasoning, and across all these areas, it requires sophisticated uses of common sense and cultural knowledge. In this paper, we analyze several specific research problems that fall under creative captioning, using the popular board game Dixit as both inspiration and proposed testing ground. We expect that Dixit could serve as an engaging and motivating benchmark for creative captioning across numerous AI research communities for the coming 1-2 decades.
Variable-Viewpoint Representations for 3D Object Recognition
Feb 08, 2020
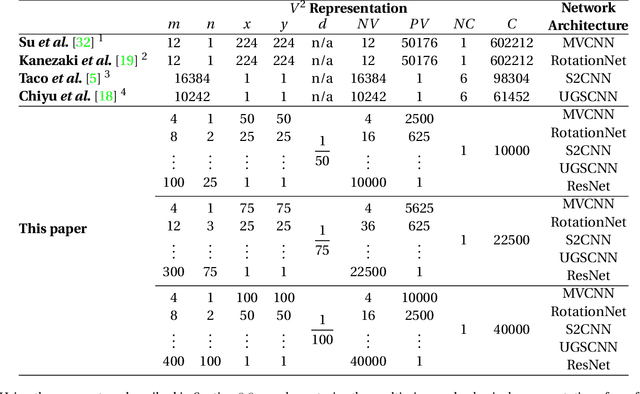

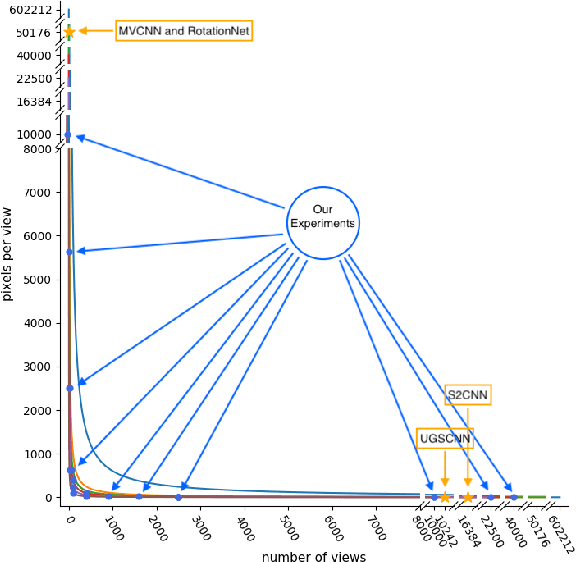
For the problem of 3D object recognition, researchers using deep learning methods have developed several very different input representations, including "multi-view" snapshots taken from discrete viewpoints around an object, as well as "spherical" representations consisting of a dense map of essentially ray-traced samples of the object from all directions. These representations offer trade-offs in terms of what object information is captured and to what degree of detail it is captured, but it is not clear how to measure these information trade-offs since the two types of representations are so different. We demonstrate that both types of representations in fact exist at two extremes of a common representational continuum, essentially choosing to prioritize either the number of views of an object or the pixels (i.e., field of view) allotted per view. We identify interesting intermediate representations that lie at points in between these two extremes, and we show, through systematic empirical experiments, how accuracy varies along this continuum as a function of input information as well as the particular deep learning architecture that is used.
