 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaren Simonyan
High-Performance Large-Scale Image Recognition Without Normalization
Feb 11, 2021
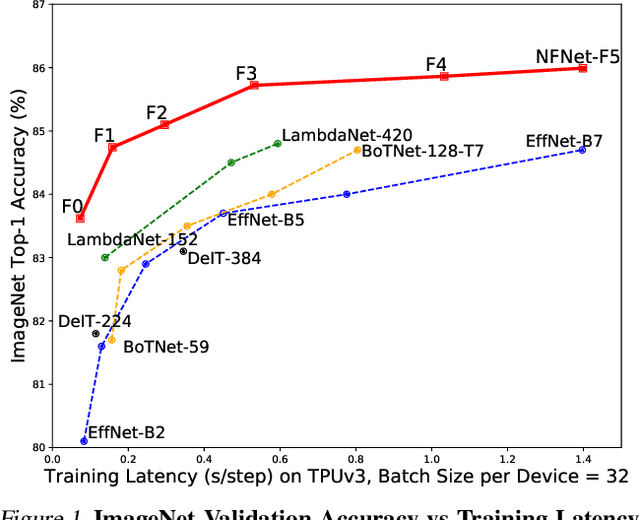
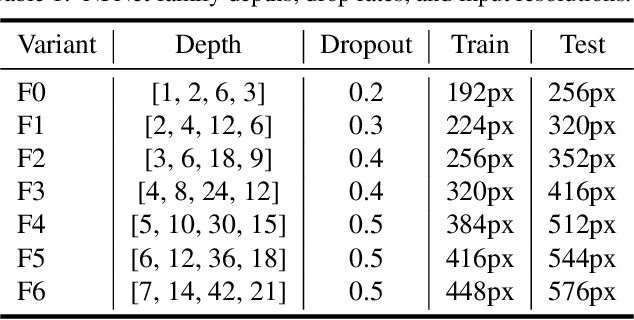
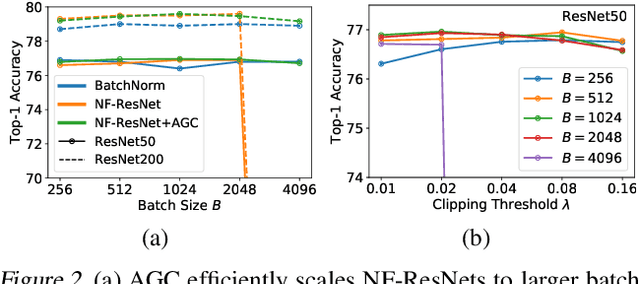
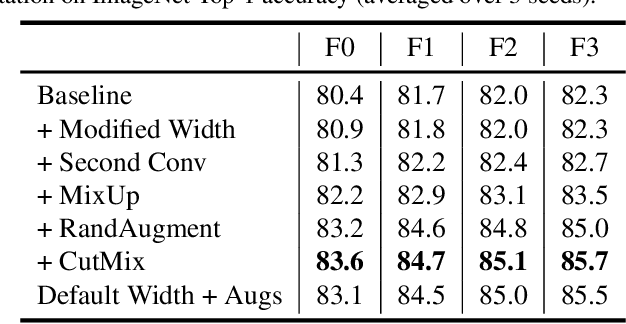
Batch normalization is a key component of most image classification models, but it has many undesirable properties stemming from its dependence on the batch size and interactions between examples. Although recent work has succeeded in training deep ResNets without normalization layers, these models do not match the test accuracies of the best batch-normalized networks, and are often unstable for large learning rates or strong data augmentations. In this work, we develop an adaptive gradient clipping technique which overcomes these instabilities, and design a significantly improved class of Normalizer-Free ResNets. Our smaller models match the test accuracy of an EfficientNet-B7 on ImageNet while being up to 8.7x faster to train, and our largest models attain a new state-of-the-art top-1 accuracy of 86.5%. In addition, Normalizer-Free models attain significantly better performance than their batch-normalized counterparts when finetuning on ImageNet after large-scale pre-training on a dataset of 300 million labeled images, with our best models obtaining an accuracy of 89.2%. Our code is available at https://github.com/deepmind/ deepmind-research/tree/master/nfnets
AlgebraNets
Jun 16, 2020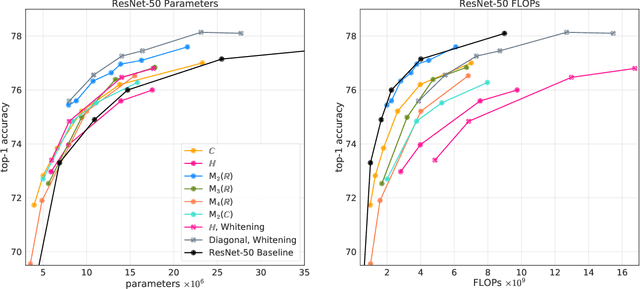
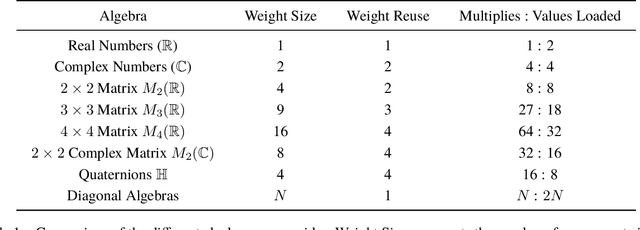
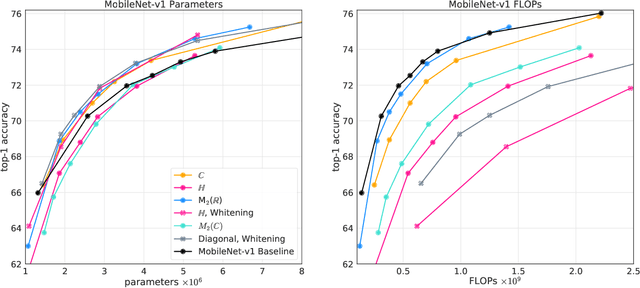

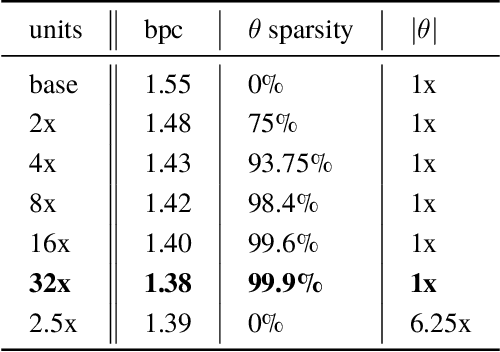
