 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKurt Shuster
Open-Domain Conversational Agents: Current Progress, Open Problems, and Future Directions
Jun 22, 2020
We present our view of what is necessary to build an engaging open-domain conversational agent: covering the qualities of such an agent, the pieces of the puzzle that have been built so far, and the gaping holes we have not filled yet. We present a biased view, focusing on work done by our own group, while citing related work in each area. In particular, we discuss in detail the properties of continual learning, providing engaging content, and being well-behaved -- and how to measure success in providing them. We end with a discussion of our experience and learnings, and our recommendations to the community.
Recipes for building an open-domain chatbot
Apr 30, 2020
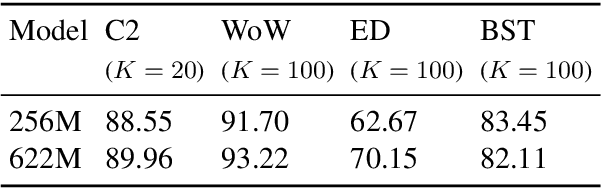
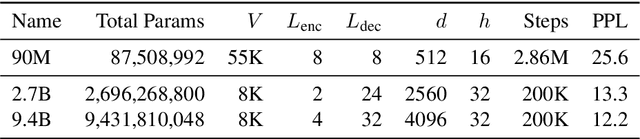
Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that scaling neural models in the number of parameters and the size of the data they are trained on gives improved results, we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to their partners, and displaying knowledge, empathy and personality appropriately, while maintaining a consistent persona. We show that large scale models can learn these skills when given appropriate training data and choice of generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter models, and make our models and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing failure cases of our models.
Can You Put it All Together: Evaluating Conversational Agents' Ability to Blend Skills
Apr 17, 2020

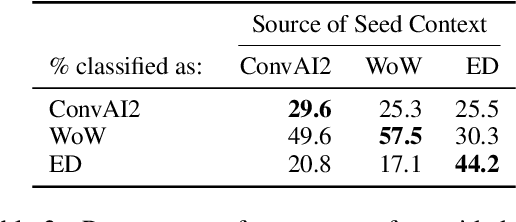
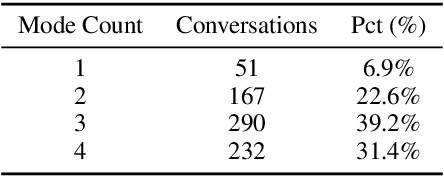
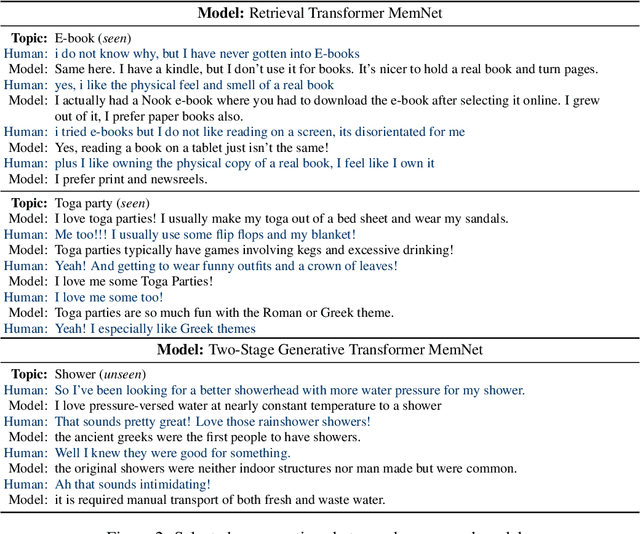
Being engaging, knowledgeable, and empathetic are all desirable general qualities in a conversational agent. Previous work has introduced tasks and datasets that aim to help agents to learn those qualities in isolation and gauge how well they can express them. But rather than being specialized in one single quality, a good open-domain conversational agent should be able to seamlessly blend them all into one cohesive conversational flow. In this work, we investigate several ways to combine models trained towards isolated capabilities, ranging from simple model aggregation schemes that require minimal additional training, to various forms of multi-task training that encompass several skills at all training stages. We further propose a new dataset, BlendedSkillTalk, to analyze how these capabilities would mesh together in a natural conversation, and compare the performance of different architectures and training schemes. Our experiments show that multi-tasking over several tasks that focus on particular capabilities results in better blended conversation performance compared to models trained on a single skill, and that both unified or two-stage approaches perform well if they are constructed to avoid unwanted bias in skill selection or are fine-tuned on our new task.
