 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaiyang Zhou
Open-Vocabulary DETR with Conditional Matching
Mar 22, 2022
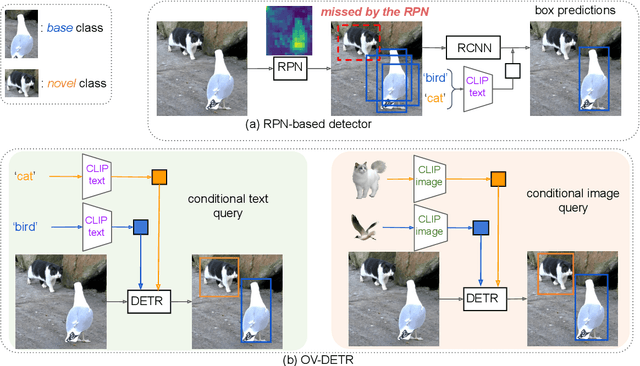
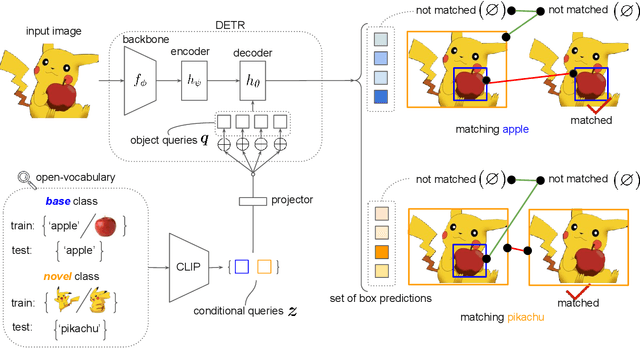
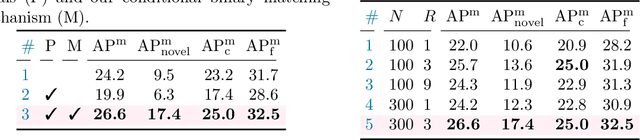
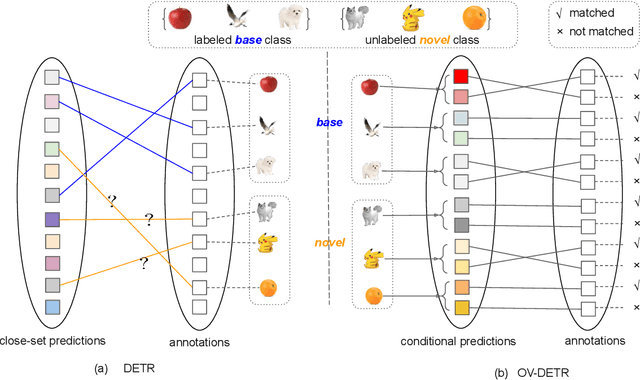
Open-vocabulary object detection, which is concerned with the problem of detecting novel objects guided by natural language, has gained increasing attention from the community. Ideally, we would like to extend an open-vocabulary detector such that it can produce bounding box predictions based on user inputs in form of either natural language or exemplar image. This offers great flexibility and user experience for human-computer interaction. To this end, we propose a novel open-vocabulary detector based on DETR -- hence the name OV-DETR -- which, once trained, can detect any object given its class name or an exemplar image. The biggest challenge of turning DETR into an open-vocabulary detector is that it is impossible to calculate the classification cost matrix of novel classes without access to their labeled images. To overcome this challenge, we formulate the learning objective as a binary matching one between input queries (class name or exemplar image) and the corresponding objects, which learns useful correspondence to generalize to unseen queries during testing. For training, we choose to condition the Transformer decoder on the input embeddings obtained from a pre-trained vision-language model like CLIP, in order to enable matching for both text and image queries. With extensive experiments on LVIS and COCO datasets, we demonstrate that our OV-DETR -- the first end-to-end Transformer-based open-vocabulary detector -- achieves non-trivial improvements over current state of the arts.
