 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirichlet Pruning for Neural Network Compression
Nov 10, 2020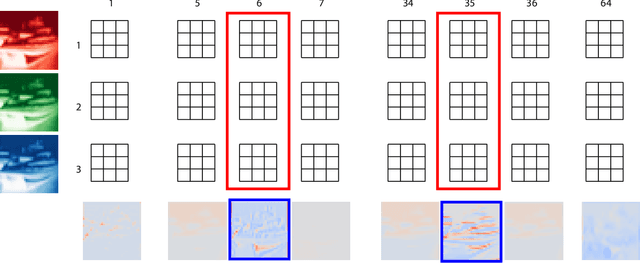
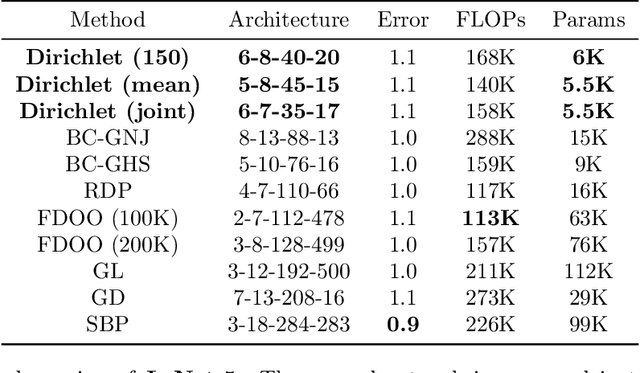

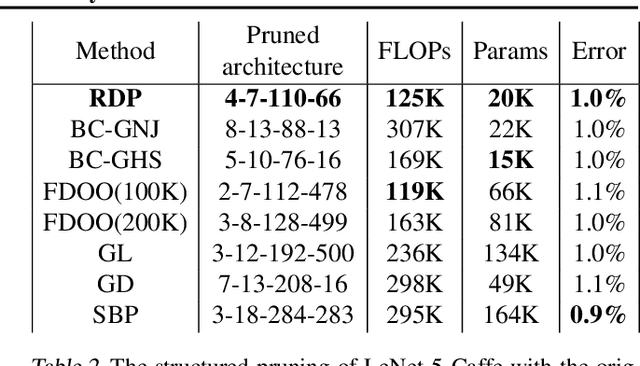
We introduce Dirichlet pruning, a novel post-processing technique to transform a large neural network model into a compressed one. Dirichlet pruning is a form of structured pruning which assigns the Dirichlet distribution over each layer's channels in convolutional layers (or neurons in fully-connected layers), and estimates the parameters of the distribution over these units using variational inference. The learned distribution allows us to remove unimportant units, resulting in a compact architecture containing only crucial features for a task at hand. Our method is extremely fast to train. The number of newly introduced Dirichlet parameters is only linear in the number of channels, which allows for rapid training, requiring as little as one epoch to converge. We perform extensive experiments, in particular on larger architectures such as VGG and WideResNet (45% and 52% compression rate, respectively) where our method achieves the state-of-the-art compression performance and provides interpretable features as a by-product.
Q-FIT: The Quantifiable Feature Importance Technique for Explainable Machine Learning
Oct 26, 2020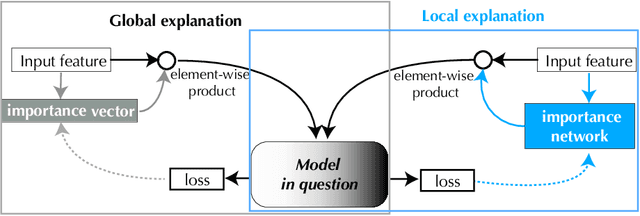
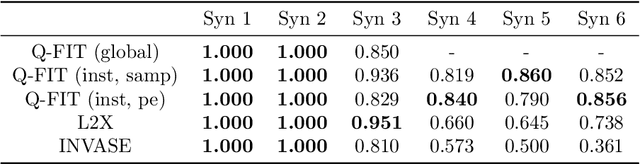
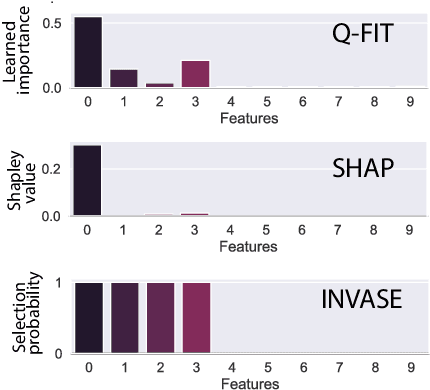

We introduce a novel framework to quantify the importance of each input feature for model explainability. A user of our framework can choose between two modes: (a) global explanation: providing feature importance globally across all the data points; and (b) local explanation: providing feature importance locally for each individual data point. The core idea of our method comes from utilizing the Dirichlet distribution to define a distribution over the importance of input features. This particular distribution is useful in ranking the importance of the input features as a sample from this distribution is a probability vector (i.e., the vector components sum to 1), Thus, the ranking uncovered by our framework which provides a \textit{quantifiable explanation} of how significant each input feature is to a model's output. This quantifiable explainability differentiates our method from existing feature-selection methods, which simply determine whether a feature is relevant or not. Furthermore, a distribution over the explanation allows to define a closed-form divergence to measure the similarity between learned feature importance under different models. We use this divergence to study how the feature importance trade-offs with essential notions in modern machine learning, such as privacy and fairness. We show the effectiveness of our method on a variety of synthetic and real datasets, taking into account both tabular and image datasets.
