 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency Weighted Convolutional Features for Instance Search
Nov 29, 2017


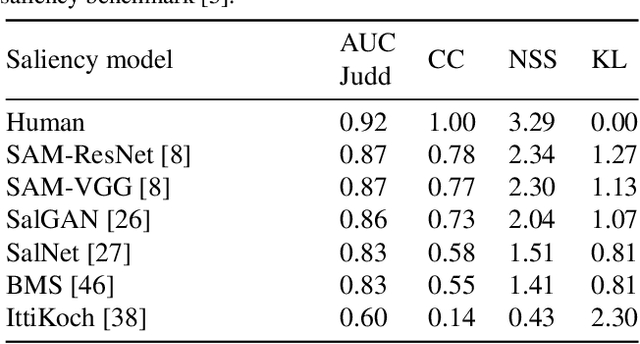
This work explores attention models to weight the contribution of local convolutional representations for the instance search task. We present a retrieval framework based on bags of local convolutional features (BLCF) that benefits from saliency weighting to build an efficient image representation. The use of human visual attention models (saliency) allows significant improvements in retrieval performance without the need to conduct region analysis or spatial verification, and without requiring any feature fine tuning. We investigate the impact of different saliency models, finding that higher performance on saliency benchmarks does not necessarily equate to improved performance when used in instance search tasks. The proposed approach outperforms the state-of-the-art on the challenging INSTRE benchmark by a large margin, and provides similar performance on the Oxford and Paris benchmarks compared to more complex methods that use off-the-shelf representations. The source code used in this project is available at https://imatge-upc.github.io/salbow/
People, Penguins and Petri Dishes: Adapting Object Counting Models To New Visual Domains And Object Types Without Forgetting
Nov 15, 2017

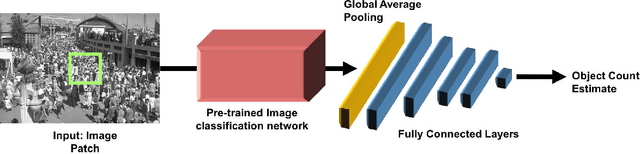
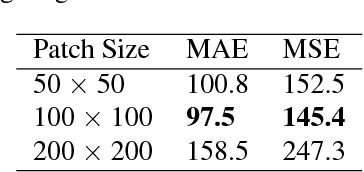
In this paper we propose a technique to adapt a convolutional neural network (CNN) based object counter to additional visual domains and object types while still preserving the original counting function. Domain-specific normalisation and scaling operators are trained to allow the model to adjust to the statistical distributions of the various visual domains. The developed adaptation technique is used to produce a singular patch-based counting regressor capable of counting various object types including people, vehicles, cell nuclei and wildlife. As part of this study a challenging new cell counting dataset in the context of tissue culture and patient diagnosis is constructed. This new collection, referred to as the Dublin Cell Counting (DCC) dataset, is the first of its kind to be made available to the wider computer vision community. State-of-the-art object counting performance is achieved in both the Shanghaitech (parts A and B) and Penguins datasets while competitive performance is observed on the TRANCOS and Modified Bone Marrow (MBM) datasets, all using a shared counting model.
SaltiNet: Scan-path Prediction on 360 Degree Images using Saliency Volumes
Aug 17, 2017
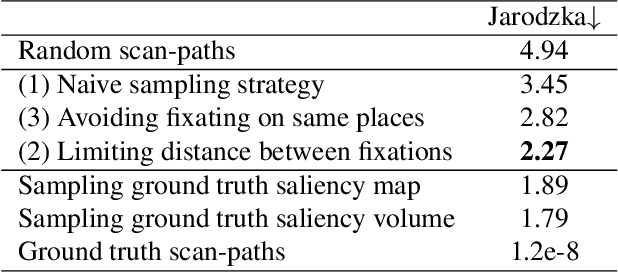
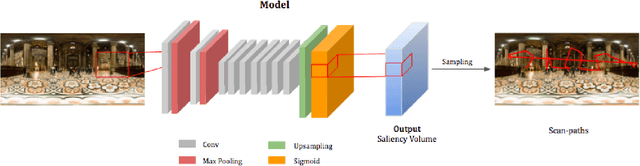

We introduce SaltiNet, a deep neural network for scanpath prediction trained on 360-degree images. The model is based on a temporal-aware novel representation of saliency information named the saliency volume. The first part of the network consists of a model trained to generate saliency volumes, whose parameters are fit by back-propagation computed from a binary cross entropy (BCE) loss over downsampled versions of the saliency volumes. Sampling strategies over these volumes are used to generate scanpaths over the 360-degree images. Our experiments show the advantages of using saliency volumes, and how they can be used for related tasks. Our source code and trained models available at https://github.com/massens/saliency-360salient-2017.
