 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiu Liu
RPMArt: Towards Robust Perception and Manipulation for Articulated Objects
Mar 24, 2024
Articulated objects are commonly found in daily life. It is essential that robots can exhibit robust perception and manipulation skills for articulated objects in real-world robotic applications. However, existing methods for articulated objects insufficiently address noise in point clouds and struggle to bridge the gap between simulation and reality, thus limiting the practical deployment in real-world scenarios. To tackle these challenges, we propose a framework towards Robust Perception and Manipulation for Articulated Objects (RPMArt), which learns to estimate the articulation parameters and manipulate the articulation part from the noisy point cloud. Our primary contribution is a Robust Articulation Network (RoArtNet) that is able to predict both joint parameters and affordable points robustly by local feature learning and point tuple voting. Moreover, we introduce an articulation-aware classification scheme to enhance its ability for sim-to-real transfer. Finally, with the estimated affordable point and articulation joint constraint, the robot can generate robust actions to manipulate articulated objects. After learning only from synthetic data, RPMArt is able to transfer zero-shot to real-world articulated objects. Experimental results confirm our approach's effectiveness, with our framework achieving state-of-the-art performance in both noise-added simulation and real-world environments. The code and data will be open-sourced for reproduction. More results are published on the project website at https://r-pmart.github.io .
ManiPose: A Comprehensive Benchmark for Pose-aware Object Manipulation in Robotics
Mar 20, 2024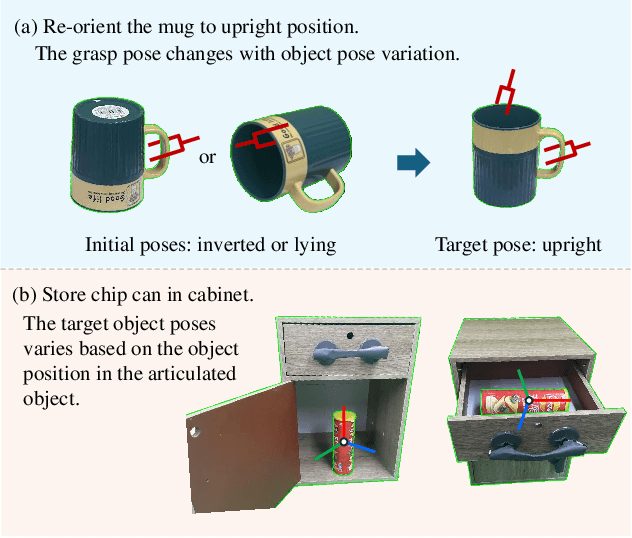
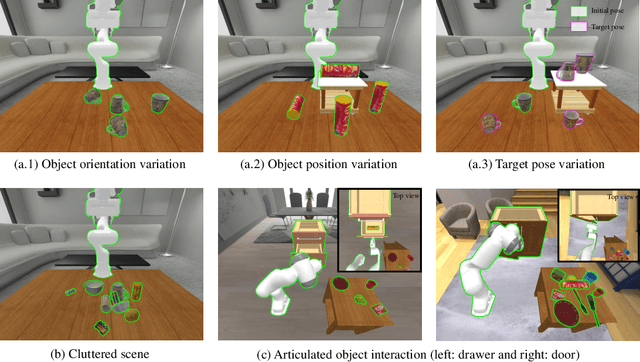
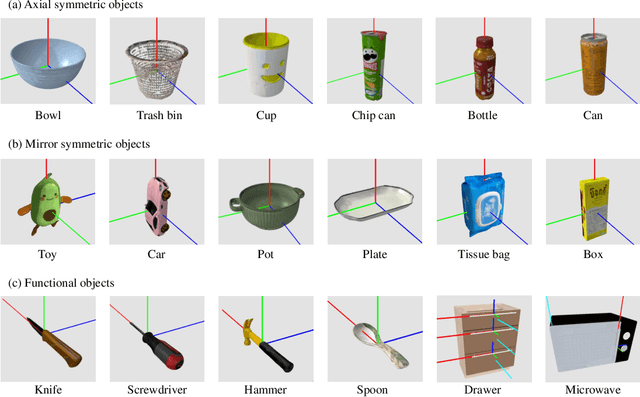

Robotic manipulation in everyday scenarios, especially in unstructured environments, requires skills in pose-aware object manipulation (POM), which adapts robots' grasping and handling according to an object's 6D pose. Recognizing an object's position and orientation is crucial for effective manipulation. For example, if a mug is lying on its side, it's more effective to grasp it by the rim rather than the handle. Despite its importance, research in POM skills remains limited, because learning manipulation skills requires pose-varying simulation environments and datasets. This paper introduces ManiPose, a pioneering benchmark designed to advance the study of pose-varying manipulation tasks. ManiPose encompasses: 1) Simulation environments for POM feature tasks ranging from 6D pose-specific pick-and-place of single objects to cluttered scenes, further including interactions with articulated objects. 2) A comprehensive dataset featuring geometrically consistent and manipulation-oriented 6D pose labels for 2936 real-world scanned rigid objects and 100 articulated objects across 59 categories. 3) A baseline for POM, leveraging the inferencing abilities of LLM (e.g., ChatGPT) to analyze the relationship between 6D pose and task-specific requirements, offers enhanced pose-aware grasp prediction and motion planning capabilities. Our benchmark demonstrates notable advancements in pose estimation, pose-aware manipulation, and real-robot skill transfer, setting new standards for POM research. We will open-source the ManiPose benchmark with the final version paper, inviting the community to engage with our resources, available at our website:https://sites.google.com/view/manipose.
