 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Effects of Software Patches in a Multiplayer Online Battle Arena Game
Oct 27, 2021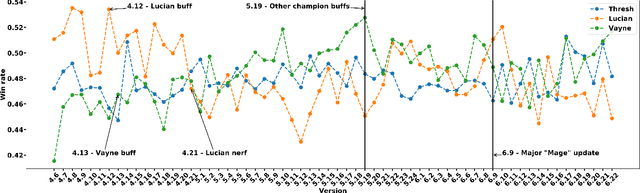
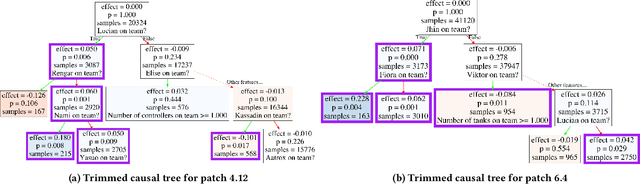

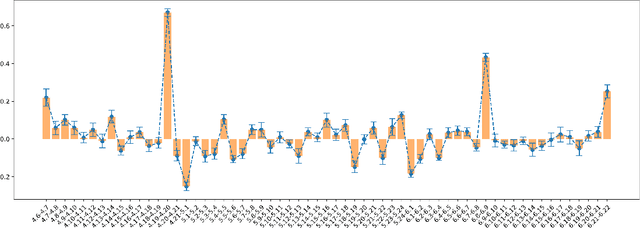
The popularity of online gaming has grown dramatically, driven in part by streaming and the billion-dollar e-sports industry. Online games regularly update their software to fix bugs, add functionality that improve the game's look and feel, and change the game mechanics to keep the games fun and challenging. An open question, however, is the impact of these changes on player performance and game balance, as well as how players adapt to these sudden changes. To address these questions, we use causal inference to measure the impact of software patches to League of Legends, a popular team-based multiplayer online game. We show that game patches have substantially different impacts on players depending on their skill level and whether they take breaks between games. We find that the gap between good and bad players increases after a patch, despite efforts to make gameplay more equal. Moreover, longer between-game breaks tend to improve player performance after patches. Overall, our results highlight the utility of causal inference, and specifically heterogeneous treatment effect estimation, as a tool to quantify the complex mechanisms of game balance and its interplay with players' performance.
* 9 pages, 11 figures
A Python Package to Detect Anti-Vaccine Users on Twitter
Oct 21, 2021
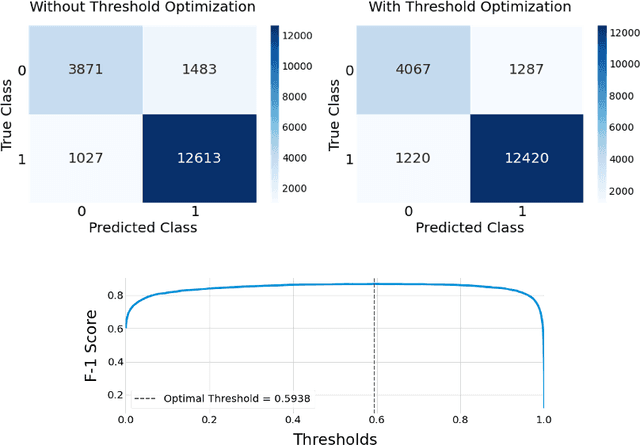
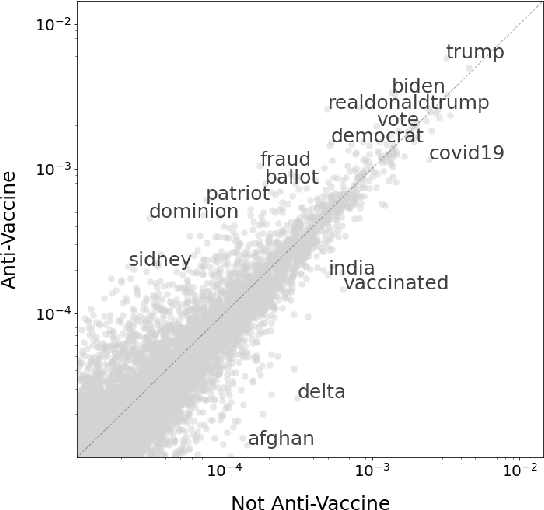
Vaccine hesitancy has a long history but has been recently driven by the anti-vaccine narratives shared online, which significantly degrades the efficacy of vaccination strategies, such as those for COVID-19. Despite broad agreement in the medical community about the safety and efficacy of available vaccines, a large number of social media users continue to be inundated with false information about vaccines and, partly because of this, became indecisive or unwilling to be vaccinated. The goal of this study is to better understand anti-vaccine sentiment, and work to reduce its impact, by developing a system capable of automatically identifying the users responsible for spreading anti-vaccine narratives. We introduce a publicly available Python package capable of analyzing Twitter profiles to assess how likely that profile is to spread anti-vaccine sentiment in the future. The software package is built using text embedding methods, neural networks, and automated dataset generation. It is trained on over one hundred thousand accounts and several million tweets. This model will help researchers and policy-makers understand anti-vaccine discussion and misinformation strategies, which can further help tailor targeted campaigns seeking to inform and debunk the harmful anti-vaccination myths currently being spread. Additionally, we leverage the data on such users to understand what are the moral and emotional characteristics of anti-vaccine spreaders.
