 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLi Jiang
Guided Point Contrastive Learning for Semi-supervised Point Cloud Semantic Segmentation
Oct 15, 2021

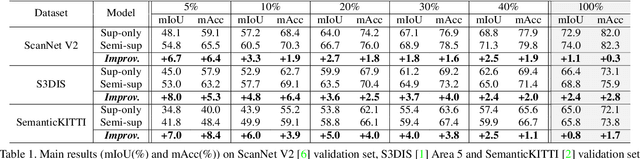
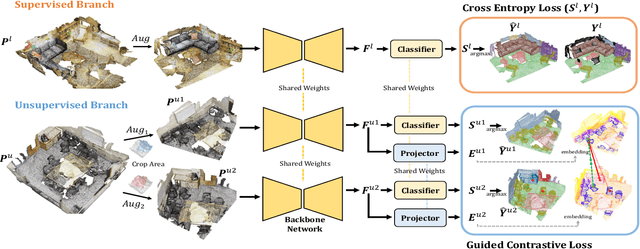
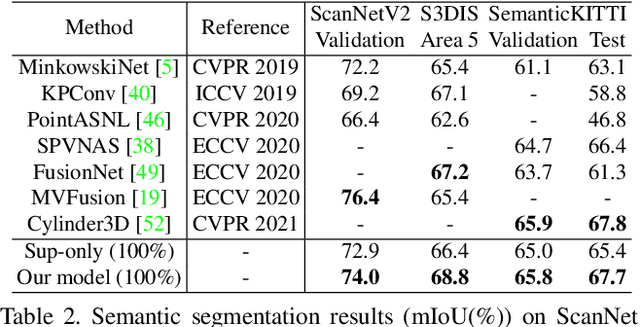
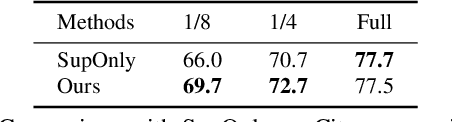
Rapid progress in 3D semantic segmentation is inseparable from the advances of deep network models, which highly rely on large-scale annotated data for training. To address the high cost and challenges of 3D point-level labeling, we present a method for semi-supervised point cloud semantic segmentation to adopt unlabeled point clouds in training to boost the model performance. Inspired by the recent contrastive loss in self-supervised tasks, we propose the guided point contrastive loss to enhance the feature representation and model generalization ability in semi-supervised setting. Semantic predictions on unlabeled point clouds serve as pseudo-label guidance in our loss to avoid negative pairs in the same category. Also, we design the confidence guidance to ensure high-quality feature learning. Besides, a category-balanced sampling strategy is proposed to collect positive and negative samples to mitigate the class imbalance problem. Extensive experiments on three datasets (ScanNet V2, S3DIS, and SemanticKITTI) show the effectiveness of our semi-supervised method to improve the prediction quality with unlabeled data.
