 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Not Simply Translate? A First Swedish Evaluation Benchmark for Semantic Similarity
Sep 07, 2020
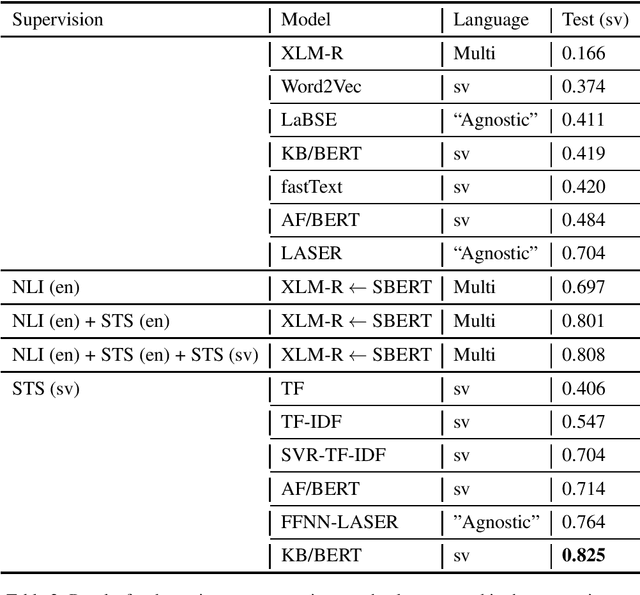
This paper presents the first Swedish evaluation benchmark for textual semantic similarity. The benchmark is compiled by simply running the English STS-B dataset through the Google machine translation API. This paper discusses potential problems with using such a simple approach to compile a Swedish evaluation benchmark, including translation errors, vocabulary variation, and productive compounding. Despite some obvious problems with the resulting dataset, we use the benchmark to compare the majority of the currently existing Swedish text representations, demonstrating that native models outperform multilingual ones, and that simple bag of words performs remarkably well.
Measuring Issue Ownership using Word Embeddings
Oct 31, 2018
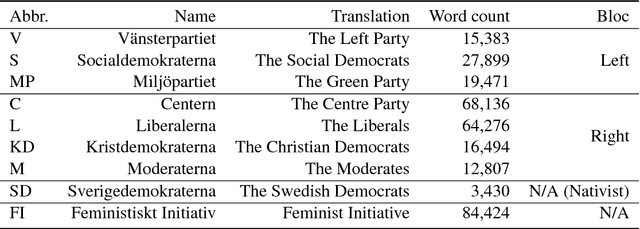
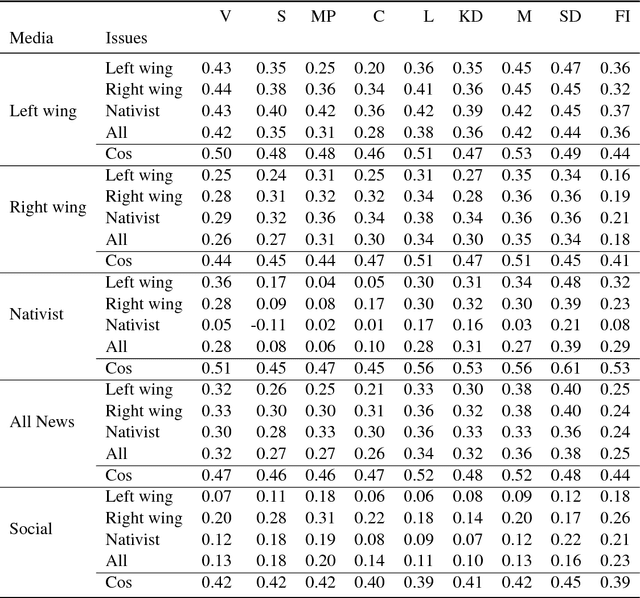
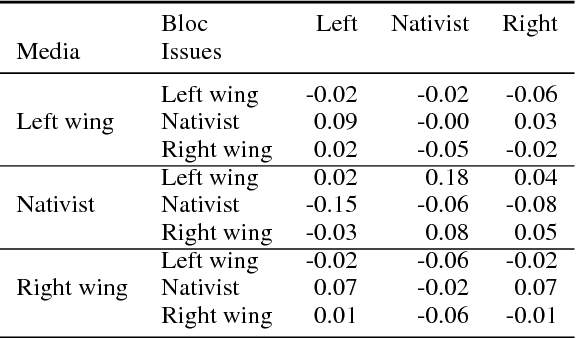
Sentiment and topic analysis are common methods used for social media monitoring. Essentially, these methods answers questions such as, "what is being talked about, regarding X", and "what do people feel, regarding X". In this paper, we investigate another venue for social media monitoring, namely issue ownership and agenda setting, which are concepts from political science that have been used to explain voter choice and electoral outcomes. We argue that issue alignment and agenda setting can be seen as a kind of semantic source similarity of the kind "how similar is source A to issue owner P, when talking about issue X", and as such can be measured using word/document embedding techniques. We present work in progress towards measuring that kind of conditioned similarity, and introduce a new notion of similarity for predictive embeddings. We then test this method by measuring the similarity between politically aligned media and political parties, conditioned on bloc-specific issues.
