 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTAdam: Automatic Balancing of Multiple Training Loss Terms
Jun 25, 2020
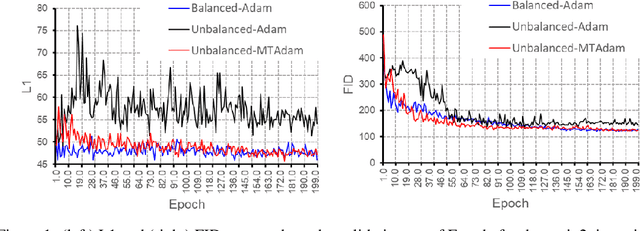

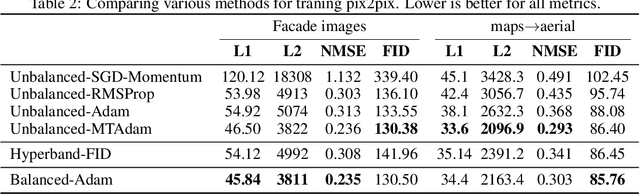
When training neural models, it is common to combine multiple loss terms. The balancing of these terms requires considerable human effort and is computationally demanding. Moreover, the optimal trade-off between the loss term can change as training progresses, especially for adversarial terms. In this work, we generalize the Adam optimization algorithm to handle multiple loss terms. The guiding principle is that for every layer, the gradient magnitude of the terms should be balanced. To this end, the Multi-Term Adam (MTAdam) computes the derivative of each loss term separately, infers the first and second moments per parameter and loss term, and calculates a first moment for the magnitude per layer of the gradients arising from each loss. This magnitude is used to continuously balance the gradients across all layers, in a manner that both varies from one layer to the next and dynamically changes over time. Our results show that training with the new method leads to fast recovery from suboptimal initial loss weighting and to training outcomes that match conventional training with the prescribed hyperparameters of each method.
Hierarchical Patch VAE-GAN: Generating Diverse Videos from a Single Sample
Jun 23, 2020

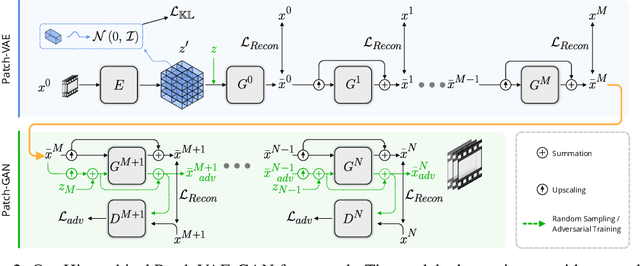

We consider the task of generating diverse and novel videos from a single video sample. Recently, new hierarchical patch-GAN based approaches were proposed for generating diverse images, given only a single sample at training time. Moving to videos, these approaches fail to generate diverse samples, and often collapse into generating samples similar to the training video. We introduce a novel patch-based variational autoencoder (VAE) which allows for a much greater diversity in generation. Using this tool, a new hierarchical video generation scheme is constructed: at coarse scales, our patch-VAE is employed, ensuring samples are of high diversity. Subsequently, at finer scales, a patch-GAN renders the fine details, resulting in high quality videos. Our experiments show that the proposed method produces diverse samples in both the image domain, and the more challenging video domain.
