 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingxi Xie
Identity-Enhanced Network for Facial Expression Recognition
Dec 11, 2018

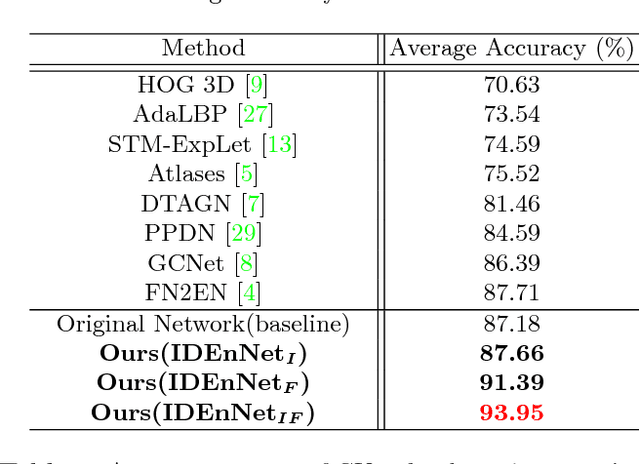
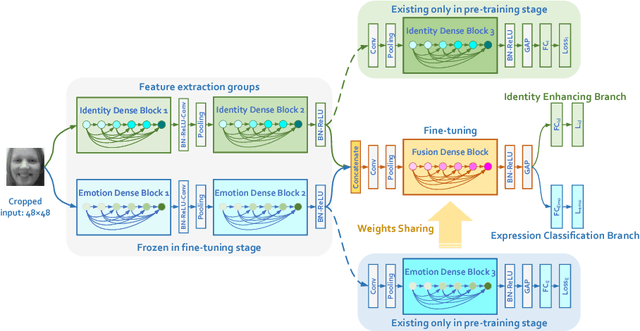
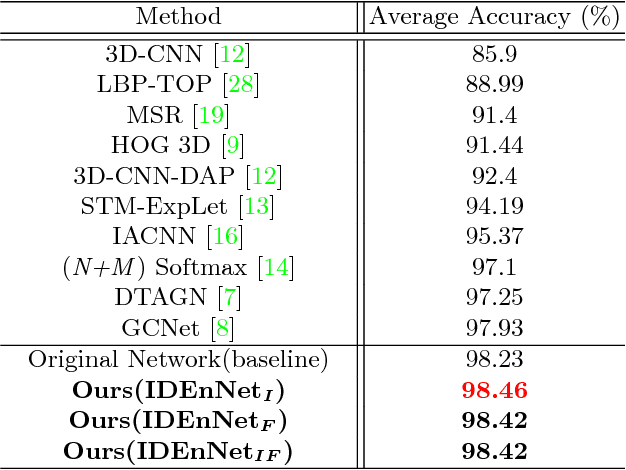
Facial expression recognition is a challenging task, arguably because of large intra-class variations and high inter-class similarities. The core drawback of the existing approaches is the lack of ability to discriminate the changes in appearance caused by emotions and identities. In this paper, we present a novel identity-enhanced network (IDEnNet) to eliminate the negative impact of identity factor and focus on recognizing facial expressions. Spatial fusion combined with self-constrained multi-task learning are adopted to jointly learn the expression representations and identity-related information. We evaluate our approach on three popular datasets, namely Oulu-CASIA, CK+ and MMI. IDEnNet improves the baseline consistently, and achieves the best or comparable state-of-the-art on all three datasets.