Neural networks have historically been built layerwise from the set of functions in ${f: \mathbb{R}^n \to \mathbb{R}^m }$, i.e. with activations and weights/parameters represented by real numbers, $\mathbb{R}$. Our work considers a richer set of objects for activations and weights, and undertakes a comprehensive study of alternative algebras as number representations by studying their performance on two challenging problems: large-scale image classification using the ImageNet dataset and language modeling using the enwiki8 and WikiText-103 datasets. We denote this broader class of models as AlgebraNets. Our findings indicate that the conclusions of prior work, which explored neural networks constructed from $\mathbb{C}$ (complex numbers) and $\mathbb{H}$ (quaternions) on smaller datasets, do not always transfer to these challenging settings. However, our results demonstrate that there are alternative algebras which deliver better parameter and computational efficiency compared with $\mathbb{R}$. We consider $\mathbb{C}$, $\mathbb{H}$, $M_{2}(\mathbb{R})$ (the set of $2\times2$ real-valued matrices), $M_{2}(\mathbb{C})$, $M_{3}(\mathbb{R})$ and $M_{4}(\mathbb{R})$. Additionally, we note that multiplication in these algebras has higher compute density than real multiplication, a useful property in situations with inherently limited parameter reuse such as auto-regressive inference and sparse neural networks. We therefore investigate how to induce sparsity within AlgebraNets. We hope that our strong results on large-scale, practical benchmarks will spur further exploration of these unconventional architectures which challenge the default choice of using real numbers for neural network weights and activations.
