 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiqiang Nie
Detecting and Grounding Multi-Modal Media Manipulation and Beyond
Sep 25, 2023
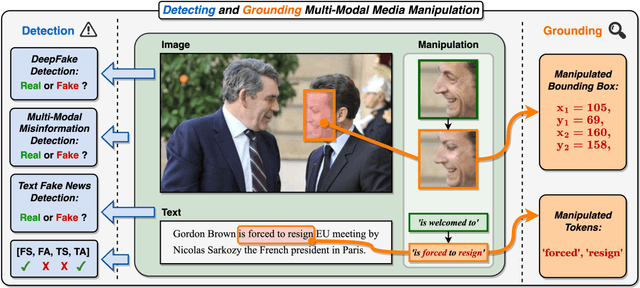

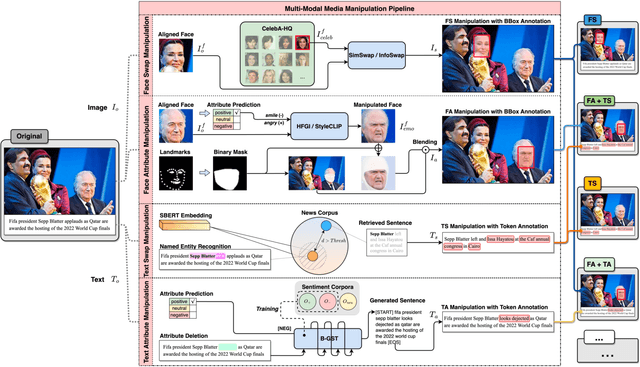

Misinformation has become a pressing issue. Fake media, in both visual and textual forms, is widespread on the web. While various deepfake detection and text fake news detection methods have been proposed, they are only designed for single-modality forgery based on binary classification, let alone analyzing and reasoning subtle forgery traces across different modalities. In this paper, we highlight a new research problem for multi-modal fake media, namely Detecting and Grounding Multi-Modal Media Manipulation (DGM^4). DGM^4 aims to not only detect the authenticity of multi-modal media, but also ground the manipulated content, which requires deeper reasoning of multi-modal media manipulation. To support a large-scale investigation, we construct the first DGM^4 dataset, where image-text pairs are manipulated by various approaches, with rich annotation of diverse manipulations. Moreover, we propose a novel HierArchical Multi-modal Manipulation rEasoning tRansformer (HAMMER) to fully capture the fine-grained interaction between different modalities. HAMMER performs 1) manipulation-aware contrastive learning between two uni-modal encoders as shallow manipulation reasoning, and 2) modality-aware cross-attention by multi-modal aggregator as deep manipulation reasoning. Dedicated manipulation detection and grounding heads are integrated from shallow to deep levels based on the interacted multi-modal information. To exploit more fine-grained contrastive learning for cross-modal semantic alignment, we further integrate Manipulation-Aware Contrastive Loss with Local View and construct a more advanced model HAMMER++. Finally, we build an extensive benchmark and set up rigorous evaluation metrics for this new research problem. Comprehensive experiments demonstrate the superiority of HAMMER and HAMMER++.
