 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeonidas J. Guibas
COPILOT: Human Collision Prediction and Localization from Multi-view Egocentric Videos
Oct 04, 2022
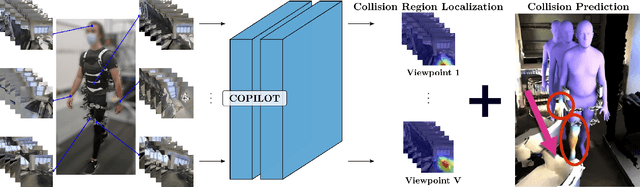
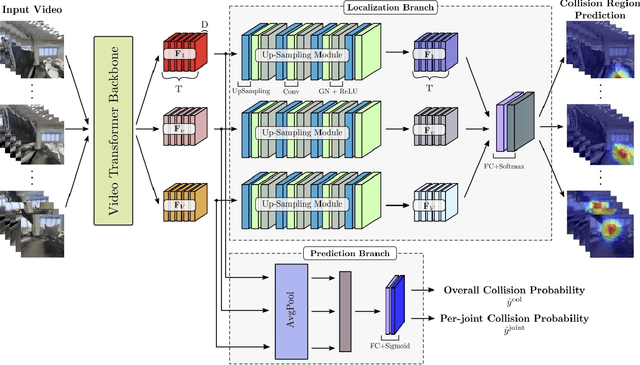
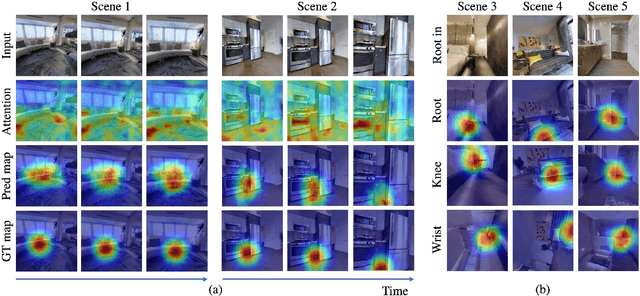
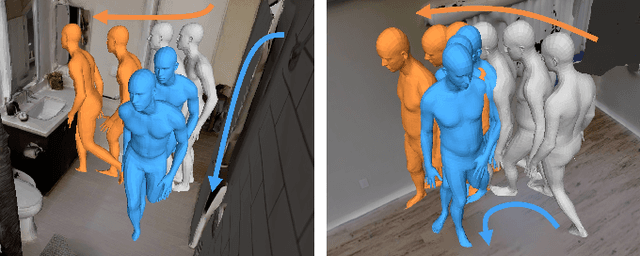
To produce safe human motions, assistive wearable exoskeletons must be equipped with a perception system that enables anticipating potential collisions from egocentric observations. However, previous approaches to exoskeleton perception greatly simplify the problem to specific types of environments, limiting their scalability. In this paper, we propose the challenging and novel problem of predicting human-scene collisions for diverse environments from multi-view egocentric RGB videos captured from an exoskeleton. By classifying which body joints will collide with the environment and predicting a collision region heatmap that localizes potential collisions in the environment, we aim to develop an exoskeleton perception system that generalizes to complex real-world scenes and provides actionable outputs for downstream control. We propose COPILOT, a video transformer-based model that performs both collision prediction and localization simultaneously, leveraging multi-view video inputs via a proposed joint space-time-viewpoint attention operation. To train and evaluate the model, we build a synthetic data generation framework to simulate virtual humans moving in photo-realistic 3D environments. This framework is then used to establish a dataset consisting of 8.6M egocentric RGBD frames to enable future work on the problem. Extensive experiments suggest that our model achieves promising performance and generalizes to unseen scenes as well as real world. We apply COPILOT to a downstream collision avoidance task, and successfully reduce collision cases by 29% on unseen scenes using a simple closed-loop control algorithm.