A Practical Sparse Approximation for Real Time Recurrent Learning
Jun 12, 2020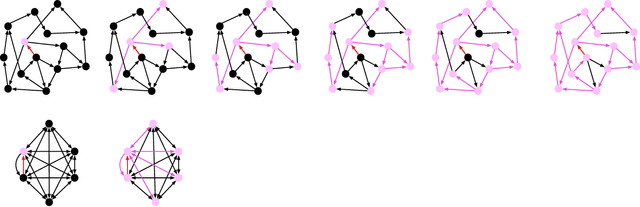
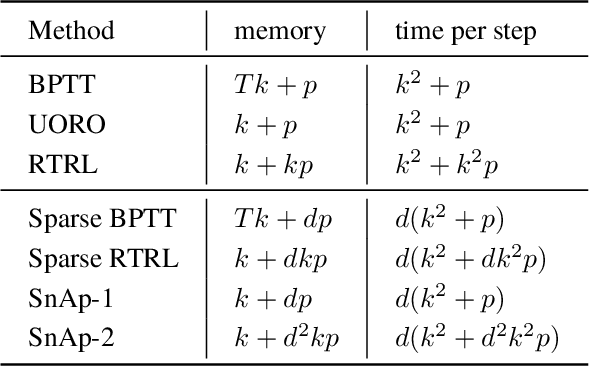
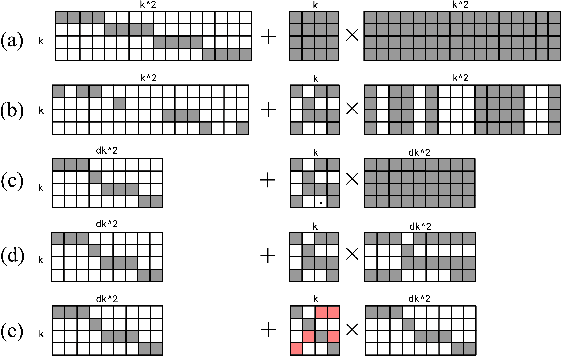
Current methods for training recurrent neural networks are based on backpropagation through time, which requires storing a complete history of network states, and prohibits updating the weights `online' (after every timestep). Real Time Recurrent Learning (RTRL) eliminates the need for history storage and allows for online weight updates, but does so at the expense of computational costs that are quartic in the state size. This renders RTRL training intractable for all but the smallest networks, even ones that are made highly sparse. We introduce the Sparse n-step Approximation (SnAp) to the RTRL influence matrix, which only keeps entries that are nonzero within n steps of the recurrent core. SnAp with n=1 is no more expensive than backpropagation, and we find that it substantially outperforms other RTRL approximations with comparable costs such as Unbiased Online Recurrent Optimization. For highly sparse networks, SnAp with n=2 remains tractable and can outperform backpropagation through time in terms of learning speed when updates are done online. SnAp becomes equivalent to RTRL when n is large.
End-to-End Adversarial Text-to-Speech
Jun 05, 2020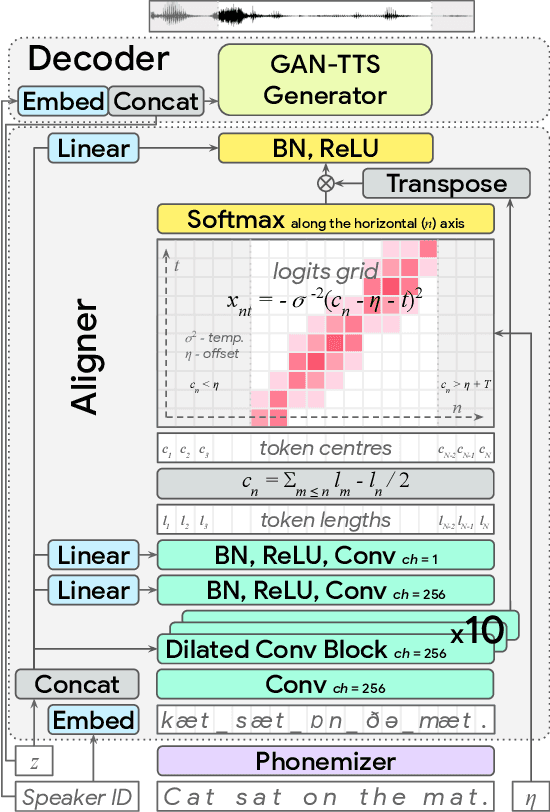
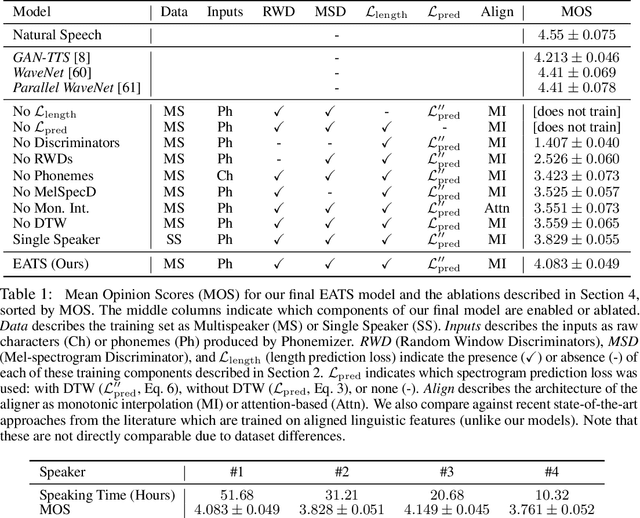

Modern text-to-speech synthesis pipelines typically involve multiple processing stages, each of which is designed or learnt independently from the rest. In this work, we take on the challenging task of learning to synthesise speech from normalised text or phonemes in an end-to-end manner, resulting in models which operate directly on character or phoneme input sequences and