Wish You Were Here: Context-Aware Human Generation
May 21, 2020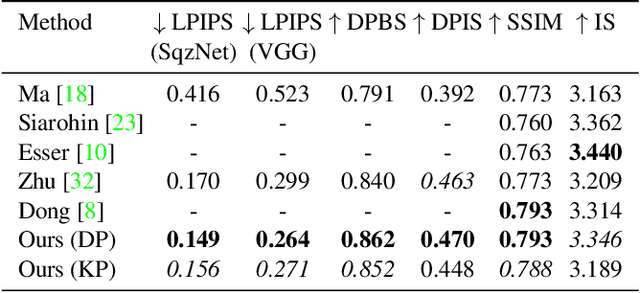
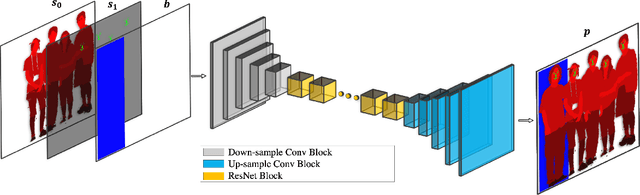
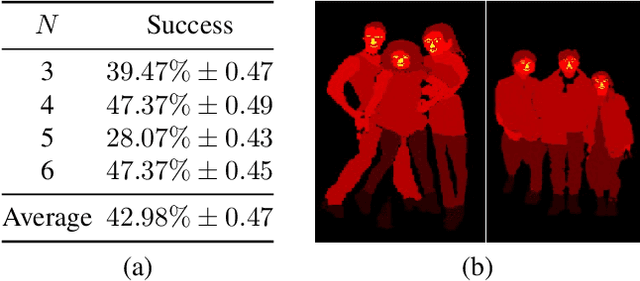
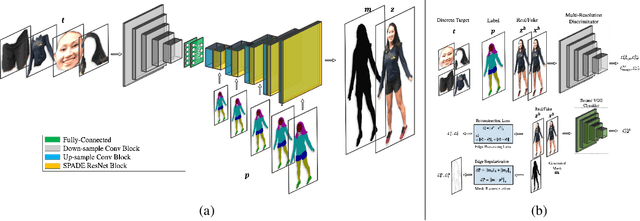
We present a novel method for inserting objects, specifically humans, into existing images, such that they blend in a photorealistic manner, while respecting the semantic context of the scene. Our method involves three subnetworks: the first generates the semantic map of the new person, given the pose of the other persons in the scene and an optional bounding box specification. The second network renders the pixels of the novel person and its blending mask, based on specifications in the form of multiple appearance components. A third network refines the generated face in order to match those of the target person. Our experiments present convincing high-resolution outputs in this novel and challenging application domain. In addition, the three networks are evaluated individually, demonstrating for example, state of the art results in pose transfer benchmarks.
Evaluation Metrics for Conditional Image Generation
Apr 26, 2020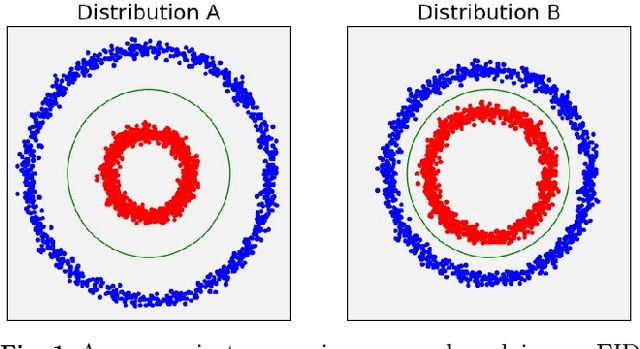
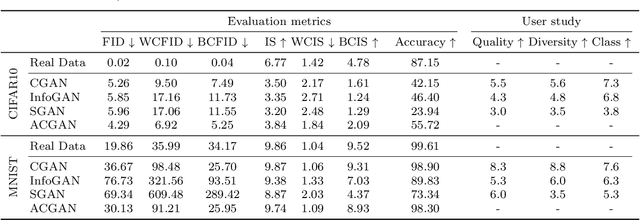
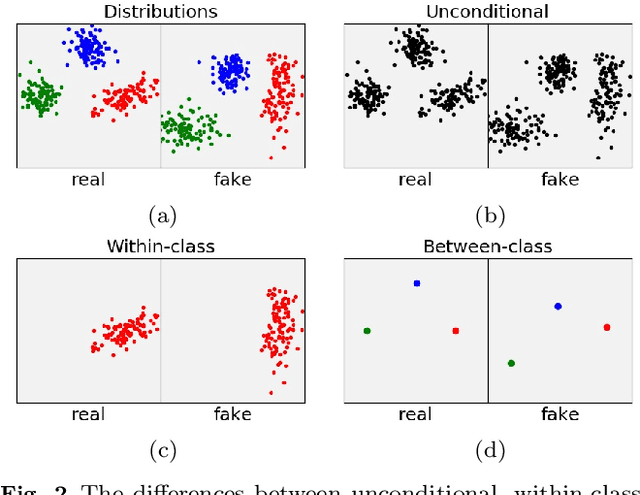
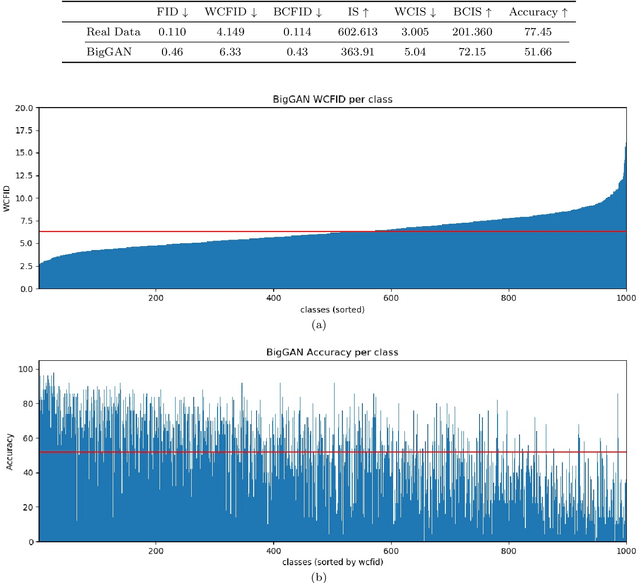
We present two new metrics for evaluating generative models in the class-conditional image generation setting. These metrics are obtained by generalizing the two most popular unconditional metrics: the Inception Score (IS) and the Fr\'{e}chet Inception Distance (FID). A theoretical analysis shows the motivation behind each proposed metric and links the novel metrics to their unconditional counterparts. The link takes the form of a product in