Attention-guided Unified Network for Panoptic Segmentation
Dec 10, 2018
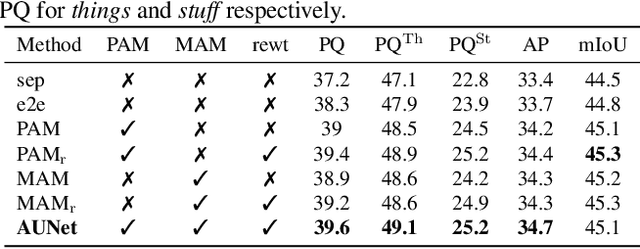
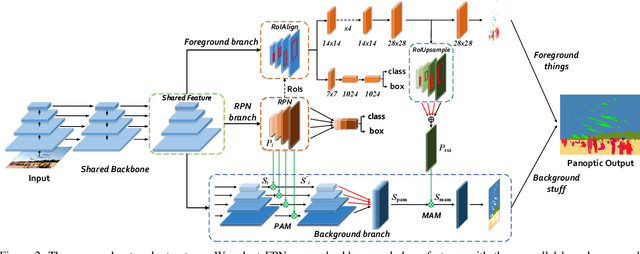
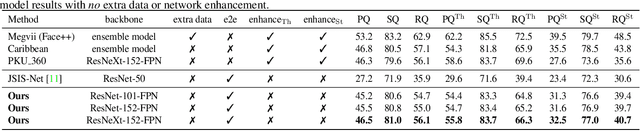
This paper studies panoptic segmentation, a recently proposed task which segments foreground (FG) objects at the instance level as well as background (BG) contents at the semantic level. Existing methods mostly dealt with these two problems separately, but in this paper, we reveal the underlying relationship between them, in particular, FG objects provide complementary cues to assist BG understanding. Our approach, named the Attention-guided Unified Network (AUNet), is an unified framework with two branches for FG and BG segmentation simultaneously. Two sources of attentions are added to the BG branch, namely, RPN and FG segmentation mask to provide object-level and pixel-level attentions, respectively. Our approach is generalized to different backbones with consistent accuracy gain in both FG and BG segmentation, and also sets new state-of-the-arts in the MS-COCO (46.5% PQ) benchmarks.
Phase Collaborative Network for Multi-Phase Medical Imaging Segmentation
Dec 06, 2018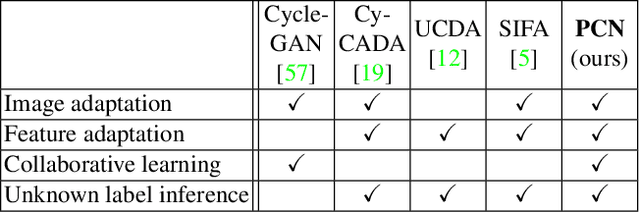
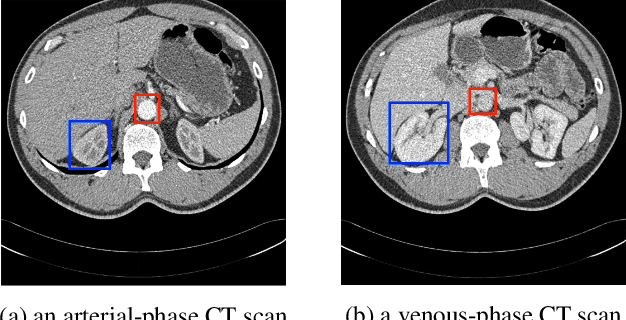
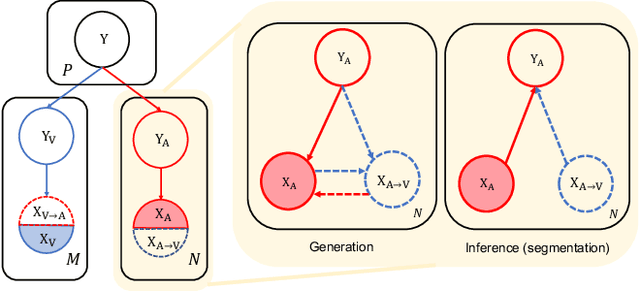
Integrating multi-phase information is an effective way of boosting visual recognition. In this paper, we investigate this problem from the perspective of medical imaging analysis, in which two phases in CT scans known as arterial and venous are combined towards higher segmentation accuracy. To this end, we propose Phase Collaborative Network (PCN), an end-to-end network which contains both generative and discriminative modules to formulate phase-to-phase relations and data-to-label relations, respectively. Experiments are performed on several CT image segmentation datasets. PCN achieves superior performance with either two phases or only one phase available. Moreover, we empirically verify that the accuracy gain comes from the collaboration between phases.
