 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKristen Grauman
Learning Spherical Convolution for Fast Features from 360° Imagery
Jan 29, 2018
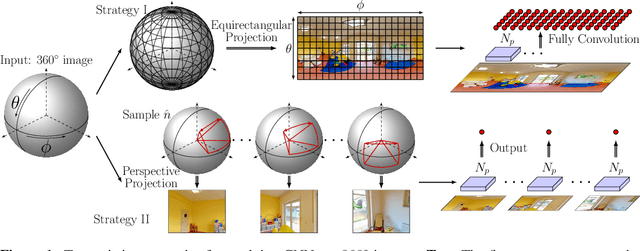

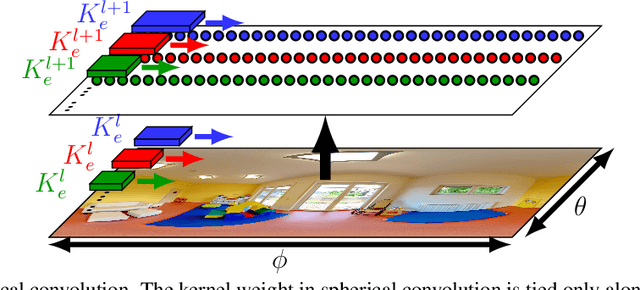
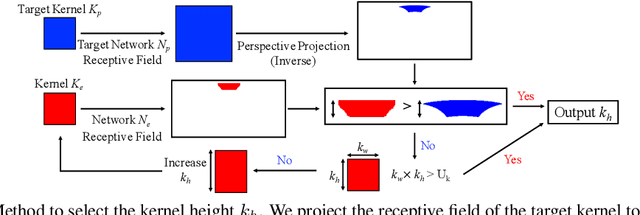
While 360{\deg} cameras offer tremendous new possibilities in vision, graphics, and augmented reality, the spherical images they produce make core feature extraction non-trivial. Convolutional neural networks (CNNs) trained on images from perspective cameras yield "flat" filters, yet 360{\deg} images cannot be projected to a single plane without significant distortion. A naive solution that repeatedly projects the viewing sphere to all tangent planes is accurate, but much too computationally intensive for real problems. We propose to learn a spherical convolutional network that translates a planar CNN to process 360{\deg} imagery directly in its equirectangular projection. Our approach learns to reproduce the flat filter outputs on 360{\deg} data, sensitive to the varying distortion effects across the viewing sphere. The key benefits are 1) efficient feature extraction for 360{\deg} images and video, and 2) the ability to leverage powerful pre-trained networks researchers have carefully honed (together with massive labeled image training sets) for perspective images. We validate our approach compared to several alternative methods in terms of both raw CNN output accuracy as well as applying a state-of-the-art "flat" object detector to 360{\deg} data. Our method yields the most accurate results while saving orders of magnitude in computation versus the existing exact reprojection solution.
Learning Compressible 360° Video Isomers
Dec 12, 2017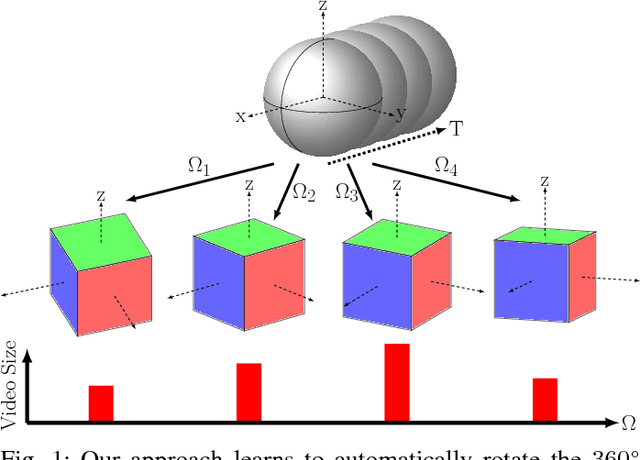
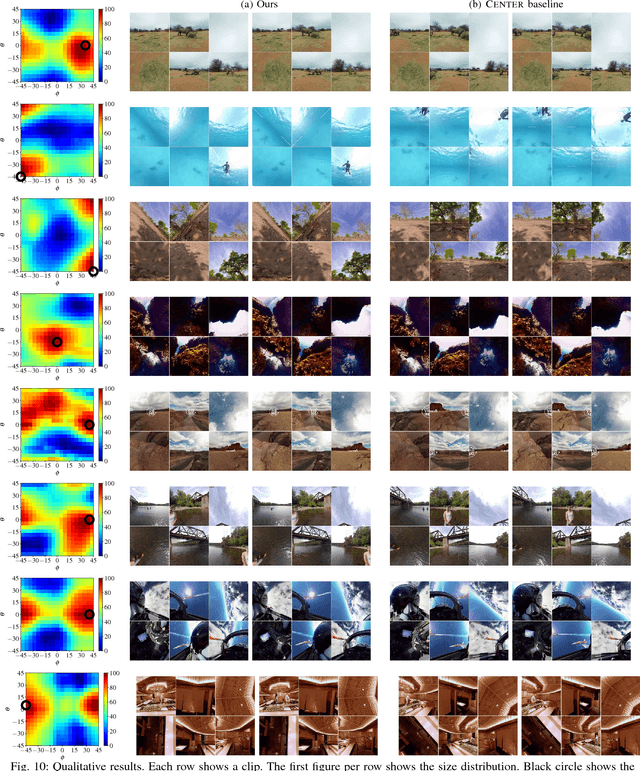