6D Camera Relocalization in Visually Ambiguous Extreme Environments
Jul 13, 2022
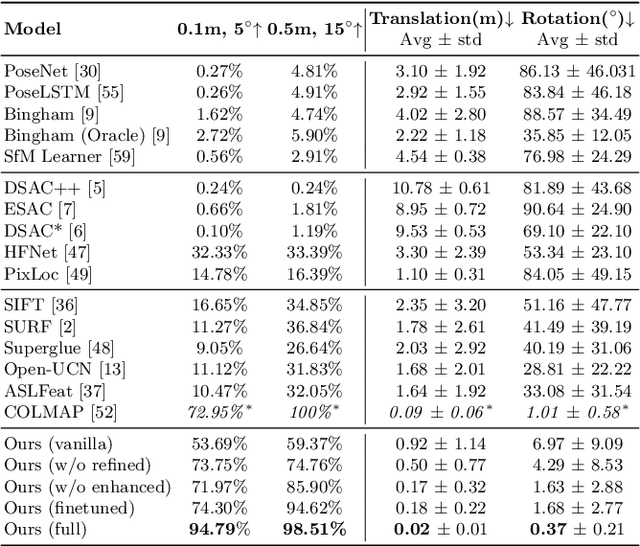
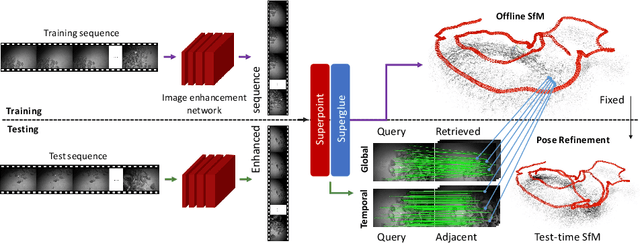
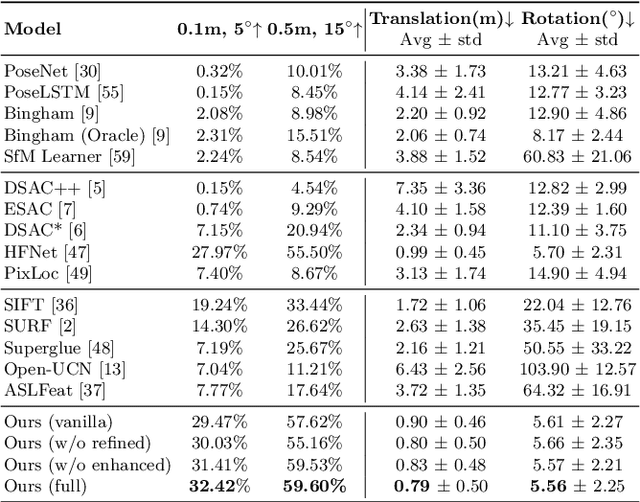
We propose a novel method to reliably estimate the pose of a camera given a sequence of images acquired in extreme environments such as deep seas or extraterrestrial terrains. Data acquired under these challenging conditions are corrupted by textureless surfaces, image degradation, and presence of repetitive and highly ambiguous structures. When naively deployed, the state-of-the-art methods can fail in those scenarios as confirmed by our empirical analysis. In this paper, we attempt to make camera relocalization work in these extreme situations. To this end, we propose: (i) a hierarchical localization system, where we leverage temporal information and (ii) a novel environment-aware image enhancement method to boost the robustness and accuracy. Our extensive experimental results demonstrate superior performance in favor of our method under two extreme settings: localizing an autonomous underwater vehicle and localizing a planetary rover in a Mars-like desert. In addition, our method achieves comparable performance with state-of-the-art methods on the indoor benchmark (7-Scenes dataset) using only 20% training data.