Conditional Prompt Learning for Vision-Language Models
Mar 10, 2022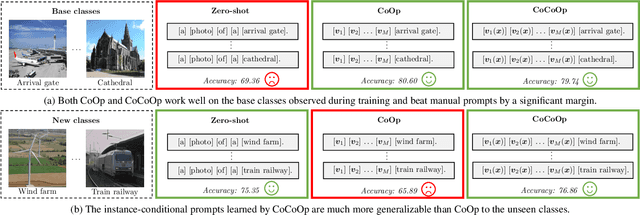
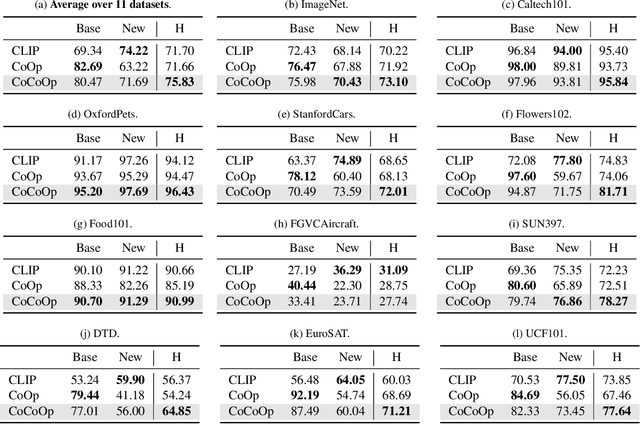
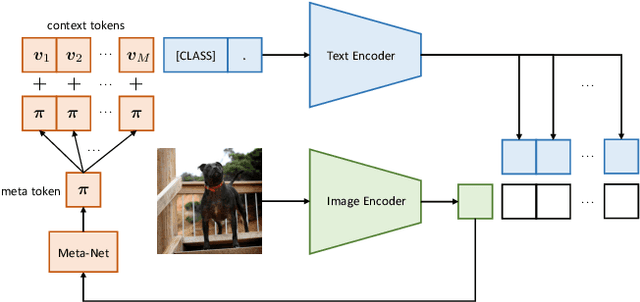
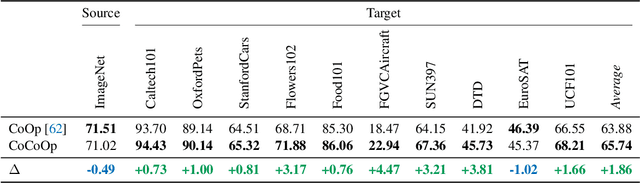
With the rise of powerful pre-trained vision-language models like CLIP, it becomes essential to investigate ways to adapt these models to downstream datasets. A recently proposed method named Context Optimization (CoOp) introduces the concept of prompt learning -- a recent trend in NLP -- to the vision domain for adapting pre-trained vision-language models. Specifically, CoOp turns context words in a prompt into a set of learnable vectors and, with only a few labeled images for learning, can achieve huge improvements over intensively-tuned manual prompts. In our study we identify a critical problem of CoOp: the learned context is not generalizable to wider unseen classes within the same dataset, suggesting that CoOp overfits base classes observed during training. To address the problem, we propose Conditional Context Optimization (CoCoOp), which extends CoOp by further learning a lightweight neural network to generate for each image an input-conditional token (vector). Compared to CoOp's static prompts, our dynamic prompts adapt to each instance and are thus less sensitive to class shift. Extensive experiments show that CoCoOp generalizes much better than CoOp to unseen classes, even showing promising transferability beyond a single dataset; and yields stronger domain generalization performance as well. Code is available at https://github.com/KaiyangZhou/CoOp.
