 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLi Dong
Adapt-and-Distill: Developing Small, Fast and Effective Pretrained Language Models for Domains
Jun 29, 2021
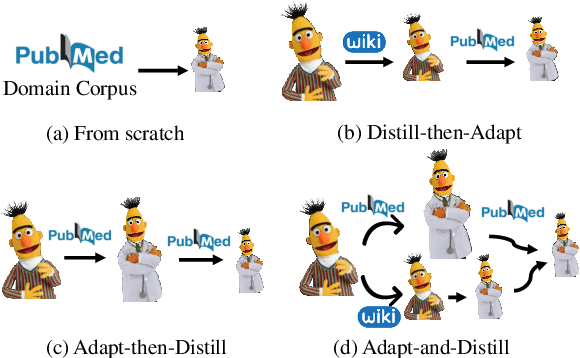
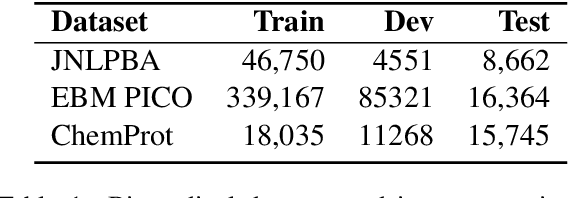
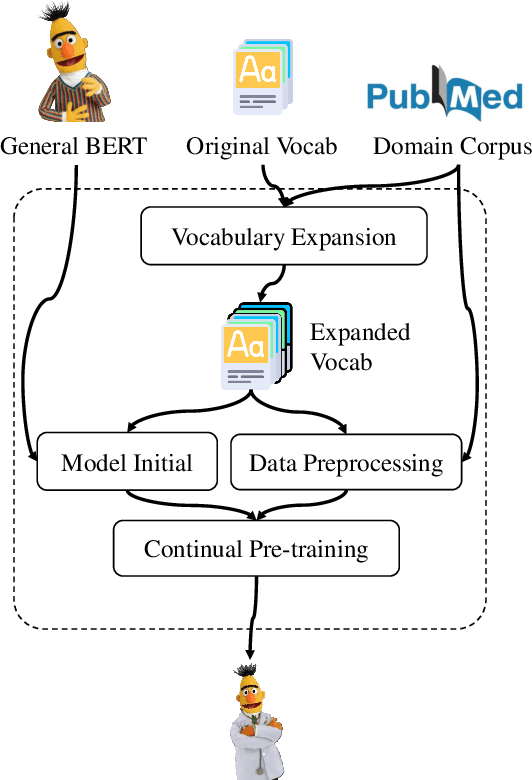
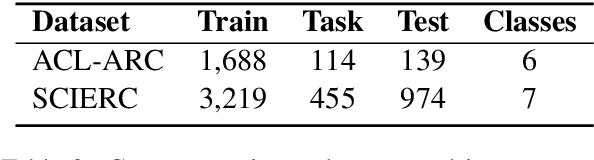
Large pre-trained models have achieved great success in many natural language processing tasks. However, when they are applied in specific domains, these models suffer from domain shift and bring challenges in fine-tuning and online serving for latency and capacity constraints. In this paper, we present a general approach to developing small, fast and effective pre-trained models for specific domains. This is achieved by adapting the off-the-shelf general pre-trained models and performing task-agnostic knowledge distillation in target domains. Specifically, we propose domain-specific vocabulary expansion in the adaptation stage and employ corpus level occurrence probability to choose the size of incremental vocabulary automatically. Then we systematically explore different strategies to compress the large pre-trained models for specific domains. We conduct our experiments in the biomedical and computer science domain. The experimental results demonstrate that our approach achieves better performance over the BERT BASE model in domain-specific tasks while 3.3x smaller and 5.1x faster than BERT BASE. The code and pre-trained models are available at https://aka.ms/adalm.
