 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongbing Cao
COVID-19 Modeling: A Review
Apr 16, 2021

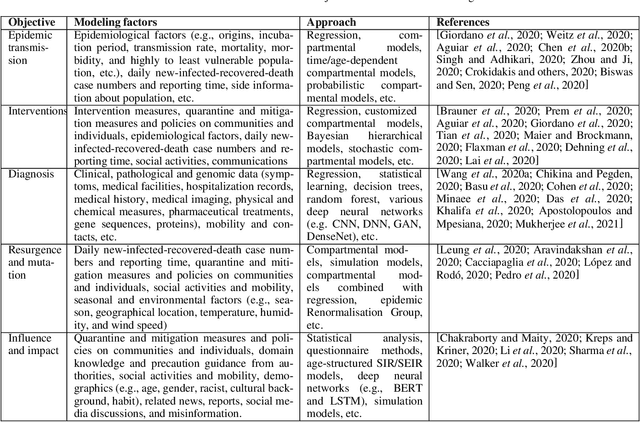
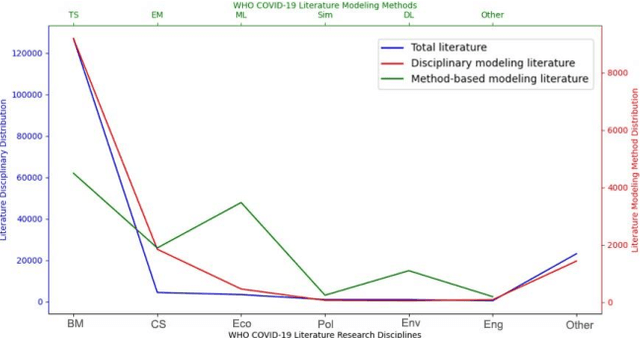
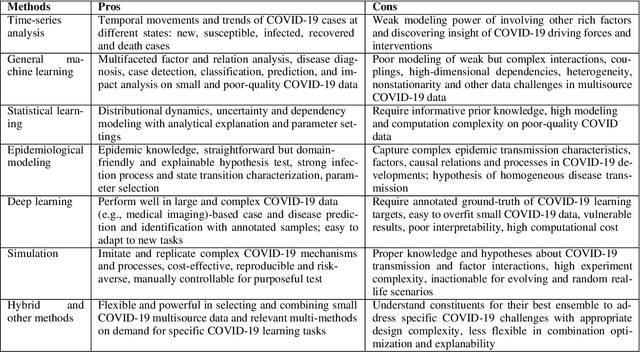
To tackle the COVID-19 pandemic, massive efforts have been made in modeling COVID-19 transmission, diagnoses, interventions, pathological and influence analysis, etc. With the most comprehensive repository on COVID-19 research - some 160k WHO-collected global literature on COVID-19 produced since 2020, some critical question to ask include: What are the COVID-19 challenges? How do they address the challenges? Where are the significant gaps and opportunities in COVID-19 modeling?. Accordingly, informed by their statistics and a deep keyword-based similarity analysis of those references on COVID-19 modeling, this is the first to systemically summarize the disease, data and modeling challenges and the corresponding modeling progress and gaps. We come up with a transdisciplinary research landscape to summarize and match the business goals and tasks and their learning methods of COVID-19 modeling.