Towards Accurate Task Accomplishment with Low-Cost Robotic Arms
Dec 03, 2018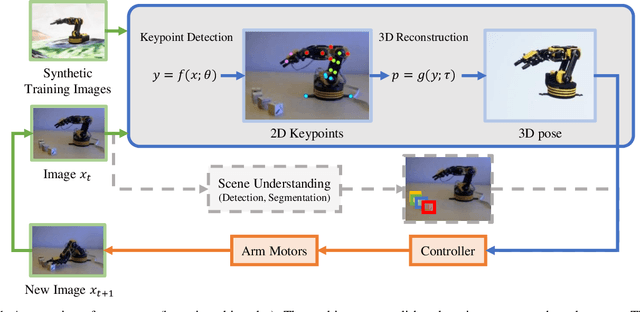
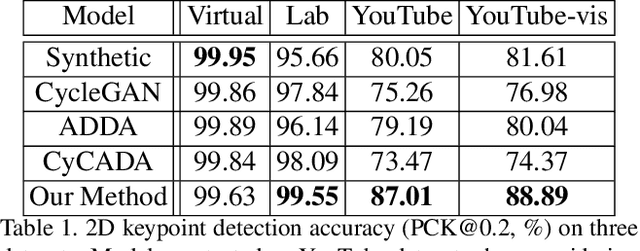
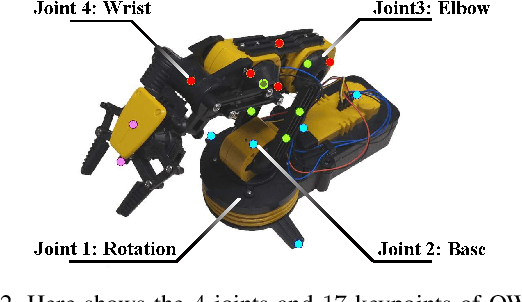
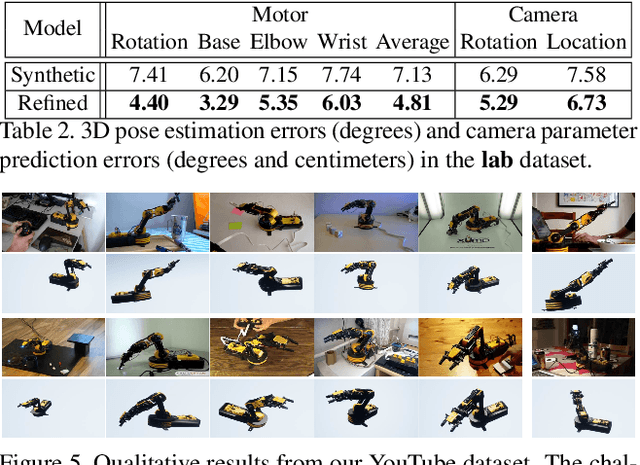
Training a robotic arm to accomplish real-world tasks has been attracting increasing attention in both academia and industry. This work discusses the role of computer vision algorithms in this field. We focus on low-cost arms on which no sensors are equipped and thus all decisions are made upon visual recognition, e.g., real-time 3D pose estimation. This requires annotating a lot of training data, which is not only time-consuming but also laborious. In this paper, we present an alternative solution, which uses a 3D model to create a large number of synthetic data, trains a vision model in this virtual domain, and applies it to real-world images after domain adaptation. To this end, we design a semi-supervised approach, which fully leverages the geometric constraints among keypoints. We apply an iterative algorithm for optimization. Without any annotations on real images, our algorithm generalizes well and produces satisfying results on 3D pose estimation, which is evaluated on two real-world datasets. We also construct a vision-based control system for task accomplishment, for which we train a reinforcement learning agent in a virtual environment and apply it to the real-world. Moreover, our approach, with merely a 3D model being required, has the potential to generalize to other types of multi-rigid-body dynamic systems.
