 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKai Yang
The Meta Distribution of SINR in UAV-Assisted Cellular Networks
Jan 30, 2023
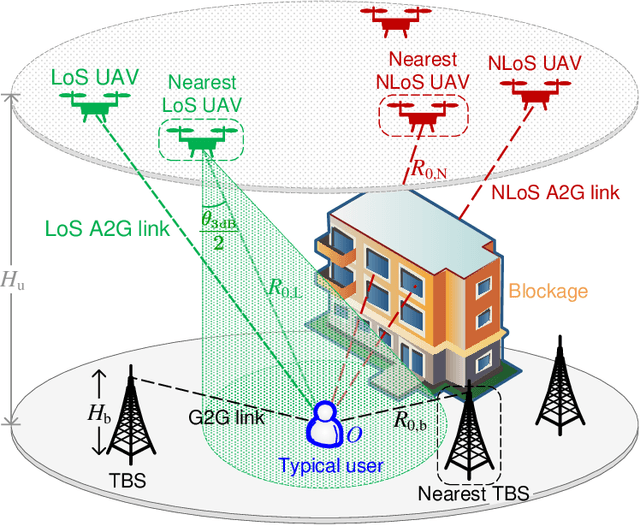
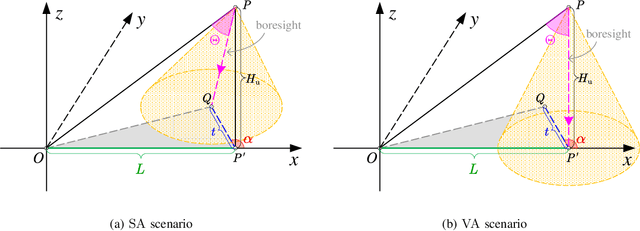
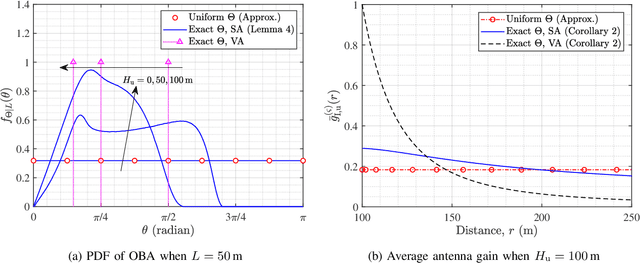
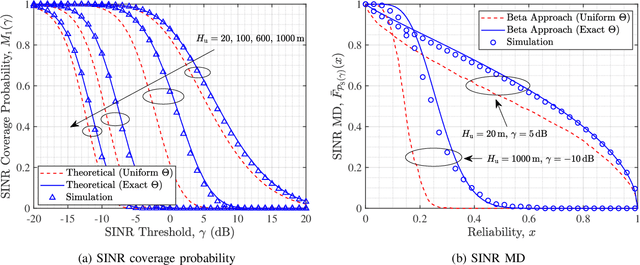
Mounting compact and lightweight base stations on unmanned aerial vehicles (UAVs) is a cost-effective and flexible solution to provide seamless coverage on the existing terrestrial networks. While the coverage probability in UAV-assisted cellular networks has been widely investigated, it provides only the first-order statistic of signal-to-interference-plus-noise ratio (SINR). In this paper, to analyze high-order statistics of SINR and characterize the disparity among individual links, we provide a meta distribution (MD)-based analytical framework for UAV-assisted cellular networks, in which the probabilistic line-of-sight channel and realistic antenna pattern are taken into account for air-to-ground transmissions. To accurately characterize the interference from UAVs, we relax the widely applied uniform off-boresight angle (OBA) assumption and derive the exact distribution of OBA. Using stochastic geometry, for both steerable and vertical antenna scenarios, we obtain mathematical expressions for the moments of condition success probability, the SINR MD, and the mean local delay. Moreover, we study the asymptotic behavior of the moments as network density approaches infinity. Numerical results validate the tightness of the theoretical results and show that the uniform OBA assumption underestimates the network performance, especially in the regime of moderate altitude of UAV. We also show that when UAVs are equipped with steerable antennas, the network coverage and user fairness can be optimized simultaneously by carefully adjusting the UAV parameters.