Homophily Outlier Detection in Non-IID Categorical Data
Mar 21, 2021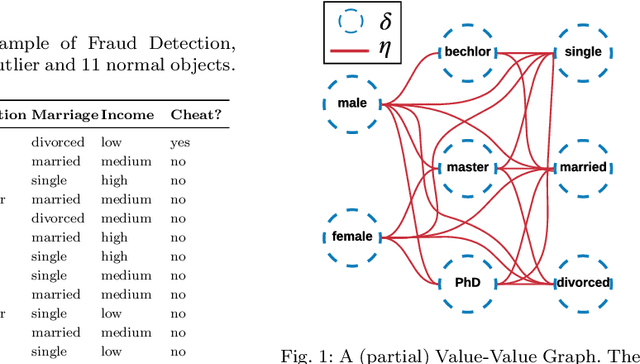
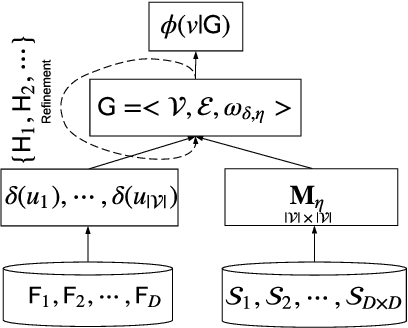
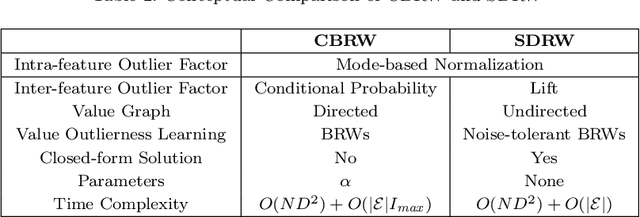
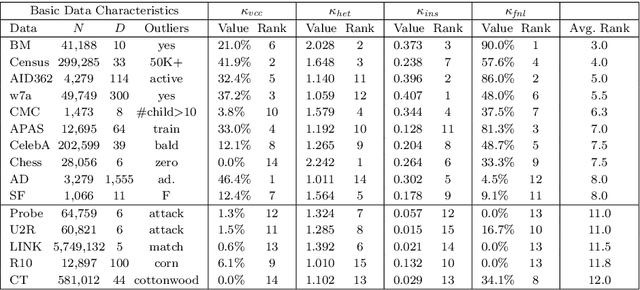
Most of existing outlier detection methods assume that the outlier factors (i.e., outlierness scoring measures) of data entities (e.g., feature values and data objects) are Independent and Identically Distributed (IID). This assumption does not hold in real-world applications where the outlierness of different entities is dependent on each other and/or taken from different probability distributions (non-IID). This may lead to the failure of detecting important outliers that are too subtle to be identified without considering the non-IID nature. The issue is even intensified in more challenging contexts, e.g., high-dimensional data with many noisy features. This work introduces a novel outlier detection framework and its two instances to identify outliers in categorical data by capturing non-IID outlier factors. Our approach first defines and incorporates distribution-sensitive outlier factors and their interdependence into a value-value graph-based representation. It then models an outlierness propagation process in the value graph to learn the outlierness of feature values. The learned value outlierness allows for either direct outlier detection or outlying feature selection. The graph representation and mining approach is employed here to well capture the rich non-IID characteristics. Our empirical results on 15 real-world data sets with different levels of data complexities show that (i) the proposed outlier detection methods significantly outperform five state-of-the-art methods at the 95%/99% confidence level, achieving 10%-28% AUC improvement on the 10 most complex data sets; and (ii) the proposed feature selection methods significantly outperform three competing methods in enabling subsequent outlier detection of two different existing detectors.
Deep Reinforcement Learning for Unknown Anomaly Detection
Sep 15, 2020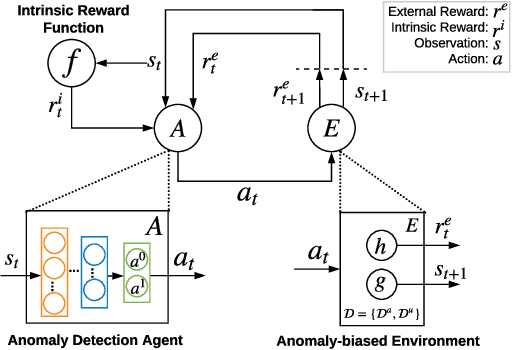
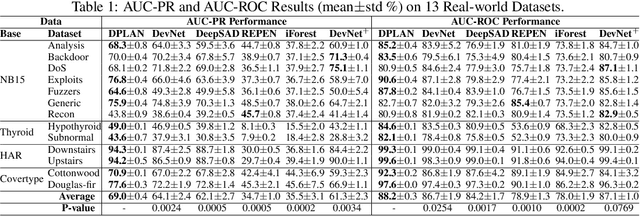

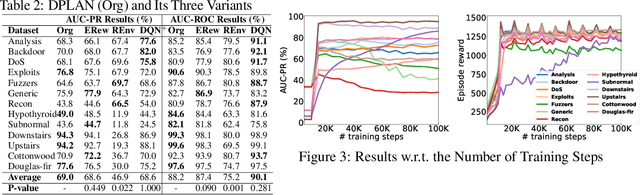
We address a critical yet largely unsolved anomaly detection problem, in which we aim to learn detection models from a small set of partially labeled anomalies and a large-scale unlabeled dataset. This is a common scenario in many important applications. Existing related methods either proceed unsupervised with the unlabeled data, or exclusively fit the limited anomaly examples that often do not span the entire set of anomalies. We propose here instead a deep reinforcement-learning-based approach that actively seeks novel classes of anomaly that lie beyond the scope of the labeled training data. This approach learns to balance exploiting its existing data model against exploring for new classes of anomaly. It is thus able to exploit the labeled anomaly data to improve detection accuracy, without limiting the set of anomalies sought to those given anomaly examples. This is of significant practical benefit, as anomalies are inevitably unpredictable in form and often expensive to miss. Extensive experiments on 48 real-world datasets show that our approach significantly outperforms five state-of-the-art competing methods.