the case of IS or an upper bound in the FID case. We provide an extensive empirical evaluation, comparing the metrics to their unconditional variants and to other metrics, and utilize them to analyze existing generative models, thus providing additional insights about their performance, from unlearned classes to mode collapse.
Structural-analogy from a Single Image Pair
Apr 16, 2020
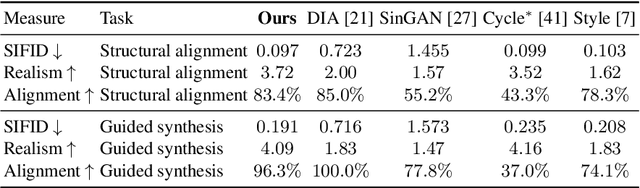
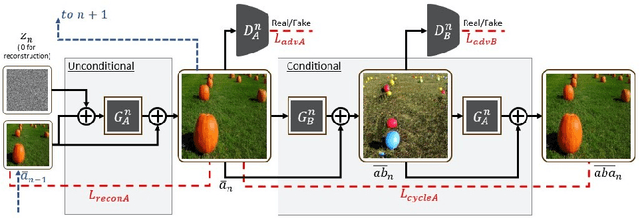
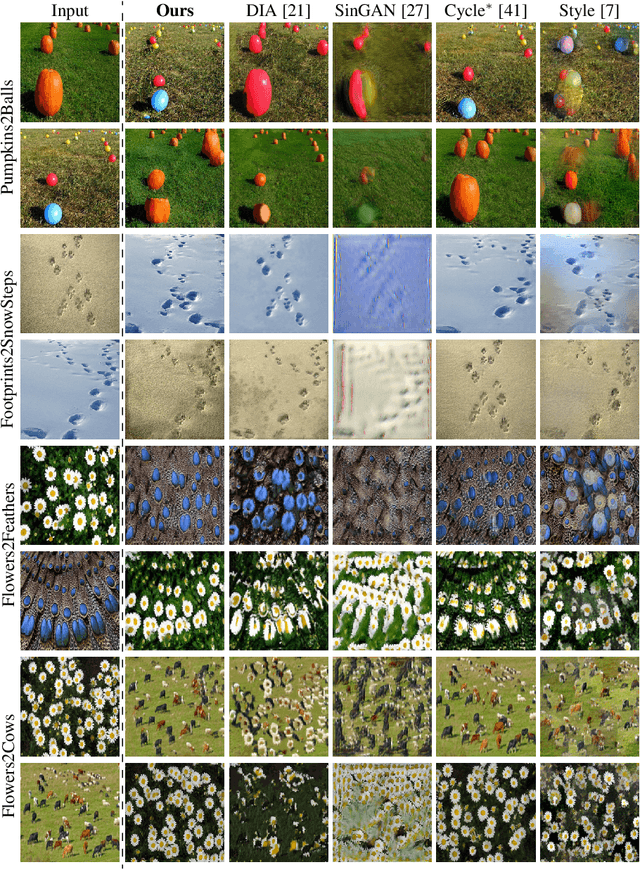
The task of unsupervised image-to-image translation has seen substantial advancements in recent years through the use of deep neural networks. Typically, the proposed solutions learn the characterizing distribution of two large, unpaired collections of images, and are able to alter the appearance of a given image, while keeping its geometry intact. In this paper, we explore the capabilities of neural networks to understand image structure given only a single pair of images, A and B. We seek to generate images that are structurally aligned: that is, to generate an image that keeps the appearance and style of B, but has a structural arrangement that corresponds to A. The key idea is to map between image patches at different scales. This enables controlling the granularity at which analogies are produced, which determines the conceptual distinction between style and content. In addition to structural alignment, our method can be used to generate high quality imagery in other conditional generation tasks utilizing images A and B only: guided image synthesis, style and texture transfer, text translation as well as video translation. Our code and additional results are available in https://github.com/rmokady/structural-analogy/.