Elastic Boundary Projection for 3D Medical Imaging Segmentation
Dec 03, 2018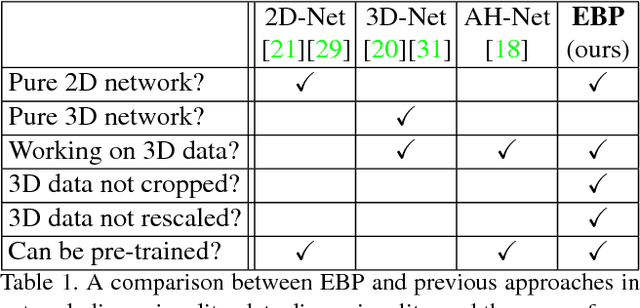
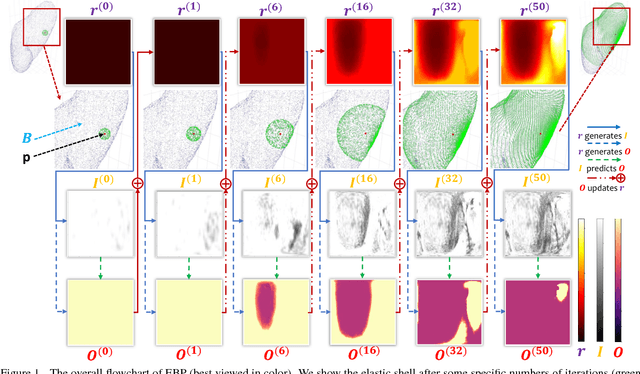

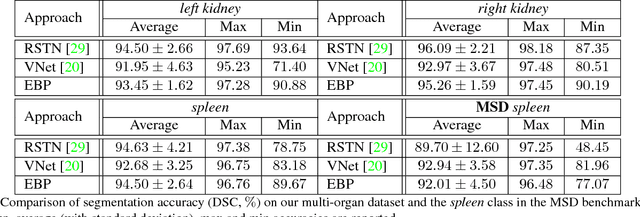
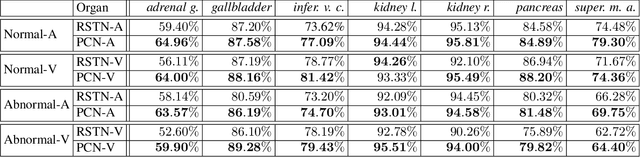
We focus on an important yet challenging problem: using a 2D deep network to deal with 3D segmentation for medical imaging analysis. Existing approaches either applied multi-view planar (2D) networks or directly used volumetric (3D) networks for this purpose, but both of them are not ideal: 2D networks cannot capture 3D contexts effectively, and 3D networks are both memory-consuming and less stable arguably due to the lack of pre-trained models. In this paper, we bridge the gap between 2D and 3D using a novel approach named Elastic Boundary Projection (EBP). The key observation is that, although the object is a 3D volume, what we really need in segmentation is to find its boundary which is a 2D surface. Therefore, we place a number of pivot points in the 3D space, and for each pivot, we determine its distance to the object boundary along a dense set of directions. This creates an elastic shell around each pivot which is initialized as a perfect sphere. We train a 2D deep network to determine whether each ending point falls within the object, and gradually adjust the shell so that it gradually converges to the actual shape of the boundary and thus achieves the goal of segmentation. EBP allows 3D segmentation without cutting the volume into slices or small patches, which stands out from conventional 2D and 3D approaches. EBP achieves promising accuracy in segmenting several abdominal organs from CT scans.
Iterative Reorganization with Weak Spatial Constraints: Solving Arbitrary Jigsaw Puzzles for Unsupervised Representation Learning
Dec 02, 2018
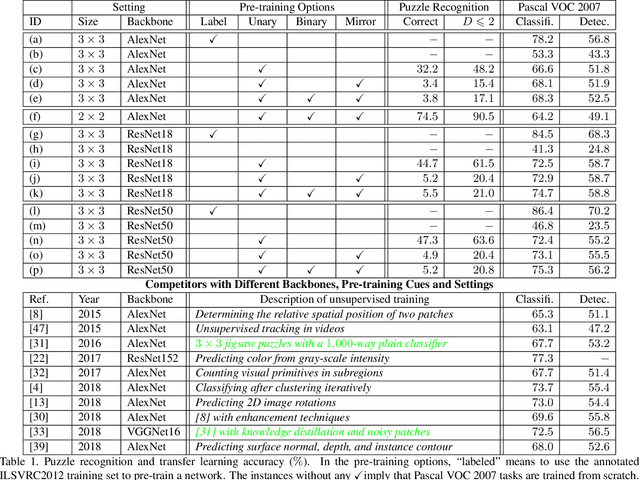
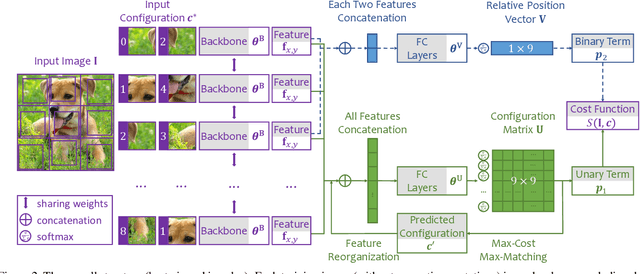
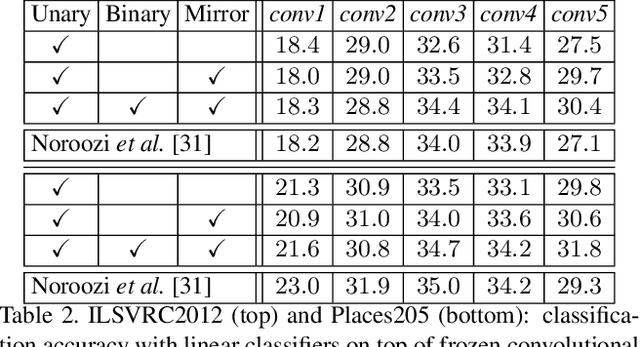
Learning visual features from unlabeled image data is an important yet challenging task, which is often achieved by training a model on some annotation-free information. We consider spatial contexts, for which we solve so-called jigsaw puzzles, i.e., each image is cut into grids and then disordered, and the goal is to recover the correct configuration. Existing approaches formulated it as a classification task by defining a fixed mapping from a small subset of configurations to a class set, but these approaches ignore the underlying relationship between different configurations and also limit their application to more complex scenarios. This paper presents a novel approach which applies to