 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveMAE: Wavelet decomposition Masked Auto-Encoder for Remote Sensing
Oct 26, 2025Self-supervised learning (SSL) has recently emerged as a key strategy for building foundation models in remote sensing, where the scarcity of annotated data limits the applicability of fully supervised approaches. In this work, we introduce WaveMAE, a masked autoencoding framework tailored for multispectral satellite imagery. Unlike conventional pixel-based reconstruction, WaveMAE leverages a multi-level Discrete Wavelet Transform (DWT) to disentangle frequency components and guide the encoder toward learning scale-aware high-frequency representations. We further propose a Geo-conditioned Positional Encoding (GPE), which incorporates geographical priors via Spherical Harmonics, encouraging embeddings that respect both semantic and geospatial structure. To ensure fairness in evaluation, all methods are pretrained on the same dataset (fMoW-S2) and systematically evaluated on the diverse downstream tasks of the PANGAEA benchmark, spanning semantic segmentation, regression, change detection, and multilabel classification. Extensive experiments demonstrate that WaveMAE achieves consistent improvements over prior state-of-the-art approaches, with substantial gains on segmentation and regression benchmarks. The effectiveness of WaveMAE pretraining is further demonstrated by showing that even a lightweight variant, containing only 26.4% of the parameters, achieves state-of-the-art performance. Our results establish WaveMAE as a strong and geographically informed foundation model for multispectral remote sensing imagery.
CFTS-GAN: Continual Few-Shot Teacher Student for Generative Adversarial Networks
Oct 17, 2024Few-shot and continual learning face two well-known challenges in GANs: overfitting and catastrophic forgetting. Learning new tasks results in catastrophic forgetting in deep learning models. In the case of a few-shot setting, the model learns from a very limited number of samples (e.g. 10 samples), which can lead to overfitting and mode collapse. So, this paper proposes a Continual Few-shot Teacher-Student technique for the generative adversarial network (CFTS-GAN) that considers both challenges together. Our CFTS-GAN uses an adapter module as a student to learn a new task without affecting the previous knowledge. To make the student model efficient in learning new tasks, the knowledge from a teacher model is distilled to the student. In addition, the Cross-Domain Correspondence (CDC) loss is used by both teacher and student to promote diversity and to avoid mode collapse. Moreover, an effective strategy of freezing the discriminator is also utilized for enhancing performance. Qualitative and quantitative results demonstrate more diverse image synthesis and produce qualitative samples comparatively good to very stronger state-of-the-art models.
MCGM: Mask Conditional Text-to-Image Generative Model
Oct 01, 2024


Recent advancements in generative models have revolutionized the field of artificial intelligence, enabling the creation of highly-realistic and detailed images. In this study, we propose a novel Mask Conditional Text-to-Image Generative Model (MCGM) that leverages the power of conditional diffusion models to generate pictures with specific poses. Our model builds upon the success of the Break-a-scene [1] model in generating new scenes using a single image with multiple subjects and incorporates a mask embedding injection that allows the conditioning of the generation process. By introducing this additional level of control, MCGM offers a flexible and intuitive approach for generating specific poses for one or more subjects learned from a single image, empowering users to influence the output based on their requirements. Through extensive experimentation and evaluation, we demonstrate the effectiveness of our proposed model in generating high-quality images that meet predefined mask conditions and improving the current Break-a-scene generative model.
Mamba-ST: State Space Model for Efficient Style Transfer
Sep 16, 2024



The goal of style transfer is, given a content image and a style source, generating a new image preserving the content but with the artistic representation of the style source. Most of the state-of-the-art architectures use transformers or diffusion-based models to perform this task, despite the heavy computational burden that they require. In particular, transformers use self- and cross-attention layers which have large memory footprint, while diffusion models require high inference time. To overcome the above, this paper explores a novel design of Mamba, an emergent State-Space Model (SSM), called Mamba-ST, to perform style transfer. To do so, we adapt Mamba linear equation to simulate the behavior of cross-attention layers, which are able to combine two separate embeddings into a single output, but drastically reducing memory usage and time complexity. We modified the Mamba's inner equations so to accept inputs from, and combine, two separate data streams. To the best of our knowledge, this is the first attempt to adapt the equations of SSMs to a vision task like style transfer without requiring any other module like cross-attention or custom normalization layers. An extensive set of experiments demonstrates the superiority and efficiency of our method in performing style transfer compared to transformers and diffusion models. Results show improved quality in terms of both ArtFID and FID metrics. Code is available at https://github.com/FilippoBotti/MambaST.
Swin2-MoSE: A New Single Image Super-Resolution Model for Remote Sensing
Apr 29, 2024