Unsupervised Heterogeneous Coupling Learning for Categorical Representation
Jul 21, 2020
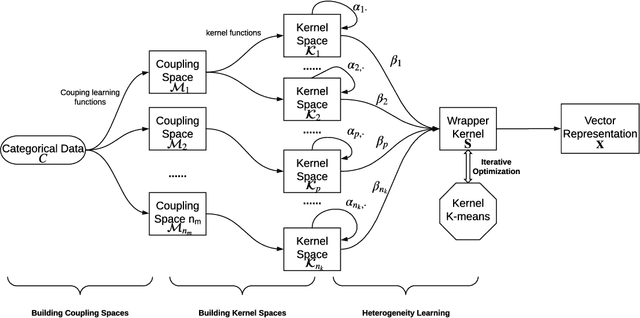

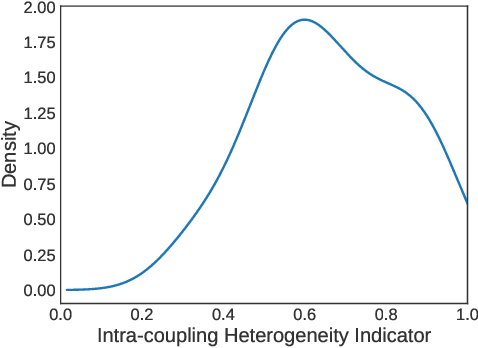
Complex categorical data is often hierarchically coupled with heterogeneous relationships between attributes and attribute values and the couplings between objects. Such value-to-object couplings are heterogeneous with complementary and inconsistent interactions and distributions. Limited research exists on unlabeled categorical data representations, ignores the heterogeneous and hierarchical couplings, underestimates data characteristics and complexities, and overuses redundant information, etc. The deep representation learning of unlabeled categorical data is challenging, overseeing such value-to-object couplings, complementarity and inconsistency, and requiring large data, disentanglement, and high computational power. This work introduces a shallow but powerful UNsupervised heTerogeneous couplIng lEarning (UNTIE) approach for representing coupled categorical data by untying the interactions between couplings and revealing heterogeneous distributions embedded in each type of couplings. UNTIE is efficiently optimized w.r.t. a kernel k-means objective function for unsupervised representation learning of heterogeneous and hierarchical value-to-object couplings. Theoretical analysis shows that UNTIE can represent categorical data with maximal separability while effectively represent heterogeneous couplings and disclose their roles in categorical data. The UNTIE-learned representations make significant performance improvement against the state-of-the-art categorical representations and deep representation models on 25 categorical data sets with diversified characteristics.