DeltaLM: Encoder-Decoder Pre-training for Language Generation and Translation by Augmenting Pretrained Multilingual Encoders
Jun 25, 2021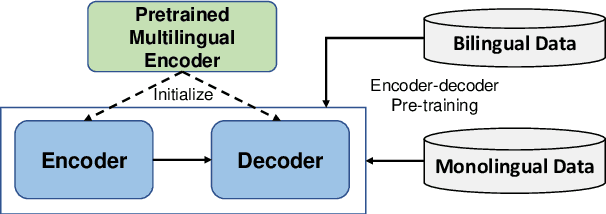

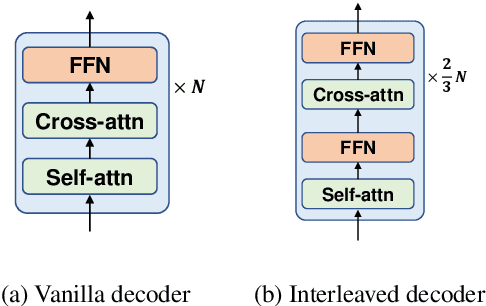
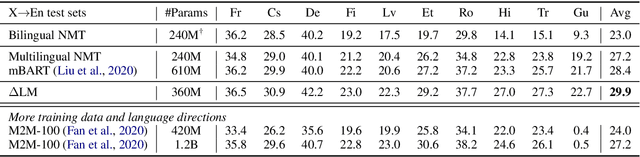
While pretrained encoders have achieved success in various natural language understanding (NLU) tasks, there is a gap between these pretrained encoders and natural language generation (NLG). NLG tasks are often based on the encoder-decoder framework, where the pretrained encoders can only benefit part of it. To reduce this gap, we introduce DeltaLM, a pretrained multilingual encoder-decoder model that regards the decoder as the task layer of off-the-shelf pretrained encoders. Specifically, we augment the pretrained multilingual encoder with a decoder and pre-train it in a self-supervised way. To take advantage of both the large-scale monolingual data and bilingual data, we adopt the span corruption and translation span corruption as the pre-training tasks. Experiments show that DeltaLM outperforms various strong baselines on both natural language generation and translation tasks, including machine translation, abstractive text summarization, data-to-text, and question generation.
Learning to Sample Replacements for ELECTRA Pre-Training
Jun 25, 2021
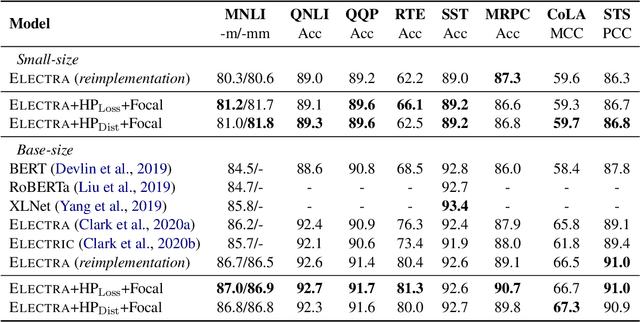

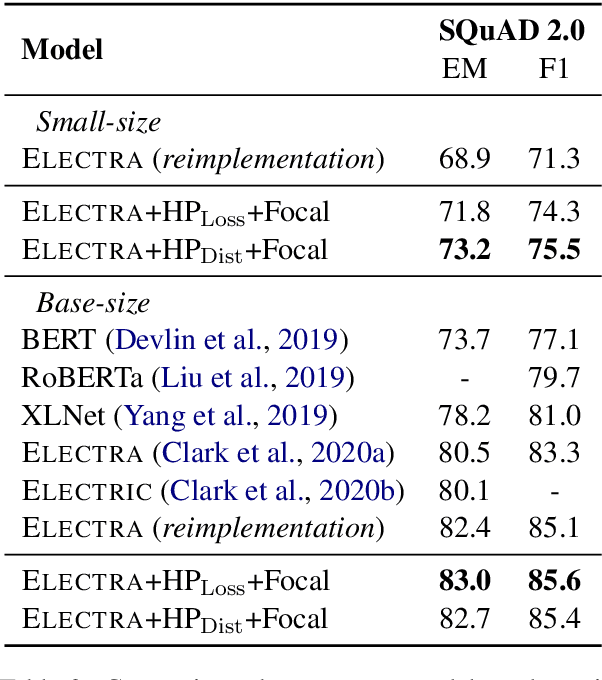
ELECTRA pretrains a discriminator to detect replaced tokens, where the replacements are sampled from a generator trained with masked language modeling. Despite the compelling performance, ELECTRA suffers from the following two issues. First, there is no direct feedback loop from discriminator to generator, which renders replacement sampling inefficient. Second, the generator's prediction tends to be over-confident along with training, making replacements biased to correct tokens. In this paper, we propose two methods to improve replacement sampling for ELECTRA pre-training. Specifically, we augment sampling with a hardness prediction mechanism, so that the generator can encourage the discriminator to learn what it has not acquired. We also prove that efficient sampling reduces the training variance of the discriminator. Moreover, we propose to use a focal loss for the generator in order to relieve oversampling of correct tokens as replacements. Experimental results show that our method improves ELECTRA pre-training on various downstream tasks.