Building Emotional Support Chatbots in the Era of LLMs
Aug 17, 2023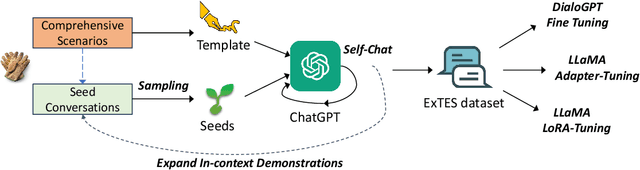
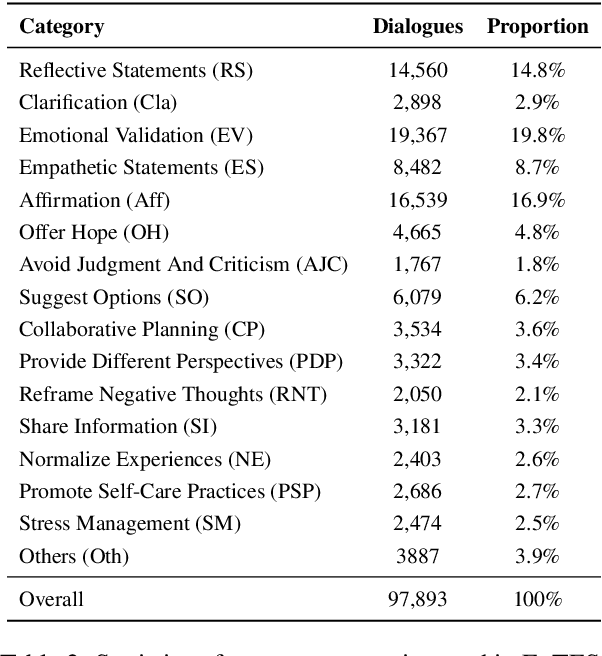
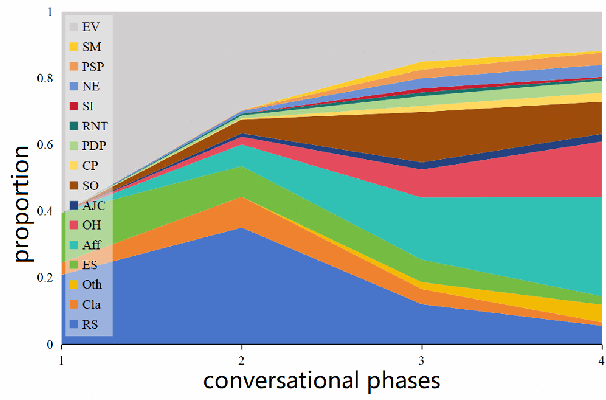
The integration of emotional support into various conversational scenarios presents profound societal benefits, such as social interactions, mental health counseling, and customer service. However, there are unsolved challenges that hinder real-world applications in this field, including limited data availability and the absence of well-accepted model training paradigms. This work endeavors to navigate these challenges by harnessing the capabilities of Large Language Models (LLMs). We introduce an innovative methodology that synthesizes human insights with the computational prowess of LLMs to curate an extensive emotional support dialogue dataset. Our approach is initiated with a meticulously designed set of dialogues spanning diverse scenarios as generative seeds. By utilizing the in-context learning potential of ChatGPT, we recursively generate an ExTensible Emotional Support dialogue dataset, named ExTES. Following this, we deploy advanced tuning techniques on the LLaMA model, examining the impact of diverse training strategies, ultimately yielding an LLM meticulously optimized for emotional support interactions. An exhaustive assessment of the resultant model showcases its proficiency in offering emotional support, marking a pivotal step in the realm of emotional support bots and paving the way for subsequent research and implementations.
Temporal Sentence Grounding in Streaming Videos
Aug 14, 2023
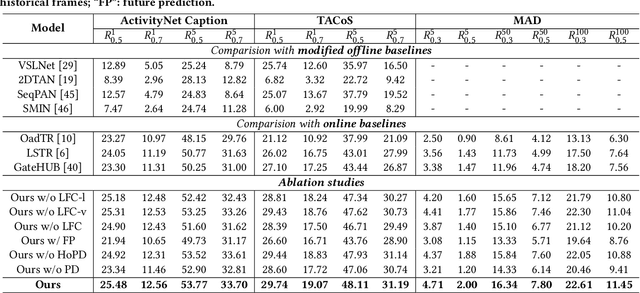
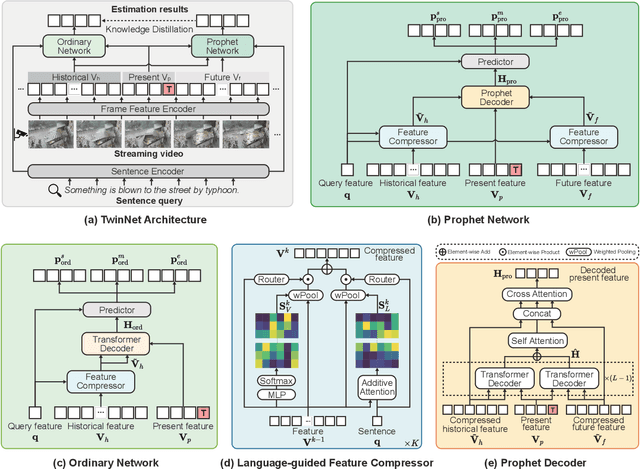

This paper aims to tackle a novel task - Temporal Sentence Grounding in Streaming Videos (TSGSV). The goal of TSGSV is to evaluate the relevance between a video stream and a given sentence query. Unlike regular videos, streaming videos are acquired continuously from a particular source, and are always desired to be processed on-the-fly in many applications such as surveillance and live-stream analysis. Thus, TSGSV is challenging since it requires the model to infer without future frames and process