Deep Learning for Anomaly Detection: A Review
Jul 08, 2020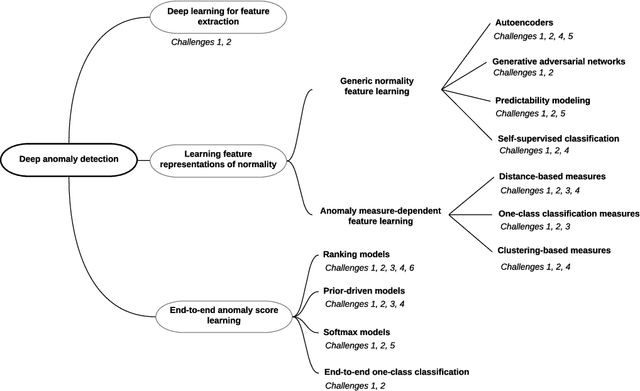
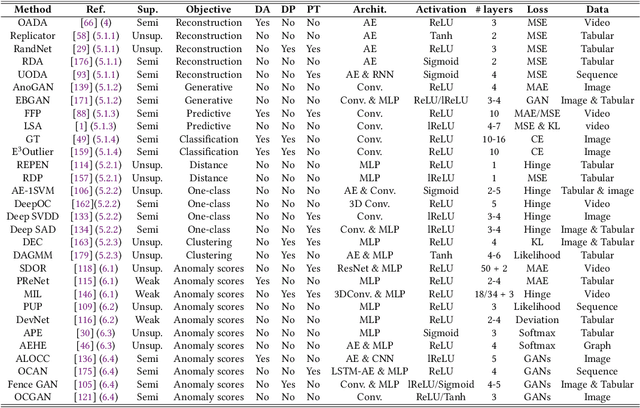
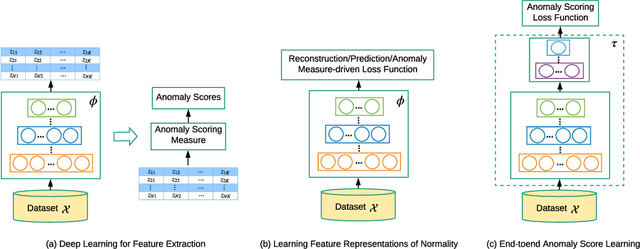
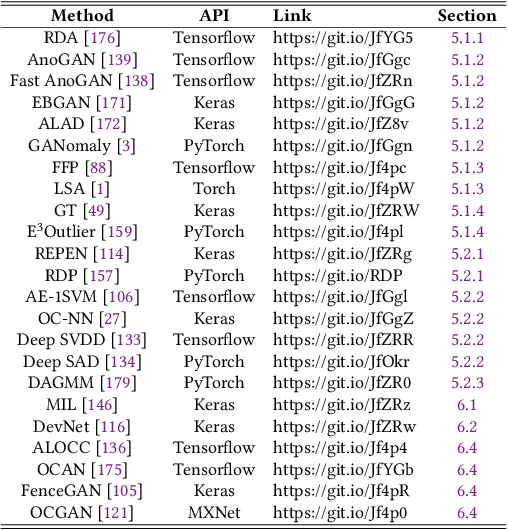
Anomaly detection, a.k.a. outlier detection, has been a lasting yet active research area in various research communities for several decades. There are still some unique problem complexities and challenges that require advanced approaches. In recent years, deep learning enabled anomaly detection, i.e., deep anomaly detection, has emerged as a critical direction. This paper reviews the research of deep anomaly detection with a comprehensive taxonomy of detection methods, covering advancements in three high-level categories and 11 fine-grained categories of the methods. We review their key intuitions, objective functions, underlying assumptions, advantages and disadvantages, and discuss how they address the aforementioned challenges. We further discuss a set of possible future opportunities and new perspectives on addressing the challenges.
Non-IID Recommender Systems: A Review and Framework of Recommendation Paradigm Shifting
Jul 01, 2020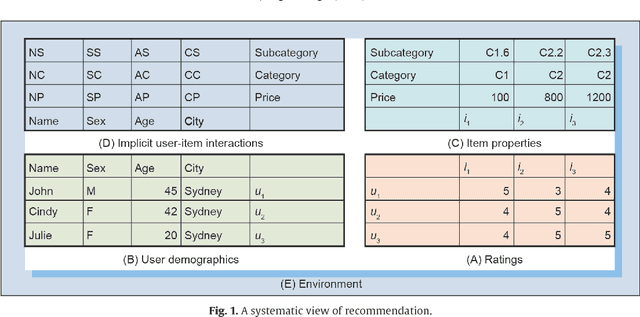
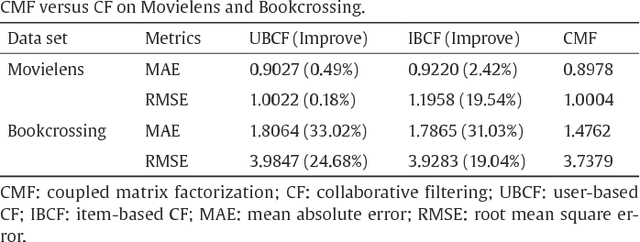
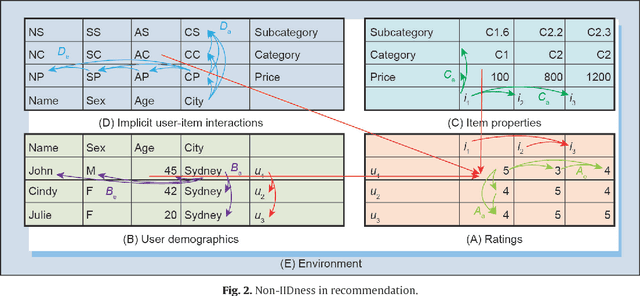
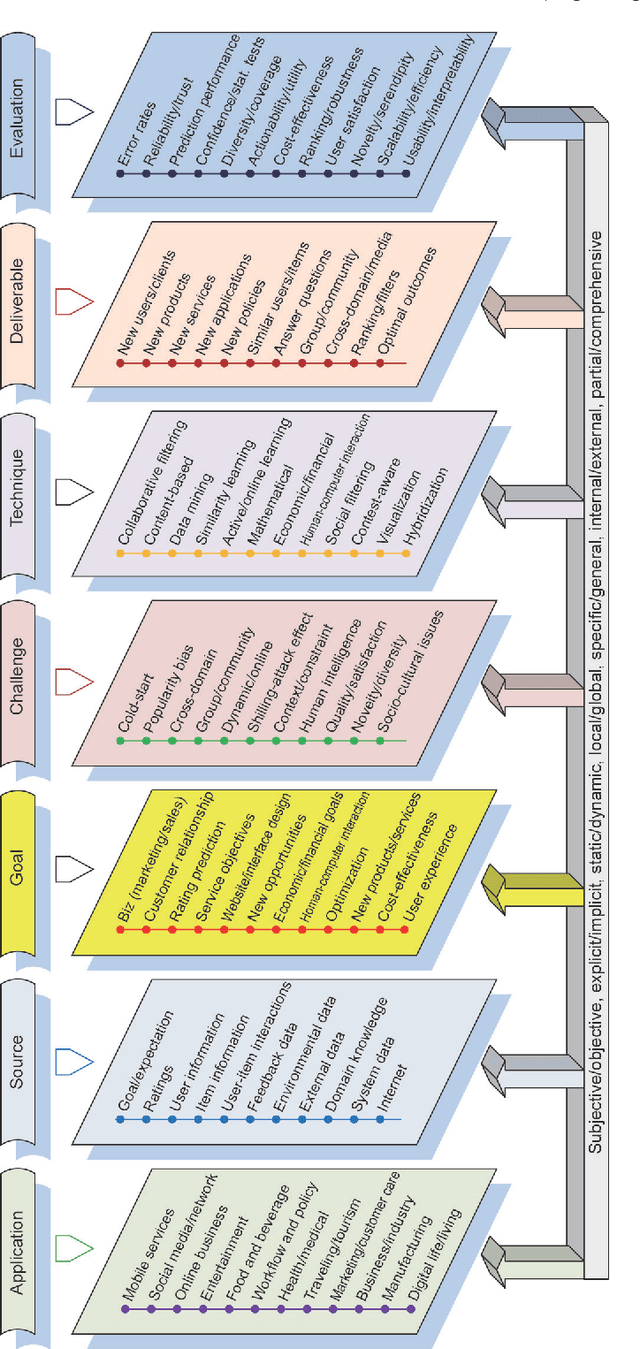
While recommendation plays an increasingly critical role in our living, study, work, and entertainment, the recommendations we receive are often for irrelevant, duplicate, or uninteresting products and services. A critical reason for such bad recommendations lies in the intrinsic assumption that recommended users and items are independent and identically distributed (IID) in existing theories and systems. Another phenomenon is that, while tremendous efforts have been made to model specific aspects of users or items, the overall user and item characteristics and their non-IIDness have been overlooked. In this paper, the non-IID nature and characteristics of recommendation are discussed, followed by the non-IID theoretical framework in order to build a deep and comprehensive understanding of the intrinsic nature of recommendation problems, from the perspective of both couplings and heterogeneity. This non-IID recommendation research triggers the paradigm shift from IID to non-IID recommendation research and can hopefully deliver informed, relevant, personalized, and actionable recommendations. It creates exciting new directions and fundamental solutions to address various complexities including cold-start, sparse data-based, cross-domain, group-based, and shilling attack-related issues.