Standard video encoders developed for conventional narrow field-of-view video are widely applied to 360{\deg} video as well, with reasonable results. However, while this approach commits arbitrarily to a projection of the spherical frames, we observe that some orientations of a 360{\deg} video, once projected, are more compressible than others. We introduce an approach to predict the sphere rotation that will yield the maximal compression rate. Given video clips in their original encoding, a convolutional neural network learns the association between a clip's visual content and its compressibility at different rotations of a cubemap projection. Given a novel video, our learning-based approach efficiently infers the most compressible direction in one shot, without repeated rendering and compression of the source video. We validate our idea on thousands of video clips and multiple popular video codecs. The results show that this untapped dimension of 360{\deg} compression has substantial potential--"good" rotations are typically 8-10% more compressible than bad ones, and our learning approach can predict them reliably 82% of the time.
Fashion Forward: Forecasting Visual Style in Fashion
Aug 03, 2017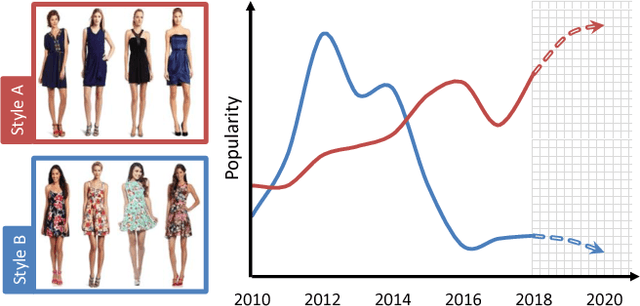

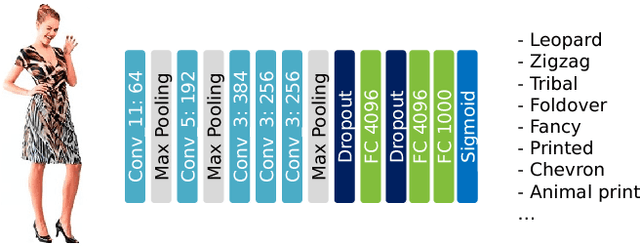
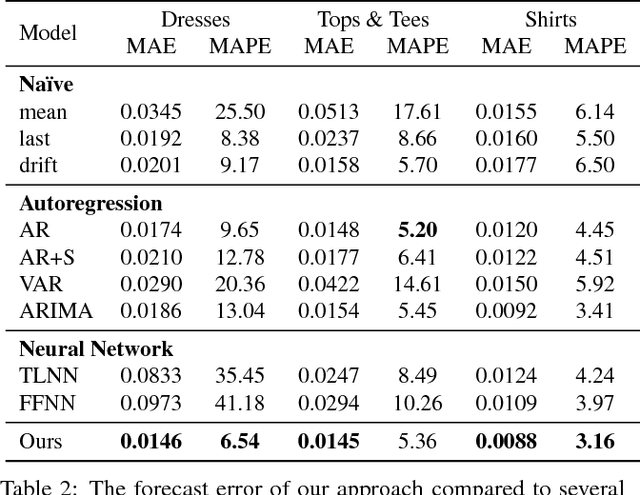
What is the future of fashion? Tackling this question from a data-driven vision perspective, we propose to forecast visual style trends before they occur. We introduce the first approach to predict the future popularity of styles discovered from fashion images in an unsupervised manner. Using these styles as a basis, we train a forecasting model to represent their trends over time. The resulting model can hypothesize new mixtures of styles that will become popular in the future, discover style dynamics (trendy vs. classic), and name the key visual attributes that will dominate tomorrow's fashion. We demonstrate our idea applied to three datasets encapsulating 80,000 fashion products sold across six years on Amazon. Results indicate that fashion forecasting benefits greatly from visual analysis, much more than textual or meta-data cues surrounding products.