long historical frames effectively, which is untouched in the early methods. To specifically address the above challenges, we propose two novel methods: (1) a TwinNet structure that enables the model to learn about upcoming events; and (2) a language-guided feature compressor that eliminates redundant visual frames and reinforces the frames that are relevant to the query. We conduct extensive experiments using ActivityNet Captions, TACoS, and MAD datasets. The results demonstrate the superiority of our proposed methods. A systematic ablation study also confirms their effectiveness.
LayoutLLM-T2I: Eliciting Layout Guidance from LLM for Text-to-Image Generation
Aug 12, 2023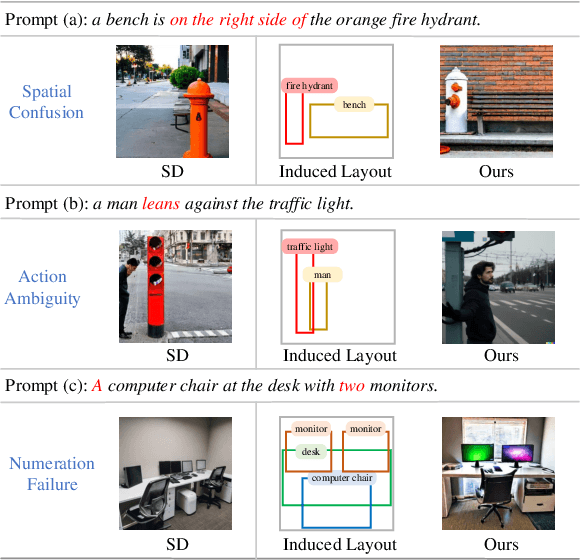
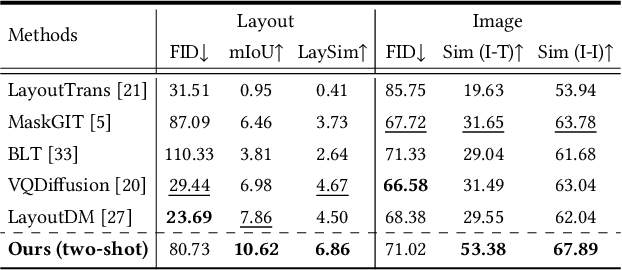
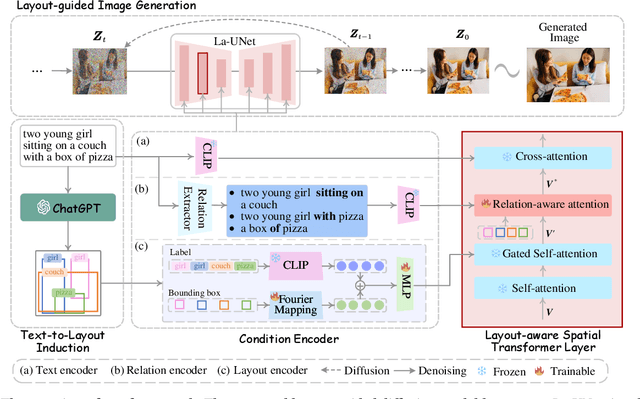

In the text-to-image generation field, recent remarkable progress in Stable Diffusion makes it possible to generate rich kinds of novel photorealistic images. However, current models still face misalignment issues (e.g., problematic spatial relation understanding and numeration failure) in complex natural scenes, which impedes the high-faithfulness text-to-image generation. Although recent efforts have been made to improve controllability by giving fine-grained guidance (e.g., sketch and scribbles), this issue has not been fundamentally tackled since users have to provide such guidance information manually. In this work, we strive to synthesize high-fidelity images that are semantically aligned with a given textual prompt without any guidance. Toward this end, we propose a coarse-to-fine paradigm to achieve layout planning and image generation. Concretely, we first generate the coarse-grained layout conditioned on a given textual prompt via in-context learning based on Large Language Models. Afterward, we propose a fine-grained object-interaction diffusion method to synthesize high-faithfulness images conditioned on the prompt and the automatically generated layout. Extensive experiments demonstrate that our proposed method outperforms the state-of-the-art models in terms of layout and image generation. Our code and settings are available at https://layoutllm-t2i.github.io.