Due to the limitations of current optical and sensor technologies and the high cost of updating them, the spectral and spatial resolution of satellites may not always meet desired requirements. For these reasons, Remote-Sensing Single-Image Super-Resolution (RS-SISR) techniques have gained significant interest. In this paper, we propose Swin2-MoSE model, an enhanced version of Swin2SR. Our model introduces MoE-SM, an enhanced Mixture-of-Experts (MoE) to replace the Feed-Forward inside all Transformer block. MoE-SM is designed with Smart-Merger, and new layer for merging the output of individual experts, and with a new way to split the work between experts, defining a new per-example strategy instead of the commonly used per-token one. Furthermore, we analyze how positional encodings interact with each other, demonstrating that per-channel bias and per-head bias can positively cooperate. Finally, we propose to use a combination of Normalized-Cross-Correlation (NCC) and Structural Similarity Index Measure (SSIM) losses, to avoid typical MSE loss limitations. Experimental results demonstrate that Swin2-MoSE outperforms SOTA by up to 0.377 ~ 0.958 dB (PSNR) on task of 2x, 3x and 4x resolution-upscaling (Sen2Venus and OLI2MSI datasets). We show the efficacy of Swin2-MoSE, applying it to a semantic segmentation task (SeasoNet dataset). Code and pretrained are available on https://github.com/IMPLabUniPr/swin2-mose/tree/official_code
Self-Balanced R-CNN for Instance Segmentation
Apr 25, 2024



Current state-of-the-art two-stage models on instance segmentation task suffer from several types of imbalances. In this paper, we address the Intersection over the Union (IoU) distribution imbalance of positive input Regions of Interest (RoIs) during the training of the second stage. Our Self-Balanced R-CNN (SBR-CNN), an evolved version of the Hybrid Task Cascade (HTC) model, brings brand new loop mechanisms of bounding box and mask refinements. With an improved Generic RoI Extraction (GRoIE), we also address the feature-level imbalance at the Feature Pyramid Network (FPN) level, originated by a non-uniform integration between low- and high-level features from the backbone layers. In addition, the redesign of the architecture heads toward a fully convolutional approach with FCC further reduces the number of parameters and obtains more clues to the connection between the task to solve and the layers used. Moreover, our SBR-CNN model shows the same or even better improvements if adopted in conjunction with other state-of-the-art models. In fact, with a lightweight ResNet-50 as backbone, evaluated on COCO minival 2017 dataset, our model reaches 45.3% and 41.5% AP for object detection and instance segmentation, with 12 epochs and without extra tricks. The code is available at https://github.com/IMPLabUniPr/mmdetection/tree/sbr_cnn
Memory-augmented Online Video Anomaly Detection
Feb 21, 2023



