 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Models of Human Interaction in Immersive Simulation Settings
Sep 24, 2019
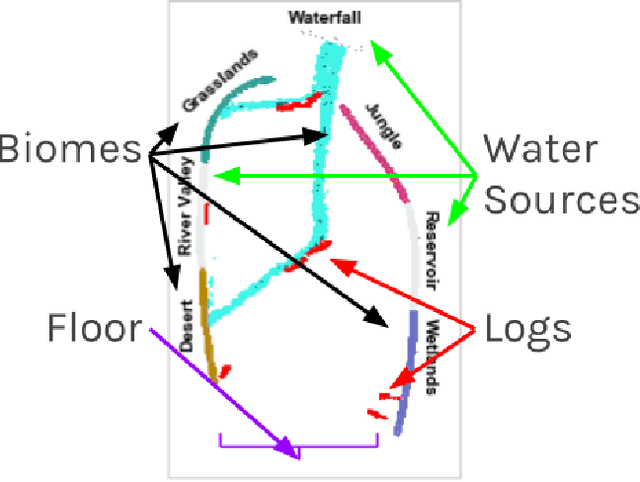
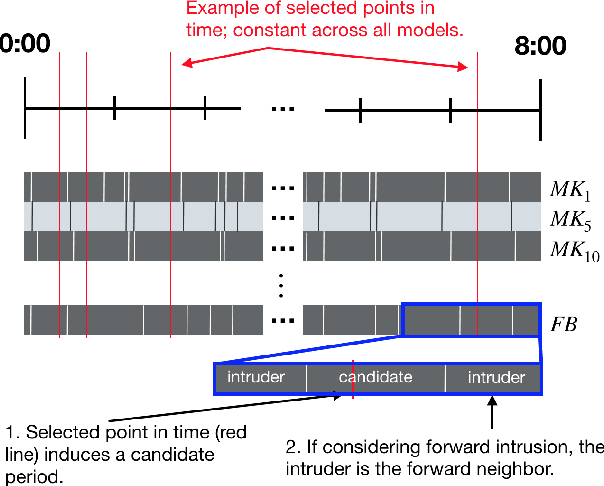
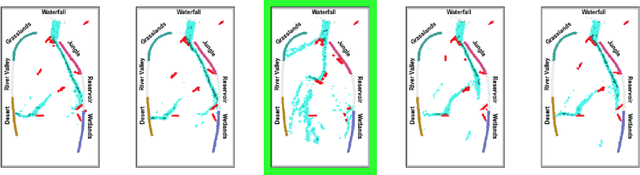
Immersive simulations are increasingly used for teaching and training in many societally important arenas including healthcare, disaster response and science education. The interactions of participants in such settings lead to a complex array of emergent outcomes that present challenges for analysis. This paper studies a central element of such an analysis, namely the interpretability of models for inferring structure in time series data. This problem is explored in the context of modeling student interactions in an immersive ecological-system simulation. Unsupervised machine learning is applied to data on system dynamics with the aim of helping teachers determine the effects of students' actions on these dynamics. We address the question of choosing the optimal machine learning model, considering both statistical information criteria and interpretabilty quality. Our approach adapts two interpretability tests from the literature that measure the agreement between the model output and human judgment. The results of a user study show that the models that are the best understood by people are not those that optimize information theoretic criteria. In addition, a model using a fully Bayesian approach performed well on both statistical measures and on human-subject tests of interpretabilty, making it a good candidate for automated model selection that does not require human-in-the-loop evaluation. The results from this paper are already being used in the classroom and can inform the design of interpretable models for a broad range of socially relevant domains.