BEiT: BERT Pre-Training of Image Transformers
Jun 15, 2021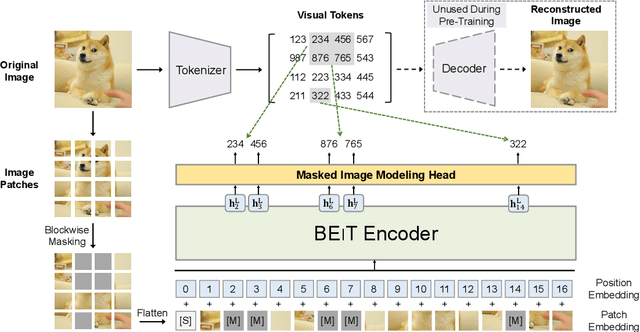
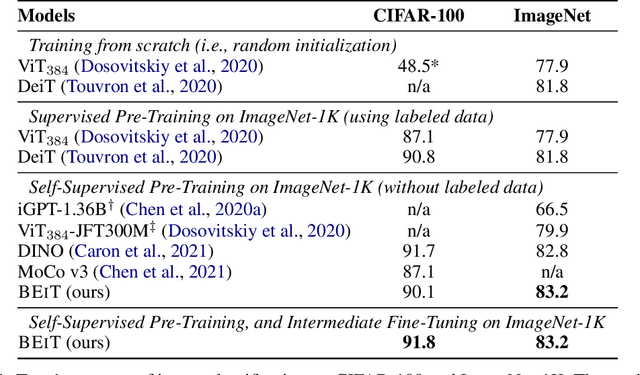
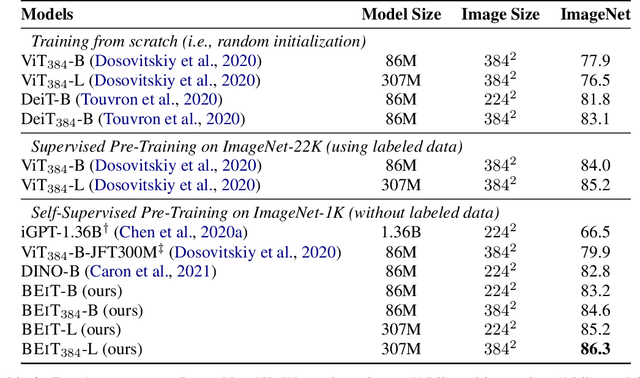
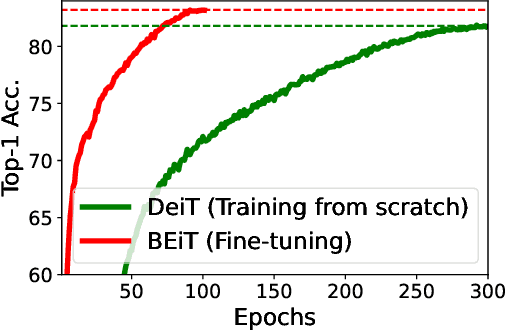
We introduce a self-supervised vision representation model BEiT, which stands for Bidirectional Encoder representation from Image Transformers. Following BERT developed in the natural language processing area, we propose a masked image modeling task to pretrain vision Transformers. Specifically, each image has two views in our pre-training, i.e, image patches (such as 16x16 pixels), and visual tokens (i.e., discrete tokens). We first "tokenize" the original image into visual tokens. Then we randomly mask some image patches and fed them into the backbone Transformer. The pre-training objective is to recover the original visual tokens based on the corrupted image patches. After pre-training BEiT, we directly fine-tune the model parameters on downstream tasks by appending task layers upon the pretrained encoder. Experimental results on image classification and semantic segmentation show that our model achieves competitive results with previous pre-training methods. For example, base-size BEiT achieves 83.2% top-1 accuracy on ImageNet-1K, significantly outperforming from-scratch DeiT training (81.8%) with the same setup. Moreover, large-size BEiT obtains 86.3% only using ImageNet-1K, even outperforming ViT-L with supervised pre-training on ImageNet-22K (85.2%). The code and pretrained models are available at https://aka.ms/beit.