On the Optimization Dynamics of Wide Hypernetworks
Apr 05, 2020Recent results in the theoretical study of deep learning have shown that the optimization dynamics of wide neural networks exhibit a surprisingly simple behaviour. In this work, we study the optimization dynamics of hypernetworks, which are architectures in which a learned meta-network produces the weights of a task-specific primary network. Hypernetworks have been demonstrated repeatedly to obtain state of the art results. However, their theoretical understanding is still lacking. As can be expected, the optimization process of multiplicative models is much more complicated than optimizing standard ReLU networks. It is shown that for an infinitely wide neural network with a gating layer the cost function cannot be accurately approximated by it first order Taylor approximation. Specifically, for a fixed sized primary network of depth H, the first H terms of the Taylor approximation of the cost function are non-zero, even when the meta-network is infinitely wide. However, for an infinitely wide meta and primary networks, the learning dynamics is determined by a linear model obtained from the first-order Taylor expansion of the network around its initial parameters and the kernel of this process is given by the Hadamard product of the kernels induced by the meta and primary networks. As part of our study, we partially solve an open problem suggested by Dyer & Gur-Ari (2020) and show that the convergence rate of the r order term of the Taylor expansion of the cost function, along the optimization trajectories of SGD is n^{1-r}, where n is the width of the learned neural network, improving upon the n^{-1} bound suggested by the conjecture of Dyer & Gur-Ari, while matching their empirical observations.