Learning the Latent "Look": Unsupervised Discovery of a Style-Coherent Embedding from Fashion Images
Aug 03, 2017
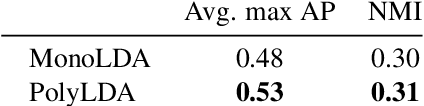
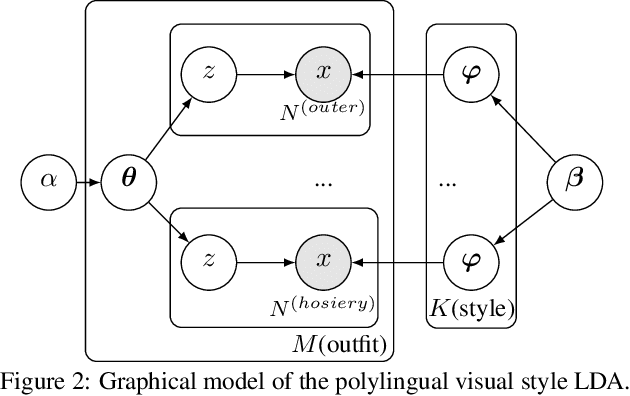
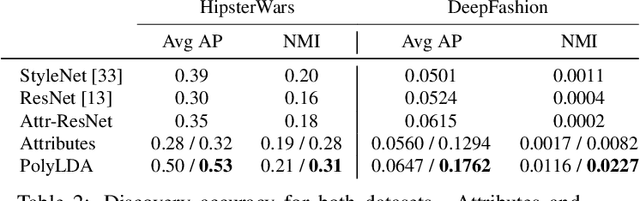
What defines a visual style? Fashion styles emerge organically from how people assemble outfits of clothing, making them difficult to pin down with a computational model. Low-level visual similarity can be too specific to detect stylistically similar images, while manually crafted style categories can be too abstract to capture subtle style differences. We propose an unsupervised approach to learn a style-coherent representation. Our method leverages probabilistic polylingual topic models based on visual attributes to discover a set of latent style factors. Given a collection of unlabeled fashion images, our approach mines for the latent styles, then summarizes outfits by how they mix those styles. Our approach can organize galleries of outfits by style without requiring any style labels. Experiments on over 100K images demonstrate its promise for retrieving, mixing, and summarizing fashion images by their style.