Consistency Regularization for Cross-Lingual Fine-Tuning
Jun 15, 2021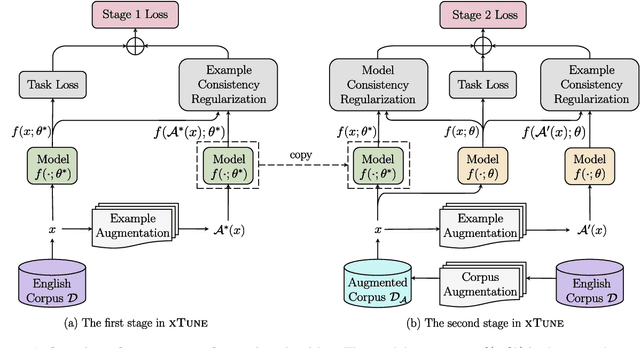
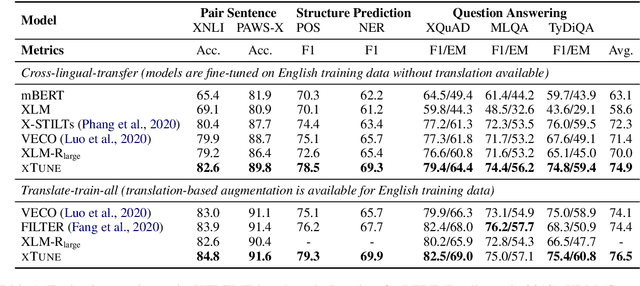
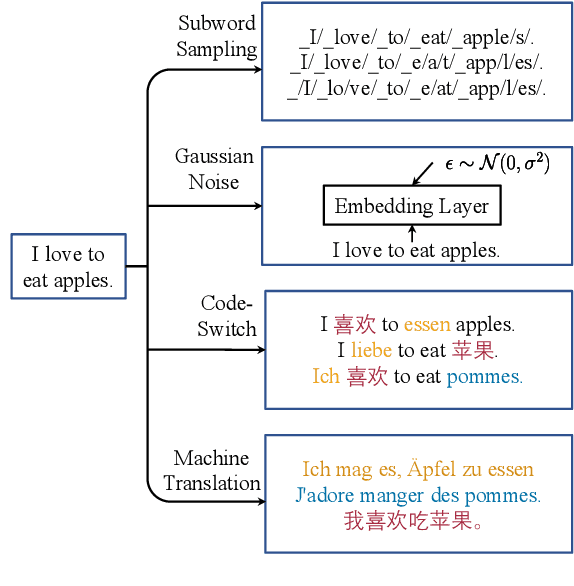
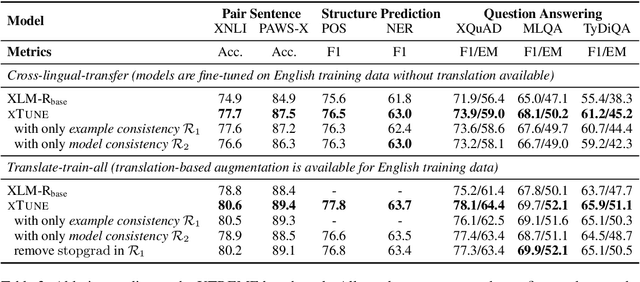
Fine-tuning pre-trained cross-lingual language models can transfer task-specific supervision from one language to the others. In this work, we propose to improve cross-lingual fine-tuning with consistency regularization. Specifically, we use example consistency regularization to penalize the prediction sensitivity to four types of data augmentations, i.e., subword sampling, Gaussian noise, code-switch substitution, and machine translation. In addition, we employ model consistency to regularize the models trained with two augmented versions of the same training set. Experimental results on the XTREME benchmark show that our method significantly improves cross-lingual fine-tuning across various tasks, including text classification, question answering, and sequence labeling.