Object Scene Representation Transformer
Jun 14, 2022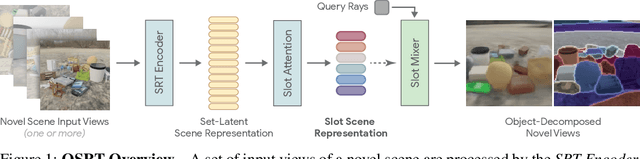

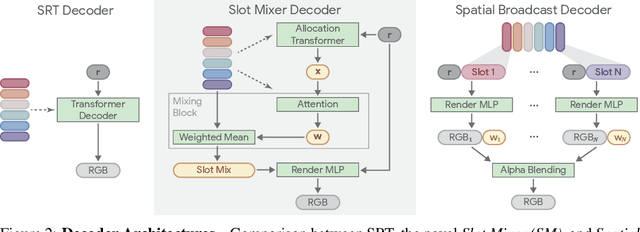
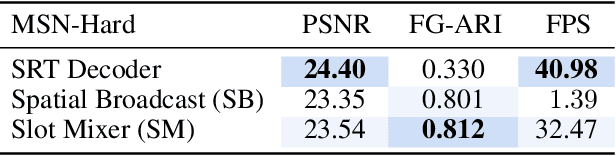
A compositional understanding of the world in terms of objects and their geometry in 3D space is considered a cornerstone of human cognition. Facilitating the learning of such a representation in neural networks holds promise for substantially improving labeled data efficiency. As a key step in this direction, we make progress on the problem of learning 3D-consistent decompositions of complex scenes into individual objects in an unsupervised fashion. We introduce Object Scene Representation Transformer (OSRT), a 3D-centric model in which individual object representations naturally emerge through novel view synthesis. OSRT scales to significantly more complex scenes with larger diversity of objects and backgrounds than existing methods. At the same time, it is multiple orders of magnitude faster at compositional rendering thanks to its light field parametrization and the novel Slot Mixer decoder. We believe this work will not only accelerate future architecture exploration and scaling efforts, but it will also serve as a useful tool for both object-centric as well as neural scene representation learning communities.
Fixing Malfunctional Objects With Learned Physical Simulation and Functional Prediction
May 05, 2022
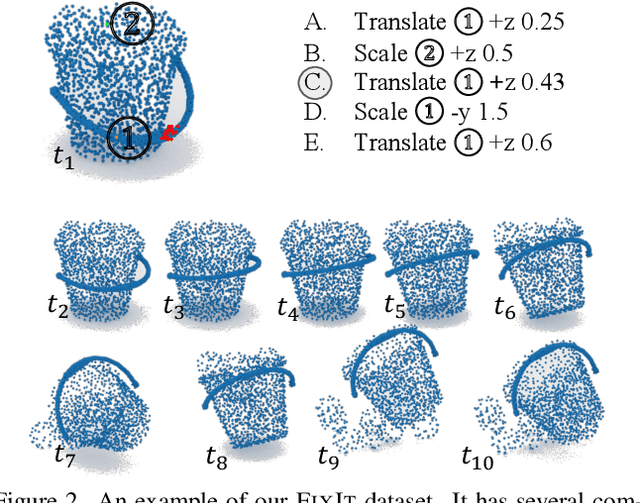
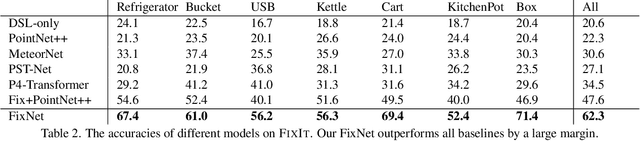
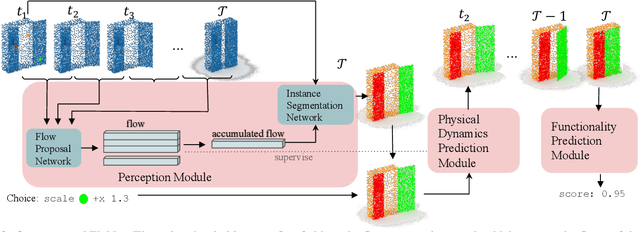
This paper studies the problem of fixing malfunctional 3D objects. While previous works focus on building passive perception models to learn the functionality from static 3D objects, we argue that functionality is reckoned with respect to the physical interactions between the object and the user. Given a malfunctional object, humans can perform mental simulations to reason about its functionality and figure out how to fix it. Inspired by this, we propose FixIt, a dataset that contains about 5k poorly-designed 3D physical objects paired with choices to fix them. To mimic humans' mental simulation process, we present FixNet, a novel framework that seamlessly incorporates perception and physical dynamics. Specifically, FixNet consists of a perception module to extract the structured representation from the 3D point cloud, a physical dynamics prediction module to simulate the results of interactions on 3D objects, and a functionality prediction module to evaluate the functionality and choose the correct fix. Experimental results show that our framework outperforms baseline models by a large margin, and can generalize well to objects with similar interaction types.
