 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining PRNU and noiseprint for robust and efficient device source identification
Jan 17, 2020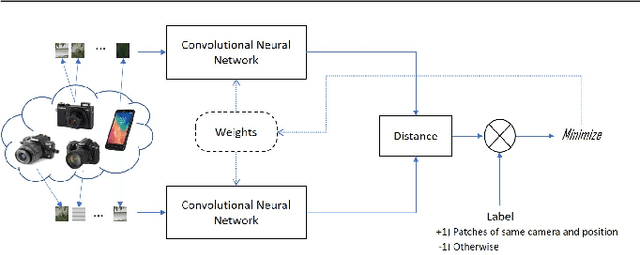
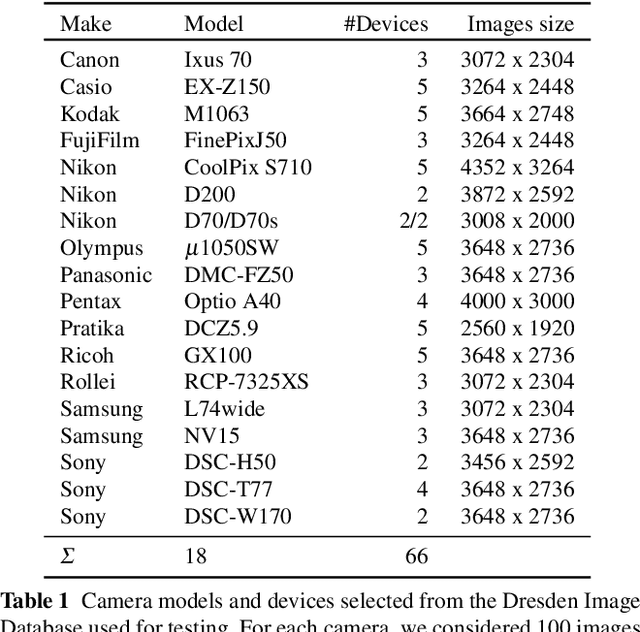

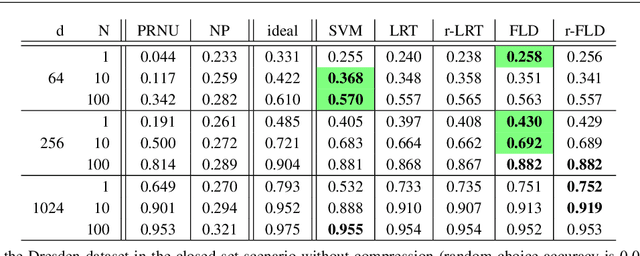
PRNU-based image processing is a key asset in digital multimedia forensics. It allows for reliable device identification and effective detection and localization of image forgeries, in very general conditions. However, performance impairs significantly in challenging conditions involving low quality and quantity of data. These include working on compressed and cropped images, or estimating the camera PRNU pattern based on only a few images. To boost the performance of PRNU-based analyses in such conditions we propose to leverage the image noiseprint, a recently proposed camera-model fingerprint that has proved effective for several forensic tasks. Numerical experiments on datasets widely used for source identification prove that the proposed method ensures a significant performance improvement in a wide range of challenging situations.