All-in-One Image-Grounded Conversational Agents
Jan 15, 2020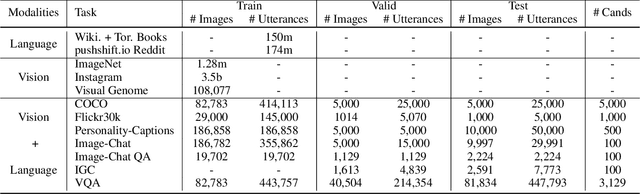
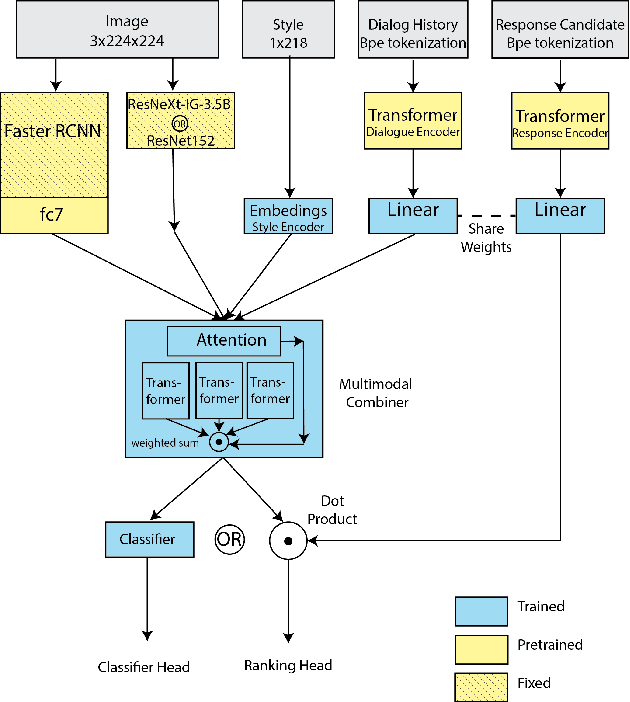
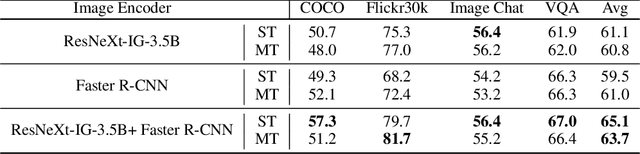
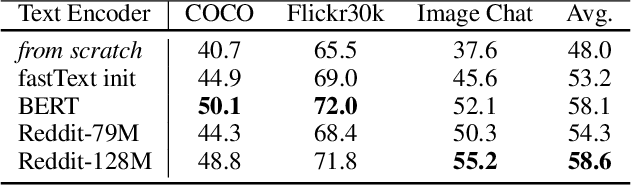
As single-task accuracy on individual language and image tasks has improved substantially in the last few years, the long-term goal of a generally skilled agent that can both see and talk becomes more feasible to explore. In this work, we focus on leveraging individual language and image tasks, along with resources that incorporate both vision and language towards that objective. We design an architecture that combines state-of-the-art Transformer and ResNeXt modules fed into a novel attentive multimodal module to produce a combined model trained on many tasks. We provide a thorough analysis of the components of the model, and transfer performance when training on one, some, or all of the tasks. Our final models provide a single system that obtains good results on all vision and language tasks considered, and improves the state-of-the-art in image-grounded conversational applications.