GIMO: Gaze-Informed Human Motion Prediction in Context
Apr 20, 2022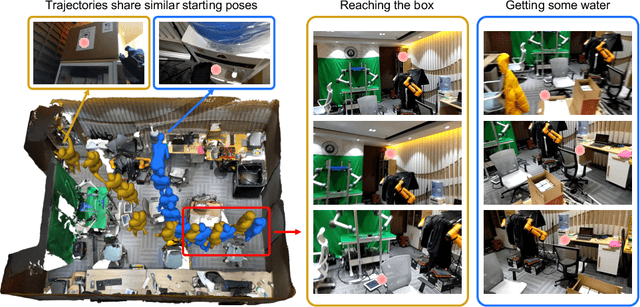
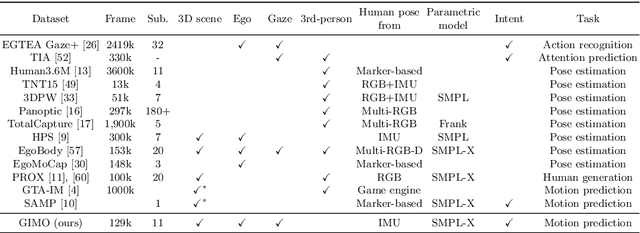
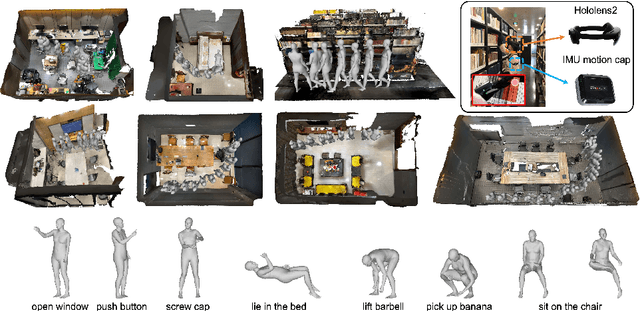
Predicting human motion is critical for assistive robots and AR/VR applications, where the interaction with humans needs to be safe and comfortable. Meanwhile, an accurate prediction depends on understanding both the scene context and human intentions. Even though many works study scene-aware human motion prediction, the latter is largely underexplored due to the lack of ego-centric views that disclose human intent and the limited diversity in motion and scenes. To reduce the gap, we propose a large-scale human motion dataset that delivers high-quality body pose sequences, scene scans, as well as ego-centric views with eye gaze that serves as a surrogate for inferring human intent. By employing inertial sensors for motion capture, our data collection is not tied to specific scenes, which further boosts the motion dynamics observed from our subjects. We perform an extensive study of the benefits of leveraging eye gaze for ego-centric human motion prediction with various state-of-the-art architectures. Moreover, to realize the full potential of gaze, we propose a novel network architecture that enables bidirectional communication between the gaze and motion branches. Our network achieves the top performance in human motion prediction on the proposed dataset, thanks to the intent information from the gaze and the denoised gaze feature modulated by the motion. The proposed dataset and our network implementation will be publicly available.