Asynchronous Distributed Bilevel Optimization
Dec 20, 2022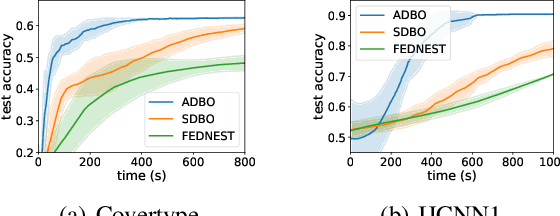
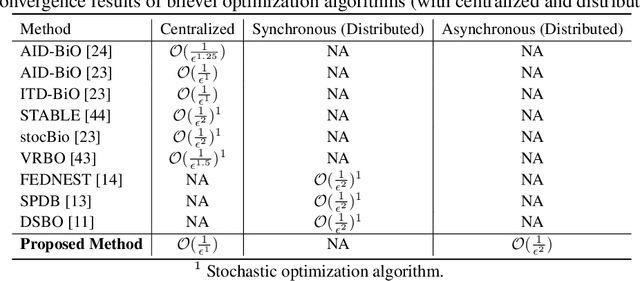

Bilevel optimization plays an essential role in many machine learning tasks, ranging from hyperparameter optimization to meta-learning. Existing studies on bilevel optimization, however, focus on either centralized or synchronous distributed setting. The centralized bilevel optimization approaches require collecting massive amount of data to a single server, which inevitably incur significant communication expenses and may give rise to data privacy risks. Synchronous distributed bilevel optimization algorithms, on the other hand, often face the straggler problem and will immediately stop working if a few workers fail to respond. As a remedy, we propose Asynchronous Distributed Bilevel Optimization (ADBO) algorithm. The proposed ADBO can tackle bilevel optimization problems with both nonconvex upper-level and lower-level objective functions, and its convergence is theoretically guaranteed. Furthermore, it is revealed through theoretic analysis that the iteration complexity of ADBO to obtain the $\epsilon$-stationary point is upper bounded by $\mathcal{O}(\frac{1}{{{\epsilon ^2}}})$. Thorough empirical studies on public datasets have been conducted to elucidate the effectiveness and efficiency of the proposed ADBO.
AI Empowered Net-RCA for 6G
Dec 05, 2022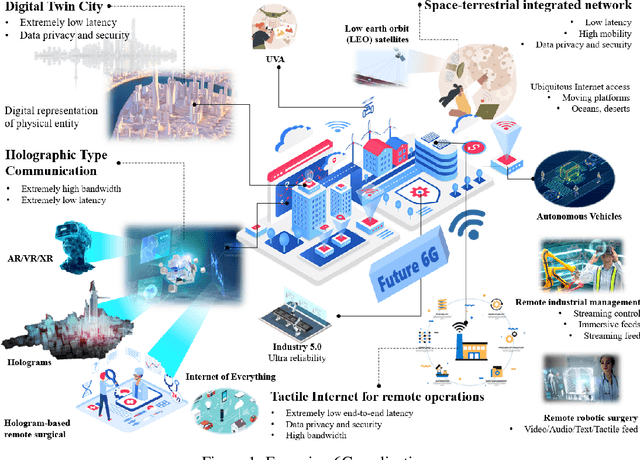
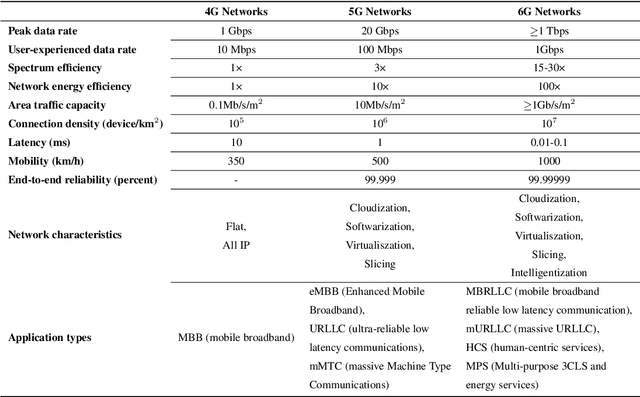
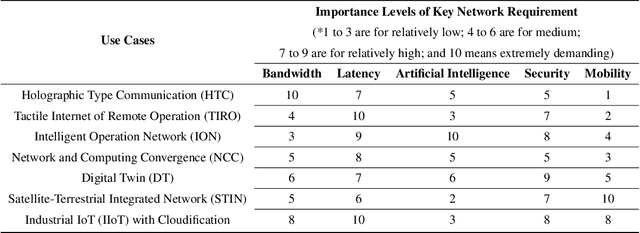
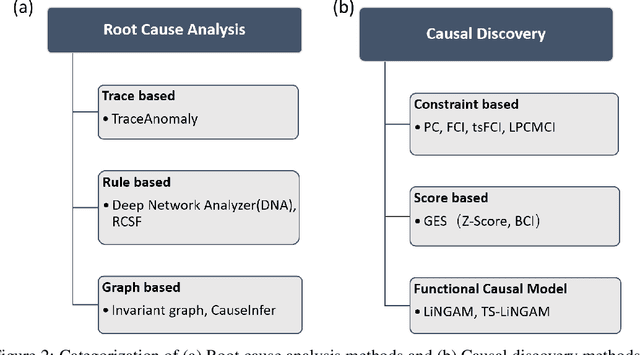
6G is envisioned to offer higher data rate, improved reliability, ubiquitous AI services, and support massive scale of connected devices. As a consequence, 6G will be much more complex than its predecessors. The growth of the system scale and complexity as well as the coexistence with the legacy networks and the diversified service requirements will inevitably incur huge maintenance cost and efforts for future 6G networks. Network