On-Demand Learning for Deep Image Restoration
Aug 02, 2017
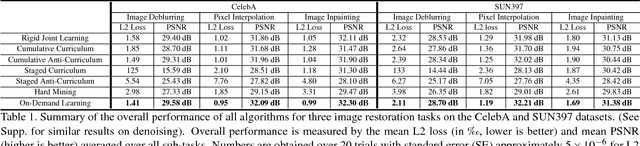

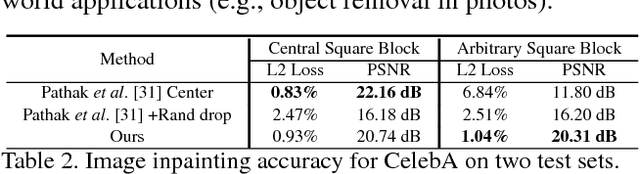
While machine learning approaches to image restoration offer great promise, current methods risk training models fixated on performing well only for image corruption of a particular level of difficulty---such as a certain level of noise or blur. First, we examine the weakness of conventional "fixated" models and demonstrate that training general models to handle arbitrary levels of corruption is indeed non-trivial. Then, we propose an on-demand learning algorithm for training image restoration models with deep convolutional neural networks. The main idea is to exploit a feedback mechanism to self-generate training instances where they are needed most, thereby learning models that can generalize across difficulty levels. On four restoration tasks---image inpainting, pixel interpolation, image deblurring, and image denoising---and three diverse datasets, our approach consistently outperforms both the status quo training procedure and curriculum learning alternatives.
Making 360$^{\circ}$ Video Watchable in 2D: Learning Videography for Click Free Viewing
May 24, 2017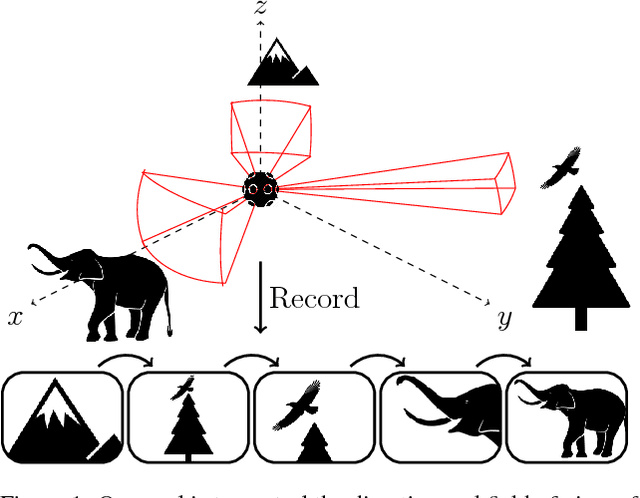


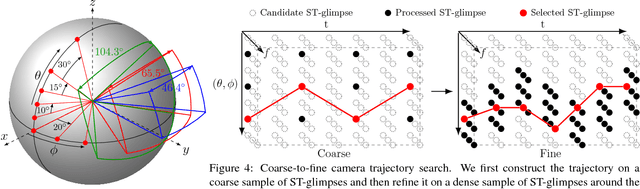
360$^{\circ}$ video requires human viewers to actively control "where" to look while watching the video. Although it provides a more immersive experience of the visual content, it also introduces additional burden for viewers; awkward interfaces to navigate the video lead to suboptimal viewing experiences. Virtual cinematography is an appealing direction to remedy these problems, but conventional methods are limited to virtual environments or rely on hand-crafted heuristics. We propose a new algorithm for virtual cinematography that automatically controls a virtual camera within a 360$^{\circ}$ video. Compared to the state of the art, our algorithm allows more general camera control, avoids redundant outputs, and extracts its output videos substantially more efficiently. Experimental results on over 7 hours of real "in the wild" video show that our generalized camera control is crucial for viewing 360$^{\circ}$ video, while the proposed efficient algorithm is essential for making the generalized control computationally tractable.
Predicting Foreground Object Ambiguity and Efficiently Crowdsourcing the Segmentation(s)
Apr 30, 2017
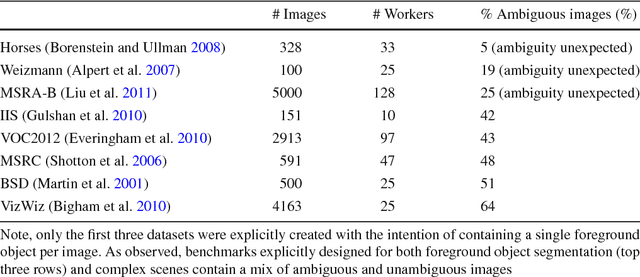


We propose the ambiguity problem for the foreground object segmentation task and motivate the importance of estimating and accounting for this ambiguity when designing vision systems. Specifically, we distinguish between images which lead multiple annotators to segment different foreground objects (ambiguous) versus minor inter-annotator differences of the same object. Taking images from eight widely used datasets, we crowdsource labeling the images as "ambiguous" or "not ambiguous" to segment in order to construct a new dataset we call STATIC. Using STATIC, we develop a system that automatically predicts which images are ambiguous. Experiments demonstrate the advantage of our prediction system over existing saliency-based methods on images from vision benchmarks and images taken by blind people who are trying to recognize objects in their environment. Finally, we introduce a crowdsourcing system to achieve cost savings for collecting the diversity of all valid "ground truth" foreground object segmentations by collecting extra segmentations only when ambiguity is expected. Experiments show our system eliminates up to 47% of human effort compared to existing crowdsourcing methods with no loss in capturing the diversity of ground truths.