Semi-supervised Semantic Segmentation with Directional Context-aware Consistency
Jun 27, 2021
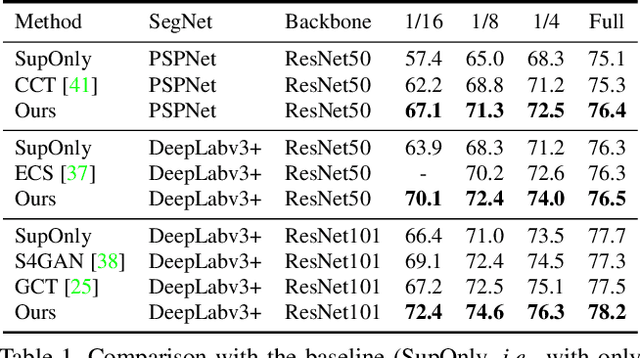
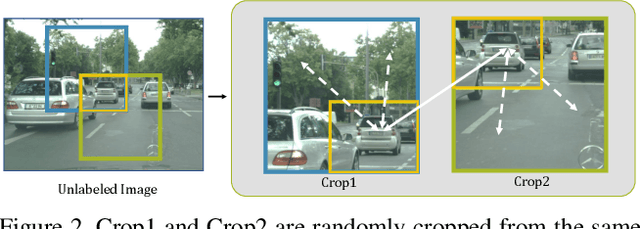
Semantic segmentation has made tremendous progress in recent years. However, satisfying performance highly depends on a large number of pixel-level annotations. Therefore, in this paper, we focus on the semi-supervised segmentation problem where only a small set of labeled data is provided with a much larger collection of totally unlabeled images. Nevertheless, due to the limited annotations, models may overly rely on the contexts available in the training data, which causes poor generalization to the scenes unseen before. A preferred high-level representation should capture the contextual information while not losing self-awareness. Therefore, we propose to maintain the context-aware consistency between features of the same identity but with different contexts, making the representations robust to the varying environments. Moreover, we present the Directional Contrastive Loss (DC Loss) to accomplish the consistency in a pixel-to-pixel manner, only requiring the feature with lower quality to be aligned towards its counterpart. In addition, to avoid the false-negative samples and filter the uncertain positive samples, we put forward two sampling strategies. Extensive experiments show that our simple yet effective method surpasses current state-of-the-art methods by a large margin and also generalizes well with extra image-level annotations.
AppealNet: An Efficient and Highly-Accurate Edge/Cloud Collaborative Architecture for DNN Inference
May 12, 2021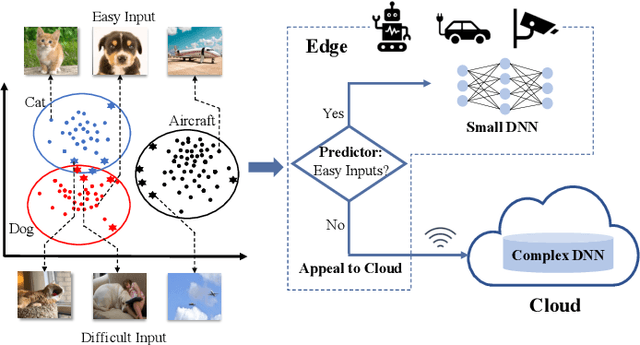
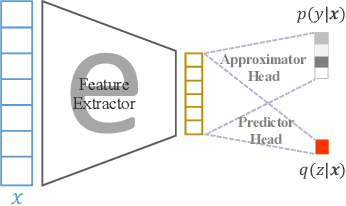
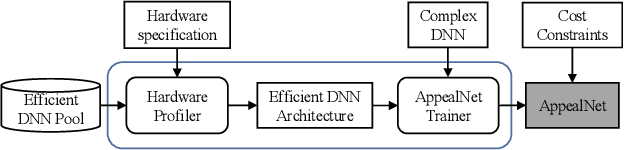
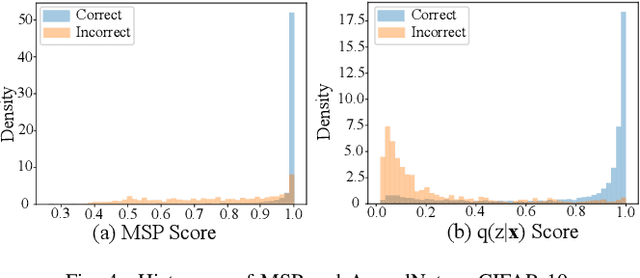
This paper presents AppealNet, a novel edge/cloud collaborative architecture that runs deep learning (DL) tasks more efficiently than state-of-the-art solutions. For a given input, AppealNet accurately predicts on-the-fly whether it can be successfully processed by the DL model deployed on the resource-constrained edge device, and if not, appeals to the more powerful DL model deployed at the cloud. This is achieved by employing a two-head neural network architecture that explicitly takes inference difficulty into consideration and optimizes the tradeoff between accuracy and computation/communication cost of the edge/cloud collaborative architecture. Experimental results on several image classification datasets show up to more than 40% energy savings compared to existing techniques without sacrificing accuracy.