DoGR: Disaggregated Gaussian Regression for Reproducible Analysis of Heterogeneous Data
Aug 31, 2021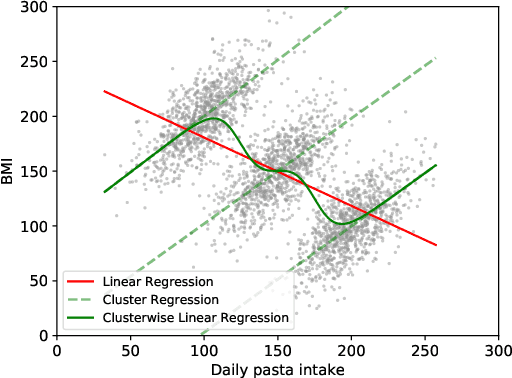
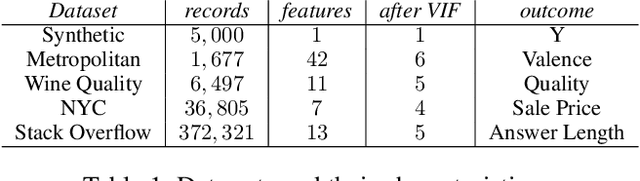
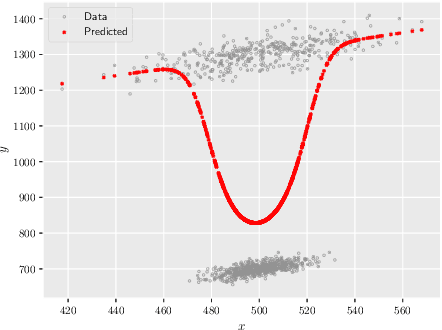
Quantitative analysis of large-scale data is often complicated by the presence of diverse subgroups, which reduce the accuracy of inferences they make on held-out data. To address the challenge of heterogeneous data analysis, we introduce DoGR, a method that discovers latent confounders by simultaneously partitioning the data into overlapping clusters (disaggregation) and modeling the behavior within them (regression). When applied to real-world data, our method discovers meaningful clusters and their characteristic behaviors, thus giving insight into group differences and their impact on the outcome of interest. By accounting for latent confounders, our framework facilitates exploratory analysis of noisy, heterogeneous data and can be used to learn predictive models that better generalize to new data. We provide the code to enable others to use DoGR within their data analytic workflows.
Inherent Trade-offs in the Fair Allocation of Treatments
Oct 30, 2020
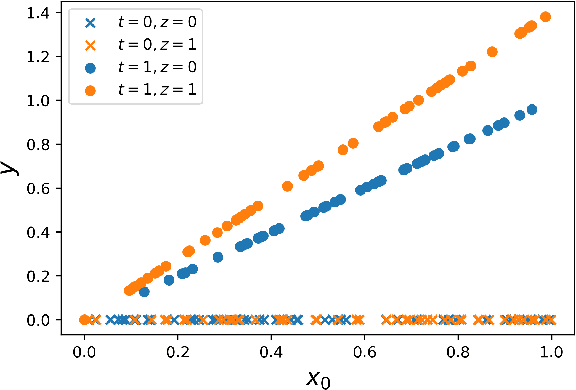
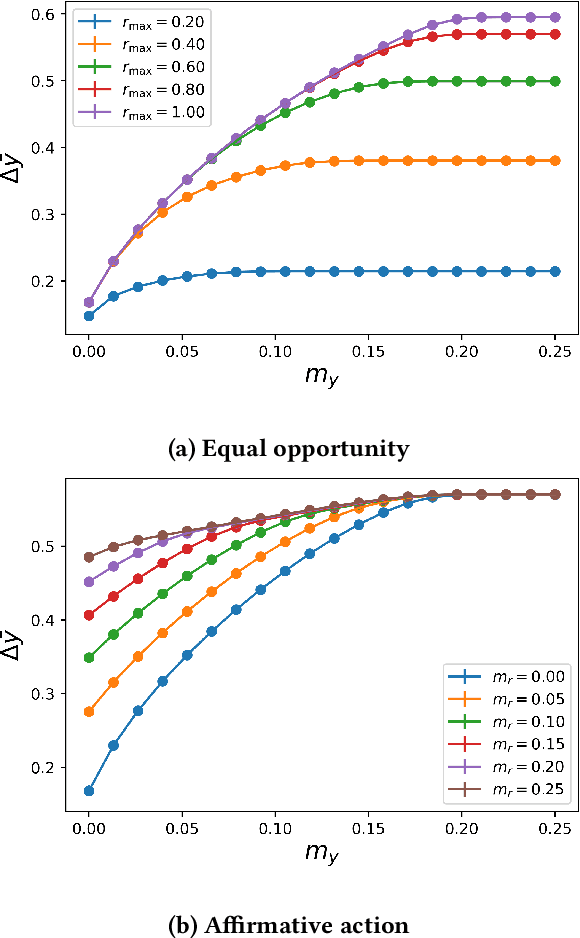
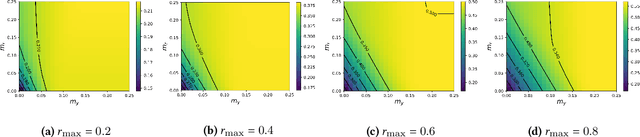
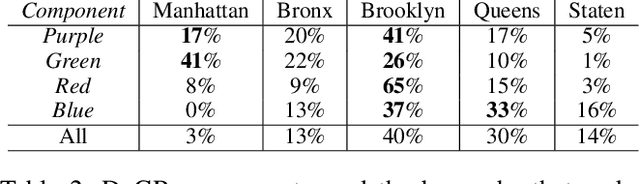
Explicit and implicit bias clouds human judgement, leading to discriminatory treatment of minority groups. A fundamental goal of algorithmic fairness is to avoid the pitfalls in human judgement by learning policies that improve the overall outcomes while providing fair treatment to protected classes. In this paper, we propose a causal framework that learns optimal intervention policies from data subject to fairness constraints. We define two measures of treatment bias and infer best treatment assignment that minimizes the bias while optimizing overall