ACID: Action-Conditional Implicit Visual Dynamics for Deformable Object Manipulation
Mar 14, 2022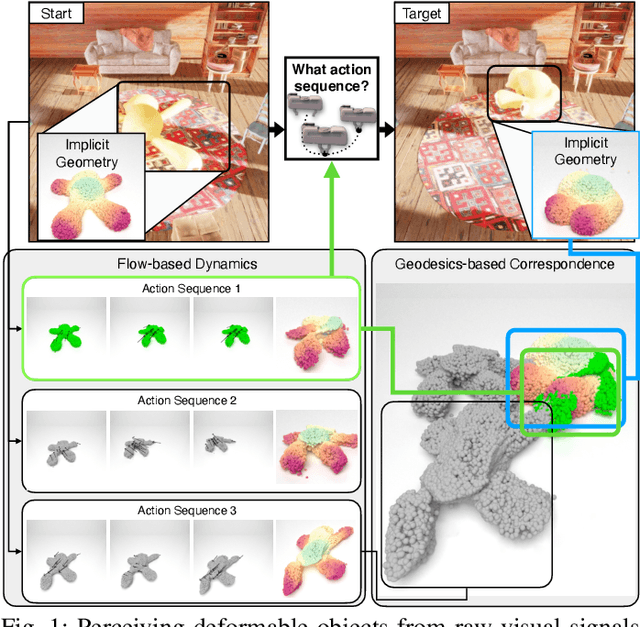
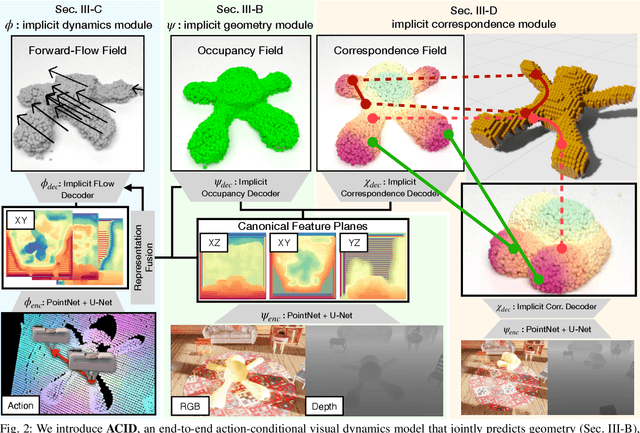


Manipulating volumetric deformable objects in the real world, like plush toys and pizza dough, bring substantial challenges due to infinite shape variations, non-rigid motions, and partial observability. We introduce ACID, an action-conditional visual dynamics model for volumetric deformable objects based on structured implicit neural representations. ACID integrates two new techniques: implicit representations for action-conditional dynamics and geodesics-based contrastive learning. To represent deformable dynamics from partial RGB-D observations, we learn implicit representations of occupancy and flow-based forward dynamics. To accurately identify state change under large non-rigid deformations, we learn a correspondence embedding field through a novel geodesics-based contrastive loss. To evaluate our approach, we develop a simulation framework for manipulating complex deformable shapes in realistic scenes and a benchmark containing over 17,000 action trajectories with six types of plush toys and 78 variants. Our model achieves the best performance in geometry, correspondence, and dynamics predictions over existing approaches. The ACID dynamics models are successfully employed to goal-conditioned deformable manipulation tasks, resulting in a 30% increase in task success rate over the strongest baseline. For more results and information, please visit https://b0ku1.github.io/acid-web/ .