The Dialogue Dodecathlon: Open-Domain Knowledge and Image Grounded Conversational Agents
Nov 09, 2019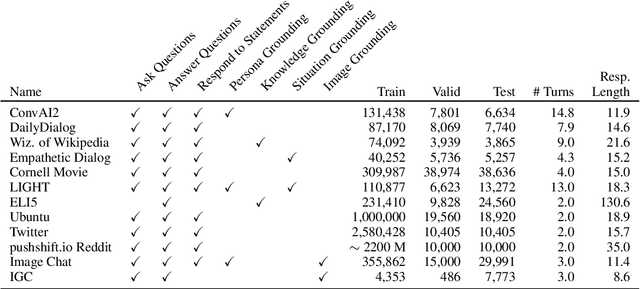
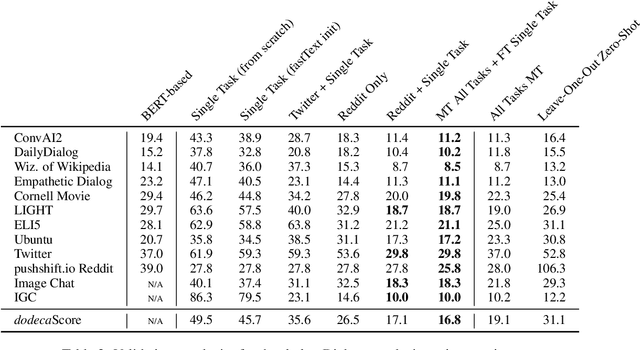
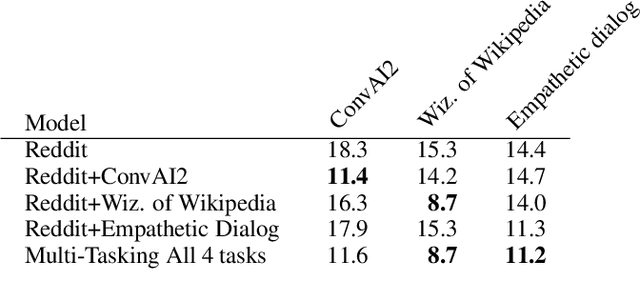

We introduce dodecaDialogue: a set of 12 tasks that measures if a conversational agent can communicate engagingly with personality and empathy, ask questions, answer questions by utilizing knowledge resources, discuss topics and situations, and perceive and converse about images. By multi-tasking on such a broad large-scale set of data, we hope to both move towards and measure progress in producing a single unified agent that can perceive, reason and converse with humans in an open-domain setting. We show that such multi-tasking improves over a BERT pre-trained baseline, largely due to multi-tasking with very large dialogue datasets in a similar domain, and that the multi-tasking in general provides gains to both text and image-based tasks using several metrics in both the fine-tune and task transfer settings. We obtain state-of-the-art results on many of the tasks, providing a strong baseline for this challenge.