outcome. We demonstrate that there is a dilemma of balancing fairness and overall benefit; however, allowing preferential treatment to protected classes in certain circumstances (affirmative action) can dramatically improve the overall benefit while also preserving fairness. We apply our framework to data containing student outcomes on standardized tests and show how it can be used to design real-world policies that fairly improve student test scores. Our framework provides a principled way to learn fair treatment policies in real-world settings.
Learning Fair and Interpretable Representations via Linear Orthogonalization
Oct 28, 2019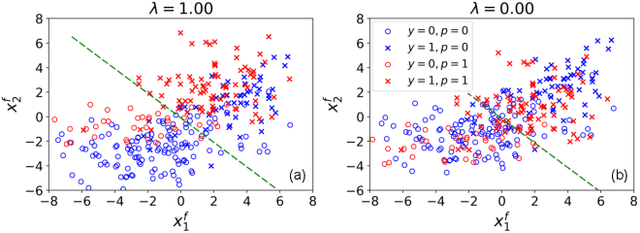
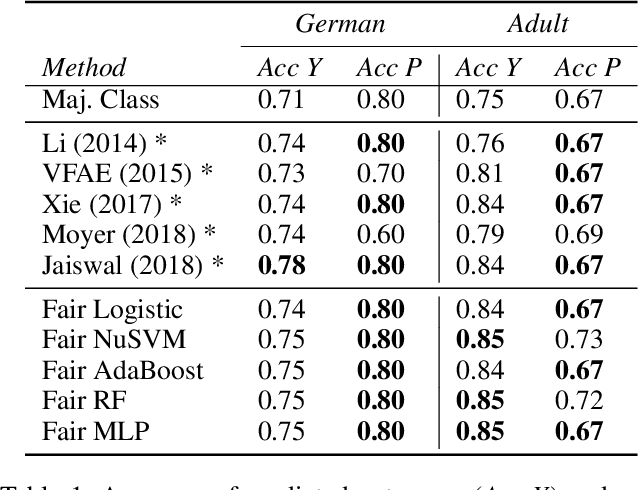
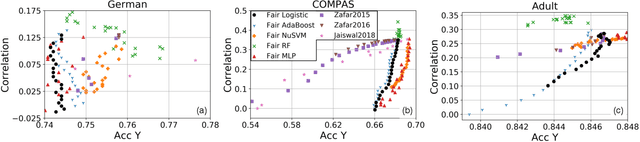

To reduce human error and prejudice, many high-stakes decisions have been turned over to machine algorithms. However, recent research suggests that this does not remove discrimination, and can perpetuate harmful stereotypes. While algorithms have been developed to improve fairness, they typically face at least one of three shortcomings: they are not interpretable, they lose significant accuracy compared to unbiased equivalents, or they are not transferable across models. To address these issues, we propose a geometric method that removes correlations between data and any number of protected variables. Further, we can control the strength of debiasing through an adjustable parameter to address the trade-off between model accuracy and fairness. The resulting features are interpretable and can be used with many popular models, such as linear regression, random forest and multilayer perceptrons. The resulting predictions are found to be more accurate and fair than several comparable fair AI algorithms across a variety of benchmark datasets. Our work shows that debiasing data is a simple and effective solution toward improving fairness.