Root Cause Analysis (Net-RCA) plays a critical role in identifying root causes of network faults. In this article, we first give an introduction about the envisioned 6G networks. Next, we discuss the challenges and potential solutions of 6G network operation and management, and comprehensively survey existing RCA methods. Then we propose an artificial intelligence (AI)-empowered Net-RCA framework for 6G. Performance comparisons on both synthetic and real-world network data are carried out to demonstrate that the proposed method outperforms the existing method considerably.
SOTIF Entropy: Online SOTIF Risk Quantification and Mitigation for Autonomous Driving
Nov 08, 2022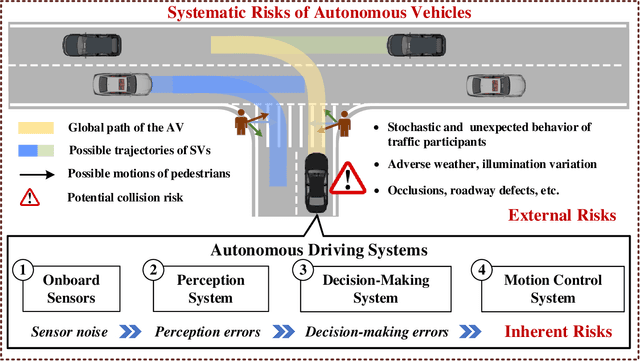

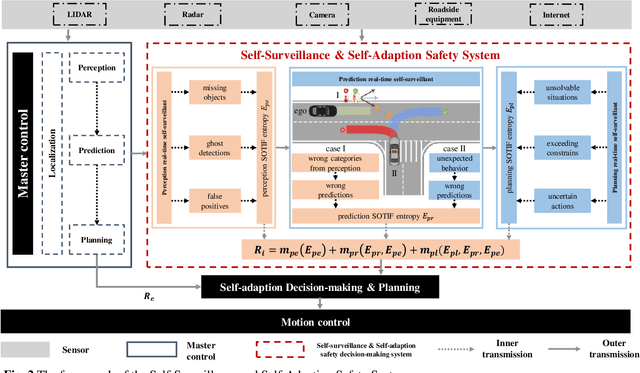
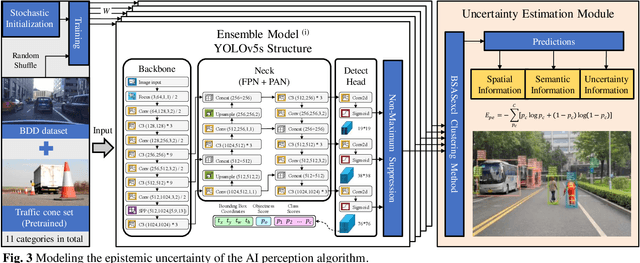
Autonomous driving confronts great challenges in complex traffic scenarios, where the risk of Safety of the Intended Functionality (SOTIF) can be triggered by the dynamic operational environment and system insufficiencies. The SOTIF risk is reflected not only intuitively in the collision risk with objects outside the autonomous vehicles (AVs), but also inherently in the performance limitation risk of the implemented algorithms themselves. How to minimize the SOTIF risk for autonomous driving is currently a critical, difficult, and unresolved issue. Therefore, this paper proposes the "Self-Surveillance and Self-Adaption System" as a systematic approach to online minimize the SOTIF risk, which aims to provide a systematic solution for monitoring, quantification, and mitigation of inherent and external risks. The core of this system is the risk monitoring of the implemented artificial intelligence algorithms within the AV. As a demonstration of the Self-Surveillance and Self-Adaption System, the risk monitoring of the perception algorithm, i.e., YOLOv5 is highlighted. Moreover, the inherent perception algorithm risk and external collision risk are jointly quantified via SOTIF entropy, which is