jigsaw puzzles with an arbitrary grid size and dimensionality. We provide a fundamental and generalized principle, that weaker cues are easier to be learned in an unsupervised manner and also transfer better. In the context of puzzle recognition, we use an iterative manner which, instead of solving the puzzle all at once, adjusts the order of the patches in each step until convergence. In each step, we combine both unary and binary features on each patch into a cost function judging the correctness of the current configuration. Our approach, by taking similarity between puzzles into consideration, enjoys a more reasonable way of learning visual knowledge. We verify the effectiveness of our approach in two aspects. First, it is able to solve arbitrarily complex puzzles, including high-dimensional puzzles, that prior methods are difficult to handle. Second, it serves as a reliable way of network initialization, which leads to better transfer performance in a few visual recognition tasks including image classification, object detection, and semantic segmentation.
Snapshot Distillation: Teacher-Student Optimization in One Generation
Dec 01, 2018
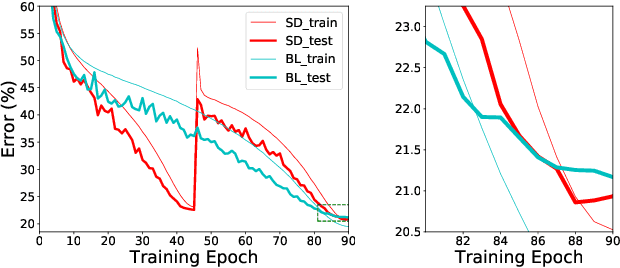
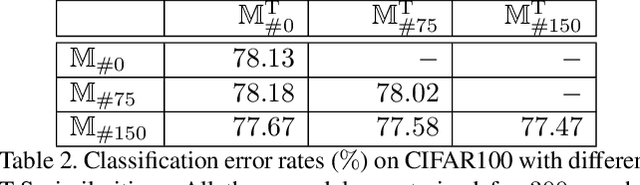
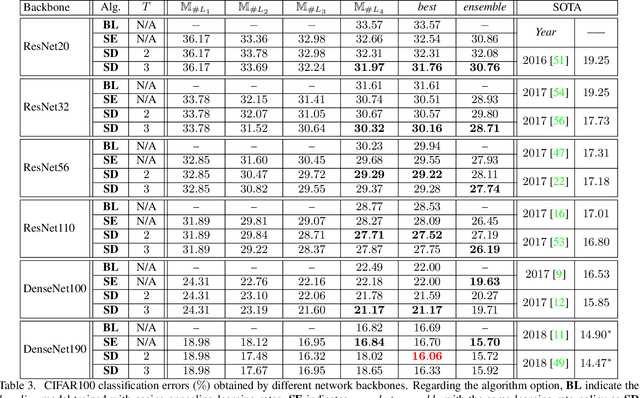
Optimizing a deep neural network is a fundamental task in computer vision, yet direct training methods often suffer from over-fitting. Teacher-student optimization aims at providing complementary cues from a model trained previously, but these approaches are often considerably slow due to the pipeline of training a few generations in sequence, i.e., time complexity is increased by several times. This paper presents snapshot distillation (SD), the first framework which enables teacher-student optimization in one generation. The idea of SD is very simple: instead of borrowing supervision signals from previous generations, we extract such information from earlier epochs in the same generation, meanwhile make sure that the difference between teacher and student is sufficiently large so as to prevent under-fitting. To achieve this goal, we implement SD in a cyclic learning rate policy, in which the last snapshot of each cycle is used as the teacher for all iterations in the next cycle, and the teacher signal is smoothed to provide richer information. In standard image classification benchmarks such as CIFAR100 and ILSVRC2012, SD achieves consistent accuracy gain without heavy computational overheads. We also verify that models pre-trained with SD transfers well to object detection and semantic segmentation in the PascalVOC dataset.