Skimming and Scanning for Untrimmed Video Action Recognition
Apr 21, 2021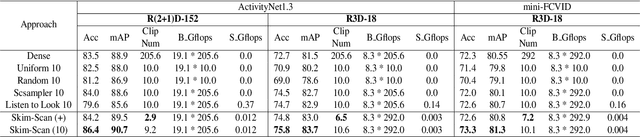
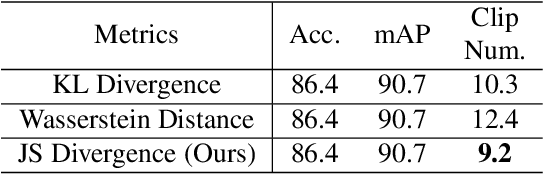
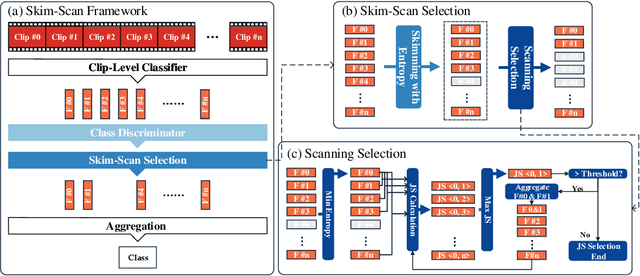
Video action recognition (VAR) is a primary task of video understanding, and untrimmed videos are more common in real-life scenes. Untrimmed videos have redundant and diverse clips containing contextual information, so sampling dense clips is essential. Recently, some works attempt to train a generic model to select the N most representative clips. However, it is difficult to model the complex relations from intra-class clips and inter-class videos within a single model and fixed selected number, and the entanglement of multiple relations is also hard to explain. Thus, instead of "only look once", we argue "divide and conquer" strategy will be more suitable in untrimmed VAR. Inspired by the speed reading mechanism, we propose a simple yet effective clip-level solution based on skim-scan techniques. Specifically, the proposed Skim-Scan framework first skims the entire video and drops those uninformative and misleading clips. For the remaining clips, it scans clips with diverse features gradually to drop redundant clips but cover essential content. The above strategies can adaptively select the necessary clips according to the difficulty of the different videos. To trade off the computational complexity and performance, we observe the similar statistical expression between lightweight and heavy networks, thus it supports us to explore the combination of them. Comprehensive experiments are performed on ActivityNet and mini-FCVID datasets, and results demonstrate that our solution surpasses the state-of-the-art performance in terms of both accuracy and efficiency.