Real-time Inference in Multi-sentence Tasks with Deep Pretrained Transformers
Apr 22, 2019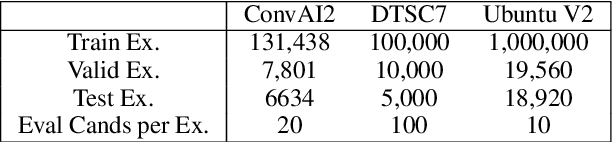
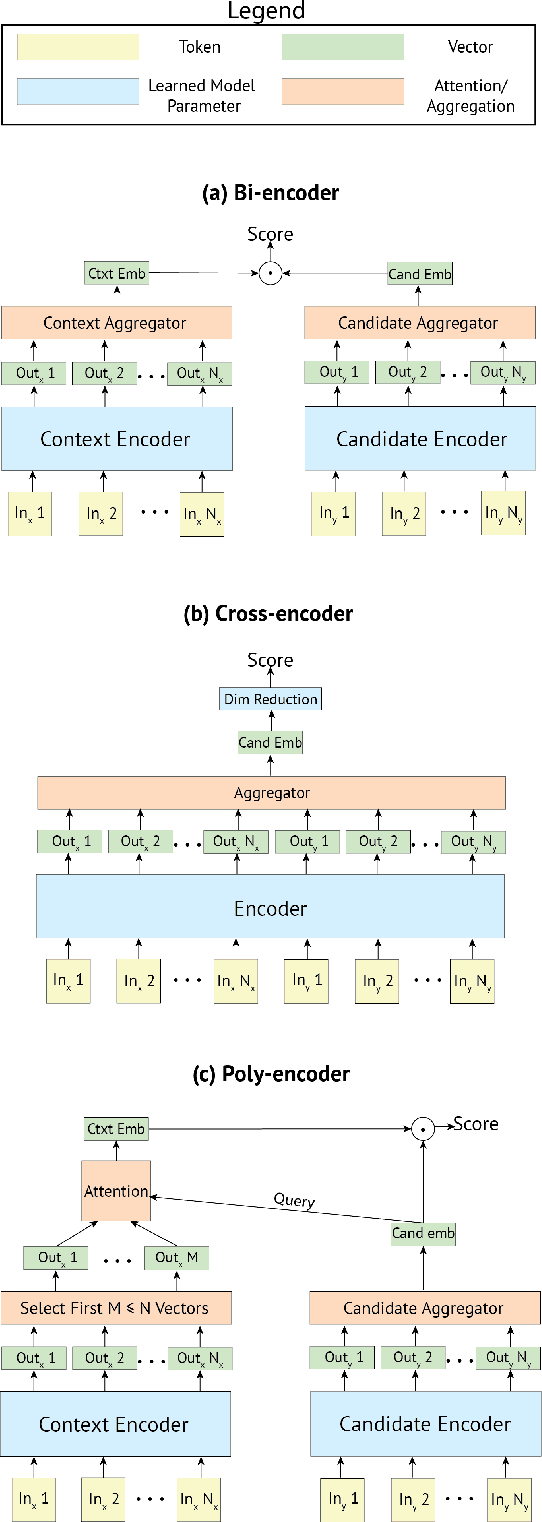

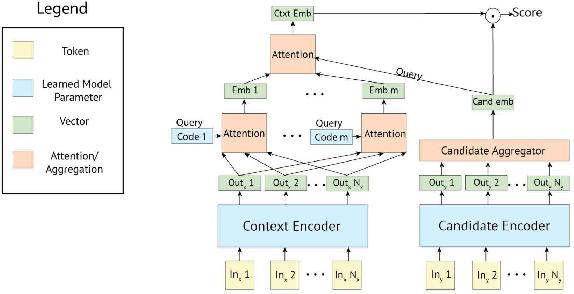
The use of deep pretrained bidirectional transformers has led to remarkable progress in learning multi-sentence representations for downstream language understanding tasks (Devlin et al., 2018). For tasks that make pairwise comparisons, e.g. matching a given context with a corresponding response, two approaches have permeated the literature. A Cross-encoder performs full self-attention over the pair; a Bi-encoder performs self-attention for each sequence separately, and the final representation is a function of the pair. While Cross-encoders nearly always outperform Bi-encoders on various tasks, both in our work and others' (Urbanek et al., 2019), they are orders of magnitude slower, which hampers their ability to perform real-time inference. In this work, we develop a new architecture, the Poly-encoder, that is designed to approach the performance of the Cross-encoder while maintaining reasonable computation time. Additionally, we explore two pretraining schemes with different datasets to determine how these affect the performance on our chosen dialogue tasks: ConvAI2 and DSTC7 Track 1. We show that our models achieve state-of-the-art results on both tasks; that the Poly-encoder is a suitable replacement for Bi-encoders and Cross-encoders; and that even better results can be obtained by pretraining on a large dialogue dataset.