Progressive Recurrent Learning for Visual Recognition
Nov 29, 2018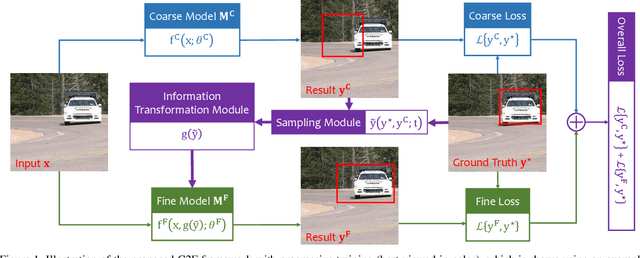
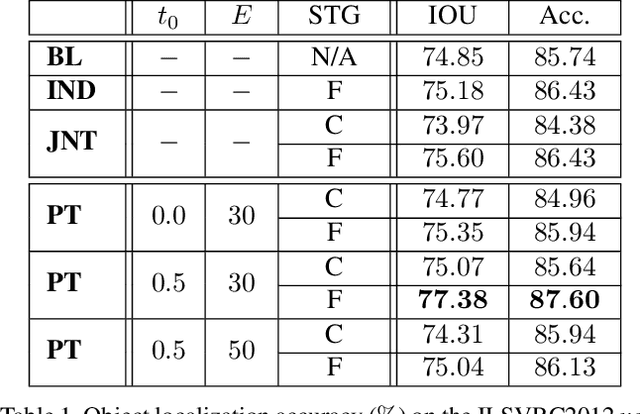

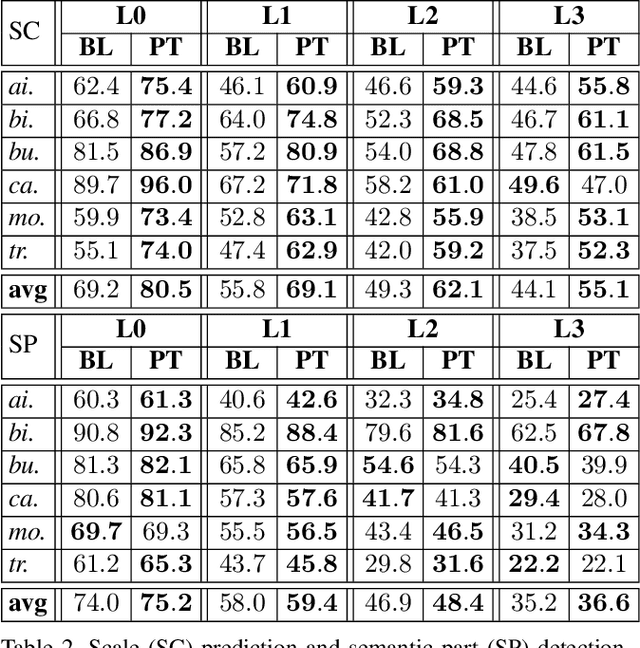
Computer vision is difficult, partly because the mathematical function connecting input and output data is often complex, fuzzy and thus hard to learn. A currently popular solution is to design a deep neural network and optimize it on a large-scale dataset. However, as the number of parameters increases, the generalization ability is often not guaranteed, e.g., the model can over-fit due to the limited amount of training data, or fail to converge because the desired function is too difficult to learn. This paper presents an effective framework named progressive recurrent learning (PRL). The core idea is similar to curriculum learning which gradually increases the difficulty of training data. We generalize it to a wide range of vision problems that were previously considered less proper to apply curriculum learning. PRL starts with inserting a recurrent prediction scheme, based on the motivation of feeding the prediction of a vision model to the same model iteratively, so that the auxiliary cues contained in it can be exploited to improve the quality of itself. In order to better optimize this framework, we start with providing perfect prediction, i.e., ground-truth, to the second stage, but gradually replace it with the prediction of the first stage. In the final status, the ground-truth information is not needed any more, so that the entire model works on the real data distribution as in the testing process. We apply PRL to two challenging visual recognition tasks, namely, object localization and semantic segmentation, and demonstrate consistent accuracy gain compared to the baseline training strategy, especially in the scenarios of more difficult vision tasks.