Differentially Private Mean Embeddings with Random Features (DP-MERF) for Simple & Practical Synthetic Data Generation
Mar 10, 2020

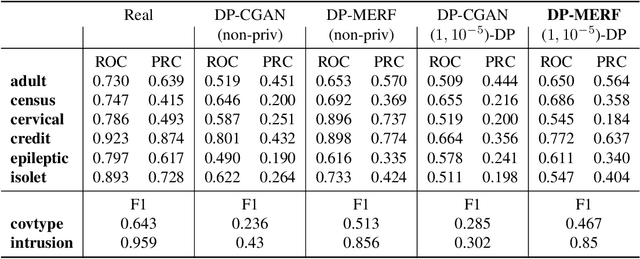

We present a differentially private data generation paradigm using random feature representations of kernel mean embeddings when comparing the distribution of true data with that of synthetic data. We exploit the random feature representations for two important benefits. First, we require a very low privacy cost for training deep generative models. This is because unlike kernel-based distance metrics that require computing the kernel matrix on all pairs of true and synthetic data points, we can detach the data-dependent term from the term solely dependent on synthetic data. Hence, we need to perturb the data-dependent term once-for-all and then use it until the end of the generator training. Second, we can obtain an analytic sensitivity of the kernel mean embedding as the random features are norm bounded by construction. This removes the necessity of hyperparameter search for a clipping norm to handle the unknown sensitivity of an encoder network when dealing with high-dimensional data. We provide several variants of our algorithm, differentially private mean embeddings with random features (DP-MERF) to generate (a) heterogeneous tabular data, (b) input features and corresponding labels jointly; and (c) high-dimensional data. Our algorithm achieves better privacy-utility trade-offs than existing methods tested on several datasets.
Neuron ranking -- an informed way to condense convolutional neural networks architecture
Jul 13, 2019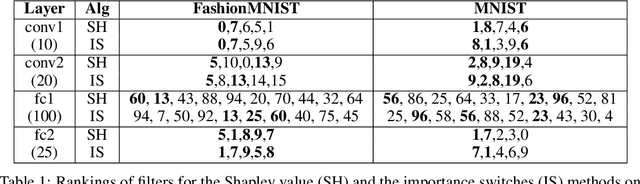
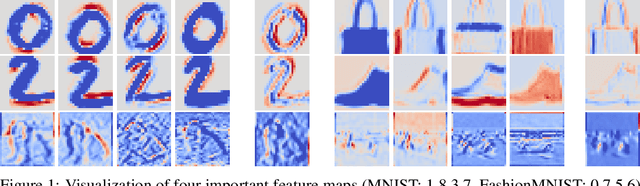
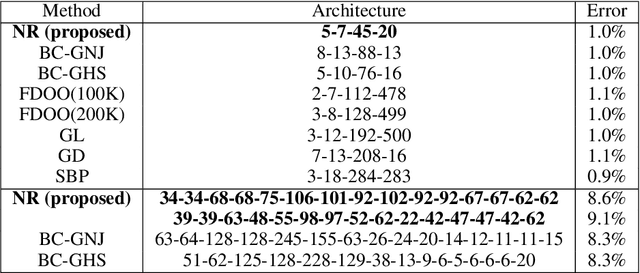
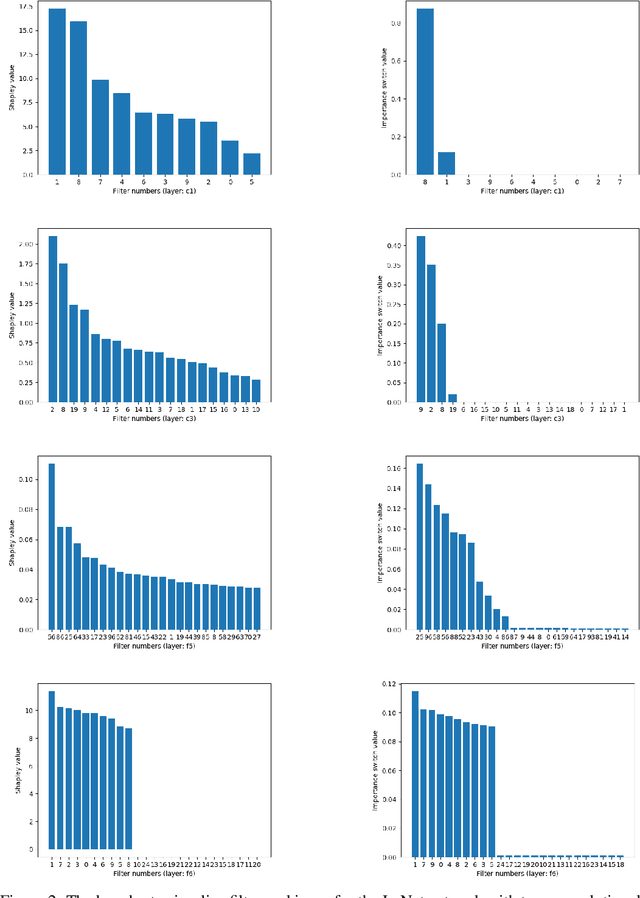
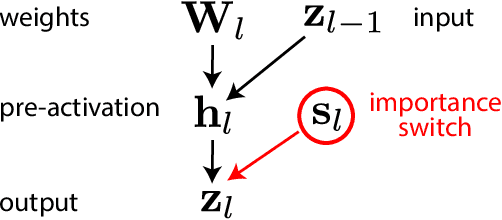
Convolutional neural networks (CNNs) in recent years have made a dramatic impact in science, technology and industry, yet the theoretical mechanism of CNN architecture design remains surprisingly vague. The CNN neurons, including its distinctive element, convolutional filters, are known to be learnable features, yet their individual role in producing the output is rather unclear. The thesis of this work is that not all neurons are equally important and some of them contain more useful information to perform a given task . Consequently, we quantify the significance