Voice Separation with an Unknown Number of Multiple Speakers
Feb 29, 2020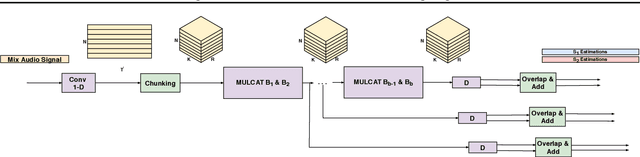
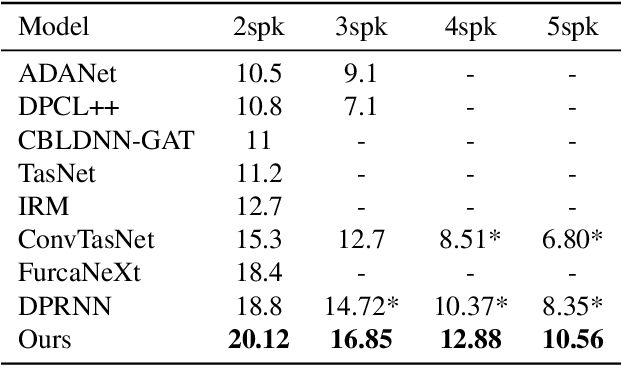

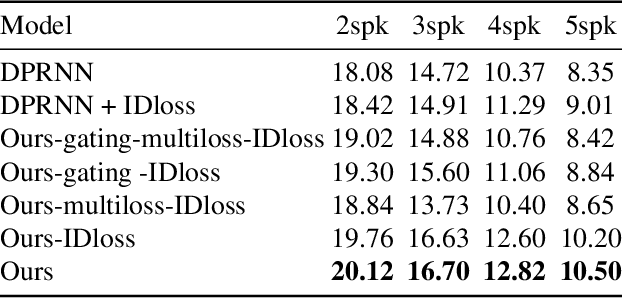
We present a new method for separating a mixed audio sequence, in which multiple voices speak simultaneously. The new method employs gated neural networks that are trained to separate the voices at multiple processing steps, while maintaining the speaker in each output channel fixed. A different model is trained for every number of possible speakers, and a the model with the largest number of speakers is employed to select the actual number of speakers in a given sample. Our method greatly outperforms the current state of the art, which, as we show, is not competitive for more than two speakers.
ScopeFlow: Dynamic Scene Scoping for Optical Flow
Feb 25, 2020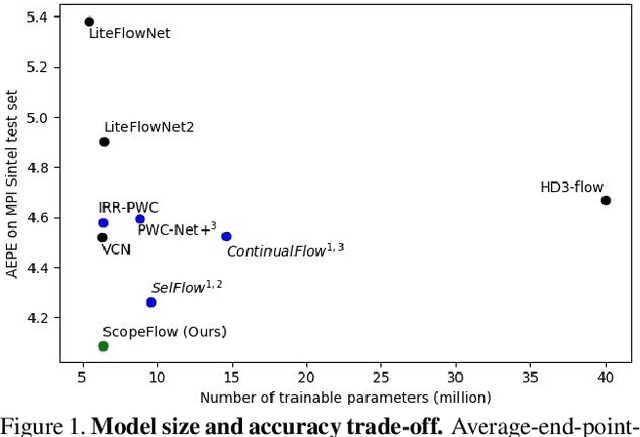

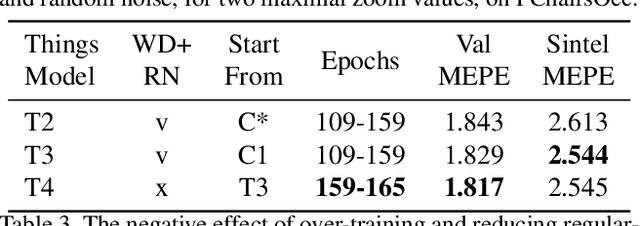
We propose to modify the common training protocols of optical flow, leading to sizable accuracy improvements without adding to the computational complexity of the training process. The improvement is based on observing the bias in sampling challenging data that exists in the current training protocol, and improving the sampling process. In addition, we find that both regularization and augmentation should decrease during the training protocol. Using a low parameters off-the-shelf model, the method is ranked first on the MPI Sintel benchmark among all other methods, improving the best two frames method accuracy by more than 10%. The method also surpasses all similar architecture variants by more than 12% and 19.7% on the KITTI benchmarks, achieving the lowest Average End-Point Error on KITTI2012 among two-frame methods, without using extra datasets.