The ability to understand the surrounding scene is of paramount importance for Autonomous Vehicles (AVs). This paper presents a system capable to work in a real time guaranteed response times and online fashion, giving an immediate response to the arise of anomalies surrounding the AV, exploiting only the videos captured by a dash-mounted camera. Our architecture, called MOVAD, relies on two main modules: a short-term memory to extract information related to the ongoing action, implemented by a Video Swin Transformer adapted to work in an online scenario, and a long-term memory module that considers also remote past information thanks to the use of a Long-Short Term Memory (LSTM) network. We evaluated the performance of our method on Detection of Traffic Anomaly (DoTA) dataset, a challenging collection of dash-mounted camera videos of accidents. After an extensive ablation study, MOVAD is able to reach an AUC score of 82.11%, surpassing the current state-of-the-art by +2.81 AUC. Our code will be available on https://github.com/IMPLabUniPr/movad/tree/icip
LDD: A Dataset for Grape Diseases Object Detection and Instance Segmentation
Jun 21, 2022The Instance Segmentation task, an extension of the well-known Object Detection task, is of great help in many areas, such as precision agriculture: being able to automatically identify plant organs and the possible diseases associated with them, allows to effectively scale and automate crop monitoring and its diseases control. To address the problem related to early disease detection and diagnosis on vines plants, a new dataset has been created with the goal of advancing the state-of-the-art of diseases recognition via instance segmentation approaches. This was achieved by gathering images of leaves and clusters of grapes affected by diseases in their natural context. The dataset contains photos of 10 object types which include leaves and grapes with and without symptoms of the eight more common grape diseases, with a total of 17,706 labeled instances in 1,092 images. Multiple statistical measures are proposed in order to offer a complete view on the characteristics of the dataset. Preliminary results for the object detection and instance segmentation tasks reached by the models Mask R-CNN and R^3-CNN are provided as baseline, demonstrating that the procedure is able to reach promising results about the objective of automatic diseases' symptoms recognition.
Improving Localization for Semi-Supervised Object Detection
Jun 21, 2022Nowadays, Semi-Supervised Object Detection (SSOD) is a hot topic, since, while it is rather easy to collect images for creating a new dataset, labeling them is still an expensive and time-consuming task. One of the successful methods to take advantage of raw images on a Semi-Supervised Learning (SSL) setting is the Mean Teacher technique, where the operations of pseudo-labeling by the Teacher and the Knowledge Transfer from the Student to the Teacher take place simultaneously. However, the pseudo-labeling by thresholding is not the best solution since the confidence value is not strictly related to the prediction uncertainty, not permitting to safely filter predictions. In this paper, we introduce an additional classification task for bounding box localization to improve the filtering of the predicted bounding boxes and obtain higher quality on Student training. Furthermore, we empirically prove that bounding box regression on the unsupervised part can equally contribute to the training as much as category classification. Our experiments show that our IL-net (Improving Localization net) increases SSOD performance by 1.14% AP on COCO dataset in limited-annotation regime. The code is available at https://github.com/IMPLabUniPr/unbiased-teacher/tree/ilnet
AEDA: An Easier Data Augmentation Technique for Text Classification
Aug 30, 2021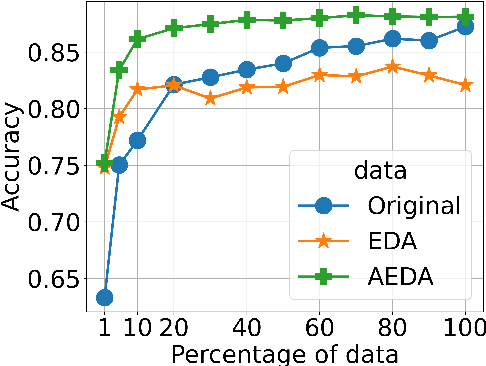
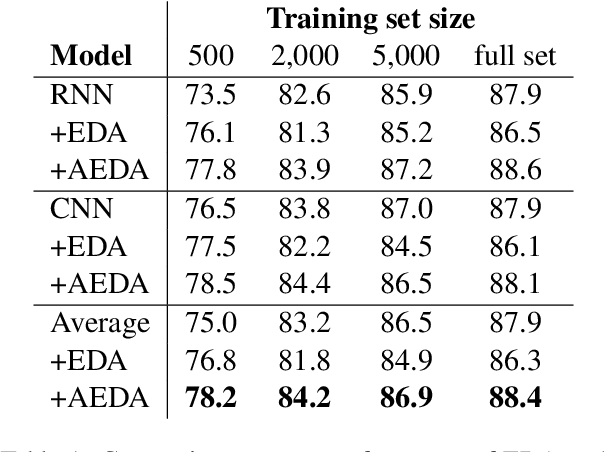

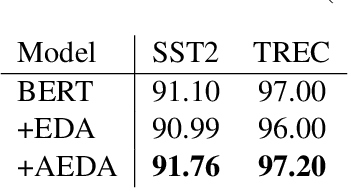
This paper proposes AEDA (An Easier Data Augmentation) technique to help improve the performance on text classification tasks. AEDA includes only random insertion of punctuation marks into the original text. This is an easier technique to implement for data augmentation than EDA method (Wei and Zou, 2019) with which we compare our results. In addition, it keeps the order of the words while changing their positions in the sentence leading to a better generalized performance. Furthermore, the deletion operation in EDA can cause loss of information which, in turn, misleads the network, whereas AEDA preserves all the input information. Following the baseline, we perform experiments on five different datasets for text classification. We show that using the AEDA-augmented data for training, the models show superior performance compared to using the EDA-augmented data in all five datasets. The source code is available for further study and reproduction of the results.