R-grams: Unsupervised Learning of Semantic Units in Natural Language
Aug 14, 2018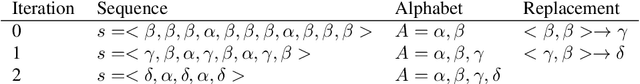
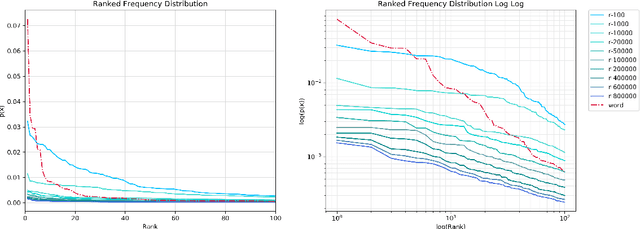

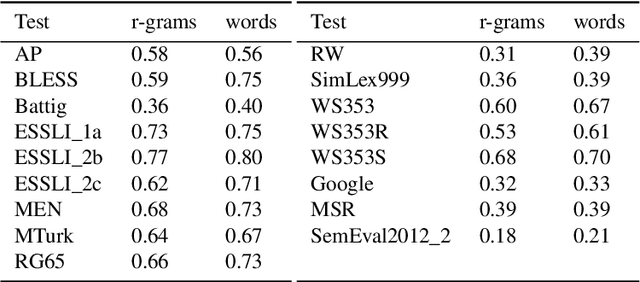
This paper introduces a novel type of data-driven segmented unit that we call r-grams. We illustrate one algorithm for calculating r-grams, and discuss its properties and impact on the frequency distribution of text representations. The proposed approach is evaluated by demonstrating its viability in embedding techniques, both in monolingual and multilingual test settings. We also provide a number of qualitative examples of the proposed methodology, demonstrating its viability as a language-invariant segmentation procedure.
Monitoring Targeted Hate in Online Environments
Mar 13, 2018
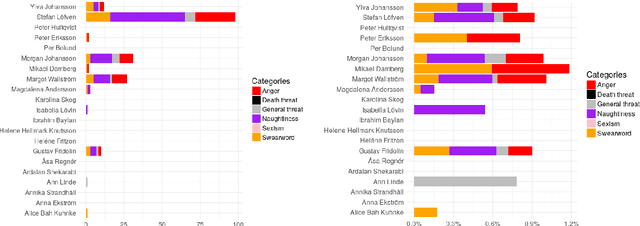

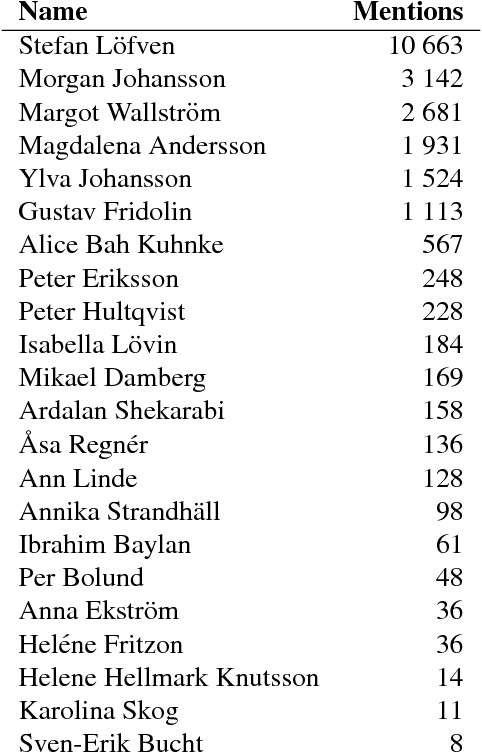
Hateful comments, swearwords and sometimes even death threats are becoming a reality for many people today in online environments. This is especially true for journalists, politicians, artists, and other public figures. This paper describes how hate directed towards individuals can be measured in online environments using a simple dictionary-based approach. We present a case study on Swedish politicians, and use examples from this study to discuss shortcomings of the proposed dictionary-based approach. We also outline possibilities for potential refinements of the proposed approach.