The Myopia of Crowds: A Study of Collective Evaluation on Stack Exchange
Feb 24, 2016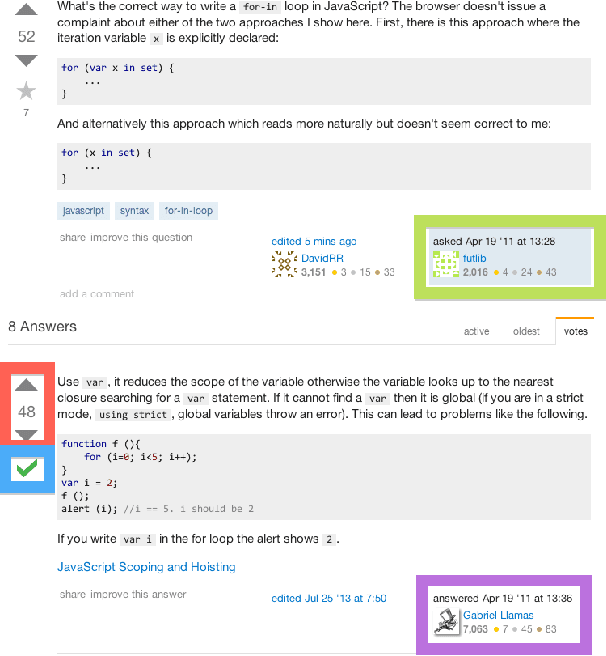
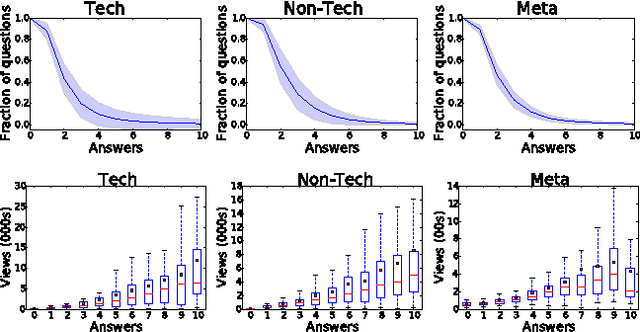
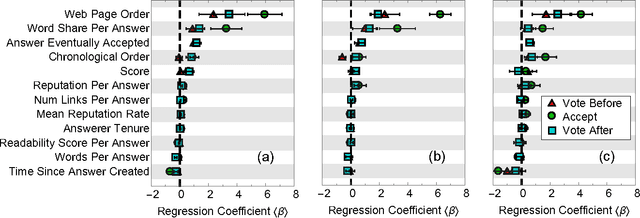
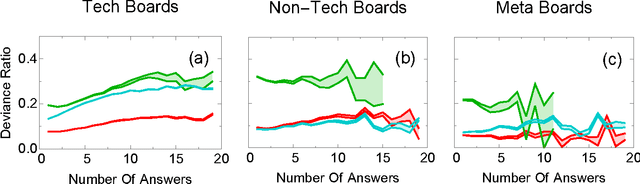
Crowds can often make better decisions than individuals or small groups of experts by leveraging their ability to aggregate diverse information. Question answering sites, such as Stack Exchange, rely on the "wisdom of crowds" effect to identify the best answers to questions asked by users. We analyze data from 250 communities on the Stack Exchange network to pinpoint factors affecting which answers are chosen as the best answers. Our results suggest that, rather than evaluate all available answers to a question, users rely on simple cognitive heuristics to choose an answer to vote for or accept. These cognitive heuristics are linked to an answer's salience, such as the order in which it is listed and how much screen space it occupies. While askers appear to depend more on heuristics, compared to voting users, when choosing an answer to accept as the most helpful one, voters use acceptance itself as a heuristic: they are more likely to choose the answer after it is accepted than before that very same answer was accepted. These heuristics become more important in explaining and predicting behavior as the number of available answers increases. Our findings suggest that crowd judgments may become less reliable as the number of answers grow.
* 10 pages, 9 figures