General Debiasing for Multimodal Sentiment Analysis
Aug 07, 2023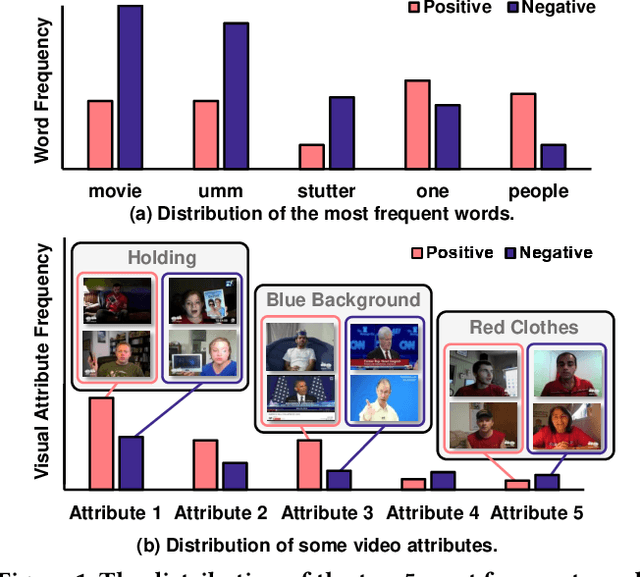

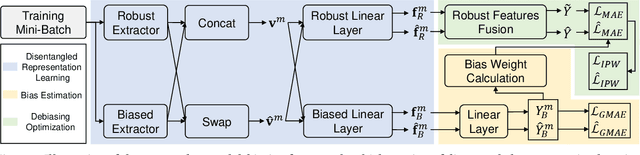
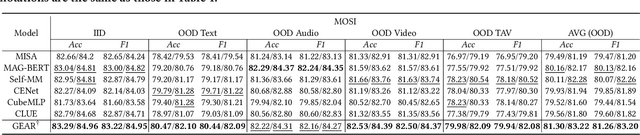
Existing work on Multimodal Sentiment Analysis (MSA) utilizes multimodal information for prediction yet unavoidably suffers from fitting the spurious correlations between multimodal features and sentiment labels. For example, if most videos with a blue background have positive labels in a dataset, the model will rely on such correlations for prediction, while "blue background" is not a sentiment-related feature. To address this problem, we define a general debiasing MSA task, which aims to enhance the Out-Of-Distribution (OOD) generalization ability of MSA models by reducing their reliance on spurious correlations. To this end, we propose a general debiasing framework based on Inverse Probability Weighting (IPW), which adaptively assigns small weights to the samples with larger bias (i.e., the severer spurious correlations). The key to this debiasing framework is to estimate the bias of each sample, which is achieved by two steps: 1) disentangling the robust features and biased features in each modality, and 2) utilizing the biased features to estimate the bias. Finally, we employ IPW to reduce the effects of large-biased samples, facilitating robust feature learning for sentiment prediction. To examine the model's generalization ability, we keep the original testing sets on two benchmarks and additionally construct multiple unimodal and multimodal OOD testing sets. The empirical results demonstrate the superior generalization ability of our proposed framework. We have released the code and data to facilitate the reproduction https://github.com/Teng-Sun/GEAR.