A Critical View of the Structural Causal Model
Feb 23, 2020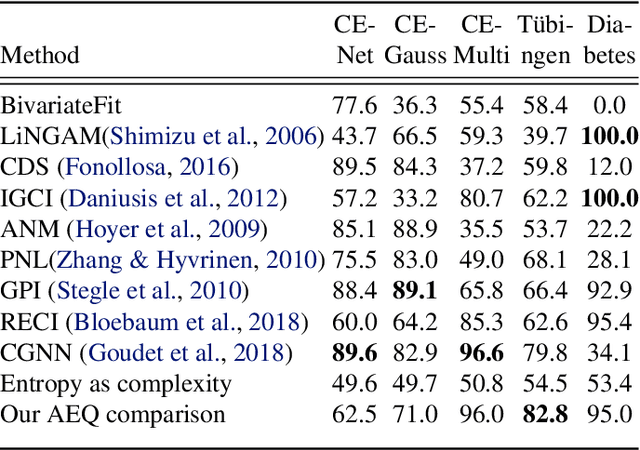
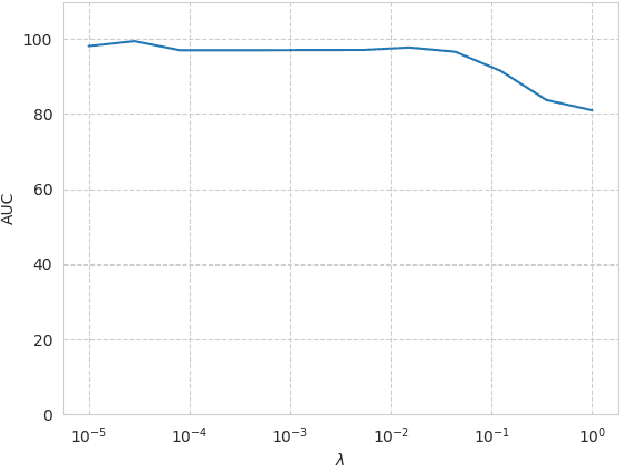
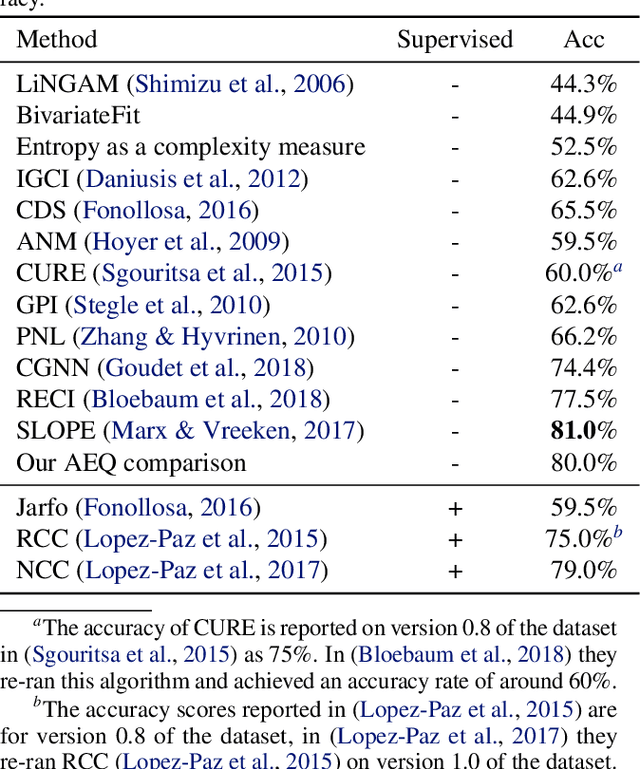
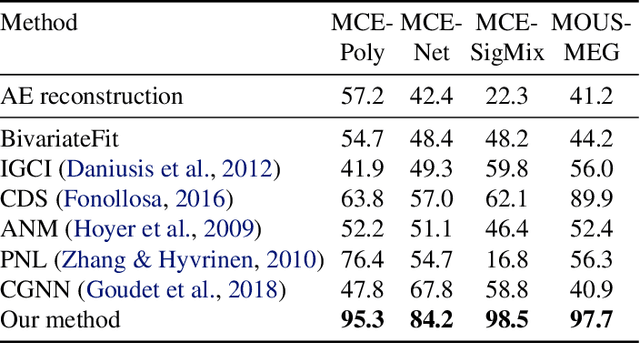
In the univariate case, we show that by comparing the individual complexities of univariate cause and effect, one can identify the cause and the effect, without considering their interaction at all. In our framework, complexities are captured by the reconstruction error of an autoencoder that operates on the quantiles of the distribution. Comparing the reconstruction errors of the two autoencoders, one for each variable, is shown to perform surprisingly well on the accepted causality directionality benchmarks. Hence, the decision as to which of the two is the cause and which is the effect may not be based on causality but on complexity. In the multivariate case, where one can ensure that the complexities of the cause and effect are balanced, we propose a new adversarial training method that mimics the disentangled structure of the causal model. We prove that in the multidimensional case, such modeling is likely to fit the data only in the direction of causality. Furthermore, a uniqueness result shows that the learned model is able to identify the underlying causal and residual (noise) components. Our multidimensional method outperforms the literature methods on both synthetic and real world datasets.