Dynamic Instance Domain Adaptation
Mar 09, 2022
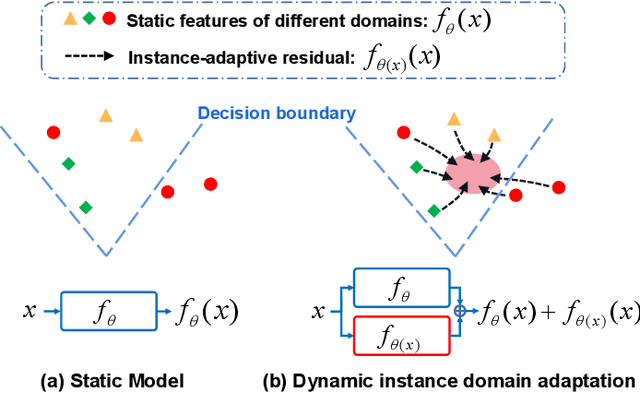
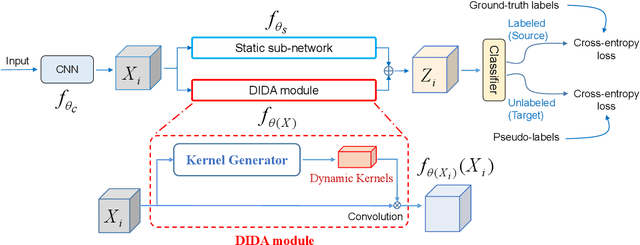
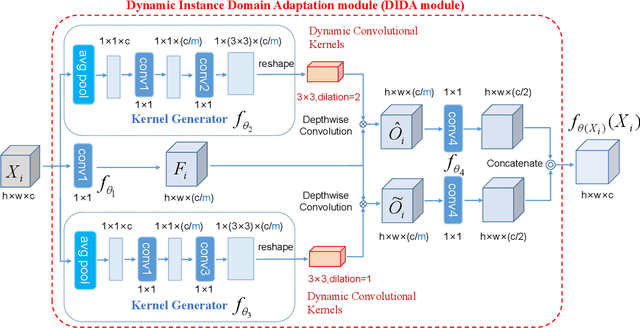
Most existing studies on unsupervised domain adaptation (UDA) assume that each domain's training samples come with domain labels (e.g., painting, photo). Samples from each domain are assumed to follow the same distribution and the domain labels are exploited to learn domain-invariant features via feature alignment. However, such an assumption often does not hold true -- there often exist numerous finer-grained domains (e.g., dozens of modern painting styles have been developed, each differing dramatically from those of the classic styles). Therefore, forcing feature distribution alignment across each artificially-defined and coarse-grained domain can be ineffective. In this paper, we address both single-source and multi-source UDA from a completely different perspective, which is to view each instance as a fine domain. Feature alignment across domains is thus redundant. Instead, we propose to perform dynamic instance domain adaptation (DIDA). Concretely, a dynamic neural network with adaptive convolutional kernels is developed to generate instance-adaptive residuals to adapt domain-agnostic deep features to each individual instance. This enables a shared classifier to be applied to both source and target domain data without relying on any domain annotation. Further, instead of imposing intricate feature alignment losses, we adopt a simple semi-supervised learning paradigm using only a cross-entropy loss for both labeled source and pseudo labeled target data. Our model, dubbed DIDA-Net, achieves state-of-the-art performance on several commonly used single-source and multi-source UDA datasets including Digits, Office-Home, DomainNet, Digit-Five, and PACS.
Domain Attention Consistency for Multi-Source Domain Adaptation
Nov 06, 2021
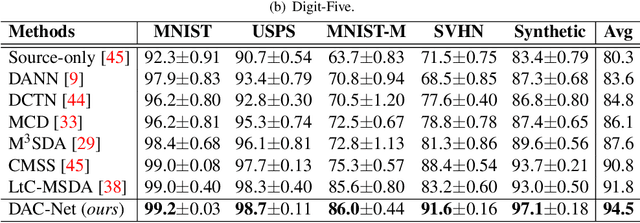
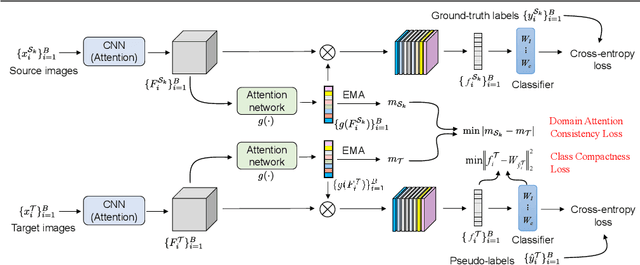
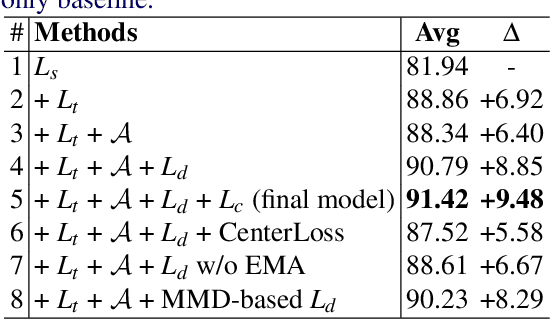
Most existing multi-source domain adaptation (MSDA) methods minimize the distance between multiple source-target domain pairs via feature distribution alignment, an approach borrowed from the single source setting. However, with diverse source domains, aligning pairwise feature distributions is challenging and could even be counter-productive for MSDA. In this paper, we introduce a novel approach: transferable attribute learning. The motivation is simple: although different domains can have drastically different visual appearances, they contain the same set of classes characterized by the same set of attributes; an MSDA model thus should focus on learning the most transferable attributes for the target domain. Adopting this approach, we propose a domain attention consistency network, dubbed DAC-Net. The key design is a feature channel attention module, which aims to identify transferable features (attributes). Importantly, the attention module is supervised by a consistency loss, which is imposed on the distributions of channel attention weights between source and target domains. Moreover, to facilitate discriminative feature learning on the target data, we combine pseudo-labeling with a class compactness loss to minimize the distance between the target features and the classifier's weight vectors. Extensive experiments on three MSDA benchmarks show that our DAC-Net achieves new state of the art performance on all of them.