Semantic-Guided Feature Distillation for Multimodal Recommendation
Aug 06, 2023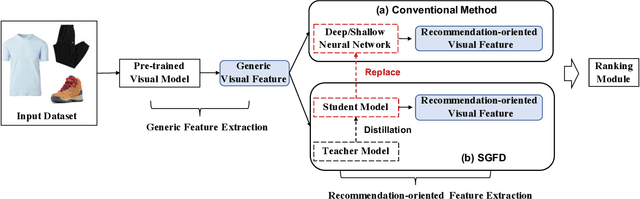
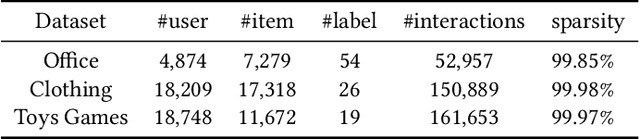
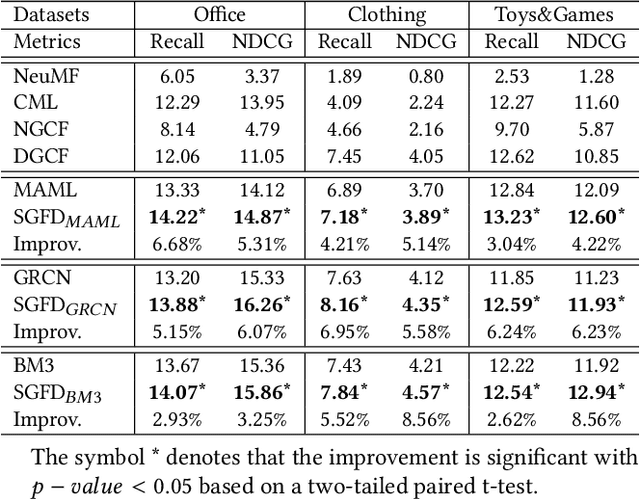
Multimodal recommendation exploits the rich multimodal information associated with users or items to enhance the representation learning for better performance. In these methods, end-to-end feature extractors (e.g., shallow/deep neural networks) are often adopted to tailor the generic multimodal features that are extracted from raw data by pre-trained models for recommendation. However, compact extractors, such as shallow neural networks, may find it challenging to extract effective information from complex and high-dimensional generic modality features. Conversely, DNN-based extractors may encounter the data sparsity problem in recommendation. To address this problem, we propose a novel model-agnostic approach called Semantic-guided Feature Distillation (SGFD), which employs a teacher-student framework to extract feature for multimodal recommendation. The teacher model first extracts rich modality features from the generic modality feature by considering both the semantic information of items and the complementary information of multiple modalities. SGFD then utilizes response-based and feature-based distillation loss to effectively transfer the knowledge encoded in the teacher model to the student model. To evaluate the effectiveness of our SGFD, we integrate SGFD into three backbone multimodal recommendation models. Extensive experiments on three public real-world datasets demonstrate that SGFD-enhanced models can achieve substantial improvement over their counterparts.