SE-SSD: Self-Ensembling Single-Stage Object Detector From Point Cloud
Apr 20, 2021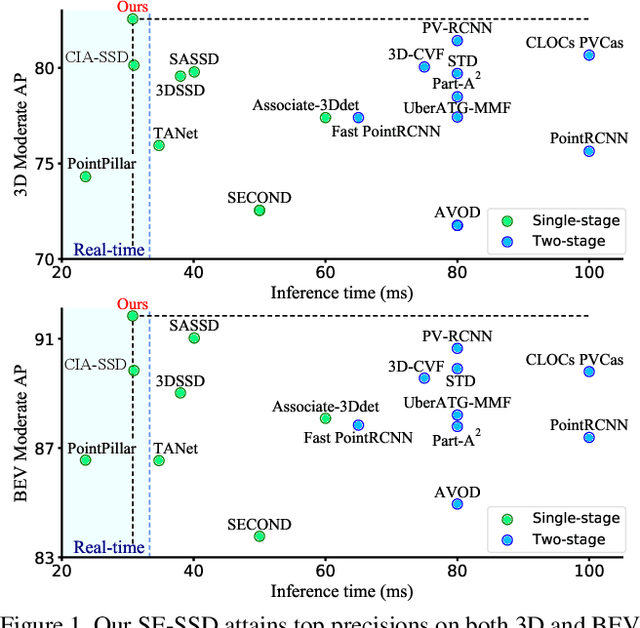
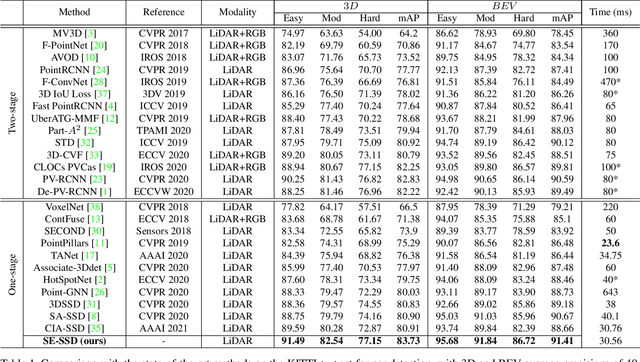
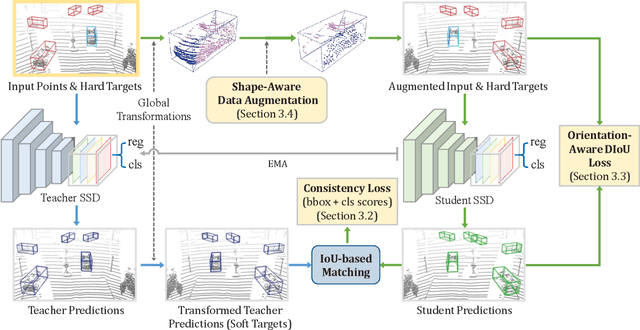
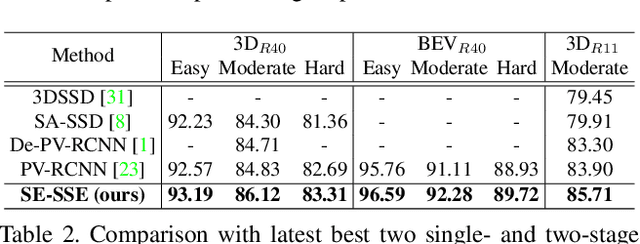
We present Self-Ensembling Single-Stage object Detector (SE-SSD) for accurate and efficient 3D object detection in outdoor point clouds. Our key focus is on exploiting both soft and hard targets with our formulated constraints to jointly optimize the model, without introducing extra computation in the inference. Specifically, SE-SSD contains a pair of teacher and student SSDs, in which we design an effective IoU-based matching strategy to filter soft targets from the teacher and formulate a consistency loss to align student predictions with them. Also, to maximize the distilled knowledge for ensembling the teacher, we design a new augmentation scheme to produce shape-aware augmented samples to train the student, aiming to encourage it to infer complete object shapes. Lastly, to better exploit hard targets, we design an ODIoU loss to supervise the student with constraints on the predicted box centers and orientations. Our SE-SSD attains top performance compared with all prior published works. Also, it attains top precisions for car detection in the KITTI benchmark (ranked 1st and 2nd on the BEV and 3D leaderboards, respectively) with an ultra-high inference speed. The code is available at https://github.com/Vegeta2020/SE-SSD.