Generalized Out-of-Distribution Detection: A Survey
Oct 21, 2021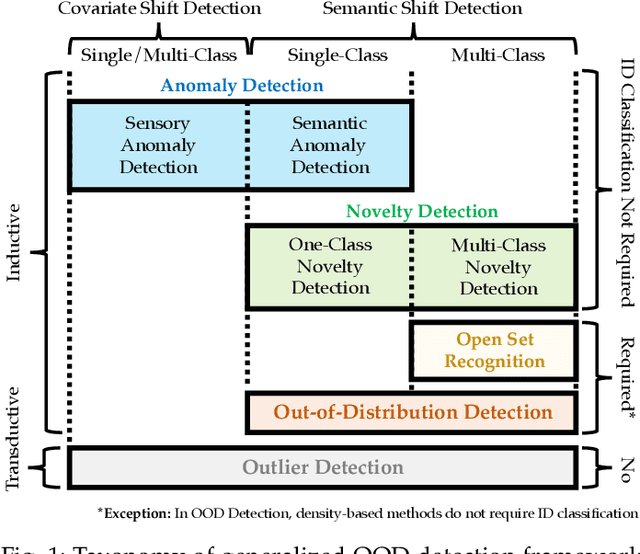
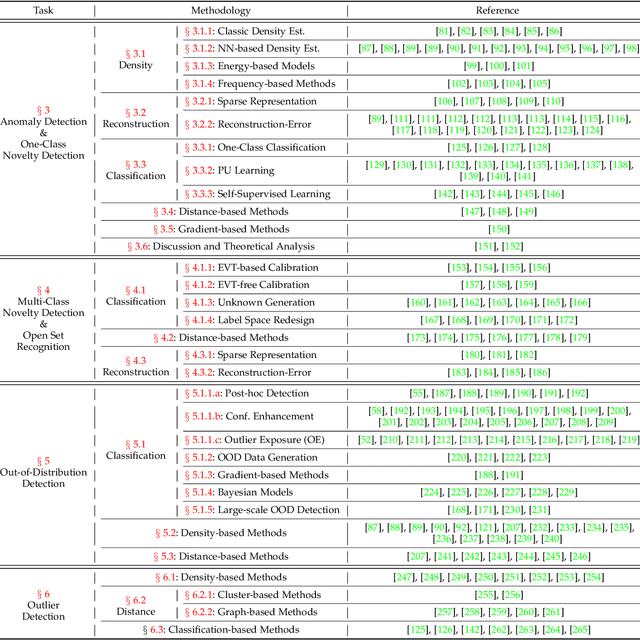

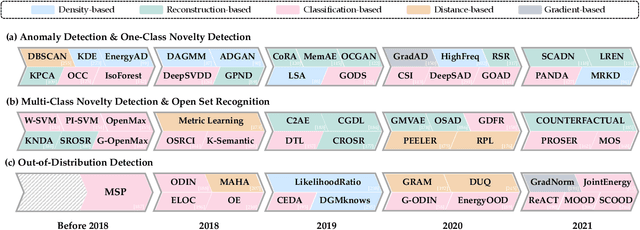
Out-of-distribution (OOD) detection is critical to ensuring the reliability and safety of machine learning systems. For instance, in autonomous driving, we would like the driving system to issue an alert and hand over the control to humans when it detects unusual scenes or objects that it has never seen before and cannot make a safe decision. This problem first emerged in 2017 and since then has received increasing attention from the research community, leading to a plethora of methods developed, ranging from classification-based to density-based to distance-based ones. Meanwhile, several other problems are closely related to OOD detection in terms of motivation and methodology. These include anomaly detection (AD), novelty detection (ND), open set recognition (OSR), and outlier detection (OD). Despite having different definitions and problem settings, these problems often confuse readers and practitioners, and as a result, some existing studies misuse terms. In this survey, we first present a generic framework called generalized OOD detection, which encompasses the five aforementioned problems, i.e., AD, ND, OSR, OOD detection, and OD. Under our framework, these five problems can be seen as special cases or sub-tasks, and are easier to distinguish. Then, we conduct a thorough review of each of the five areas by summarizing their recent technical developments. We conclude this survey with open challenges and potential research directions.