Thermal-NeRF: Neural Radiance Fields from an Infrared Camera
Mar 15, 2024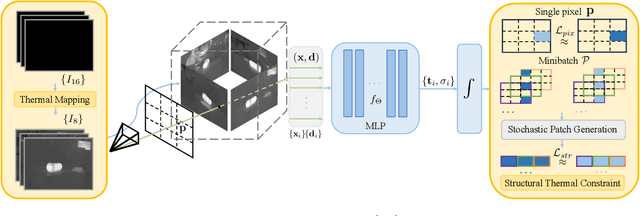



In recent years, Neural Radiance Fields (NeRFs) have demonstrated significant potential in encoding highly-detailed 3D geometry and environmental appearance, positioning themselves as a promising alternative to traditional explicit representation for 3D scene reconstruction. However, the predominant reliance on RGB imaging presupposes ideal lighting conditions: a premise frequently unmet in robotic applications plagued by poor lighting or visual obstructions. This limitation overlooks the capabilities of infrared (IR) cameras, which excel in low-light detection and present a robust alternative under such adverse scenarios. To tackle these issues, we introduce Thermal-NeRF, the first method that estimates a volumetric scene representation in the form of a NeRF solely from IR imaging. By leveraging a thermal mapping and structural thermal constraint derived from the thermal characteristics of IR imaging, our method showcasing unparalleled proficiency in recovering NeRFs in visually degraded scenes where RGB-based methods fall short. We conduct extensive experiments to demonstrate that Thermal-NeRF can achieve superior quality compared to existing methods. Furthermore, we contribute a dataset for IR-based NeRF applications, paving the way for future research in IR NeRF reconstruction.
Step-On-Feet Tuning: Scaling Self-Alignment of LLMs via Bootstrapping
Feb 22, 2024Self-alignment is an effective way to reduce the cost of human annotation while ensuring promising model capability. However, most current methods complete the data collection and training steps in a single round, which may overlook the continuously improving ability of self-aligned models. This gives rise to a key query: What if we do multi-time bootstrapping self-alignment? Does this strategy enhance model performance or lead to rapid degradation? In this paper, our pioneering exploration delves into the impact of bootstrapping self-alignment on large language models. Our findings reveal that bootstrapping self-alignment markedly surpasses the single-round approach, by guaranteeing data diversity from in-context learning. To further exploit the capabilities of bootstrapping, we investigate and adjust the training order of data, which yields improved performance of the model. Drawing on these findings, we propose Step-On-Feet Tuning (SOFT) which leverages model's continuously enhanced few-shot ability to boost zero or one-shot performance. Based on easy-to-hard training recipe, we propose SOFT+ which further boost self-alignment's performance. Our experiments demonstrate the efficiency of SOFT (SOFT+) across various classification and generation tasks, highlighting the potential of bootstrapping self-alignment on continually enhancing model alignment performance.