The Second Conversational Intelligence Challenge (ConvAI2)
Jan 31, 2019

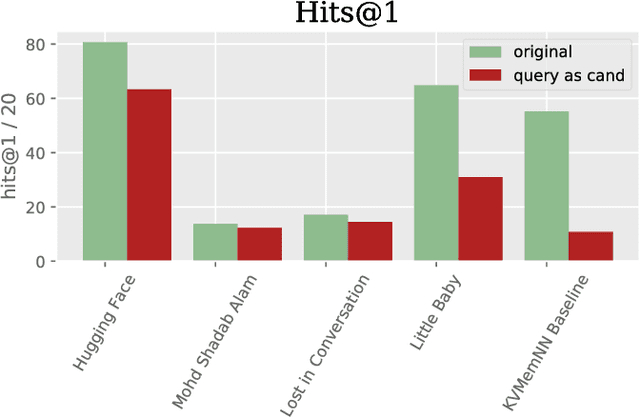
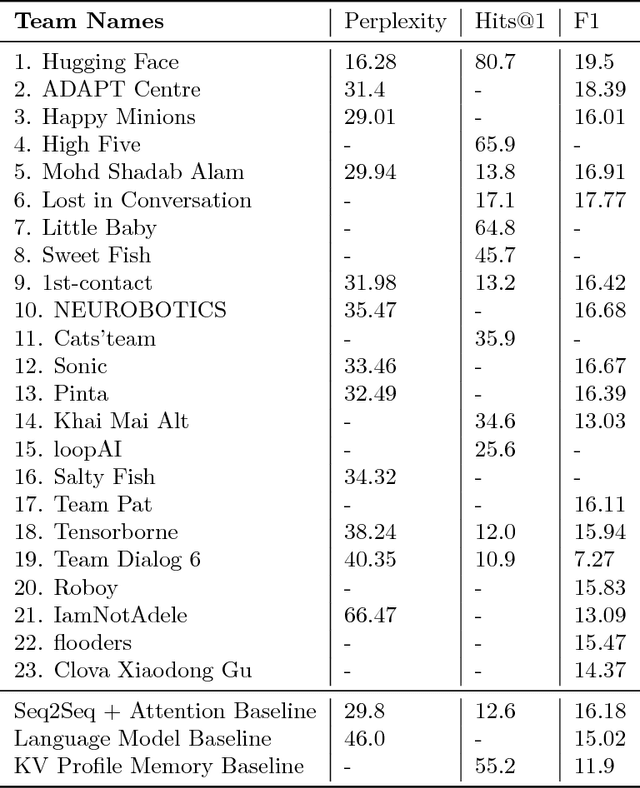
We describe the setting and results of the ConvAI2 NeurIPS competition that aims to further the state-of-the-art in open-domain chatbots. Some key takeaways from the competition are: (i) pretrained Transformer variants are currently the best performing models on this task, (ii) but to improve performance on multi-turn conversations with humans, future systems must go beyond single word metrics like perplexity to measure the performance across sequences of utterances (conversations) -- in terms of repetition, consistency and balance of dialogue acts (e.g. how many questions asked vs. answered).