produce raw speech audio outputs. Our proposed generator is feed-forward and thus efficient for both training and inference, using a differentiable monotonic interpolation scheme to predict the duration of each input token. It learns to produce high fidelity audio through a combination of adversarial feedback and prediction losses constraining the generated audio to roughly match the ground truth in terms of its total duration and mel-spectrogram. To allow the model to capture temporal variation in the generated audio, we employ soft dynamic time warping in the spectrogram-based prediction loss. The resulting model achieves a mean opinion score exceeding 4 on a 5 point scale, which is comparable to the state-of-the-art models relying on multi-stage training and additional supervision.
Evolving Normalization-Activation Layers
Apr 28, 2020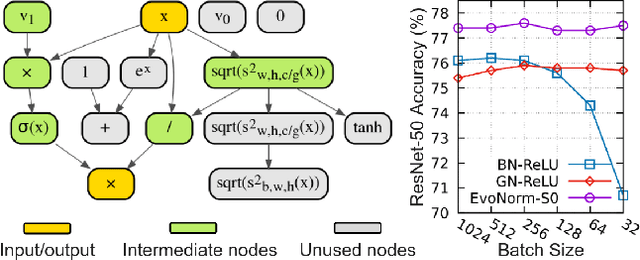

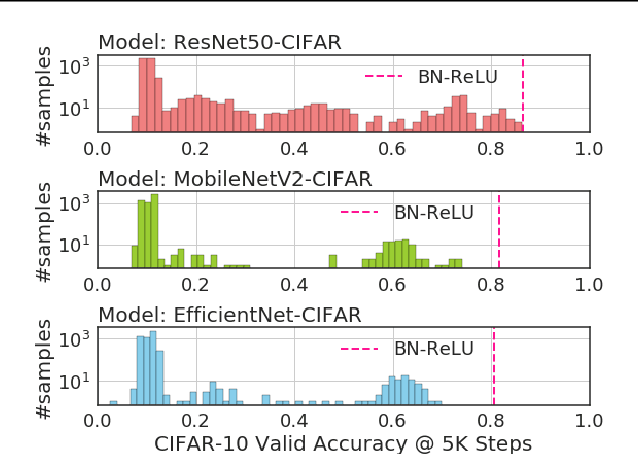
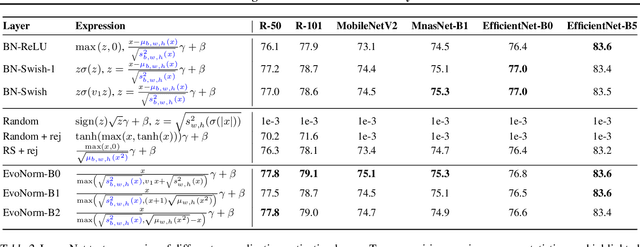
Normalization layers and activation functions are critical components in deep neural networks that frequently co-locate with each other. Instead of designing them separately, we unify them into a single computation graph, and evolve its structure starting from low-level primitives. Our layer search algorithm leads to the discovery of EvoNorms, a set of new normalization-activation layers that go beyond existing design patterns. Several of these layers enjoy the property of being independent from the batch statistics. Our experiments show that EvoNorms not only work well on a variety of image classification models including ResNets, MobileNets and EfficientNets but also transfer well to Mask R-CNN, SpineNet for instance segmentation and BigGAN for image synthesis, significantly outperforming BatchNorm and GroupNorm based layers in many cases.