Bidirectional Projection Network for Cross Dimension Scene Understanding
Mar 26, 2021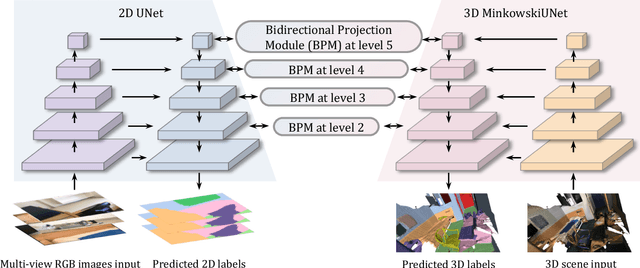
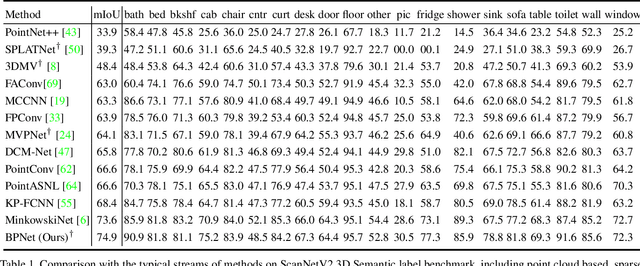
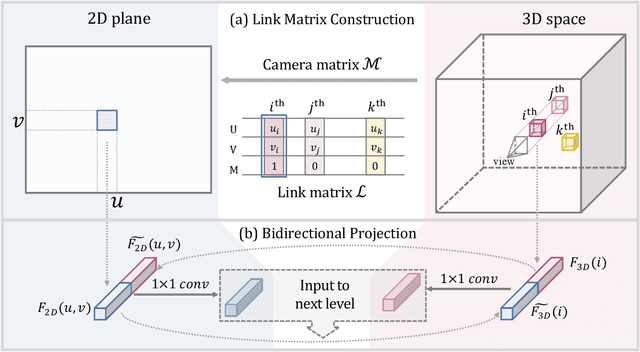
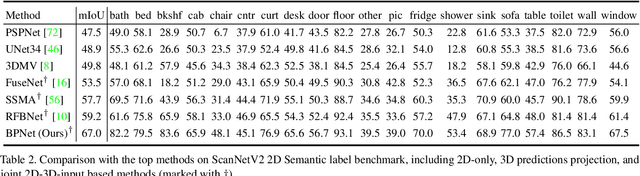
2D image representations are in regular grids and can be processed efficiently, whereas 3D point clouds are unordered and scattered in 3D space. The information inside these two visual domains is well complementary, e.g., 2D images have fine-grained texture while 3D point clouds contain plentiful geometry information. However, most current visual recognition systems process them individually. In this paper, we present a \emph{bidirectional projection network (BPNet)} for joint 2D and 3D reasoning in an end-to-end manner. It contains 2D and 3D sub-networks with symmetric architectures, that are connected by our proposed \emph{bidirectional projection module (BPM)}. Via the \emph{BPM}, complementary 2D and 3D information can interact with each other in multiple architectural levels, such that advantages in these two visual domains can be combined for better scene recognition. Extensive quantitative and qualitative experimental evaluations show that joint reasoning over 2D and 3D visual domains can benefit both 2D and 3D scene understanding simultaneously. Our \emph{BPNet} achieves top performance on the ScanNetV2 benchmark for both 2D and 3D semantic segmentation. Code is available at \url{https://github.com/wbhu/BPNet}.