Learning Spatially Structured Image Transformations Using Planar Neural Networks
Dec 03, 2019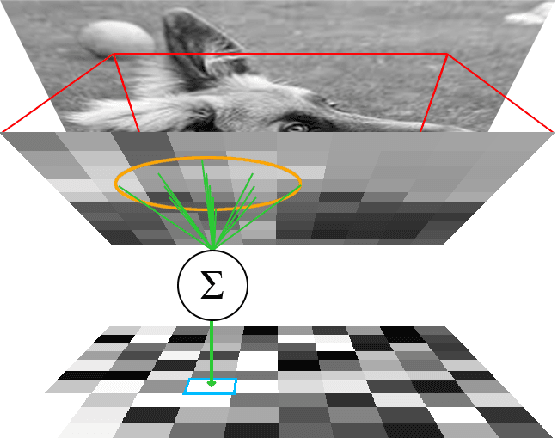

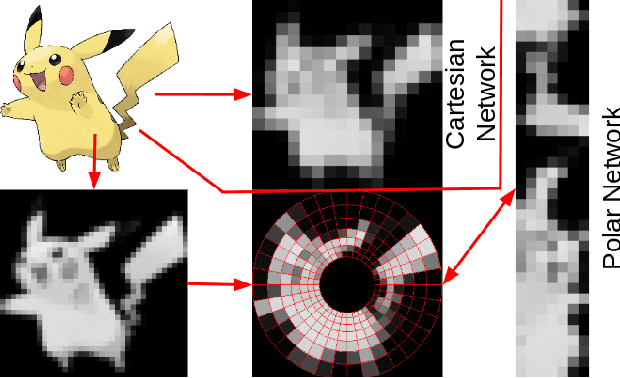
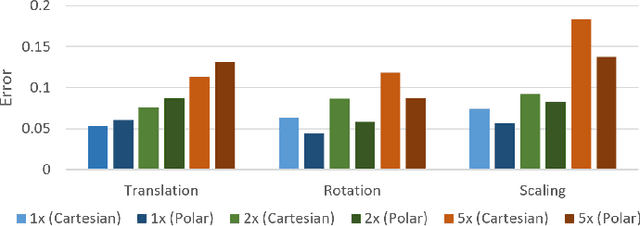
Learning image transformations is essential to the idea of mental simulation as a method of cognitive inference. We take a connectionist modeling approach, using planar neural networks to learn fundamental imagery transformations, like translation, rotation, and scaling, from perceptual experiences in the form of image sequences. We investigate how variations in network topology, training data, and image shape, among other factors, affect the efficiency and effectiveness of learning visual imagery transformations, including effectiveness of transfer to operating on new types of data.
Modeling Gestalt Visual Reasoning on the Raven's Progressive Matrices Intelligence Test Using Generative Image Inpainting Techniques
Nov 26, 2019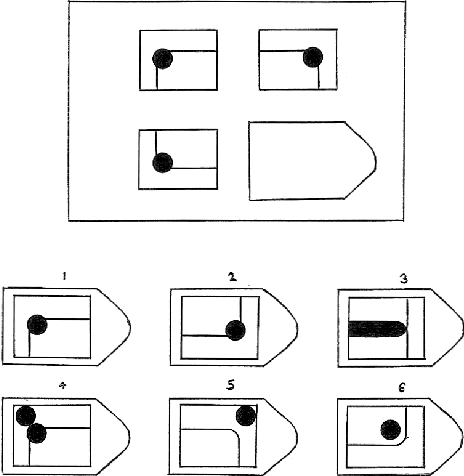


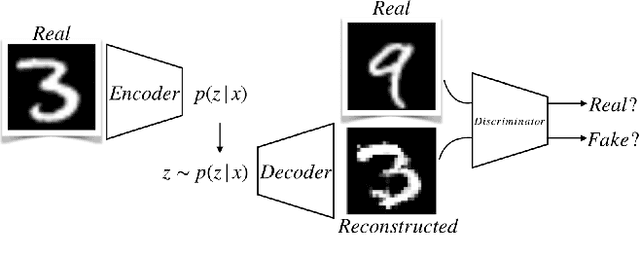
Psychologists recognize Raven's Progressive Matrices as a very effective test of general human intelligence. While many computational models have been developed by the AI community to investigate different forms of top-down, deliberative reasoning on the test, there has been less research on bottom-up perceptual processes, like Gestalt image completion, that are also critical in human test performance. In this work, we investigate how Gestalt visual reasoning on the Raven's test can be modeled using generative image inpainting techniques from computer vision. We demonstrate that a self-supervised inpainting model trained only on photorealistic images of objects achieves a score of 27/36 on the Colored Progressive Matrices, which corresponds to average performance for nine-year-old children. We also show that models trained on other datasets (faces, places, and textures) do not perform as well. Our results illustrate how learning visual regularities in real-world images can translate into successful reasoning about artificial test stimuli. On the flip side, our results also highlight the limitations of such transfer, which may explain why intelligence tests like the Raven's are often sensitive to people's individual sociocultural backgrounds.