Comparing the Parameter Complexity of Hypernetworks and the Embedding-Based Alternative
Feb 23, 2020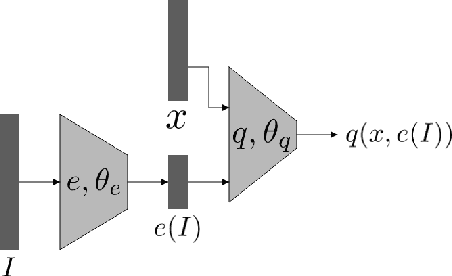
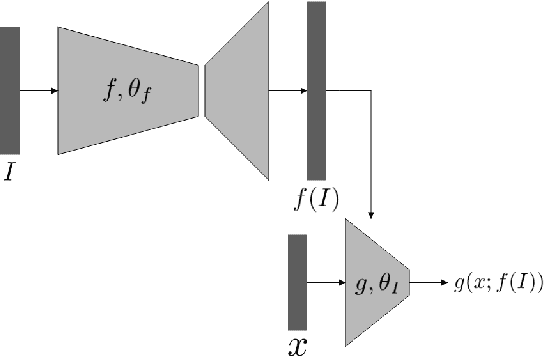
In the context of learning to map an input $I$ to a function $h_I:\mathcal{X}\to \mathbb{R}$, we compare two alternative methods: (i) an embedding-based method, which learns a fixed function in which $I$ is encoded as a conditioning signal $e(I)$ and the learned function takes the form $h_I(x) = q(x,e(I))$, and (ii) hypernetworks, in which the weights $\theta_I$ of the function $h_I(x) = g(x;\theta_I)$ are given by a hypernetwork $f$ as $\theta_I=f(I)$. We extend the theory of~\cite{devore} and provide a lower bound on the complexity of neural networks as function approximators, i.e., the number of trainable parameters. This extension, eliminates the requirements for the approximation method to be robust. Our results are then used to compare the complexities of $q$ and $g$, showing that under certain conditions and when letting the functions $e$ and $f$ be as large as we wish, $g$ can be smaller than $q$ by orders of magnitude. In addition, we show that for typical assumptions on the function to be approximated, the overall number of trainable parameters in a hypernetwork is smaller by orders of magnitude than the number of trainable parameters of a standard neural network and an embedding method.