Improving Pretrained Cross-Lingual Language Models via Self-Labeled Word Alignment
Jun 11, 2021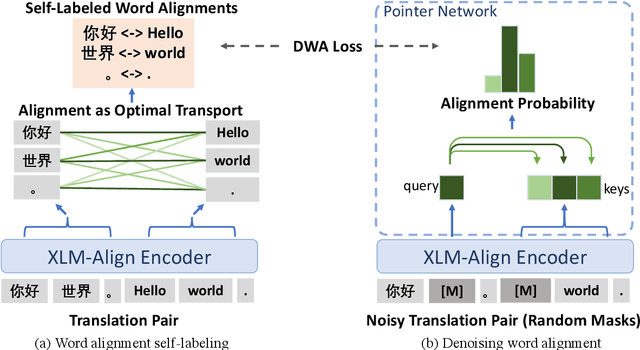
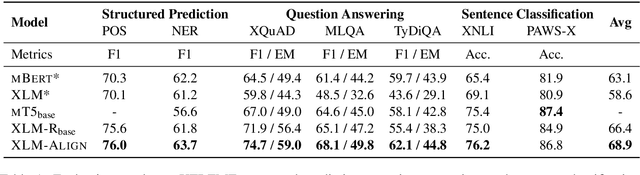
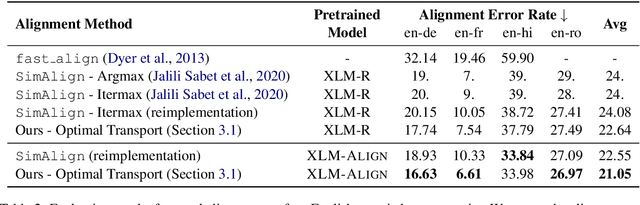
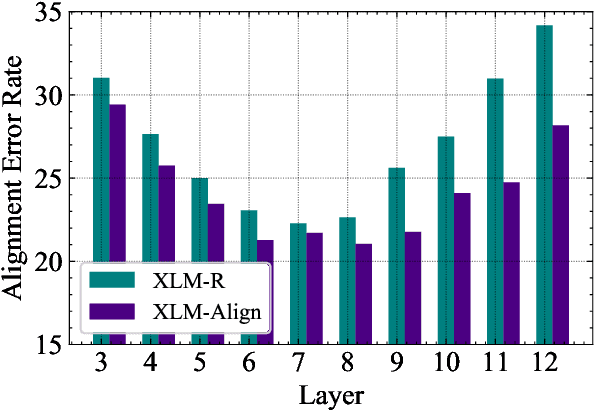
The cross-lingual language models are typically pretrained with masked language modeling on multilingual text or parallel sentences. In this paper, we introduce denoising word alignment as a new cross-lingual pre-training task. Specifically, the model first self-labels word alignments for parallel sentences. Then we randomly mask tokens in a bitext pair. Given a masked token, the model uses a pointer network to predict the aligned token in the other language. We alternately perform the above two steps in an expectation-maximization manner. Experimental results show that our method improves cross-lingual transferability on various datasets, especially on the token-level tasks, such as question answering, and structured prediction. Moreover, the model can serve as a pretrained word aligner, which achieves reasonably low error rates on the alignment benchmarks. The code and pretrained parameters are available at https://github.com/CZWin32768/XLM-Align.