of each filter and rank its importance in describing input to produce the desired output. This work presents two different methods: (1) a game theoretical approach based on Shapley value which computes the marginal contribution of each filter; and (2) a probabilistic approach based on what-we-call, the Importance switch using variational inference. Strikingly, these two vastly different methods produce similar experimental results, confirming the general theory that some of the filters are inherently more important that the others. The learned ranks can be readily useable for network compression and interpretability.
Radial and Directional Posteriors for Bayesian Neural Networks
Mar 13, 2019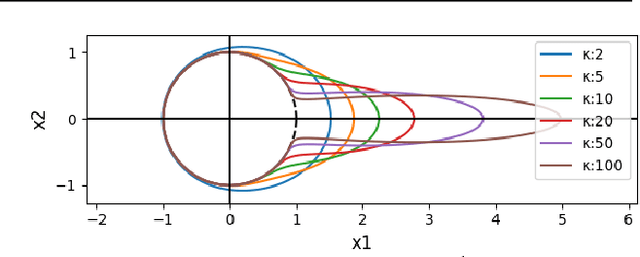
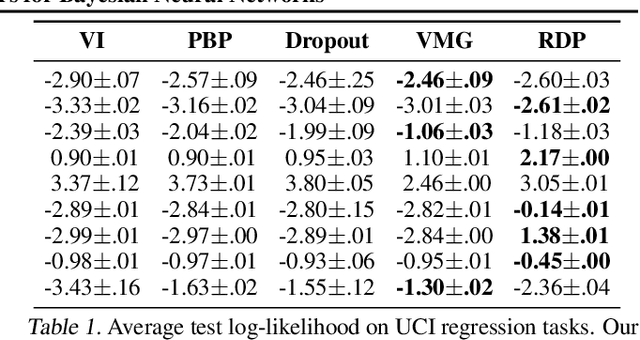
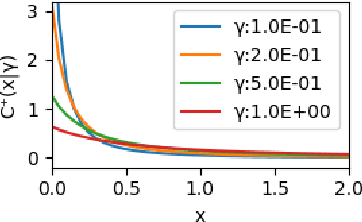
We propose a new variational family for Bayesian neural networks. We decompose the variational posterior into two components, where the radial component captures the strength of each neuron in terms of its magnitude; while the directional component captures the statistical dependencies among the weight parameters. The dependencies learned via the directional density provide better modeling performance compared to the widely-used Gaussian mean-field-type variational family. In addition, the strength of input and output neurons learned via the radial density provides a structured way to compress neural networks. Indeed, experiments show that our variational family improves predictive performance and yields compressed networks simultaneously.
How good is the Shapley value-based approach to the influence maximization problem?
Sep 27, 2014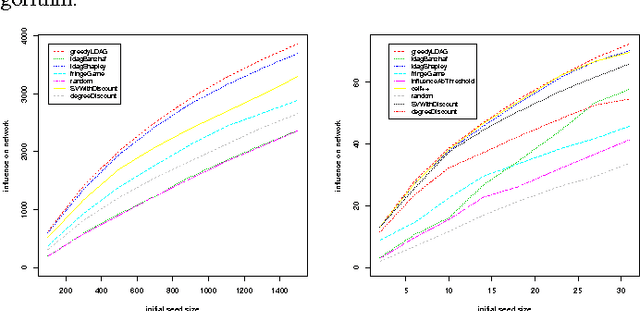
The Shapley value has been recently advocated as a method to choose the seed nodes for the process of information diffusion. Intuitively, since the Shapley value evaluates the average marginal contribution of a player to the coalitional game, it can be used in the network context to evaluate the marginal contribution of a node in the process of information diffusion given various groups of already 'infected' nodes. Although the above direction of research seems promising, the current liter- ature is missing a throughout assessment of its performance. The aim of this work is to provide such an assessment of the existing Shapley value-based approaches to information diffusion.