Semantic Jitter: Dense Supervision for Visual Comparisons via Synthetic Images
Apr 27, 2017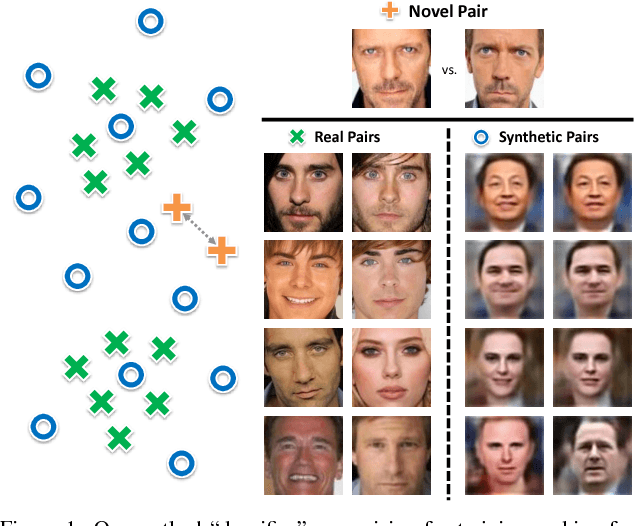
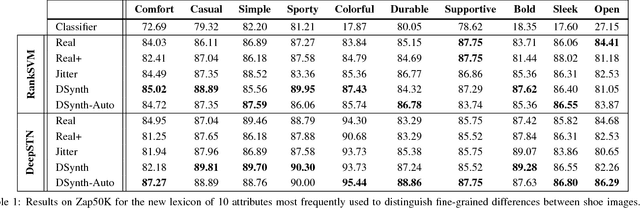
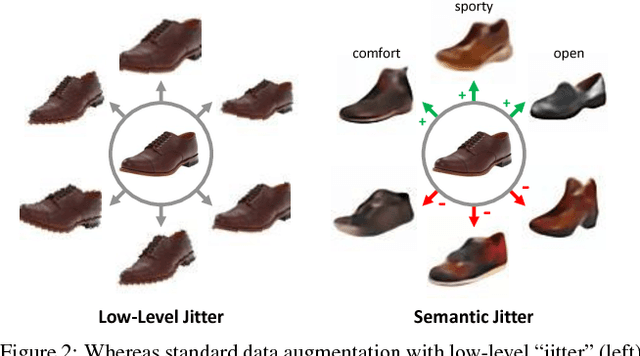
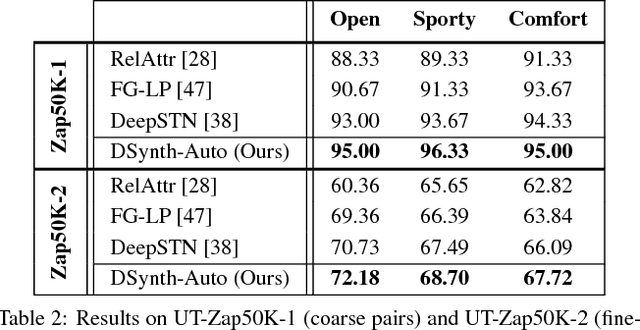
Distinguishing subtle differences in attributes is valuable, yet learning to make visual comparisons remains non-trivial. Not only is the number of possible comparisons quadratic in the number of training images, but also access to images adequately spanning the space of fine-grained visual differences is limited. We propose to overcome the sparsity of supervision problem via synthetically generated images. Building on a state-of-the-art image generation engine, we sample pairs of training images exhibiting slight modifications of individual attributes. Augmenting real training image pairs with these examples, we then train attribute ranking models to predict the relative strength of an attribute in novel pairs of real images. Our results on datasets of faces and fashion images show the great promise of bootstrapping imperfect image generators to counteract sample sparsity for learning to rank.