Quantifying Human Behavior on the Block Design Test Through Automated Multi-Level Analysis of Overhead Video
Nov 19, 2018
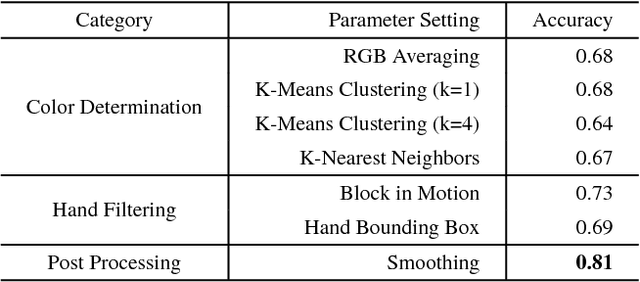
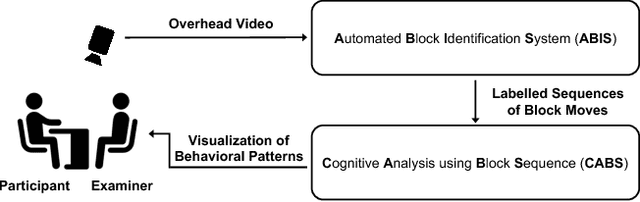
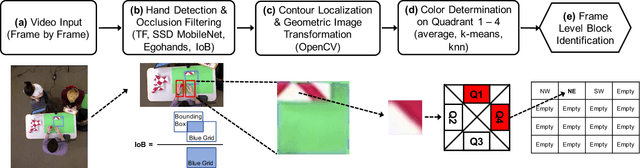
The block design test is a standardized, widely used neuropsychological assessment of visuospatial reasoning that involves a person recreating a series of given designs out of a set of colored blocks. In current testing procedures, an expert neuropsychologist observes a person's accuracy and completion time as well as overall impressions of the person's problem-solving procedures, errors, etc., thus obtaining a holistic though subjective and often qualitative view of the person's cognitive processes. We propose a new framework that combines room sensors and AI techniques to augment the information available to neuropsychologists from block design and similar tabletop assessments. In particular, a ceiling-mounted camera captures an overhead view of the table surface. From this video, we demonstrate how automated classification using machine learning can produce a frame-level description of the state of the block task and the person's actions over the course of each test problem. We also show how a sequence-comparison algorithm can classify one individual's problem-solving strategy relative to a database of simulated strategies, and how these quantitative results can be visualized for use by neuropsychologists.
Seeing Neural Networks Through a Box of Toys: The Toybox Dataset of Visual Object Transformations
Jul 31, 2018


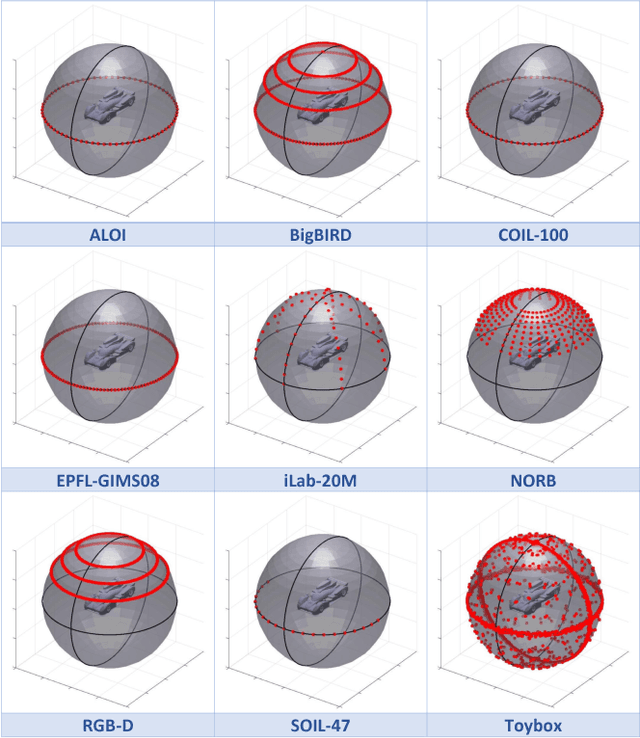
Deep convolutional neural networks (CNNs) have enjoyed tremendous success in computer vision in the past several years, particularly for visual object recognition.However, how CNNs work remains poorly understood, and the training of deep CNNs is still considered more art than science. To better characterize deep CNNs and the training process, we introduce a new video dataset called Toybox. Images in Toybox come from first-person, wearable camera recordings of common household objects and toys being manually manipulated to undergo structured transformations like rotations and translations. We also present results from initial experiments using deep CNNs that begin to examine how different distributions of training data can affect visual object recognition performance, and how visual object concepts are represented within a trained network.