* CVPR 2021 (Oral)
SME: ReRAM-based Sparse-Multiplication-Engine to Squeeze-Out Bit Sparsity of Neural Network
Mar 02, 2021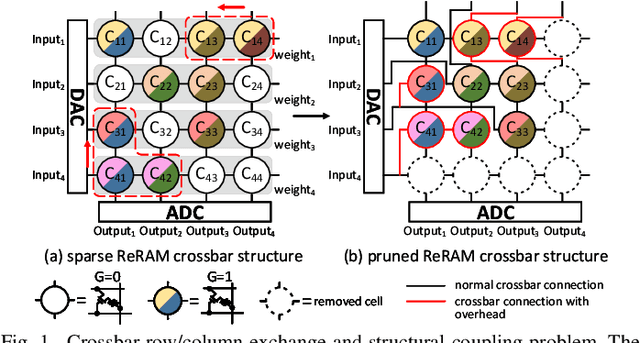
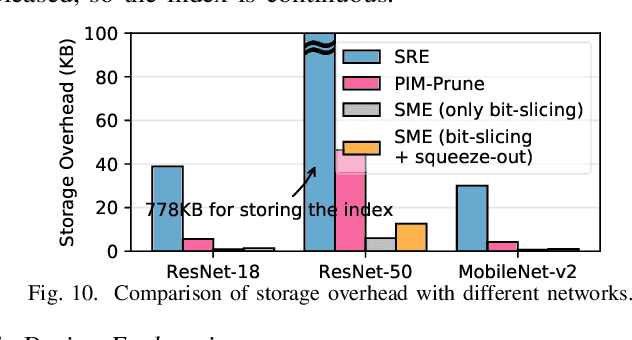
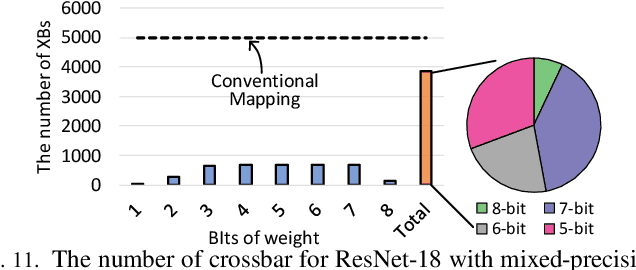
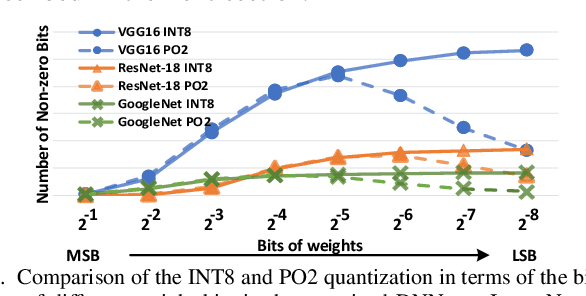
Resistive Random-Access-Memory (ReRAM) crossbar is a promising technique for deep neural network (DNN) accelerators, thanks to its in-memory and in-situ analog computing abilities for Vector-Matrix Multiplication-and-Accumulations (VMMs). However, it is challenging for crossbar architecture to exploit the sparsity in the DNN. It inevitably causes complex and costly control to exploit fine-grained sparsity due to the limitation of tightly-coupled crossbar structure. As the countermeasure, we developed a novel ReRAM-based DNN accelerator, named Sparse-Multiplication-Engine (SME), based on a hardware and software co-design framework. First, we orchestrate the bit-sparse pattern to increase the density of bit-sparsity based on existing quantization methods. Second, we propose a novel weigh mapping mechanism to slice the bits of a weight across the crossbars and splice the activation results in peripheral circuits. This mechanism can decouple the tightly-coupled crossbar structure and cumulate the sparsity in the crossbar. Finally, a superior squeeze-out scheme empties the crossbars mapped with highly-sparse non-zeros from the previous two steps. We design the SME architecture and discuss its use for other quantization methods and different ReRAM cell technologies. Compared with prior state-of-the-art designs, the SME shrinks the use of crossbars up to 8.7x and 2.1x using Resent-50 and MobileNet-v2, respectively, with less than 0.3% accuracy drop on ImageNet.