then propagated downstream to the decision-making module and mitigated. Finally, several challenging scenarios are demonstrated, and the Hardware-in-the-Loop experiments are conducted to verify the efficiency and effectiveness of the system. The results demonstrate that the Self-Surveillance and Self-Adaption System enables dependable online monitoring, quantification, and mitigation of SOTIF risk in real-time critical traffic environments.
Distributed Distributionally Robust Optimization with Non-Convex Objectives
Oct 14, 2022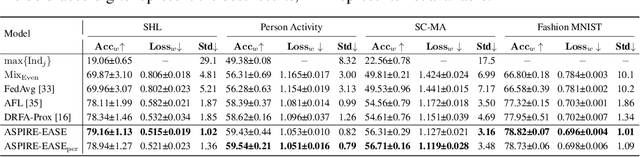
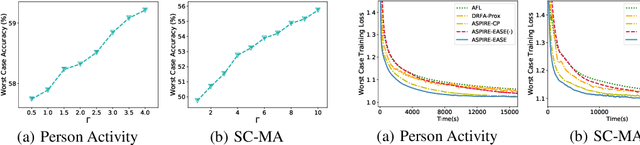

Distributionally Robust Optimization (DRO), which aims to find an optimal decision that minimizes the worst case cost over the ambiguity set of probability distribution, has been widely applied in diverse applications, e.g., network behavior analysis, risk management, etc. However, existing DRO techniques face three key challenges: 1) how to deal with the asynchronous updating in a distributed environment; 2) how to leverage the prior distribution effectively; 3) how to properly adjust the degree of robustness according to different scenarios. To this end, we propose an asynchronous distributed algorithm, named Asynchronous Single-looP alternatIve gRadient projEction (ASPIRE) algorithm with the itErative Active SEt method (EASE) to tackle the distributed distributionally robust optimization (DDRO) problem. Furthermore, a new uncertainty set, i.e., constrained D-norm uncertainty set, is developed to effectively leverage the prior distribution and flexibly control the degree of robustness. Finally, our theoretical analysis elucidates that the proposed algorithm is guaranteed to converge and the iteration complexity is also analyzed. Extensive empirical studies on real-world datasets demonstrate that the proposed method can not only achieve fast convergence, and remain robust against data heterogeneity as well as malicious attacks, but also tradeoff robustness with performance.