Transformation-based Adversarial Video Prediction on Large-Scale Data
Mar 09, 2020
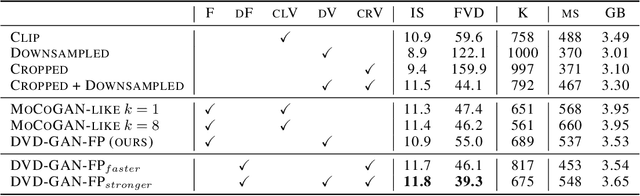
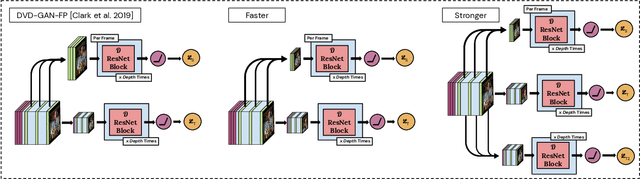
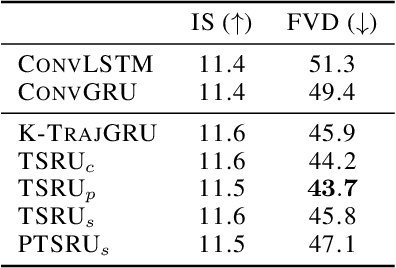
Recent breakthroughs in adversarial generative modeling have led to models capable of producing video samples of high quality, even on large and complex datasets of real-world video. In this work, we focus on the task of video prediction, where given a sequence of frames extracted from a video, the goal is to generate a plausible future sequence. We first improve the state of the art by performing a systematic empirical study of discriminator decompositions and proposing an architecture that yields faster convergence and higher performance than previous approaches. We then analyze recurrent units in the generator, and propose a novel recurrent unit which transforms its past hidden state according to predicted motion-like features, and refines it to to handle dis-occlusions, scene changes and other complex behavior. We show that this recurrent unit consistently outperforms previous designs. Our final model leads to a leap in the state-of-the-art performance, obtaining a test set Frechet Video Distance of 25.7, down from 69.2, on the large-scale Kinetics-600 dataset.
LOGAN: Latent Optimisation for Generative Adversarial Networks
Dec 02, 2019

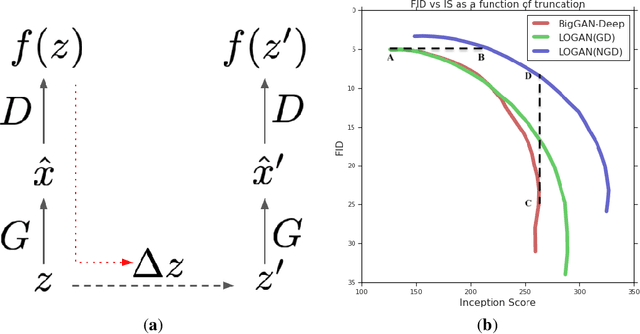
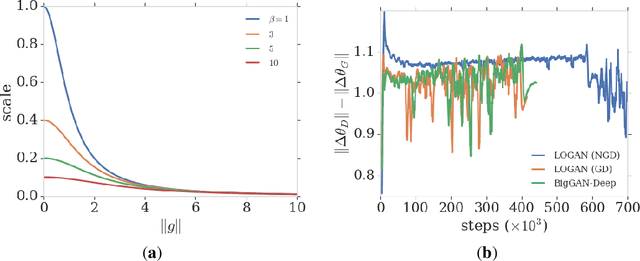
Training generative adversarial networks requires balancing of delicate adversarial dynamics. Even with careful tuning, training may diverge or end up in a bad equilibrium with dropped modes. In this work, we introduce a new form of latent optimisation inspired by the CS-GAN and show that it improves adversarial dynamics by enhancing interactions between the discriminator and the generator. We develop supporting theoretical analysis from the perspectives of differentiable games and stochastic approximation. Our experiments demonstrate that latent optimisation can significantly improve GAN training, obtaining state-of-the-art performance for the ImageNet (128 x 128) dataset. Our model achieves an Inception Score (IS) of 148 and an Fr\'echet Inception Distance (FID) of 3.4, an improvement of 17% and 32% in IS and FID respectively, compared with the baseline BigGAN-deep model with the same architecture and number of parameters.