ConDor: Self-Supervised Canonicalization of 3D Pose for Partial Shapes
Jan 19, 2022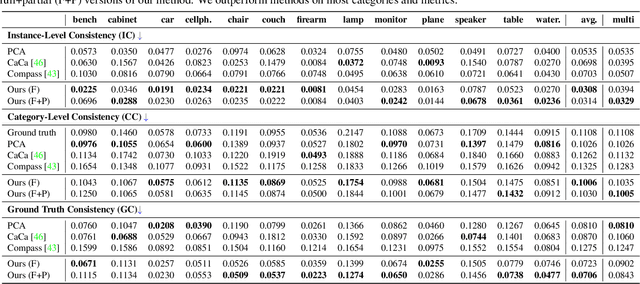
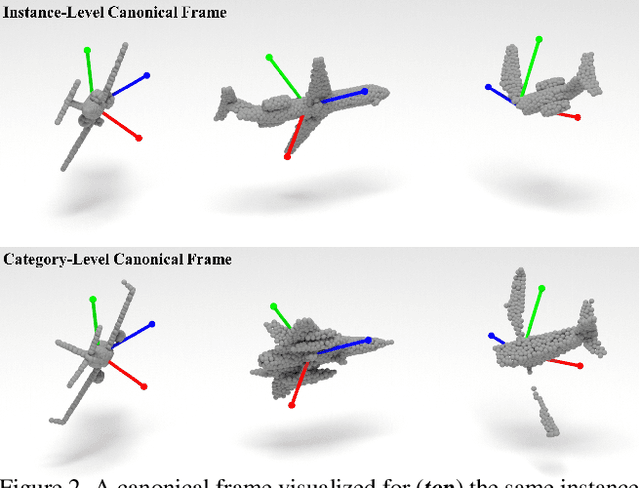
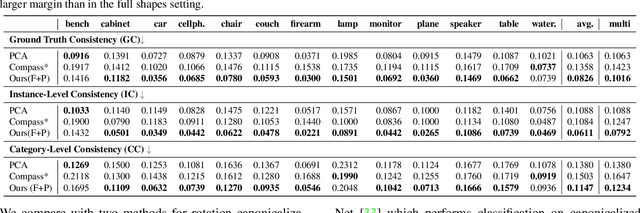
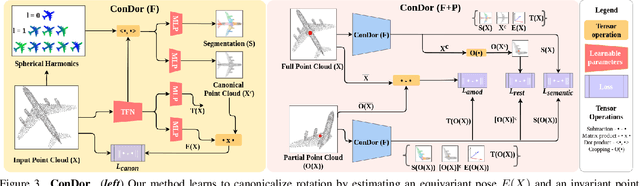
Progress in 3D object understanding has relied on manually canonicalized shape datasets that contain instances with consistent position and orientation (3D pose). This has made it hard to generalize these methods to in-the-wild shapes, eg., from internet model collections or depth sensors. ConDor is a self-supervised method that learns to Canonicalize the 3D orientation and position for full and partial 3D point clouds. We build on top of Tensor Field Networks (TFNs), a class of permutation- and rotation-equivariant, and translation-invariant 3D networks. During inference, our method takes an unseen full or partial 3D point cloud at an arbitrary pose and outputs an equivariant canonical pose. During training, this network uses self-supervision losses to learn the canonical pose from an un-canonicalized collection of full and partial 3D point clouds. ConDor can also learn to consistently co-segment object parts without any supervision. Extensive quantitative results on four new metrics show that our approach outperforms existing methods while enabling new applications such as operation on depth images and annotation transfer.