ResnetCrowd: A Residual Deep Learning Architecture for Crowd Counting, Violent Behaviour Detection and Crowd Density Level Classification
May 30, 2017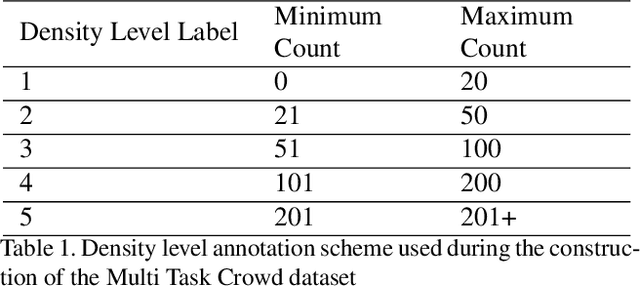


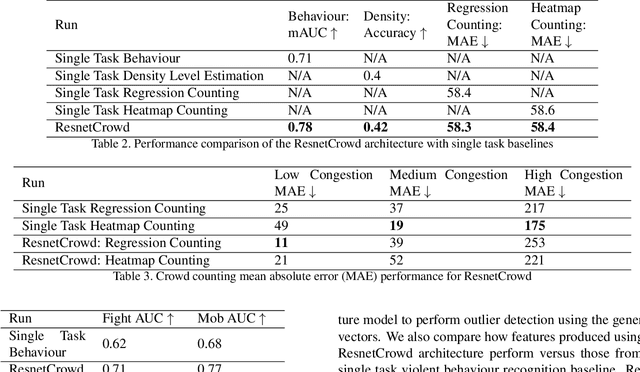
In this paper we propose ResnetCrowd, a deep residual architecture for simultaneous crowd counting, violent behaviour detection and crowd density level classification. To train and evaluate the proposed multi-objective technique, a new 100 image dataset referred to as Multi Task Crowd is constructed. This new dataset is the first computer vision dataset fully annotated for crowd counting, violent behaviour detection and density level classification. Our experiments show that a multi-task approach boosts individual task performance for all tasks and most notably for violent behaviour detection which receives a 9\% boost in ROC curve AUC (Area under the curve). The trained ResnetCrowd model is also evaluated on several additional benchmarks highlighting the superior generalisation of crowd analysis models trained for multiple objectives.