A Semi-supervised Multi-task Learning Approach to Classify Customer Contact Intents
Jun 10, 2021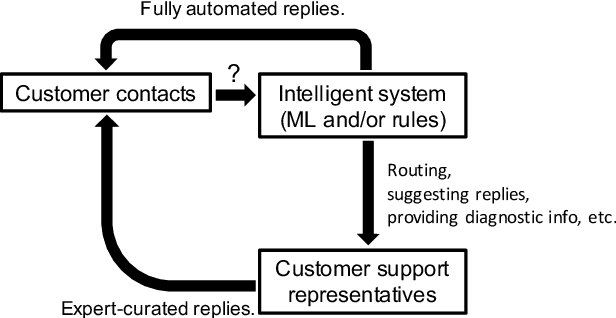

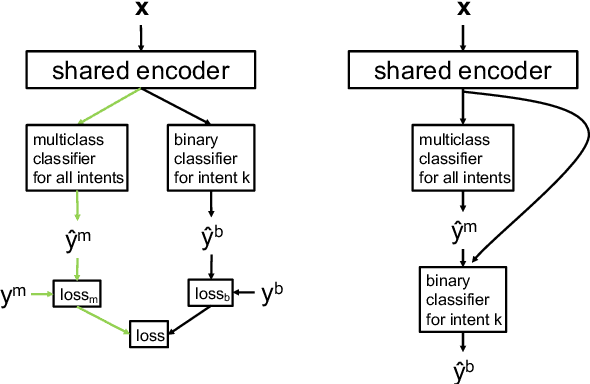

In the area of customer support, understanding customers' intents is a crucial step. Machine learning plays a vital role in this type of intent classification. In reality, it is typical to collect confirmation from customer support representatives (CSRs) regarding the intent prediction, though it can unnecessarily incur prohibitive cost to ask CSRs to assign existing or new intents to the mis-classified cases. Apart from the confirmed cases with and without intent labels, there can be a number of cases with no human curation. This data composition (Positives + Unlabeled + multiclass Negatives) creates unique challenges for model development. In response to that, we propose a semi-supervised multi-task learning paradigm. In this manuscript, we share our experience in building text-based intent classification models for a customer support service on an E-commerce website. We improve the performance significantly by evolving the model from multiclass classification to semi-supervised multi-task learning by leveraging the negative cases, domain- and task-adaptively pretrained ALBERT on customer contact texts, and a number of un-curated data with no labels. In the evaluation, the final model boosts the average AUC ROC by almost 20 points compared to the baseline finetuned multiclass classification ALBERT model.
Memory-Efficient Differentiable Transformer Architecture Search
May 31, 2021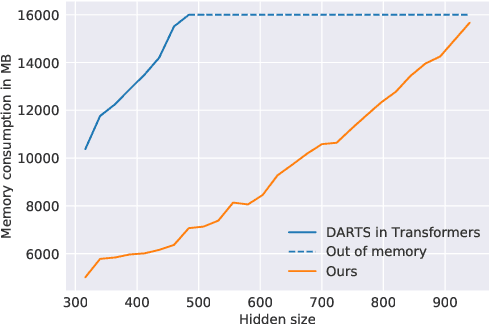
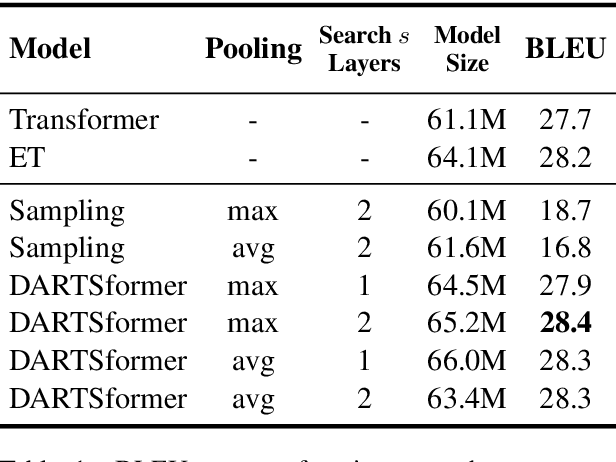
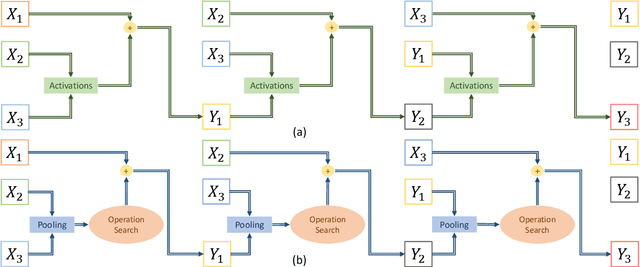
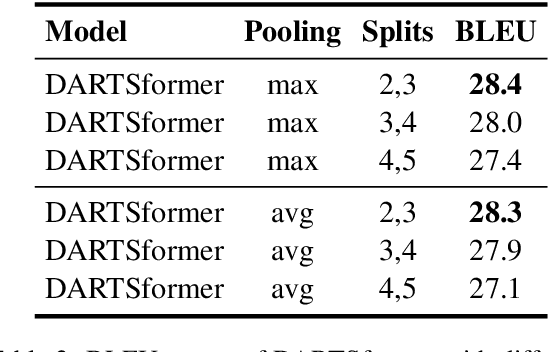
Differentiable architecture search (DARTS) is successfully applied in many vision tasks. However, directly using DARTS for Transformers is memory-intensive, which renders the search process infeasible. To this end, we propose a multi-split reversible network and combine it with DARTS. Specifically, we devise a backpropagation-with-reconstruction algorithm so that we only need to store the last layer's outputs. By relieving the memory burden for DARTS, it allows us to search with larger hidden size and more candidate operations. We evaluate the searched architecture on three sequence-to-sequence datasets, i.e., WMT'14 English-German, WMT'14 English-French, and WMT'14 English-Czech. Experimental results show that our network consistently outperforms standard Transformers across the tasks. Moreover, our method compares favorably with big-size Evolved Transformers, reducing search computation by an order of magnitude.