Distributional Term Set Expansion
Feb 14, 2018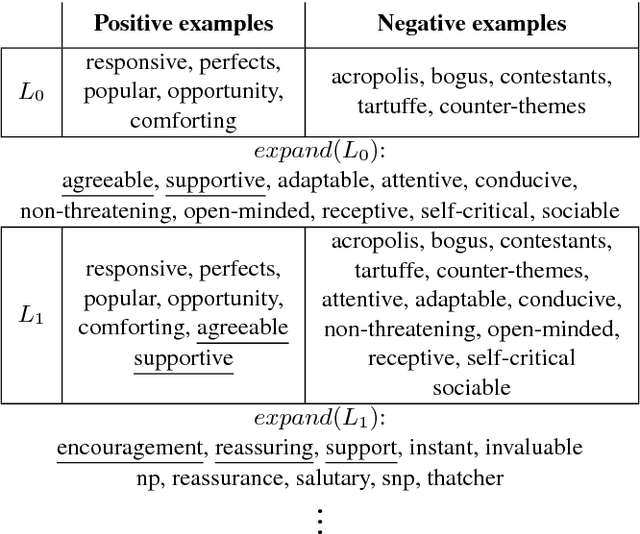
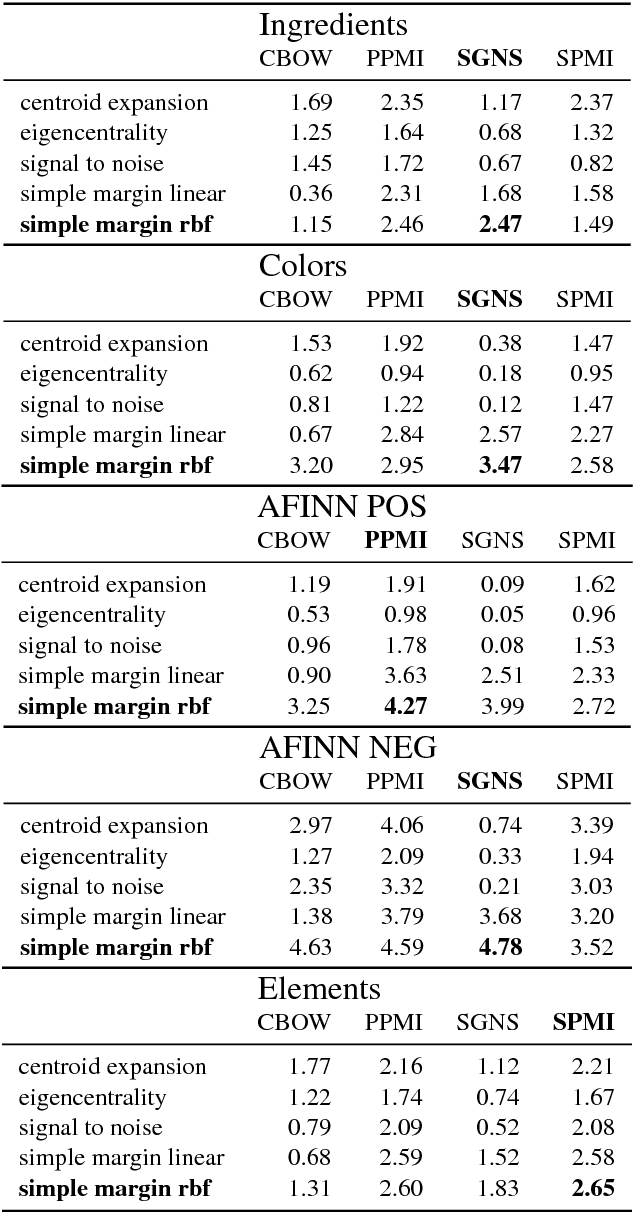

This paper is a short empirical study of the performance of centrality and classification based iterative term set expansion methods for distributional semantic models. Iterative term set expansion is an interactive process using distributional semantics models where a user labels terms as belonging to some sought after term set, and a system uses this labeling to supply the user with new, candidate, terms to label, trying to maximize the number of positive examples found. While centrality based methods have a long history in term set expansion, we compare them to classification methods based on the the Simple Margin method, an Active Learning approach to classification using Support Vector Machines. Examining the performance of various centrality and classification based methods for a variety of distributional models over five different term sets, we can show that active learning based methods consistently outperform centrality based methods.