Generating Useful Accident-Prone Driving Scenarios via a Learned Traffic Prior
Dec 09, 2021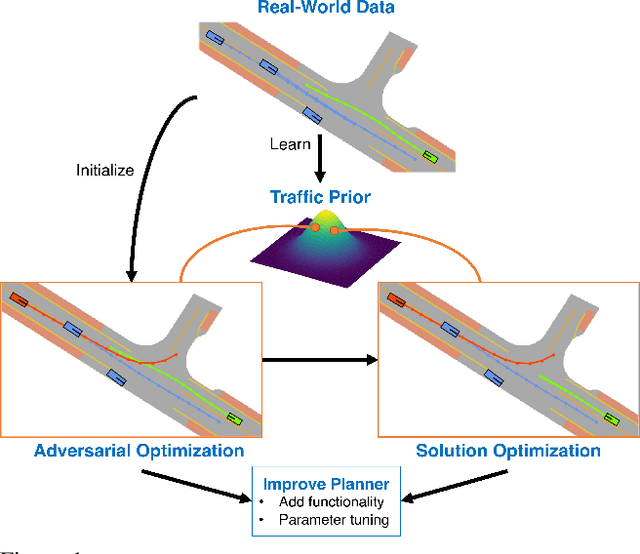

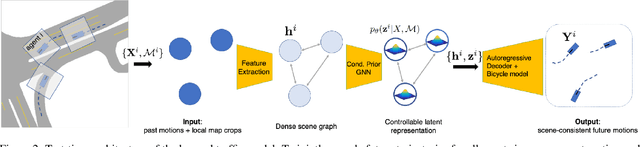

Evaluating and improving planning for autonomous vehicles requires scalable generation of long-tail traffic scenarios. To be useful, these scenarios must be realistic and challenging, but not impossible to drive through safely. In this work, we introduce STRIVE, a method to automatically generate challenging scenarios that cause a given planner to produce undesirable behavior, like collisions. To maintain scenario plausibility, the key idea is to leverage a learned model of traffic motion in the form of a graph-based conditional VAE. Scenario generation is formulated as an optimization in the latent space of this traffic model, effected by perturbing an initial real-world scene to produce trajectories that collide with a given planner. A subsequent optimization is used to find a "solution" to the scenario, ensuring it is useful to improve the given planner. Further analysis clusters generated scenarios based on collision type. We attack two planners and show that STRIVE successfully generates realistic, challenging scenarios in both cases. We additionally "close the loop" and use these scenarios to optimize hyperparameters of a rule-based planner.
Multiway Non-rigid Point Cloud Registration via Learned Functional Map Synchronization
Nov 25, 2021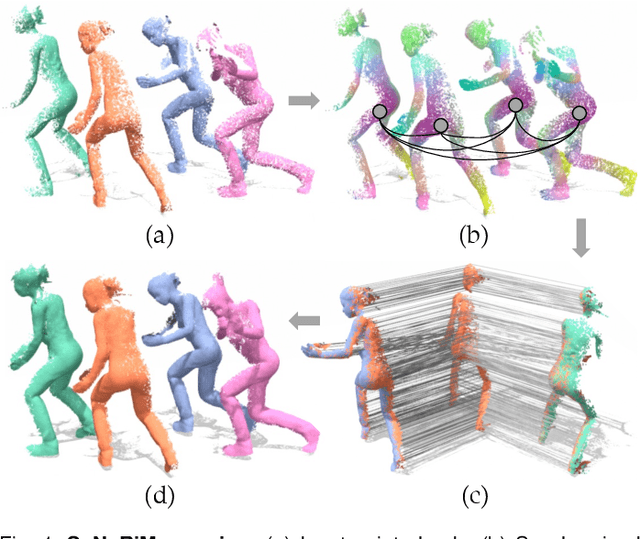
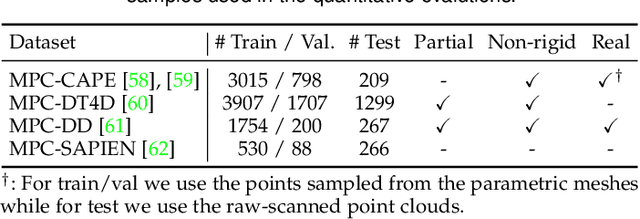
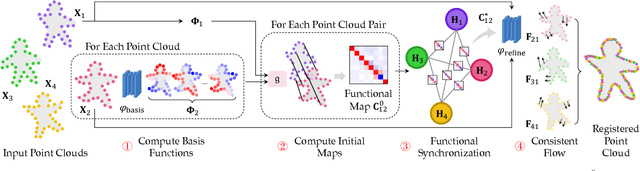
We present SyNoRiM, a novel way to jointly register multiple non-rigid shapes by synchronizing the maps relating learned functions defined on the point clouds. Even though the ability to process non-rigid shapes is critical in various applications ranging from computer animation to 3D digitization, the literature still lacks a robust and flexible framework to match and align a collection of real, noisy scans observed under occlusions. Given a set of such point