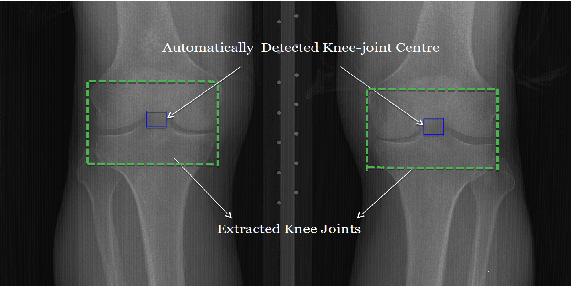
Automatic Detection of Knee Joints and Quantification of Knee Osteoarthritis Severity using Convolutional Neural Networks
Mar 29, 2017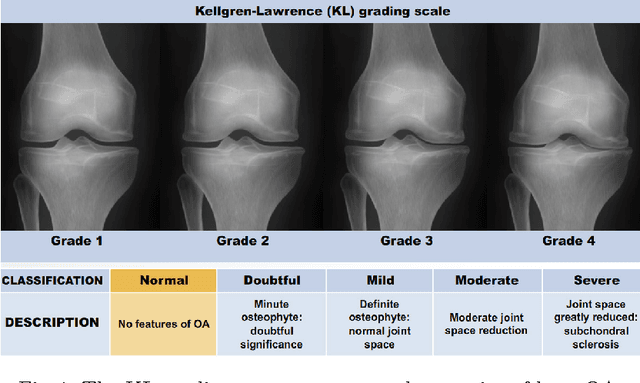

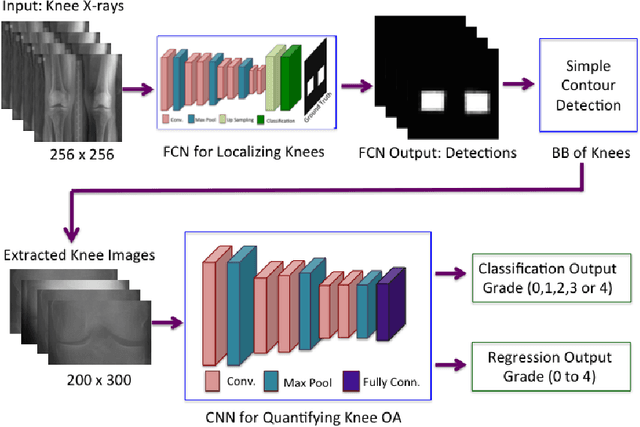

This paper introduces a new approach to automatically quantify the severity of knee OA using X-ray images. Automatically quantifying knee OA severity involves two steps: first, automatically localizing the knee joints; next, classifying the localized knee joint images. We introduce a new approach to automatically detect the knee joints using a fully convolutional neural network (FCN). We train convolutional neural networks (CNN) from scratch to automatically quantify the knee OA severity optimizing a weighted ratio of two loss functions: categorical cross-entropy and mean-squared loss. This joint training further improves the overall quantification of knee OA severity, with the added benefit of naturally producing simultaneous multi-class classification and regression outputs. Two public datasets are used to evaluate our approach, the Osteoarthritis Initiative (OAI) and the Multicenter Osteoarthritis Study (MOST), with extremely promising results that outperform existing approaches.
Where is my Phone ? Personal Object Retrieval from Egocentric Images
Mar 02, 2017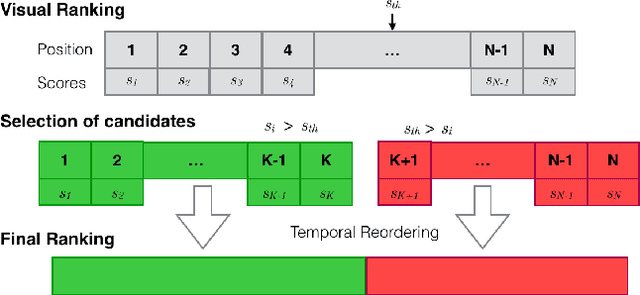
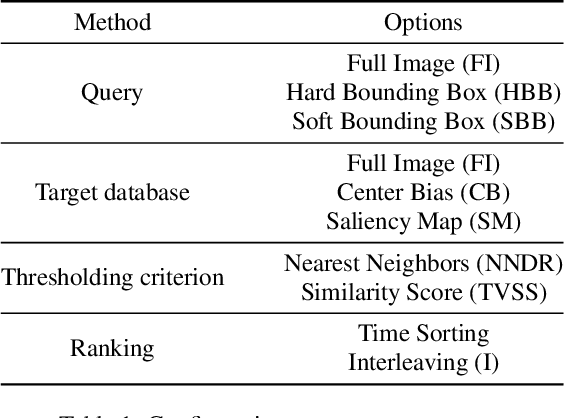


This work presents a retrieval pipeline and evaluation scheme for the problem of finding the last appearance of personal objects in a large dataset of images captured from a wearable camera. Each personal object is modelled by a small set of images that define a query for a visual search engine.The retrieved results are reranked considering the temporal timestamps of the images to increase the relevance of the later detections. Finally, a temporal interleaving of the results is introduced for robustness against false detections. The Mean Reciprocal Rank is proposed as a metric to evaluate this problem. This application could help into developing personal assistants capable of helping users when they do not remember where they left their personal belongings.