PV-RCNN++: Point-Voxel Feature Set Abstraction With Local Vector Representation for 3D Object Detection
Jan 31, 2021
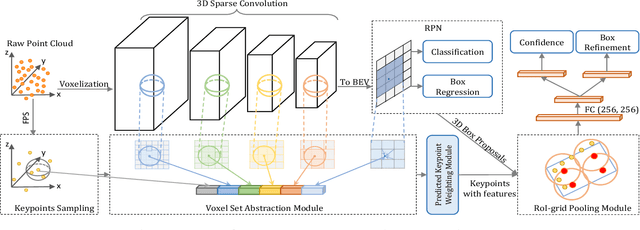
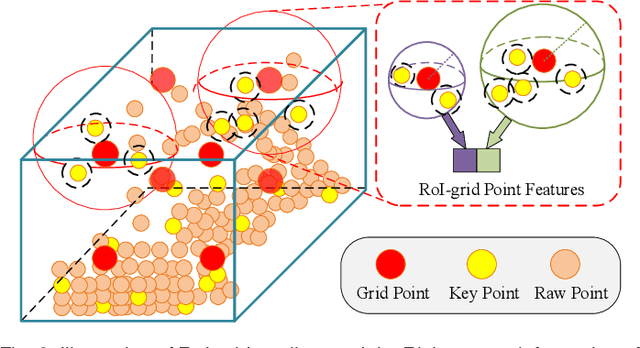

3D object detection is receiving increasing attention from both industry and academia thanks to its wide applications in various fields. In this paper, we propose the Point-Voxel Region based Convolution Neural Networks (PV-RCNNs) for accurate 3D detection from point clouds. First, we propose a novel 3D object detector, PV-RCNN-v1, which employs the voxel-to-keypoint scene encoding and keypoint-to-grid RoI feature abstraction two novel steps. These two steps deeply incorporate both 3D voxel CNN and PointNet-based set abstraction for learning discriminative point-cloud features. Second, we propose a more advanced framework, PV-RCNN-v2, for more efficient and accurate 3D detection. It consists of two major improvements, where the first one is the sectorized proposal-centric strategy for efficiently producing more representative and uniformly distributed keypoints, and the second one is the VectorPool aggregation to replace set abstraction for better aggregating local point-cloud features with much less resource consumption. With these two major modifications, our PV-RCNN-v2 runs more than twice as fast as the v1 version while still achieving better performance on the large-scale Waymo Open Dataset with 150m * 150m detection range. Extensive experiments demonstrate that our proposed PV-RCNNs significantly outperform previous state-of-the-art 3D detection methods on both the Waymo Open Dataset and the highly-competitive KITTI benchmark.
Point Transformer
Dec 16, 2020
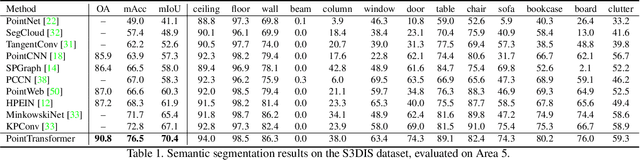
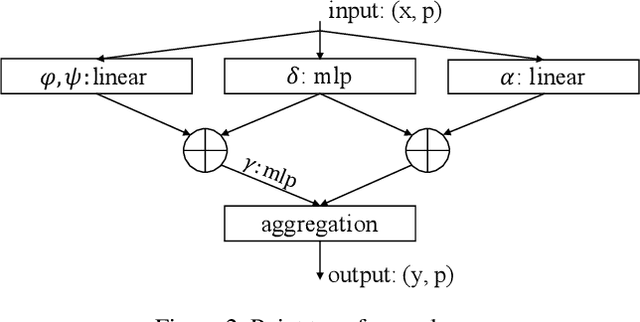
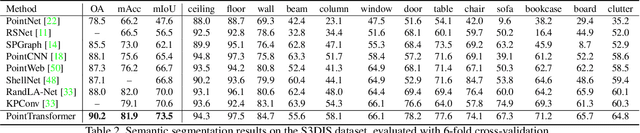
Self-attention networks have revolutionized natural language processing and are making impressive strides in image analysis tasks such as image classification and object detection. Inspired by this success, we investigate the application of self-attention networks to 3D point cloud processing. We design self-attention layers for point clouds and use these to construct self-attention networks for tasks such as semantic scene segmentation, object part segmentation, and object classification. Our Point Transformer design improves upon prior work across domains and tasks. For example, on the challenging S3DIS dataset for large-scale semantic scene segmentation, the Point Transformer attains an mIoU of 70.4% on Area 5, outperforming the strongest prior model by 3.3 absolute percentage points and crossing the 70% mIoU threshold for the first time.