SIND: A Drone Dataset at Signalized Intersection in China
Sep 06, 2022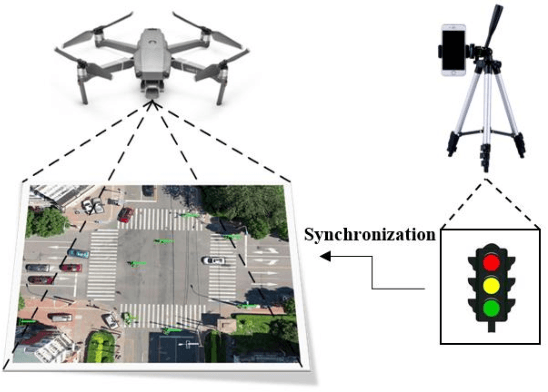

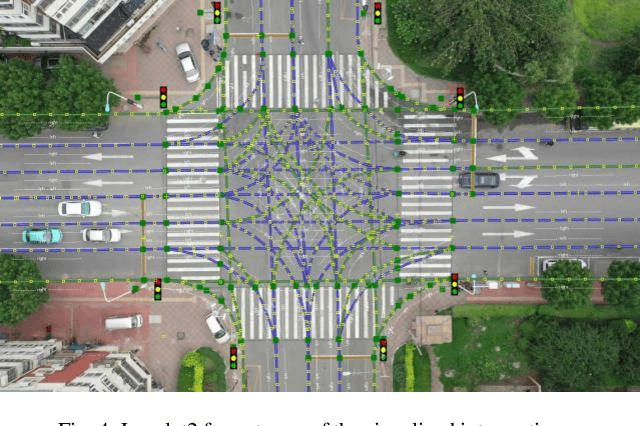
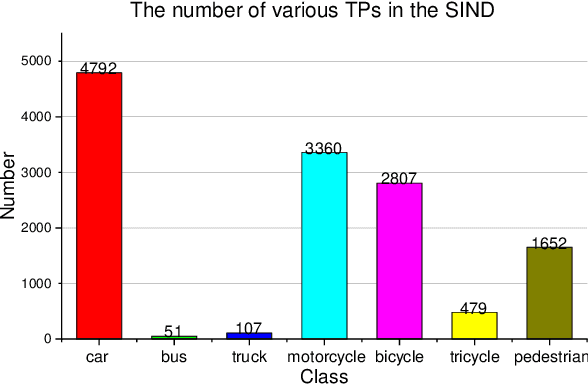
Intersection is one of the most challenging scenarios for autonomous driving tasks. Due to the complexity and stochasticity, essential applications (e.g., behavior modeling, motion prediction, safety validation, etc.) at intersections rely heavily on data-driven techniques. Thus, there is an intense demand for trajectory datasets of traffic participants (TPs) in intersections. Currently, most intersections in urban areas are equipped with traffic lights. However, there is not yet a large-scale, high-quality, publicly available trajectory dataset for signalized intersections. Therefore, in this paper, a typical two-phase signalized intersection is selected in Tianjin, China. Besides, a pipeline is designed to construct a Signalized INtersection Dataset (SIND), which contains 7 hours of recording including over 13,000 TPs with 7 types. Then, the behaviors of traffic light violations in SIND are recorded. Furthermore, the SIND is also compared with other similar works. The features of the SIND can be summarized as follows: 1) SIND provides more comprehensive information, including traffic light states, motion parameters, High Definition (HD) map, etc. 2) The category of TPs is diverse and characteristic, where the proportion of vulnerable road users (VRUs) is up to 62.6% 3) Multiple traffic light violations of non-motor vehicles are shown. We believe that SIND would be an effective supplement to existing datasets and can promote related research on autonomous driving.The dataset is available online via: https://github.com/SOTIF-AVLab/SinD
ADTR: Anomaly Detection Transformer with Feature Reconstruction
Sep 05, 2022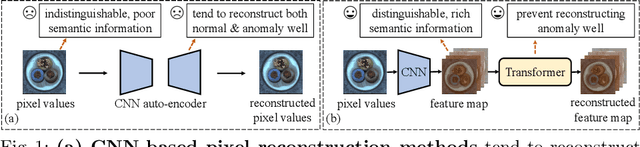
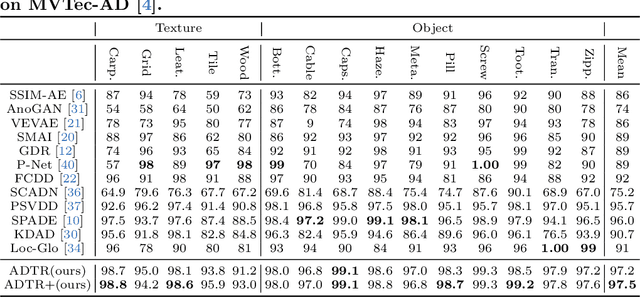
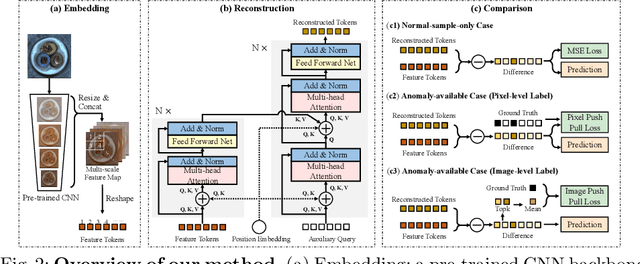
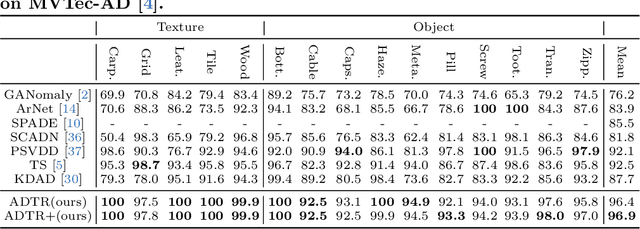
Anomaly detection with only prior knowledge from normal samples attracts more attention because of the lack of anomaly samples. Existing CNN-based pixel reconstruction approaches suffer from two concerns. First, the reconstruction source and target are raw pixel values that contain indistinguishable semantic information. Second, CNN tends to reconstruct both normal samples and anomalies well, making