Fully Convolutional Crowd Counting On Highly Congested Scenes
Jan 17, 2017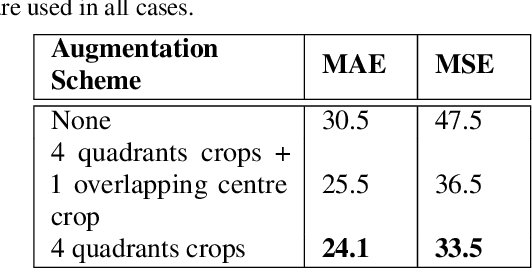
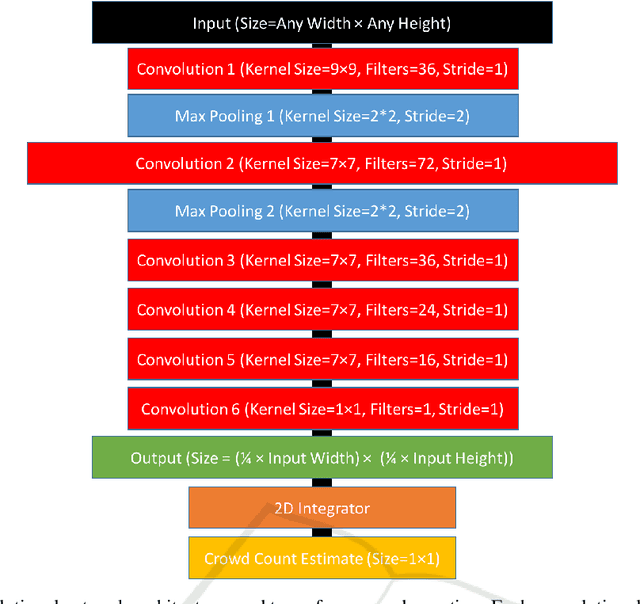
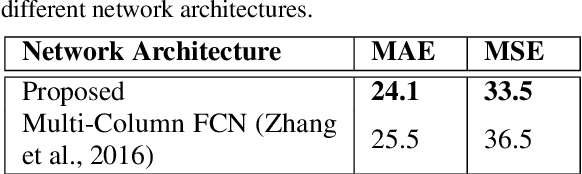

In this paper we advance the state-of-the-art for crowd counting in high density scenes by further exploring the idea of a fully convolutional crowd counting model introduced by (Zhang et al., 2016). Producing an accurate and robust crowd count estimator using computer vision techniques has attracted significant research interest in recent years. Applications for crowd counting systems exist in many diverse areas including city planning, retail, and of course general public safety. Developing a highly generalised counting model that can be deployed in any surveillance scenario with any camera perspective is the key objective for research in this area. Techniques developed in the past have generally performed poorly in highly congested scenes with several thousands of people in frame (Rodriguez et al., 2011). Our approach, influenced by the work of (Zhang et al., 2016), consists of the following contributions: (1) A training set augmentation scheme that minimises redundancy among training samples to improve model generalisation and overall counting performance; (2) a deep, single column, fully convolutional network (FCN) architecture; (3) a multi-scale averaging step during inference. The developed technique can analyse images of any resolution or aspect ratio and achieves state-of-the-art counting performance on the Shanghaitech Part B and UCF CC 50 datasets as well as competitive performance on Shanghaitech Part A.