A difficulty ranking approach to personalization in E-learning
Jul 28, 2019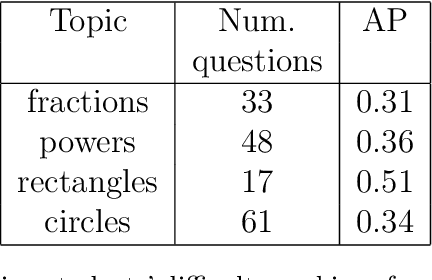
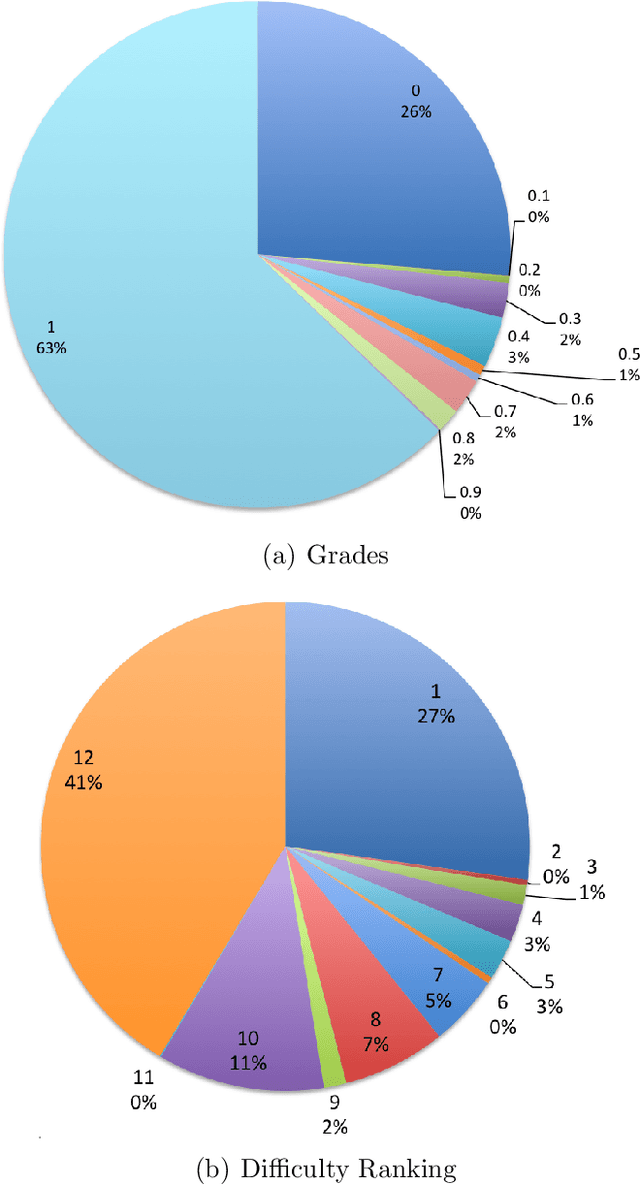

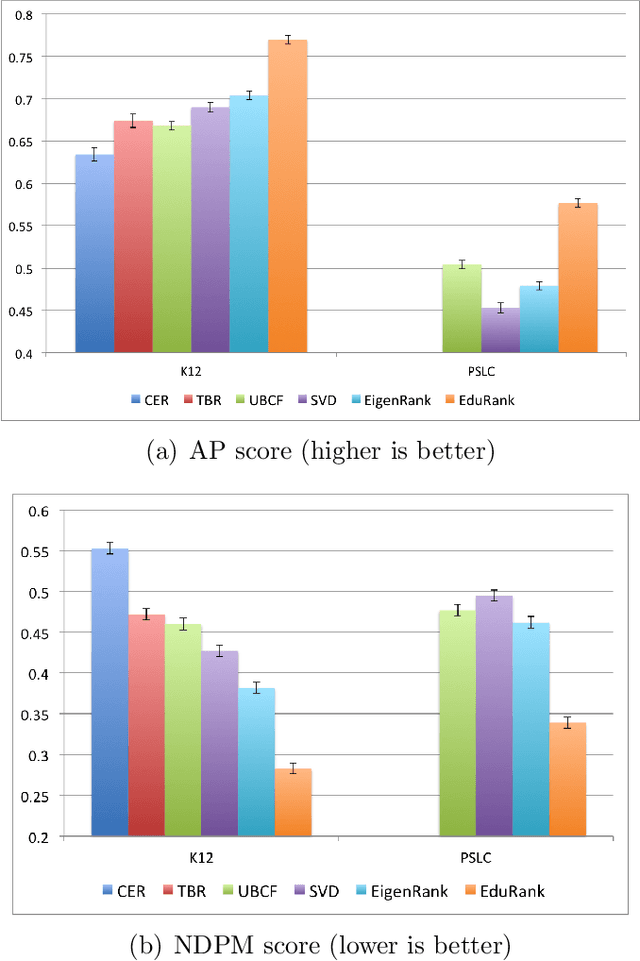
The prevalence of e-learning systems and on-line courses has made educational material widely accessible to students of varying abilities and backgrounds. There is thus a growing need to accommodate for individual differences in e-learning systems. This paper presents an algorithm called EduRank for personalizing educational content to students that combines a collaborative filtering algorithm with voting methods. EduRank constructs a difficulty ranking for each student by aggregating the rankings of similar students using different aspects of their performance on common questions. These aspects include grades, number of retries, and time spent solving questions. It infers a difficulty ranking directly over the questions for each student, rather than ordering them according to the student's predicted score. The EduRank algorithm was tested on two data sets containing thousands of students and a million records. It was able to outperform the state-of-the-art ranking approaches as well as a domain expert. EduRank was used by students in a classroom activity, where a prior model was incorporated to predict the difficulty rankings of students with no prior history in the system. It was shown to lead students to solve more difficult questions than an ordering by a domain expert, without reducing their performance.