SpoC: Spoofing Camera Fingerprints
Nov 27, 2019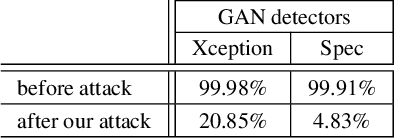
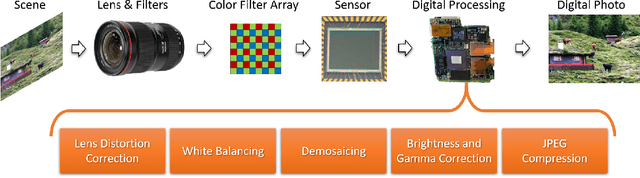
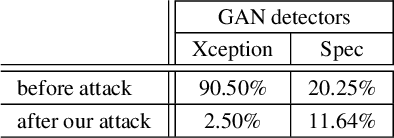
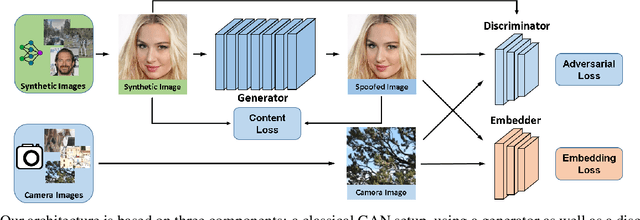
Thanks to the fast progress in synthetic media generation, creating realistic false images has become very easy. Such images can be used to wrap rich fake news with enhanced credibility, spawning a new wave of high-impact, high-risk misinformation campaigns. Therefore, there is a fast-growing interest in reliable detectors of manipulated media. The most powerful detectors, to date, rely on the subtle traces left by any device on all images acquired by it. In particular, due to proprietary in-camera processes, like demosaicing or compression, each camera model leaves trademark traces that can be exploited for forensic analyses. The absence or distortion of such traces in the target image is a strong hint of manipulation. In this paper, we challenge such detectors to gain better insight into their vulnerabilities. This is an important study in order to build better forgery detectors able to face malicious attacks. Our proposal consists of a GAN-based approach that injects camera traces into synthetic images. Given a GANgenerated image, we insert the traces of a specific camera model into it and deceive state-of-the-art detectors into believing the image was acquired by that model. Likewise, we deceive independent detectors of synthetic GAN images into believing the image is real. Experiments prove the effectiveness of the proposed method in a wide array of conditions. Moreover, no prior information on the attacked detectors is needed, but only sample images from the target camera.
Incremental learning for the detection and classification of GAN-generated images
Oct 06, 2019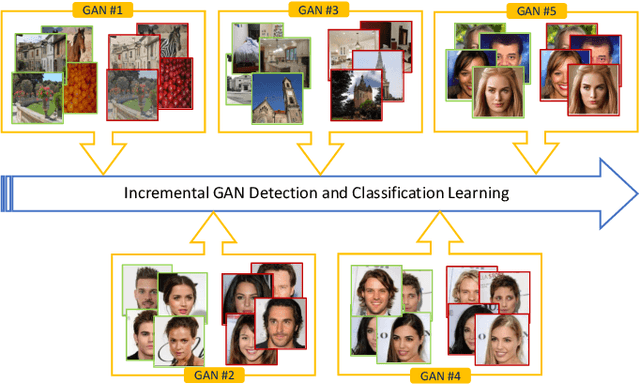
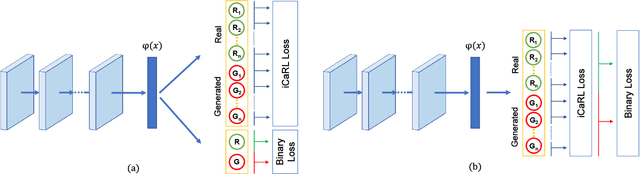

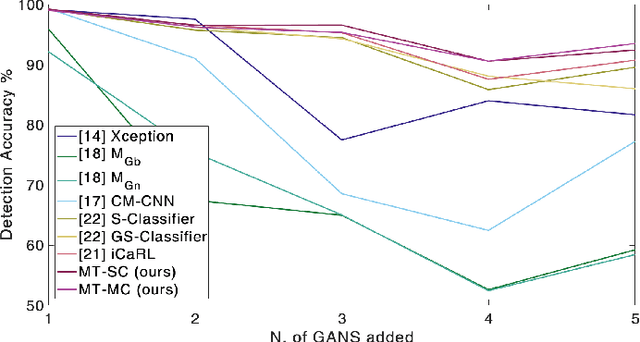
Current developments in computer vision and deep learning allow to automatically generate hyper-realistic images, hardly distinguishable from real ones. In particular, human face generation achieved a stunning level of realism, opening new opportunities for the creative industry but, at the same time, new scary scenarios where such content can be maliciously misused. Therefore, it is essential to develop innovative methodologies to automatically tell apart real from computer generated multimedia, possibly able to follow the evolution and continuous improvement of data in terms of quality and realism. In the last few years, several deep learning-based solutions have been proposed for this problem, mostly based on Convolutional Neural Networks (CNNs). Although results are good in controlled conditions, it is not clear how such proposals can adapt to real-world scenarios, where learning needs to continuously evolve as new types of generated data appear. In this work, we tackle this problem by proposing an approach based on incremental learning for the detection and classification of GAN-generated images. Experiments on a dataset comprising images generated by several GAN-based architectures show that the proposed method is able to correctly perform discrimination when new GANs are presented to the network
A Full-Image Full-Resolution End-to-End-Trainable CNN Framework for Image Forgery Detection
Sep 15, 2019



Due to limited computational and memory resources, current deep learning models accept only rather small images in input, calling for preliminary image resizing. This is not a problem for high-level vision problems, where discriminative features are barely affected by resizing. On the contrary, in image forensics, resizing tends to destroy precious high-frequency details, impacting heavily on performance. One can avoid resizing by means of patch-wise processing, at the cost of renouncing whole-image analysis. In this work, we propose a CNN-based image forgery detection framework which makes decisions based on full-resolution information gathered from the whole image. Thanks to gradient checkpointing, the framework is trainable end-to-end with limited memory resources and weak (image-level) supervision, allowing for the joint optimization of all parameters. Experiments on widespread image forensics datasets prove the good performance of the proposed approach, which largely outperforms all baselines and all reference methods.