An Interactive Segmentation Tool for Quantifying Fat in Lumbar Muscles using Axial Lumbar-Spine MRI
Sep 09, 2016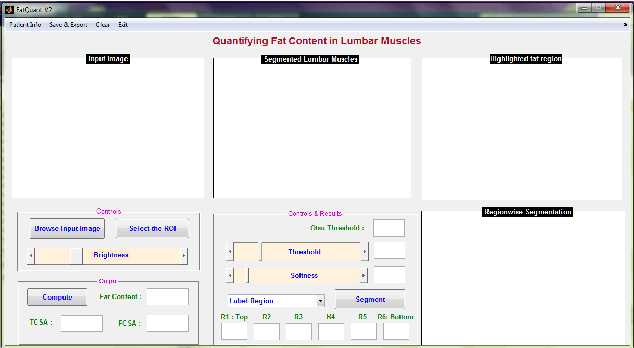

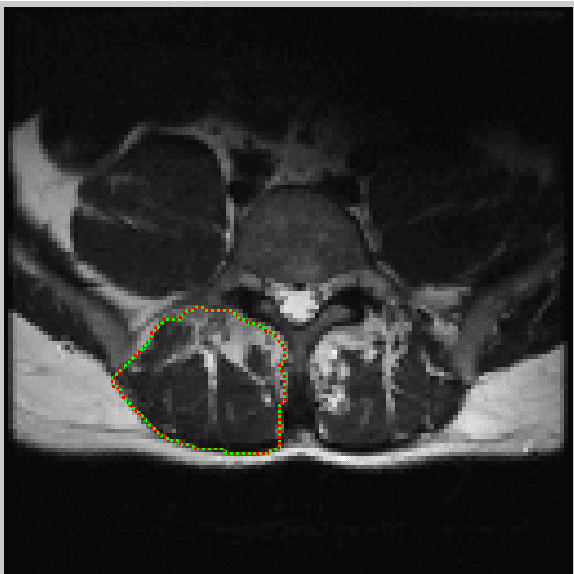
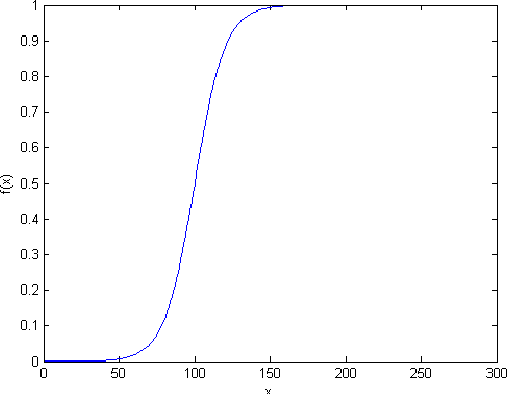
In this paper we present an interactive tool that can be used to quantify fat infiltration in lumbar muscles, which is useful in studying fat infiltration and lower back pain (LBP) in adults. Currently, a qualitative assessment by visual grading via a 5-point scale is used to study fat infiltration in lumbar muscles from an axial view of lumbar-spine MR Images. However, a quantitative approach (on a continuous scale of 0-100\%) may provide a greater insight. In this paper, we propose a method to precisely quantify the fat deposition / infiltration in a user-defined region of the lumbar muscles, which may aid better diagnosis and analysis. The key steps are interactively segmenting the region of interest (ROI) from the lumbar muscles using the well known livewire technique, identifying fatty regions in the segmented region based on variable-selection of threshold and softness levels, automatically detecting the center of the spinal column and fragmenting the lumbar muscles into smaller regions with reference to the center of the spinal column, computing key parameters [such as total and region-wise fat content percentage, total-cross sectional area (TCSA) and functional cross-sectional area (FCSA)] and exporting the computations and associated patient information from the MRI, into a database. A standalone application using MATLAB R2014a was developed to perform the required computations along with an intuitive graphical user interface (GUI).