The Effects of Data Size and Frequency Range on Distributional Semantic Models
Sep 27, 2016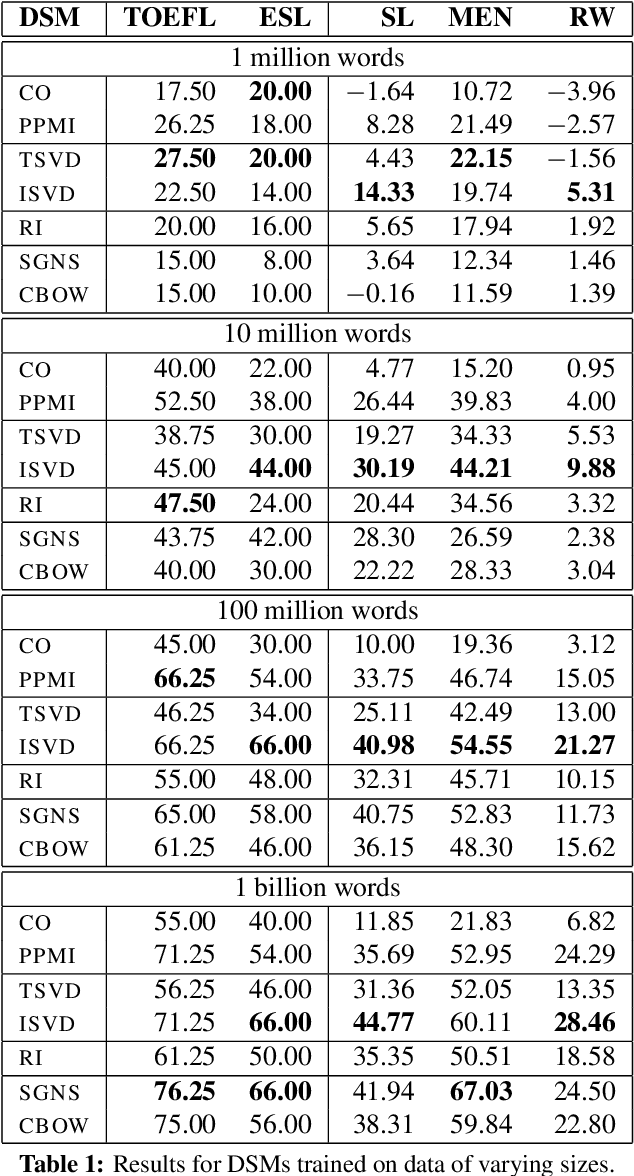
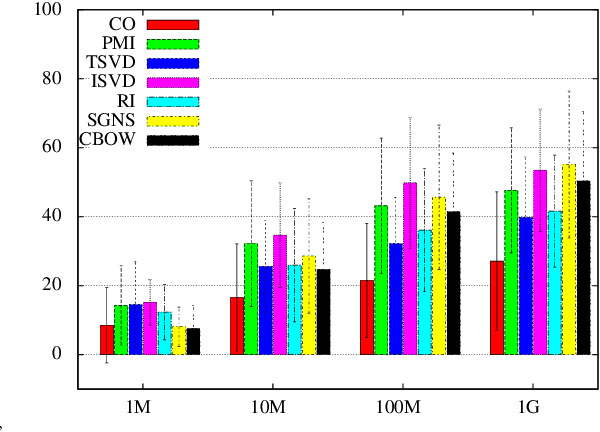

This paper investigates the effects of data size and frequency range on distributional semantic models. We compare the performance of a number of representative models for several test settings over data of varying sizes, and over test items of various frequency. Our results show that neural network-based models underperform when the data is small, and that the most reliable model over data of varying sizes and frequency ranges is the inverted factorized model.