Wizard of Wikipedia: Knowledge-Powered Conversational agents
Nov 03, 2018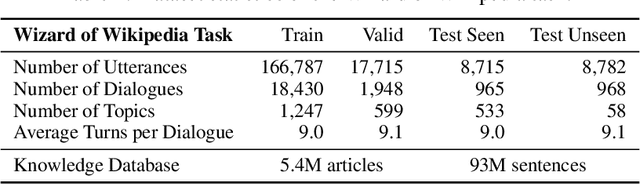
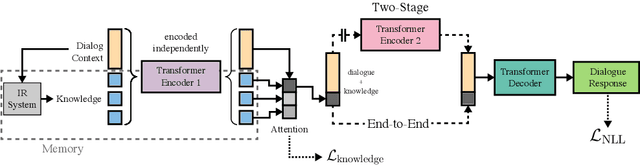

In open-domain dialogue intelligent agents should exhibit the use of knowledge, however there are few convincing demonstrations of this to date. The most popular sequence to sequence models typically "generate and hope" generic utterances that can be memorized in the weights of the model when mapping from input utterance(s) to output, rather than employing recalled knowledge as context. Use of knowledge has so far proved difficult, in part because of the lack of a supervised learning benchmark task which exhibits knowledgeable open dialogue with clear grounding. To that end we collect and release a large dataset with conversations directly grounded with knowledge retrieved from Wikipedia. We then design architectures capable of retrieving knowledge, reading and conditioning on it, and finally generating natural responses. Our best performing dialogue models are able to conduct knowledgeable discussions on open-domain topics as evaluated by automatic metrics and human evaluations, while our new benchmark allows for measuring further improvements in this important research direction.
Engaging Image Chat: Modeling Personality in Grounded Dialogue
Nov 02, 2018
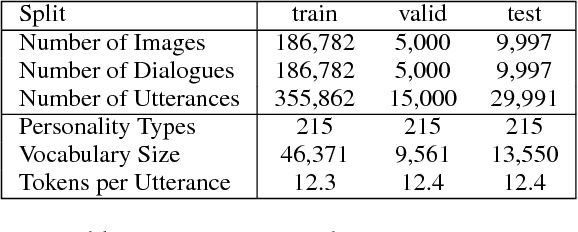
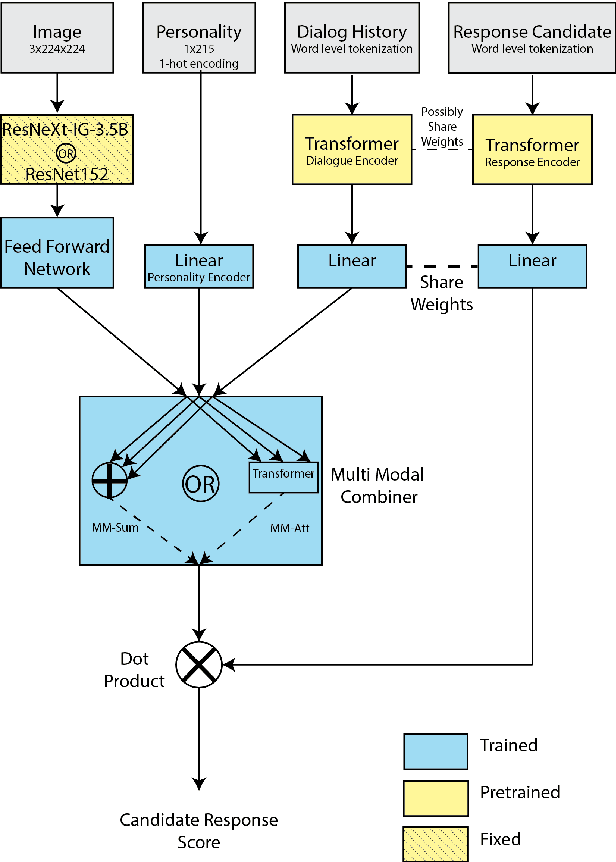

To achieve the long-term goal of machines being able to engage humans in conversation, our models should be engaging. We focus on communication grounded in images, whereby a dialogue is conducted based on a given photo, a setup that is naturally engaging to humans (Hu et al., 2014). We collect a large dataset of grounded human-human conversations, where humans are asked to play the role of a given personality, as the use of personality in conversation has also been shown to be engaging (Shuster et al., 2018). Our dataset, Image-Chat, consists of 202k dialogues and 401k utterances over 202k images using 215 possible personality traits. We then design a set of natural architectures using state-of-the-art image and text representations, considering various ways to fuse the components. Automatic metrics and human evaluations show the efficacy of approach, in particular where our best performing model is preferred over human conversationalists 47.7% of the time