Combining Difficulty Ranking with Multi-Armed Bandits to Sequence Educational Content
Apr 14, 2018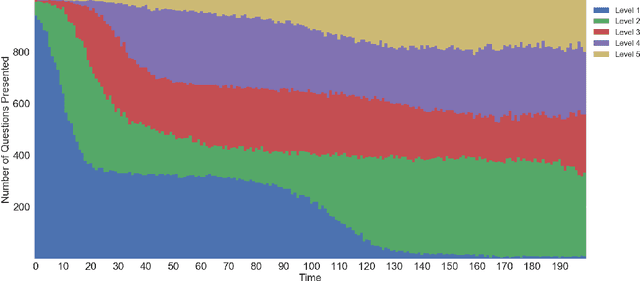

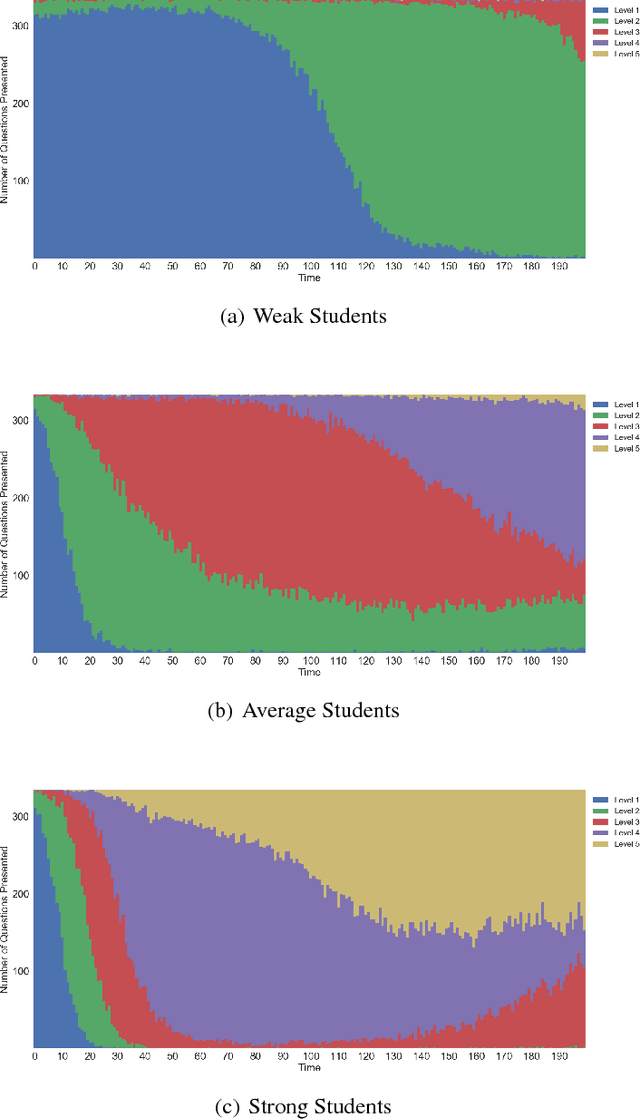
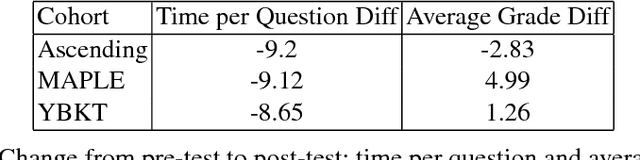
As e-learning systems become more prevalent, there is a growing need for them to accommodate individual differences between students. This paper addresses the problem of how to personalize educational content to students in order to maximize their learning gains over time. We present a new computational approach to this problem called MAPLE (Multi-Armed Bandits based Personalization for Learning Environments) that combines difficulty ranking with multi-armed bandits. Given a set of target questions MAPLE estimates the expected learning gains for each question and uses an exploration-exploitation strategy to choose the next question to pose to the student. It maintains a personalized ranking over the difficulties of question in the target set which is used in two ways: First, to obtain initial estimates over the learning gains for the set of questions. Second, to update the estimates over time based on the students responses. We show in simulations that MAPLE was able to improve students' learning gains compared to approaches that sequence questions in increasing level of difficulty, or rely on content experts. When implemented in a live e-learning system in the wild, MAPLE showed promising results. This work demonstrates the efficacy of using stochastic approaches to the sequencing problem when augmented with information about question difficulty.