Navigating the Semantic Horizon using Relative Neighborhood Graphs
Jan 12, 2015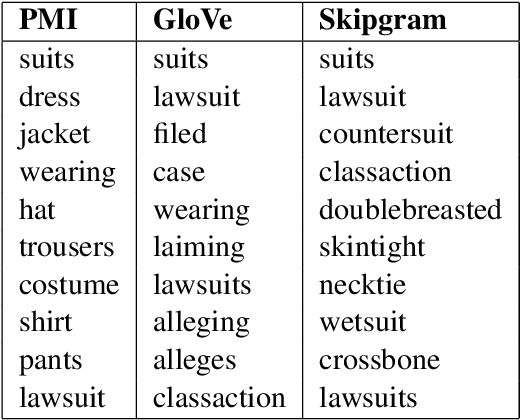
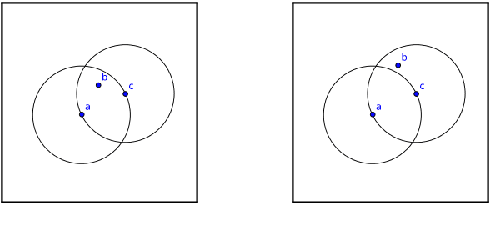
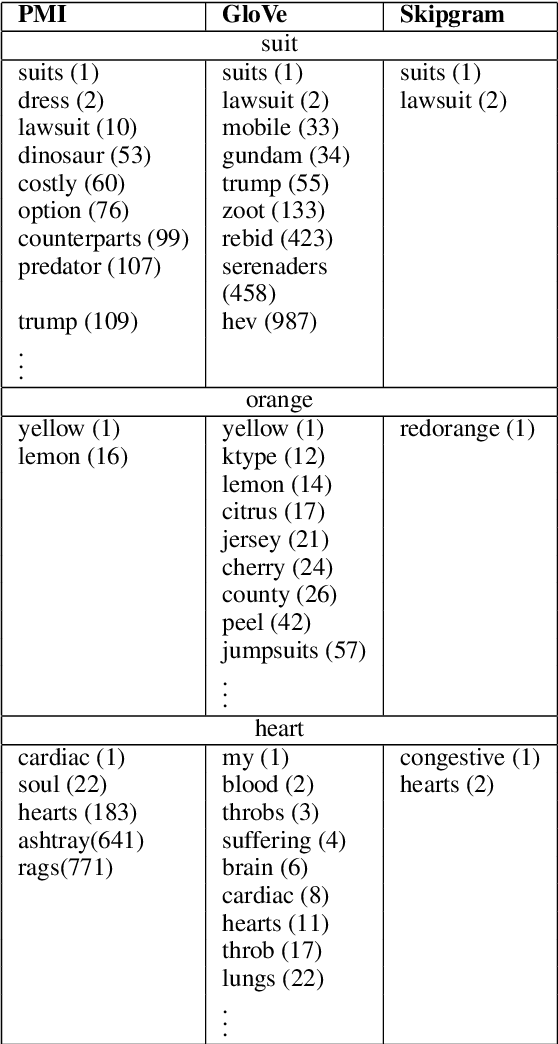

This paper is concerned with nearest neighbor search in distributional semantic models. A normal nearest neighbor search only returns a ranked list of neighbors, with no information about the structure or topology of the local neighborhood. This is a potentially serious shortcoming of the mode of querying a distributional semantic model, since a ranked list of neighbors may conflate several different senses. We argue that the topology of neighborhoods in semantic space provides important information about the different senses of terms, and that such topological structures can be used for word-sense induction. We also argue that the topology of the neighborhoods in semantic space can be used to determine the semantic horizon of a point, which we define as the set of neighbors that have a direct connection to the point. We introduce relative neighborhood graphs as method to uncover the topological properties of neighborhoods in semantic models. We also provide examples of relative neighborhood graphs for three well-known semantic models; the PMI model, the GloVe model, and the skipgram model.
