 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiting Sun
Courteous Autonomous Cars
Aug 16, 2018
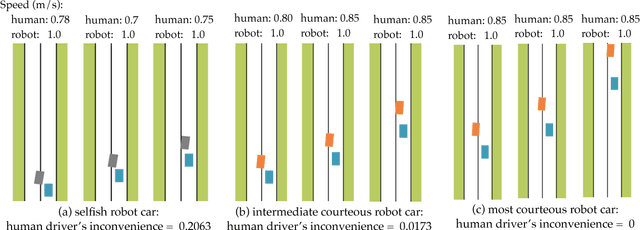

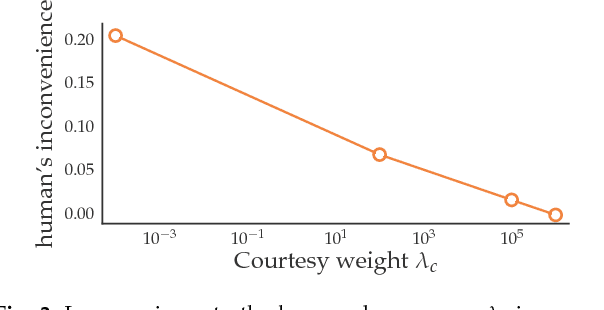
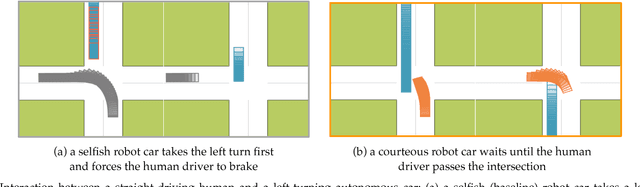
Typically, autonomous cars optimize for a combination of safety, efficiency, and driving quality. But as we get better at this optimization, we start seeing behavior go from too conservative to too aggressive. The car's behavior exposes the incentives we provide in its cost function. In this work, we argue for cars that are not optimizing a purely selfish cost, but also try to be courteous to other interactive drivers. We formalize courtesy as a term in the objective that measures the increase in another driver's cost induced by the autonomous car's behavior. Such a courtesy term enables the robot car to be aware of possible irrationality of the human behavior, and plan accordingly. We analyze the effect of courtesy in a variety of scenarios. We find, for example, that courteous robot cars leave more space when merging in front of a human driver. Moreover, we find that such a courtesy term can help explain real human driver behavior on the NGSIM dataset.
A Fast Integrated Planning and Control Framework for Autonomous Driving via Imitation Learning
Jul 09, 2017



For safe and efficient planning and control in autonomous driving, we need a driving policy which can achieve desirable driving quality in long-term horizon with guaranteed safety and feasibility. Optimization-based approaches, such as Model Predictive Control (MPC), can provide such optimal policies, but their computational complexity is generally unacceptable for real-time implementation. To address this problem, we propose a fast integrated planning and control framework that combines learning- and optimization-based approaches in a two-layer hierarchical structure. The first layer, defined as the "policy layer", is established by a neural network which learns the long-term optimal driving policy generated by MPC. The second layer, called the "execution layer", is a short-term optimization-based controller that tracks the reference trajecotries given by the "policy layer" with guaranteed short-term safety and feasibility. Moreover, with efficient and highly-representative features, a small-size neural network is sufficient in the "policy layer" to handle many complicated driving scenarios. This renders online imitation learning with Dataset Aggregation (DAgger) so that the performance of the "policy layer" can be improved rapidly and continuously online. Several exampled driving scenarios are demonstrated to verify the effectiveness and efficiency of the proposed framework.