Perceptual Quality-preserving Black-Box Attack against Deep Learning Image Classifiers
Feb 20, 2019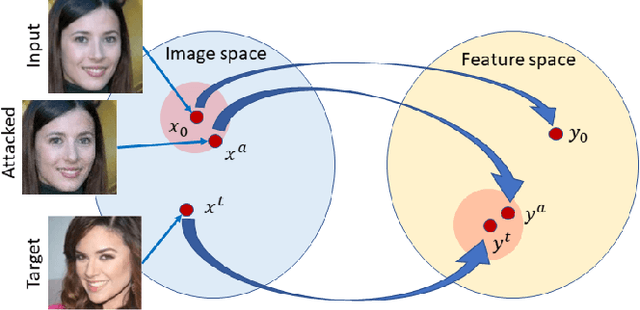
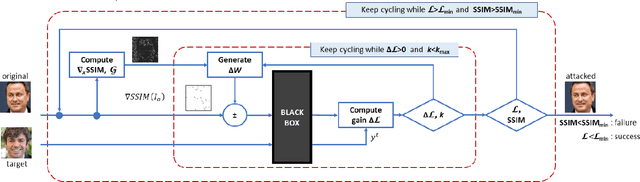
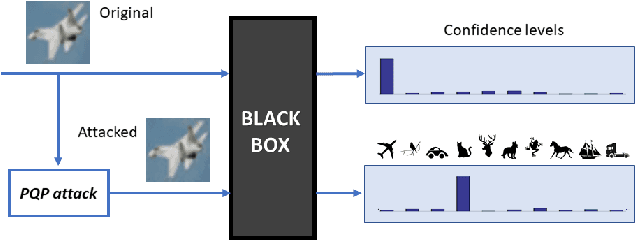
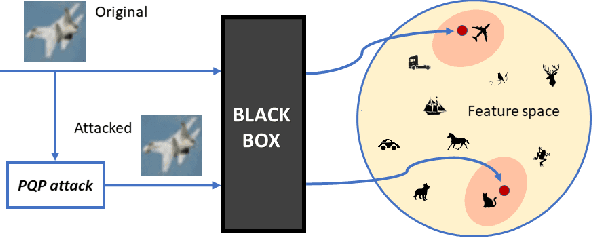
Deep neural networks provide unprecedented performance in all image classification problems, leveraging the availability of huge amounts of data for training. Recent studies, however, have shown their vulnerability to adversarial attacks, spawning an intense research effort in this field. With the aim of building better systems, new countermeasures and stronger attacks are proposed by the day. On the attacker's side, there is growing interest for the realistic black-box scenario, in which the user has no access to the neural network parameters. The problem is to design limited-complexity attacks which mislead the neural network without impairing image quality too much, not to raise the attention of human observers. In this work, we put special emphasis on this latter requirement and propose a powerful and low-complexity black-box attack which preserves perceptual image quality. Numerical experiments prove the effectiveness of the proposed techniques both for tasks commonly considered in this context, and for other applications in biometrics (face recognition) and forensics (camera model identification).