Learning to Prompt for Vision-Language Models
Sep 21, 2021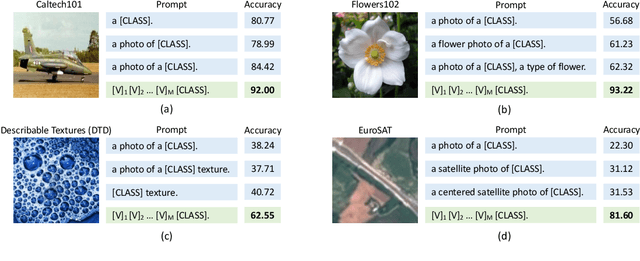
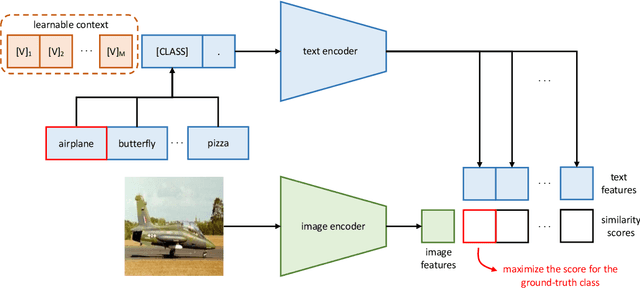
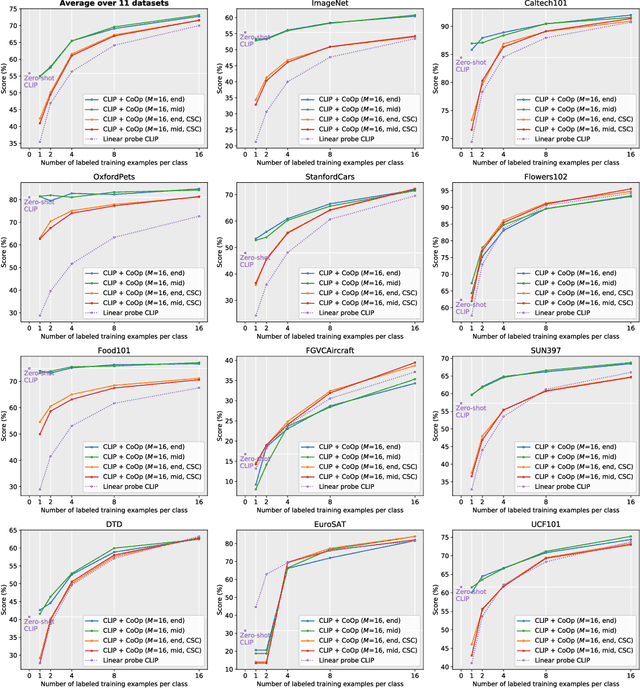
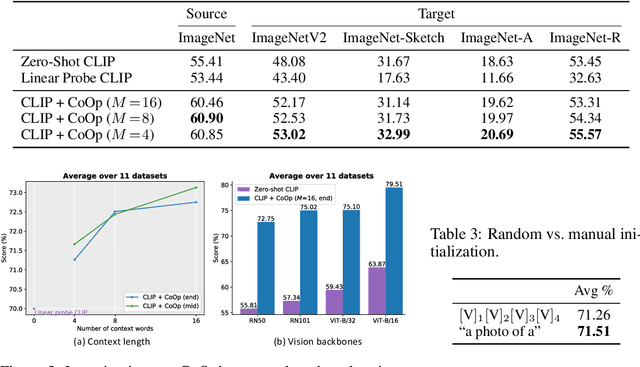
Vision-language pre-training has recently emerged as a promising alternative for representation learning. It shifts from the tradition of using images and discrete labels for learning a fixed set of weights, seen as visual concepts, to aligning images and raw text for two separate encoders. Such a paradigm benefits from a broader source of supervision and allows zero-shot transfer to downstream tasks since visual concepts can be diametrically generated from natural language, known as prompt. In this paper, we identify that a major challenge of deploying such models in practice is prompt engineering. This is because designing a proper prompt, especially for context words surrounding a class name, requires domain expertise and typically takes a significant amount of time for words tuning since a slight change in wording could have a huge impact on performance. Moreover, different downstream tasks require specific designs, further hampering the efficiency of deployment. To overcome this challenge, we propose a novel approach named context optimization (CoOp). The main idea is to model context in prompts using continuous representations and perform end-to-end learning from data while keeping the pre-trained parameters fixed. In this way, the design of task-relevant prompts can be fully automated. Experiments on 11 datasets show that CoOp effectively turns pre-trained vision-language models into data-efficient visual learners, requiring as few as one or two shots to beat hand-crafted prompts with a decent margin and able to gain significant improvements when using more shots (e.g., at 16 shots the average gain is around 17% with the highest reaching over 50%). CoOp also exhibits strong robustness to distribution shift.