Enhance DNN Adversarial Robustness and Efficiency via Injecting Noise to Non-Essential Neurons
Feb 06, 2024Deep Neural Networks (DNNs) have revolutionized a wide range of industries, from healthcare and finance to automotive, by offering unparalleled capabilities in data analysis and decision-making. Despite their transforming impact, DNNs face two critical challenges: the vulnerability to adversarial attacks and the increasing computational costs associated with more complex and larger models. In this paper, we introduce an effective method designed to simultaneously enhance adversarial robustness and execution efficiency. Unlike prior studies that enhance robustness via uniformly injecting noise, we introduce a non-uniform noise injection algorithm, strategically applied at each DNN layer to disrupt adversarial perturbations introduced in attacks. By employing approximation techniques, our approach identifies and protects essential neurons while strategically introducing noise into non-essential neurons. Our experimental results demonstrate that our method successfully enhances both robustness and efficiency across several attack scenarios, model architectures, and datasets.
Efficient approximation of Earth Mover's Distance Based on Nearest Neighbor Search
Jan 20, 2024Earth Mover's Distance (EMD) is an important similarity measure between two distributions, used in computer vision and many other application domains. However, its exact calculation is computationally and memory intensive, which hinders its scalability and applicability for large-scale problems. Various approximate EMD algorithms have been proposed to reduce computational costs, but they suffer lower accuracy and may require additional memory usage or manual parameter tuning. In this paper, we present a novel approach, NNS-EMD, to approximate EMD using Nearest Neighbor Search (NNS), in order to achieve high accuracy, low time complexity, and high memory efficiency. The NNS operation reduces the number of data points compared in each NNS iteration and offers opportunities for parallel processing. We further accelerate NNS-EMD via vectorization on GPU, which is especially beneficial for large datasets. We compare NNS-EMD with both the exact EMD and state-of-the-art approximate EMD algorithms on image classification and retrieval tasks. We also apply NNS-EMD to calculate transport mapping and realize color transfer between images. NNS-EMD can be 44x to 135x faster than the exact EMD implementation, and achieves superior accuracy, speedup, and memory efficiency over existing approximate EMD methods.
Event Camera Data Dense Pre-training
Nov 20, 2023This paper introduces a self-supervised learning framework designed for pre-training neural networks tailored to dense prediction tasks using event camera data. Our approach utilizes solely event data for training. Transferring achievements from dense RGB pre-training directly to event camera data yields subpar performance. This is attributed to the spatial sparsity inherent in an event image (converted from event data), where many pixels do not contain information. To mitigate this sparsity issue, we encode an event image into event patch features, automatically mine contextual similarity relationships among patches, group the patch features into distinctive contexts, and enforce context-to-context similarities to learn discriminative event features. For training our framework, we curate a synthetic event camera dataset featuring diverse scene and motion patterns. Transfer learning performance on downstream dense prediction tasks illustrates the superiority of our method over state-of-the-art approaches. Notably, our single model secured the top position in the challenging DSEC-Flow benchmark.
PainSeeker: An Automated Method for Assessing Pain in Rats Through Facial Expressions
Nov 06, 2023In this letter, we aim to investigate whether laboratory rats' pain can be automatically assessed through their facial expressions. To this end, we began by presenting a publicly available dataset called RatsPain, consisting of 1,138 facial images captured from six rats that underwent an orthodontic treatment operation. Each rat' facial images in RatsPain were carefully selected from videos recorded either before or after the operation and well labeled by eight annotators according to the Rat Grimace Scale (RGS). We then proposed a novel deep learning method called PainSeeker for automatically assessing pain in rats via facial expressions. PainSeeker aims to seek pain-related facial local regions that facilitate learning both pain discriminative and head pose robust features from facial expression images. To evaluate the PainSeeker, we conducted extensive experiments on the RatsPain dataset. The results demonstrate the feasibility of assessing rats' pain from their facial expressions and also verify the effectiveness of the proposed PainSeeker in addressing this emerging but intriguing problem. The RasPain dataset can be freely obtained from https://github.com/xhzongyuan/RatsPain.