Semantic Part Detection via Matching: Learning to Generalize to Novel Viewpoints from Limited Training Data
Nov 28, 2018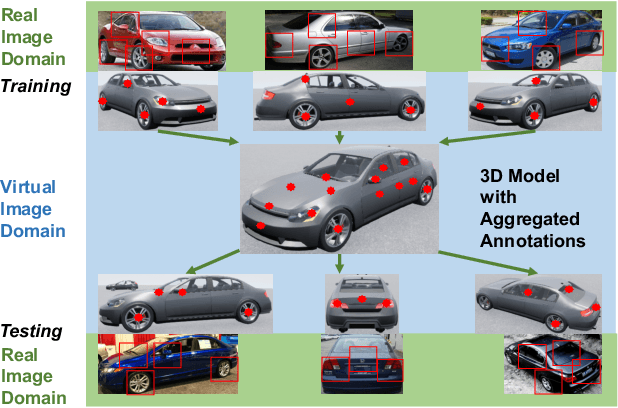


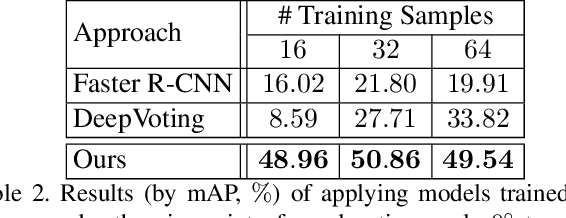
Detecting semantic parts of an object is a challenging task in computer vision, particularly because it is hard to construct large annotated datasets due to the difficulty of annotating semantic parts. In this paper we present an approach which learns from a small training dataset of annotated semantic parts, where the object is seen from a limited range of viewpoints, but generalizes to detect semantic parts from a much larger range of viewpoints. Our approach is based on a matching algorithm for finding accurate spatial correspondence between two images, which enables semantic parts annotated on one image to be transplanted to another. In particular, this enables images in the training dataset to be matched to a virtual 3D model of the object (for simplicity, we assume that the object viewpoint can be estimated by standard techniques). Then a clustering algorithm is used to annotate the semantic parts of the 3D virtual model. This virtual 3D model can be used to synthesize annotated images from a large range of viewpoint. These can be matched to images in the test set, using the same matching algorithm, to detect semantic parts in novel viewpoints of the object. Our algorithm is very simple, intuitive, and contains very few parameters. We evaluate our approach in the car subclass of the VehicleSemanticPart dataset. We show it outperforms standard deep network approaches and, in particular, performs much better on novel viewpoints.
Adversarial Attacks Beyond the Image Space
Sep 10, 2018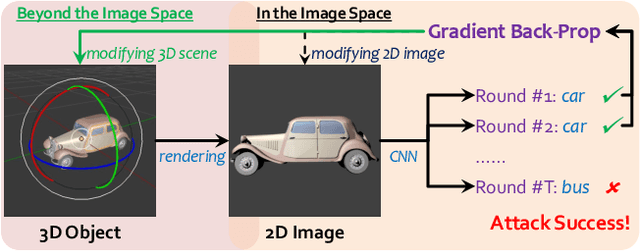



Generating adversarial examples is an intriguing problem and an important way of understanding the working mechanism of deep neural networks. Most existing approaches generated perturbations in the image space, i.e., each pixel can be modified independently. However, in this paper we pay special attention to the subset of adversarial examples that are physically authentic -- those corresponding to actual changes in 3D physical properties (like surface normals, illumination condition, etc.). These adversaries arguably pose a more serious concern, as they demonstrate the possibility of causing neural network failure by small perturbations of real-world 3D objects and scenes. In the contexts of object classification and visual question answering, we augment state-of-the-art deep neural networks that receive 2D input images with a rendering module (either differentiable or not) in front, so that a 3D scene (in the physical space) is rendered into a 2D image (in the image space), and then mapped to a prediction (in the output space). The adversarial perturbations can now go beyond the image space, and have clear meanings in the 3D physical world. Through extensive experiments, we found that a vast majority of image-space adversaries cannot be explained by adjusting parameters in the physical space, i.e., they are usually physically inauthentic. But it is still possible to successfully attack beyond the image space on the physical space (such that authenticity is enforced), though this is more difficult than image-space attacks, reflected in lower success rates and heavier perturbations required.