FaceForensics++: Learning to Detect Manipulated Facial Images
Jan 25, 2019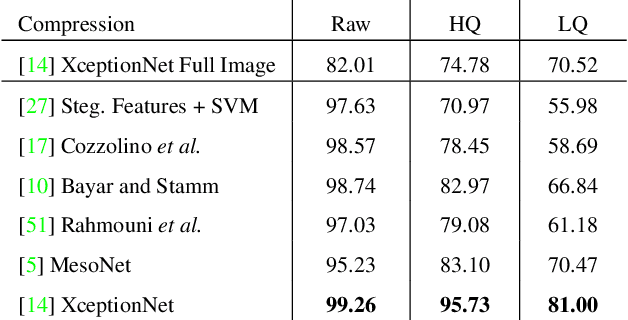

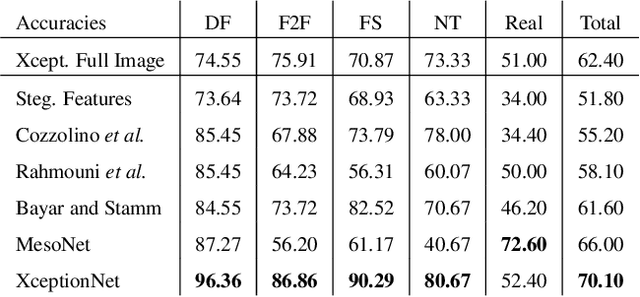
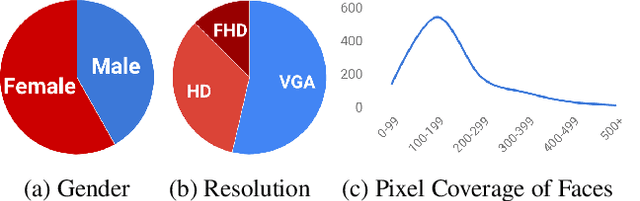
The rapid progress in synthetic image generation and manipulation has now come to a point where it raises significant concerns on the implication on the society. At best, this leads to a loss of trust in digital content, but it might even cause further harm by spreading false information and the creation of fake news. In this paper, we examine the realism of state-of-the-art image manipulations, and how difficult it is to detect them - either automatically or by humans. In particular, we focus on DeepFakes, Face2Face, and FaceSwap as prominent representatives for facial manipulations. We create more than half a million manipulated images respectively for each approach. The resulting publicly available dataset is at least an order of magnitude larger than comparable alternatives and it enables us to train data-driven forgery detectors in a supervised fashion. We show that the use of additional domain specific knowledge improves forgery detection to an unprecedented accuracy, even in the presence of strong compression. By conducting a series of thorough experiments, we quantify the differences between classical approaches, novel deep learning approaches, and the performance of human observers.
Do GANs leave artificial fingerprints?
Dec 31, 2018

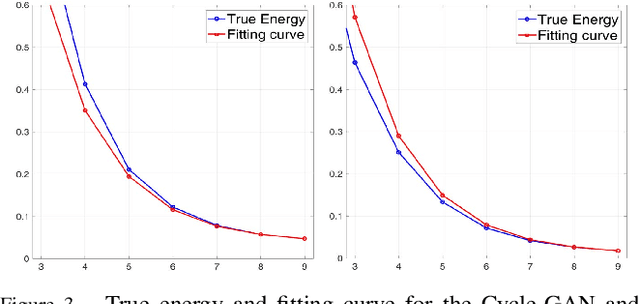
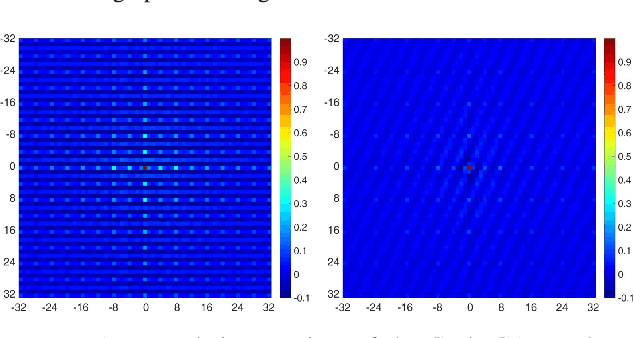
In the last few years, generative adversarial networks (GAN) have shown tremendous potential for a number of applications in computer vision and related fields. With the current pace of progress, it is a sure bet they will soon be able to generate high-quality images and videos, virtually indistinguishable from real ones. Unfortunately, realistic GAN-generated images pose serious threats to security, to begin with a possible flood of fake multimedia, and multimedia forensic countermeasures are in urgent need. In this work, we show that each GAN leaves its specific fingerprint in the images it generates, just like real-world cameras mark acquired images with traces of their photo-response non-uniformity pattern. Source identification experiments with several popular GANs show such fingerprints to represent a precious asset for forensic analyses.