Incremental dimension reduction of tensors with random index
Mar 18, 2011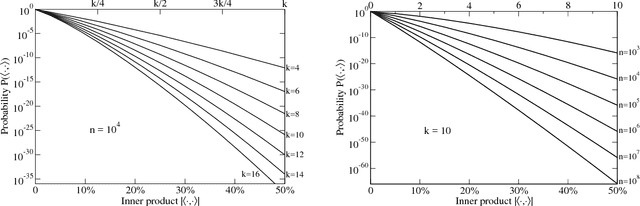
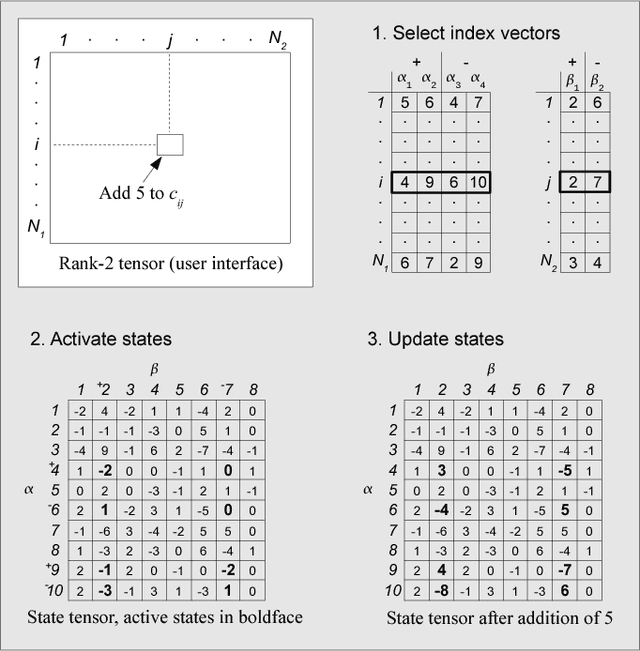
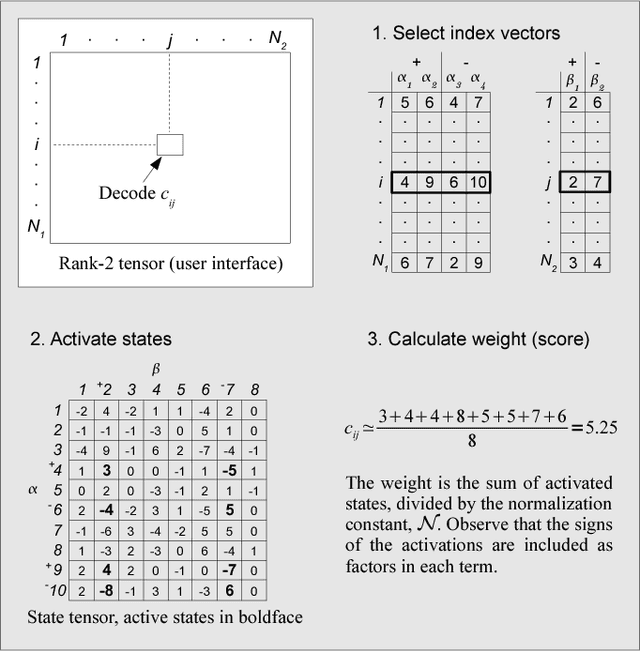
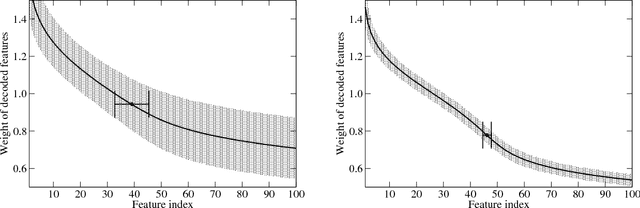
We present an incremental, scalable and efficient dimension reduction technique for tensors that is based on sparse random linear coding. Data is stored in a compactified representation with fixed size, which makes memory requirements low and predictable. Component encoding and decoding are performed on-line without computationally expensive re-analysis of the data set. The range of tensor indices can be extended dynamically without modifying the component representation. This idea originates from a mathematical model of semantic memory and a method known as random indexing in natural language processing. We generalize the random-indexing algorithm to tensors and present signal-to-noise-ratio simulations for representations of vectors and matrices. We present also a mathematical analysis of the approximate orthogonality of high-dimensional ternary vectors, which is a property that underpins this and other similar random-coding approaches to dimension reduction. To further demonstrate the properties of random indexing we present results of a synonym identification task. The method presented here has some similarities with random projection and Tucker decomposition, but it performs well at high dimensionality only (n>10^3). Random indexing is useful for a range of complex practical problems, e.g., in natural language processing, data mining, pattern recognition, event detection, graph searching and search engines. Prototype software is provided. It supports encoding and decoding of tensors of order >= 1 in a unified framework, i.e., vectors, matrices and higher order tensors.
* 36 pages, 9 figures