them still hard to distinguish. In this paper, we propose Anomaly Detection TRansformer (ADTR) to apply a transformer to reconstruct pre-trained features. The pre-trained features contain distinguishable semantic information. Also, the adoption of transformer limits to reconstruct anomalies well such that anomalies could be detected easily once the reconstruction fails. Moreover, we propose novel loss functions to make our approach compatible with the normal-sample-only case and the anomaly-available case with both image-level and pixel-level labeled anomalies. The performance could be further improved by adding simple synthetic or external irrelevant anomalies. Extensive experiments are conducted on anomaly detection datasets including MVTec-AD and CIFAR-10. Our method achieves superior performance compared with all baselines.
Task-aware Similarity Learning for Event-triggered Time Series
Jul 17, 2022


Time series analysis has achieved great success in diverse applications such as network security, environmental monitoring, and medical informatics. Learning similarities among different time series is a crucial problem since it serves as the foundation for downstream analysis such as clustering and anomaly detection. It often remains unclear what kind of distance metric is suitable for similarity learning due to the complex temporal dynamics of the time series generated from event-triggered sensing, which is common in diverse applications, including automated driving, interactive healthcare, and smart home automation. The overarching goal of this paper is to develop an unsupervised learning framework that is capable of learning task-aware similarities among unlabeled event-triggered time series. From the machine learning vantage point, the proposed framework harnesses the power of both hierarchical multi-scale sequence autoencoders and Gaussian Mixture Model (GMM) to effectively learn the low-dimensional representations from the time series. Finally, the obtained similarity measure can be easily visualized for explaining. The proposed framework aspires to offer a stepping stone that gives rise to a systematic approach to model and learn similarities among a multitude of event-triggered time series. Through extensive qualitative and quantitative experiments, it is revealed that the proposed method outperforms state-of-the-art methods considerably.