ForensicTransfer: Weakly-supervised Domain Adaptation for Forgery Detection
Dec 06, 2018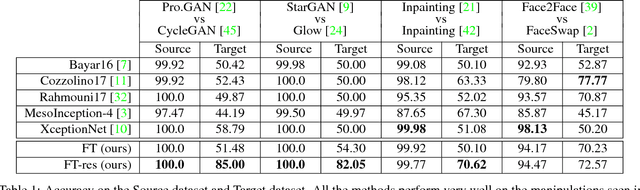
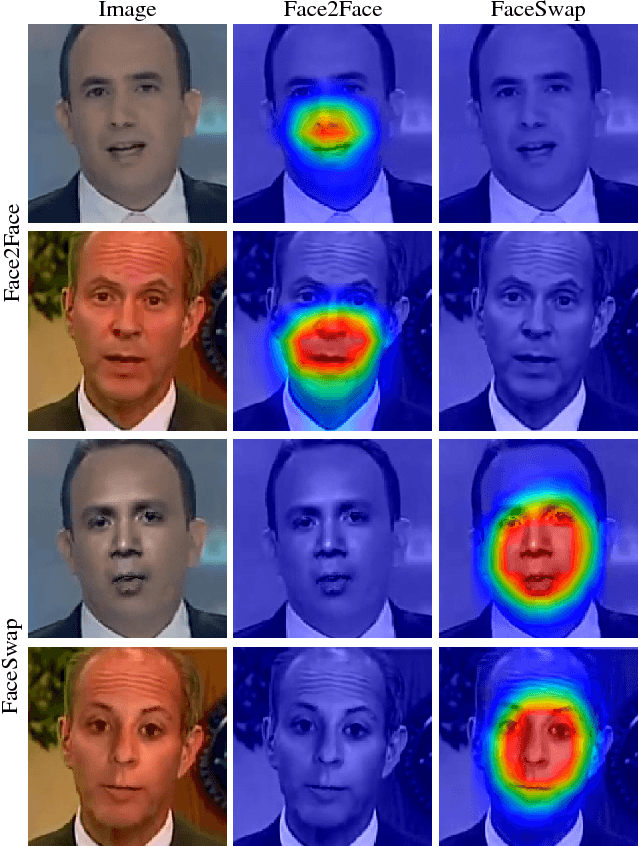


Distinguishing fakes from real images is becoming increasingly difficult as new sophisticated image manipulation approaches come out by the day. Convolutional neural networks (CNN) show excellent performance in detecting image manipulations when they are trained on a specific forgery method. However, on examples from unseen manipulation approaches, their performance drops significantly. To address this limitation in transferability, we introduce ForensicTransfer. ForensicTransfer tackles two challenges in multimedia forensics. First, we devise a learning-based forensic detector which adapts well to new domains, i.e., novel manipulation methods. Second we handle scenarios where only a handful of fake examples are available during training. To this end, we learn a forensic embedding that can be used to distinguish between real and fake imagery. We are using a new autoencoder-based architecture which enforces activations in different parts of a latent vector for the real and fake classes. Together with the constraint of correct reconstruction this ensures that the latent space keeps all the relevant information about the nature of the image. Therefore, the learned embedding acts as a form of anomaly detector; namely, an image manipulated from an unseen method will be detected as fake provided it maps sufficiently far away from the cluster of real images. Comparing with prior works, ForensicTransfer shows significant improvements in transferability, which we demonstrate in a series of experiments on cutting-edge benchmarks. For instance, on unseen examples, we achieve up to 80-85% in terms of accuracy compared to 50-59%, and with only a handful of seen examples, our performance already reaches around 95%.