Quantifying Radiographic Knee Osteoarthritis Severity using Deep Convolutional Neural Networks
Sep 08, 2016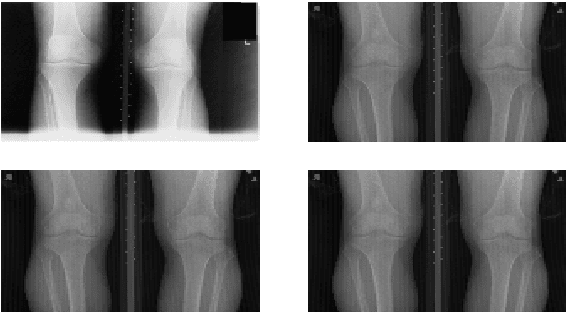
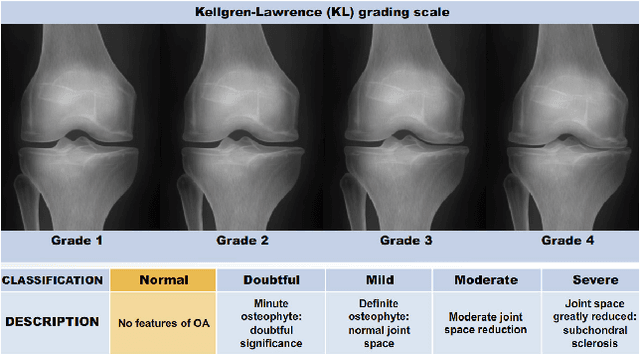
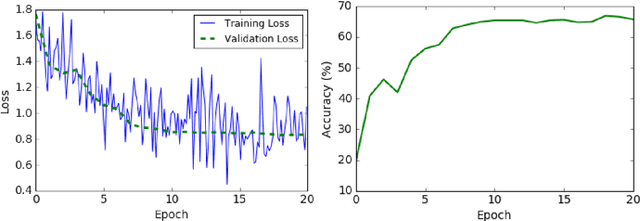
This paper proposes a new approach to automatically quantify the severity of knee osteoarthritis (OA) from radiographs using deep convolutional neural networks (CNN). Clinically, knee OA severity is assessed using Kellgren \& Lawrence (KL) grades, a five point scale. Previous work on automatically predicting KL grades from radiograph images were based on training shallow classifiers using a variety of hand engineered features. We demonstrate that classification accuracy can be significantly improved using deep convolutional neural network models pre-trained on ImageNet and fine-tuned on knee OA images. Furthermore, we argue that it is more appropriate to assess the accuracy of automatic knee OA severity predictions using a continuous distance-based evaluation metric like mean squared error than it is to use classification accuracy. This leads to the formulation of the prediction of KL grades as a regression problem and further improves accuracy. Results on a dataset of X-ray images and KL grades from the Osteoarthritis Initiative (OAI) show a sizable improvement over the current state-of-the-art.
Bags of Local Convolutional Features for Scalable Instance Search
Apr 15, 2016
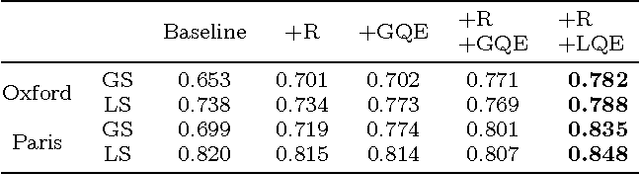

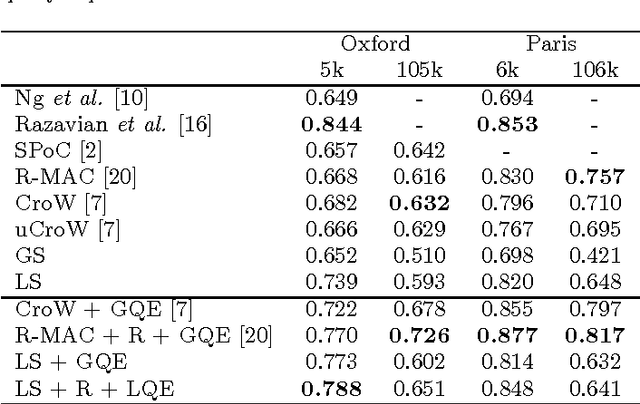
This work proposes a simple instance retrieval pipeline based on encoding the convolutional features of CNN using the bag of words aggregation scheme (BoW). Assigning each local array of activations in a convolutional layer to a visual word produces an \textit{assignment map}, a compact representation that relates regions of an image with a visual word. We use the assignment map for fast spatial reranking, obtaining object localizations that are used for query expansion. We demonstrate the suitability of the BoW representation based on local CNN features for instance retrieval, achieving competitive performance on the Oxford and Paris buildings benchmarks. We show that our proposed system for CNN feature aggregation with BoW outperforms state-of-the-art techniques using sum pooling at a subset of the challenging TRECVid INS benchmark.