Fast Sparse ConvNets
Nov 21, 2019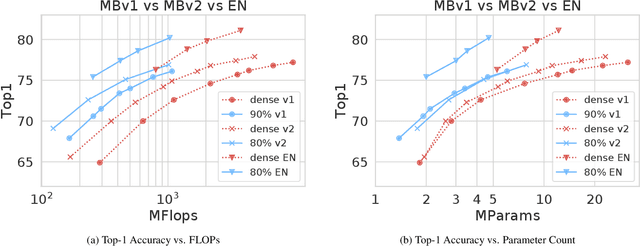
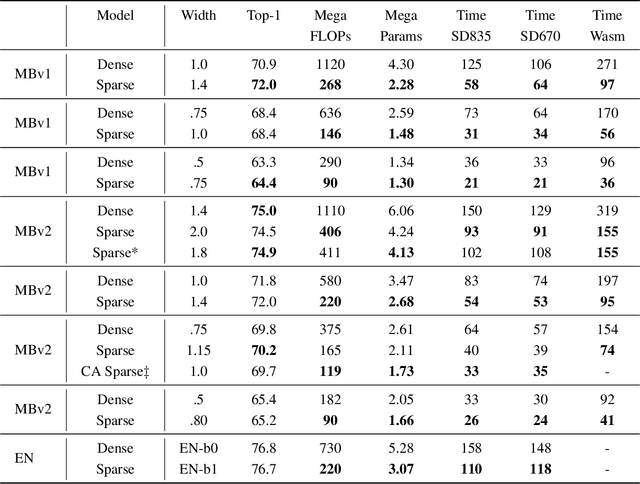
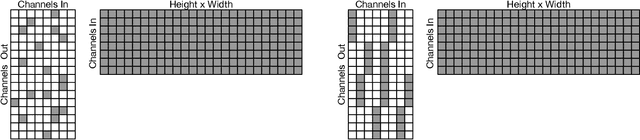

Historically, the pursuit of efficient inference has been one of the driving forces behind research into new deep learning architectures and building blocks. Some recent examples include: the squeeze-and-excitation module, depthwise separable convolutions in Xception, and the inverted bottleneck in MobileNet v2. Notably, in all of these cases, the resulting building blocks enabled not only higher efficiency, but also higher accuracy, and found wide adoption in the field. In this work, we further expand the arsenal of efficient building blocks for neural network architectures; but instead of combining standard primitives (such as convolution), we advocate for the replacement of these dense primitives with their sparse counterparts. While the idea of using sparsity to decrease the parameter count is not new, the conventional wisdom is that this reduction in theoretical FLOPs does not translate into real-world efficiency gains. We aim to correct this misconception by introducing a family of efficient sparse kernels for ARM and WebAssembly, which we open-source for the benefit of the community as part of the XNNPACK library. Equipped with our efficient implementation of sparse primitives, we show that sparse versions of MobileNet v1, MobileNet v2 and EfficientNet architectures substantially outperform strong dense baselines on the efficiency-accuracy curve. On Snapdragon 835 our sparse networks outperform their dense equivalents by $1.3-2.4\times$ -- equivalent to approximately one entire generation of MobileNet-family improvement. We hope that our findings will facilitate wider adoption of sparsity as a tool for creating efficient and accurate deep learning architectures.