Jointly Modeling Intra- and Inter-transaction Dependencies with Hierarchical Attentive Transaction Embeddings for Next-item Recommendation
May 30, 2020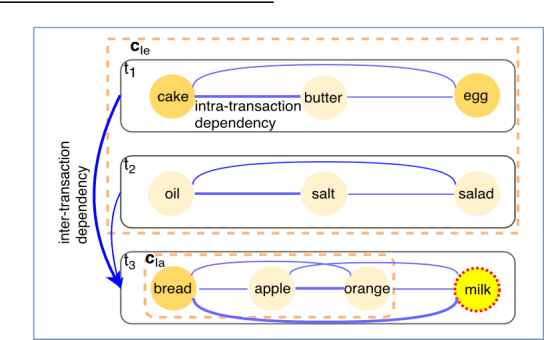
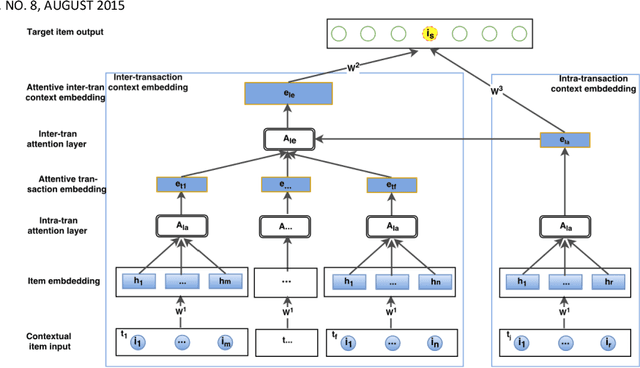
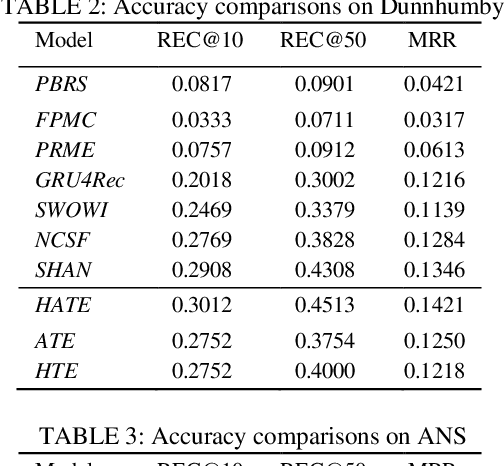
A transaction-based recommender system (TBRS) aims to predict the next item by modeling dependencies in transactional data. Generally, two kinds of dependencies considered are intra-transaction dependency and inter-transaction dependency. Most existing TBRSs recommend next item by only modeling the intra-transaction dependency within the current transaction while ignoring inter-transaction dependency with recent transactions that may also affect the next item. However, as not all recent transactions are relevant to the current and next items, the relevant ones should be identified and prioritized. In this paper, we propose a novel hierarchical attentive transaction embedding (HATE) model to tackle these issues. Specifically, a two-level attention mechanism integrates both item embedding and transaction embedding to build an attentive context representation that incorporates both intraand inter-transaction dependencies. With the learned context representation, HATE then recommends the next item. Experimental evaluations on two real-world transaction datasets show that HATE significantly outperforms the state-ofthe-art methods in terms of recommendation accuracy.