Energy-Based Open-World Uncertainty Modeling for Confidence Calibration
Aug 16, 2021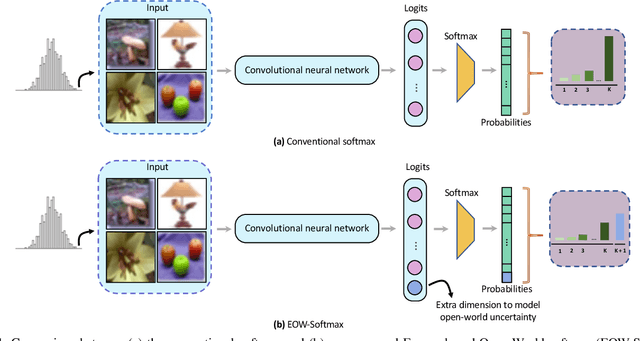
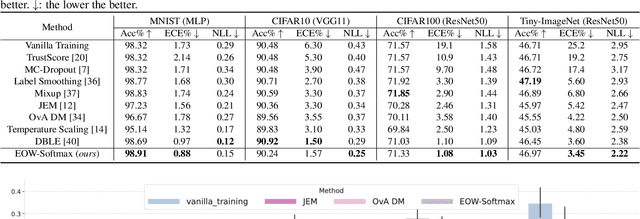
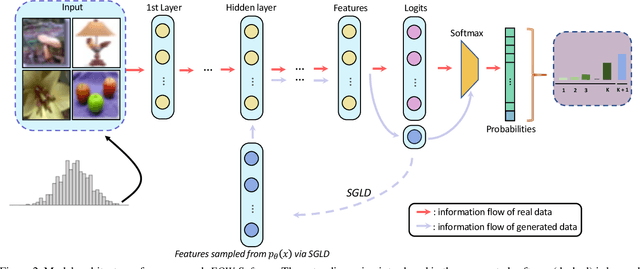
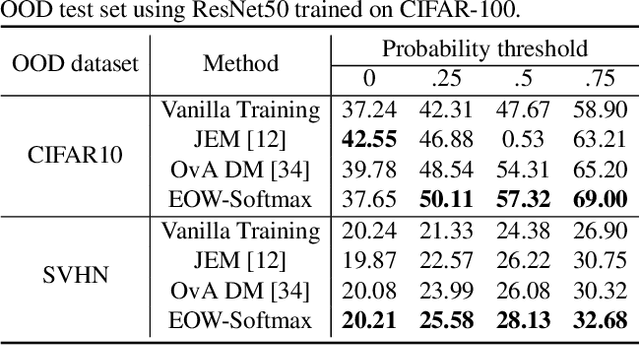
Confidence calibration is of great importance to the reliability of decisions made by machine learning systems. However, discriminative classifiers based on deep neural networks are often criticized for producing overconfident predictions that fail to reflect the true correctness likelihood of classification accuracy. We argue that such an inability to model uncertainty is mainly caused by the closed-world nature in softmax: a model trained by the cross-entropy loss will be forced to classify input into one of $K$ pre-defined categories with high probability. To address this problem, we for the first time propose a novel $K$+1-way softmax formulation, which incorporates the modeling of open-world uncertainty as the extra dimension. To unify the learning of the original $K$-way classification task and the extra dimension that models uncertainty, we propose a novel energy-based objective function, and moreover, theoretically prove that optimizing such an objective essentially forces the extra dimension to capture the marginal data distribution. Extensive experiments show that our approach, Energy-based Open-World Softmax (EOW-Softmax), is superior to existing state-of-the-art methods in improving confidence calibration.