A Unified Model for Multi-class Anomaly Detection
Jun 08, 2022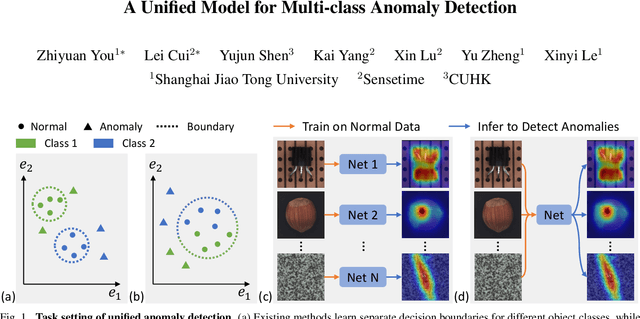
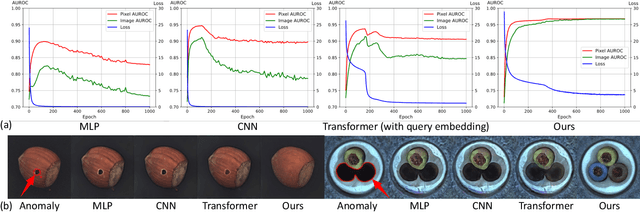
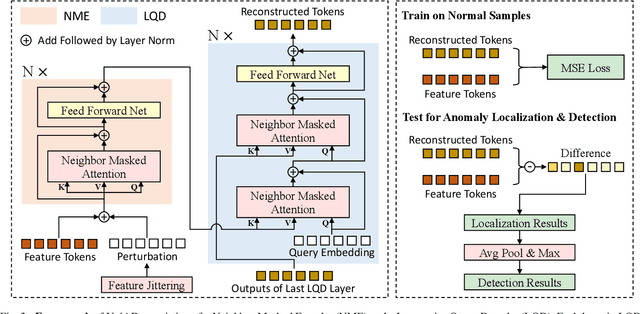
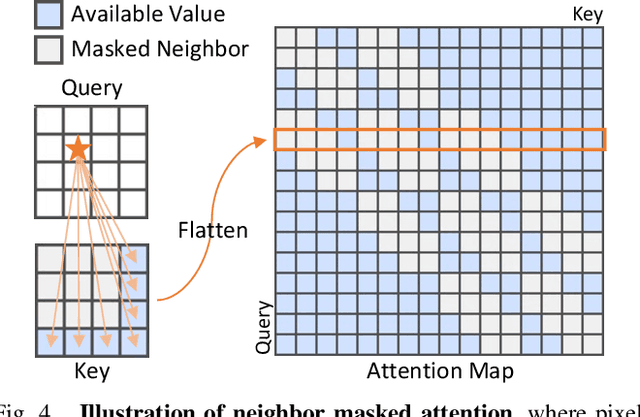
Despite the rapid advance of unsupervised anomaly detection, existing methods require to train separate models for different objects. In this work, we present UniAD that accomplishes anomaly detection for multiple classes with a unified framework. Under such a challenging setting, popular reconstruction networks may fall into an "identical shortcut", where both normal and anomalous samples can be well recovered, and hence fail to spot outliers. To tackle this obstacle, we make three improvements. First, we revisit the formulations of fully-connected layer, convolutional layer, as well as attention layer, and confirm the important role of query embedding (i.e., within attention layer) in preventing the network from learning the shortcut. We therefore come up with a layer-wise query decoder to help model the multi-class distribution. Second, we employ a neighbor masked attention module to further avoid the information leak from the input feature to the reconstructed output feature. Third, we propose a feature jittering strategy that urges the model to recover the correct message even with noisy inputs. We evaluate our algorithm on MVTec-AD and CIFAR-10 datasets, where we surpass the state-of-the-art alternatives by a sufficiently large margin. For example, when learning a unified model for 15 categories in MVTec-AD, we surpass the second competitor on the tasks of both anomaly detection (from 88.1% to 96.5%) and anomaly localization (from 89.5% to 96.8%). Code will be made publicly available.