Pixel Objectness
Apr 12, 2017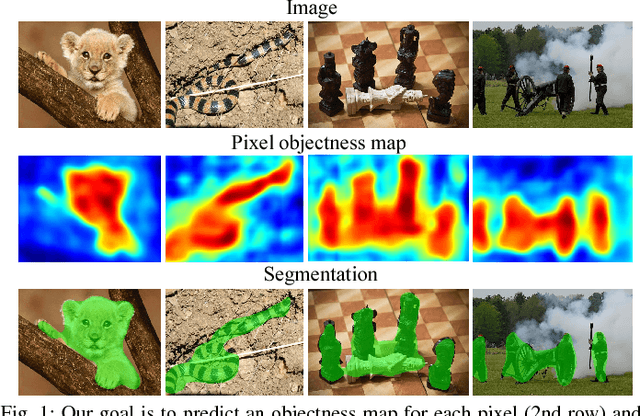



We propose an end-to-end learning framework for generating foreground object segmentations. Given a single novel image, our approach produces pixel-level masks for all "object-like" regions---even for object categories never seen during training. We formulate the task as a structured prediction problem of assigning foreground/background labels to all pixels, implemented using a deep fully convolutional network. Key to our idea is training with a mix of image-level object category examples together with relatively few images with boundary-level annotations. Our method substantially improves the state-of-the-art on foreground segmentation for ImageNet and MIT Object Discovery datasets. Furthermore, on over 1 million images, we show that it generalizes well to segment object categories unseen in the foreground maps used for training. Finally, we demonstrate how our approach benefits image retrieval and image retargeting, both of which flourish when given our high-quality foreground maps.
FusionSeg: Learning to combine motion and appearance for fully automatic segmention of generic objects in videos
Apr 12, 2017

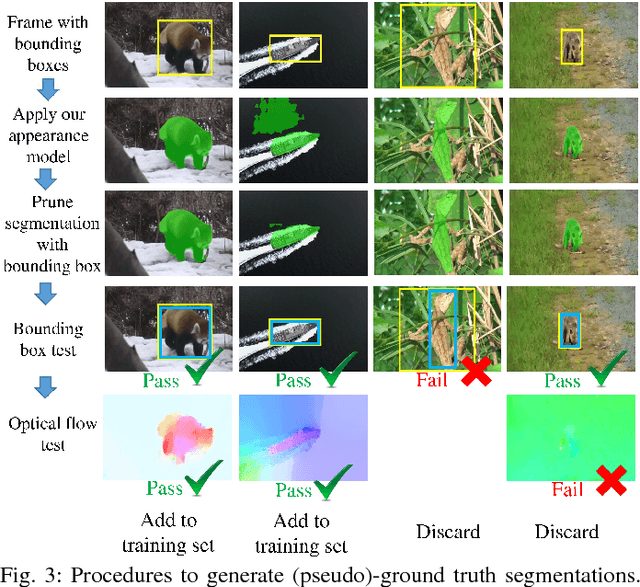

We propose an end-to-end learning framework for segmenting generic objects in videos. Our method learns to combine appearance and motion information to produce pixel level segmentation masks for all prominent objects in videos. We formulate this task as a structured prediction problem and design a two-stream fully convolutional neural network which fuses together motion and appearance in a unified framework. Since large-scale video datasets with pixel level segmentations are problematic, we show how to bootstrap weakly annotated videos together with existing image recognition datasets for training. Through experiments on three challenging video segmentation benchmarks, our method substantially improves the state-of-the-art for segmenting generic (unseen) objects. Code and pre-trained models are available on the project website.