Zero-shot Cross-lingual Transfer of Neural Machine Translation with Multilingual Pretrained Encoders
Apr 18, 2021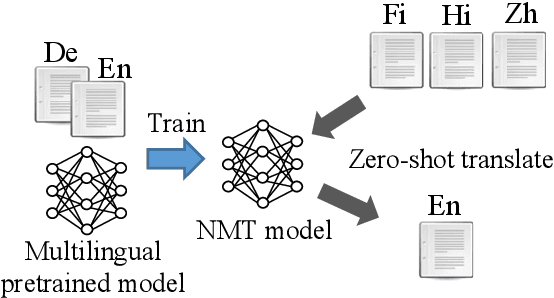
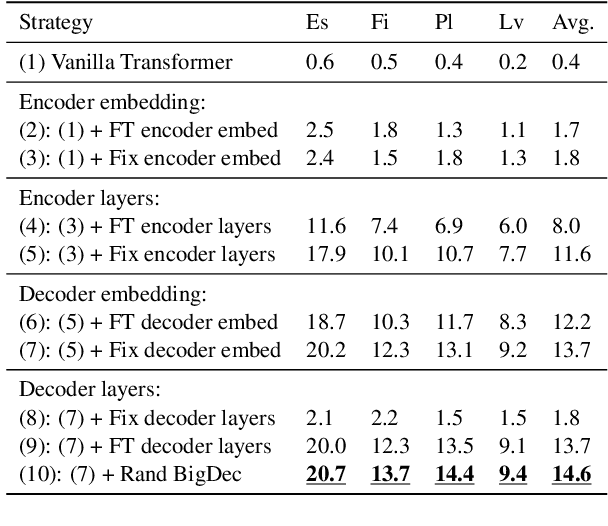
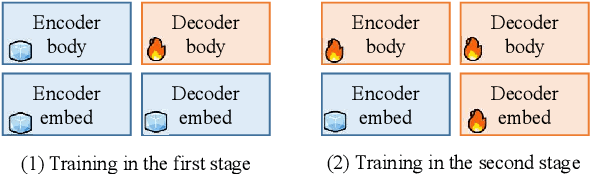
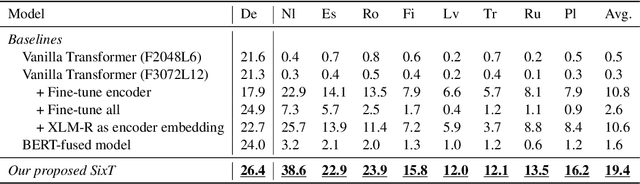
Previous works mainly focus on improving cross-lingual transfer for NLU tasks with multilingual pretrained encoder (MPE), or improving the translation performance on NMT task with BERT. However, how to improve the cross-lingual transfer of NMT model with multilingual pretrained encoder is under-explored. In this paper, we focus on a zero-shot cross-lingual transfer task in NMT. In this task, the NMT model is trained with one parallel dataset and an off-the-shelf MPE, then is directly tested on zero-shot language pairs. We propose SixT, a simple yet effective model for this task. The SixT model leverages the MPE with a two-stage training schedule and gets further improvement with a position disentangled encoder and a capacity-enhanced decoder. The extensive experiments prove that SixT significantly improves the translation quality of the unseen languages. With much less computation cost and training data, our model achieves better performance on many-to-English testsets than CRISS and m2m-100, two strong multilingual NMT baselines.