clouds, our method first computes the pairwise correspondences parameterized via functional maps. We simultaneously learn potentially non-orthogonal basis functions to effectively regularize the deformations, while handling the occlusions in an elegant way. To maximally benefit from the multi-way information provided by the inferred pairwise deformation fields, we synchronize the pairwise functional maps into a cycle-consistent whole thanks to our novel and principled optimization formulation. We demonstrate via extensive experiments that our method achieves a state-of-the-art performance in registration accuracy, while being flexible and efficient as we handle both non-rigid and multi-body cases in a unified framework and avoid the costly optimization over point-wise permutations by the use of basis function maps.
Unsupervised Discovery of Object Radiance Fields
Jul 16, 2021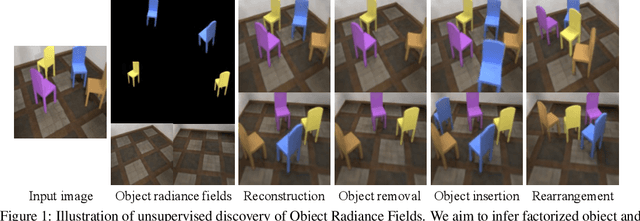

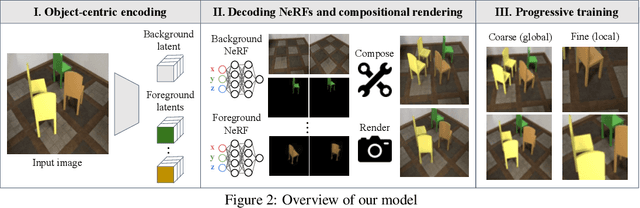
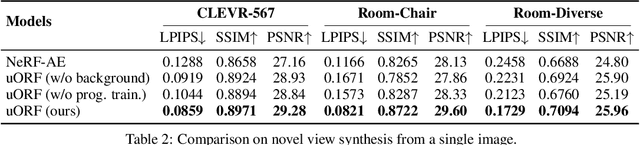
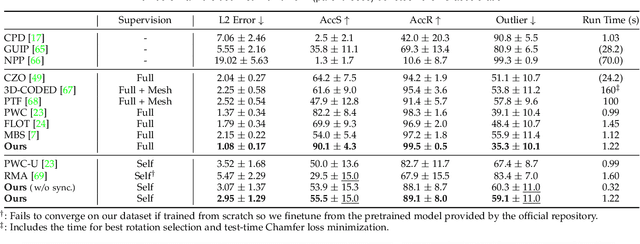
We study the problem of inferring an object-centric scene representation from a single image, aiming to derive a representation that explains the image formation process, captures the scene's 3D nature, and is learned without supervision. Most existing methods on scene decomposition lack one or more of these characteristics, due to the fundamental challenge in integrating the complex 3D-to-2D image formation process into powerful inference schemes like deep networks. In this paper, we propose unsupervised discovery of Object Radiance Fields (uORF), integrating recent progresses in neural 3D scene representations and rendering with deep inference networks for unsupervised 3D scene decomposition. Trained on multi-view RGB images without annotations, uORF learns to decompose complex scenes with diverse, textured background from a single image. We show that uORF performs well on unsupervised 3D scene segmentation, novel view synthesis, and scene editing on three datasets.