Guided patch-wise nonlocal SAR despeckling
Nov 28, 2018

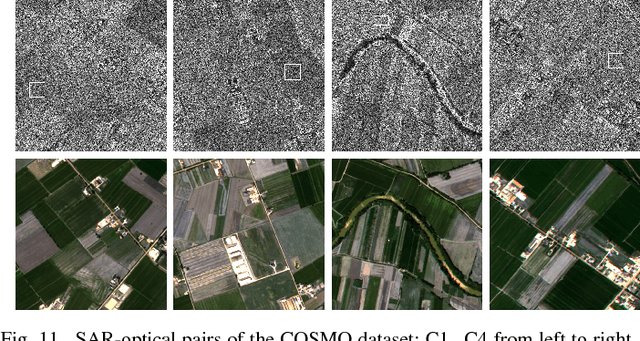

We propose a new method for SAR image despeckling which leverages information drawn from co-registered optical imagery. Filtering is performed by plain patch-wise nonlocal means, operating exclusively on SAR data. However, the filtering weights are computed by taking into account also the optical guide, which is much cleaner than the SAR data, and hence more discriminative. To avoid injecting optical-domain information into the filtered image, a SAR-domain statistical test is preliminarily performed to reject right away any risky predictor. Experiments on two SAR-optical datasets prove the proposed method to suppress very effectively the speckle, preserving structural details, and without introducing visible filtering artifacts. Overall, the proposed method compares favourably with all state-of-the-art despeckling filters, and also with our own previous optical-guided filter.
Camera-based Image Forgery Localization using Convolutional Neural Networks
Aug 29, 2018
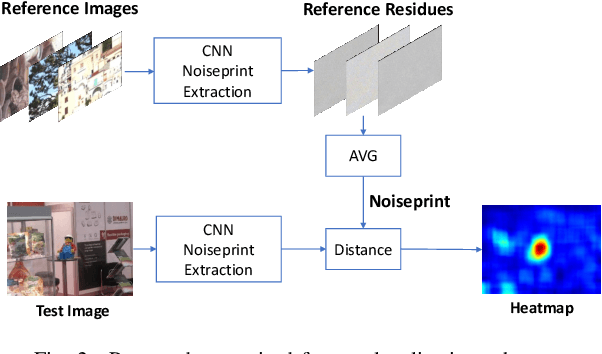
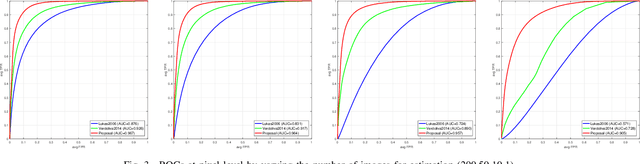
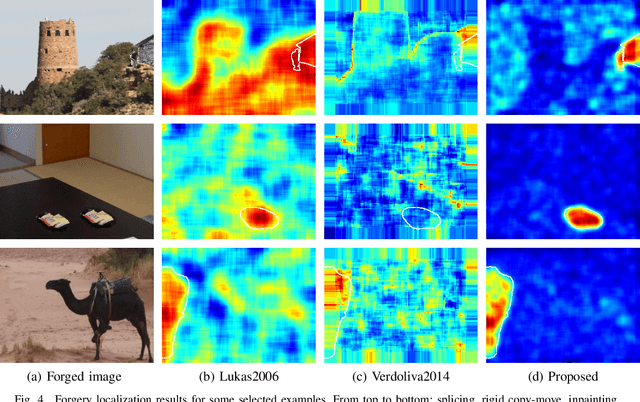
Camera fingerprints are precious tools for a number of image forensics tasks. A well-known example is the photo response non-uniformity (PRNU) noise pattern, a powerful device fingerprint. Here, to address the image forgery localization problem, we rely on noiseprint, a recently proposed CNN-based camera model fingerprint. The CNN is trained to minimize the distance between same-model patches, and maximize the distance otherwise. As a result, the noiseprint accounts for model-related artifacts just like the PRNU accounts for device-related non-uniformities. However, unlike the PRNU, it is only mildly affected by residuals of high-level scene content. The experiments show that the proposed noiseprint-based forgery localization method improves over the PRNU-based reference.