* ACM Multimedia 2023 Accepted
StyleEDL: Style-Guided High-order Attention Network for Image Emotion Distribution Learning
Aug 06, 2023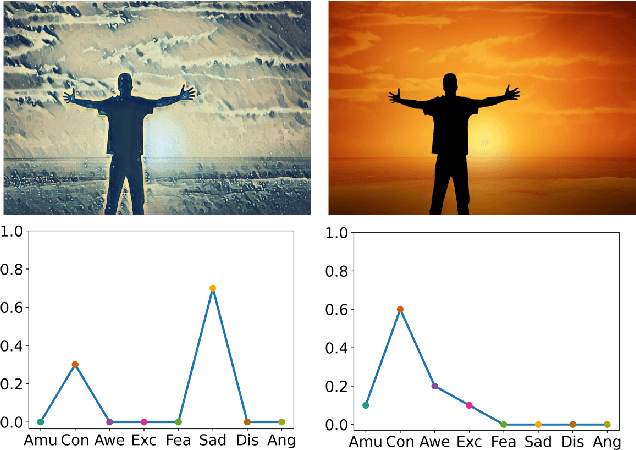
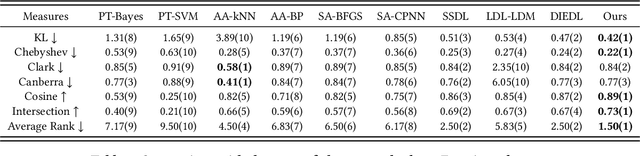
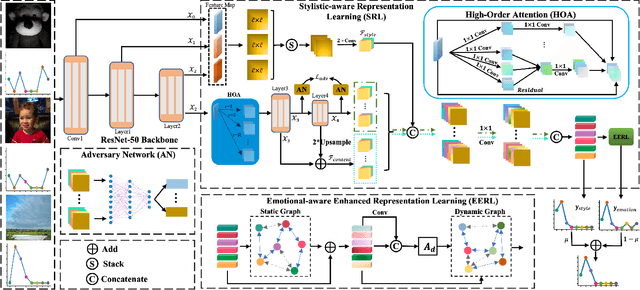
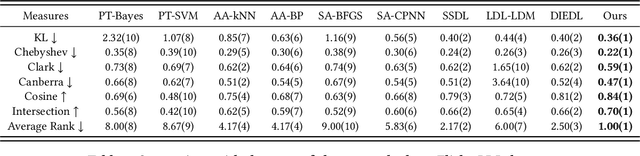
Emotion distribution learning has gained increasing attention with the tendency to express emotions through images. As for emotion ambiguity arising from humans' subjectivity, substantial previous methods generally focused on learning appropriate representations from the holistic or significant part of images. However, they rarely consider establishing connections with the stylistic information although it can lead to a better understanding of images. In this paper, we propose a style-guided high-order attention network for image emotion distribution learning termed StyleEDL, which interactively learns stylistic-aware representations of images by exploring the hierarchical stylistic information of visual contents. Specifically, we consider exploring the intra- and inter-layer correlations among GRAM-based stylistic representations, and meanwhile exploit an adversary-constrained high-order attention mechanism to capture potential interactions between subtle visual parts. In addition, we introduce a stylistic graph convolutional network to dynamically generate the content-dependent emotion representations to benefit the final emotion distribution learning. Extensive experiments conducted on several benchmark datasets demonstrate the effectiveness of our proposed StyleEDL compared to state-of-the-art methods. The implementation is released at: https://github.com/liuxianyi/StyleEDL.
Towards Generalizable Deepfake Detection by Primary Region Regularization
Jul 28, 2023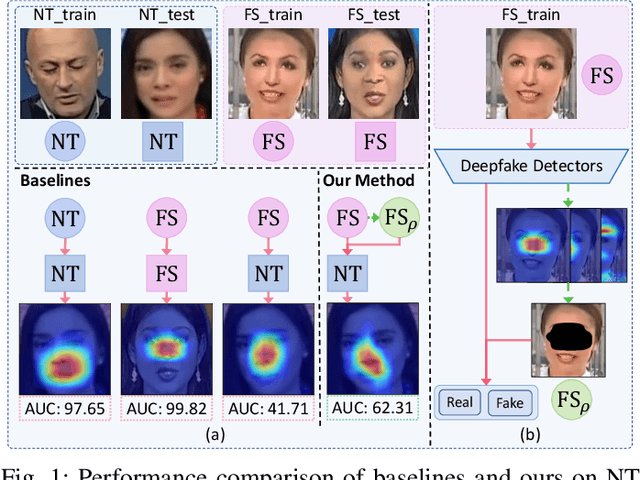
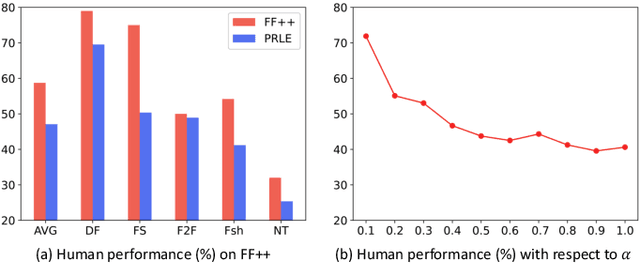
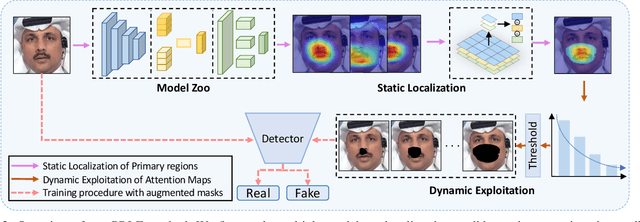
The existing deepfake detection methods have reached a bottleneck in generalizing to unseen forgeries and manipulation approaches. Based on the observation that the deepfake detectors exhibit a preference for overfitting the specific primary regions in input, this paper enhances the generalization capability from a novel regularization