Sequential Recommender Systems: Challenges, Progress and Prospects
Dec 28, 2019
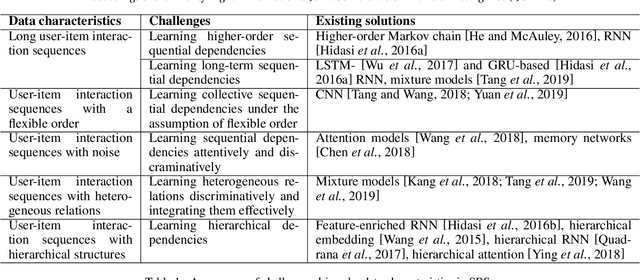
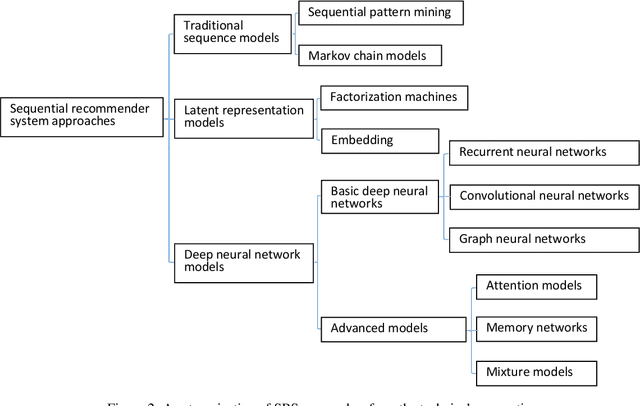
The emerging topic of sequential recommender systems has attracted increasing attention in recent years.Different from the conventional recommender systems including collaborative filtering and content-based filtering, SRSs try to understand and model the sequential user behaviors, the interactions between users and items, and the evolution of users preferences and item popularity over time. SRSs involve the above aspects for more precise characterization of user contexts, intent and goals, and item consumption trend, leading to more accurate, customized and dynamic recommendations.In this paper, we provide a systematic review on SRSs.We first present the characteristics of SRSs, and then summarize and categorize the key challenges in this research area, followed by the corresponding research progress consisting of the most recent and representative developments on this topic.Finally, we discuss the important research directions in this vibrant area.
FiDi-RL: Incorporating Deep Reinforcement Learning with Finite-Difference Policy Search for Efficient Learning of Continuous Control
Jul 10, 2019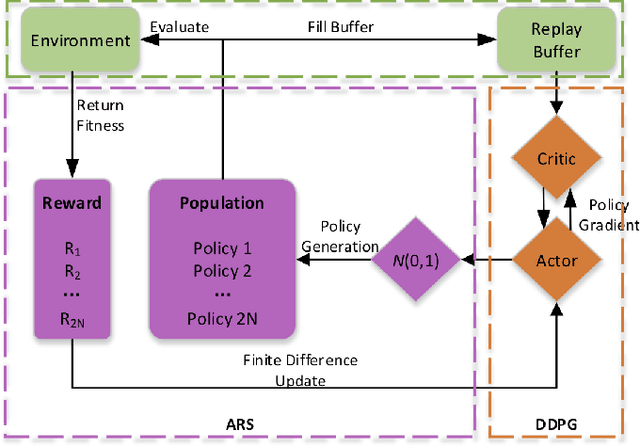

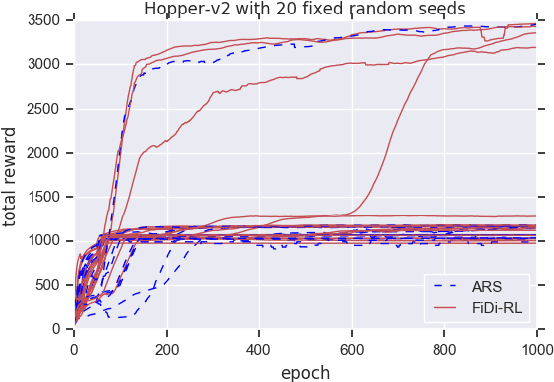
In recent years significant progress has been made in dealing with challenging problems using reinforcement learning.Despite its great success, reinforcement learning still faces challenge in continuous control tasks. Conventional methods always compute the derivatives of the optimal goal with a costly computation resources, and are inefficient, unstable and lack of robust-ness when dealing with such tasks. Alternatively, derivative-based methods treat the optimization process as a blackbox and show robustness and stability in learning continuous control tasks, but not data efficient in learning. The combination of both methods so as to get the best of the both has raised attention. However, most of the existing combination works adopt complex neural networks (NNs) as the policy for control. The double-edged sword of deep NNs can yield better performance, but also makes it difficult for parameter tuning and computation. To this end, in this paper we presents a novel method called FiDi-RL, which incorporates deep RL with Finite-Difference (FiDi) policy search.FiDi-RL combines Deep Deterministic Policy Gradients (DDPG)with Augment Random Search (ARS) and aims at improving the data efficiency of ARS. The empirical results show that FiDi-RL can improves the performance and stability of ARS, and provide competitive results against some existing deep reinforcement learning methods