perspective. This can be simply achieved by augmenting the images through primary region removal, thereby preventing the detector from over-relying on data bias. Our method consists of two stages, namely the static localization for primary region maps, as well as the dynamic exploitation of primary region masks. The proposed method can be seamlessly integrated into different backbones without affecting their inference efficiency. We conduct extensive experiments over three widely used deepfake datasets - DFDC, DF-1.0, and Celeb-DF with five backbones. Our method demonstrates an average performance improvement of 6% across different backbones and performs competitively with several state-of-the-art baselines.
Sample Less, Learn More: Efficient Action Recognition via Frame Feature Restoration
Jul 27, 2023
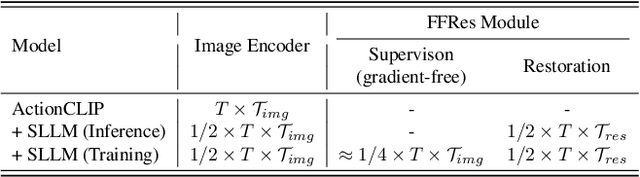

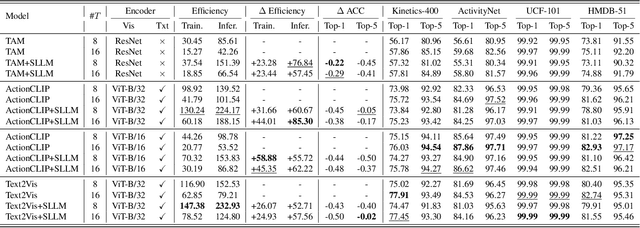
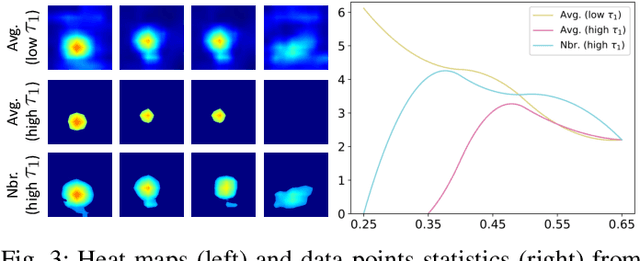
Training an effective video action recognition model poses significant computational challenges, particularly under limited resource budgets. Current methods primarily aim to either reduce model size or utilize pre-trained models, limiting their adaptability to various backbone architectures. This paper investigates the issue of over-sampled frames, a prevalent problem in many approaches yet it has received relatively little attention. Despite the use of fewer frames being a potential solution, this approach often results in a substantial decline in performance. To address this issue, we propose a novel method to restore the intermediate features for two sparsely sampled and adjacent video frames. This feature restoration technique brings a negligible increase in computational requirements compared to resource-intensive image encoders, such as ViT. To evaluate the effectiveness of our method, we conduct extensive experiments on four public datasets, including Kinetics-400, ActivityNet, UCF-101, and HMDB-51. With the integration of our method, the efficiency of three commonly used baselines has been improved by over 50%, with a mere 0.5% reduction in recognition accuracy. In addition, our method also surprisingly helps improve the generalization ability of the models under zero-shot settings.